目录
0. 前言
1. Penn-Fudan数据集介绍
2. Penn-Fudan数据集预处理过程
3. 结果展示
4. 完整代码
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文以Penn-Fudan数据集预处理为例,说明用于目标检测算法训练的数据集的预处理方法及过程。
因为要给目标检测算法进行训练,需要预先提取出图像中定位及分类相关信息,过程稍微有点复杂,所以单独写作这篇博客专门介绍整个过程。
1. Penn-Fudan数据集介绍
1.1 基础概述
Penn-Fudan行人数据集(Penn-Fudan Pedestrian Detection Dataset)是一个专门用于行人检测任务的小规模图像数据集。这个数据集由宾夕法尼亚大学和复旦大学的研究者共同创建,主要用于学术研究和算法验证。
该数据集包含170张高分辨率的RGB图像,这些图片都是从视频序列中截取的,并且在每幅图像中有0到6个不等的行人目标。每个行人的位置都通过矩形框(mask)进行了精确标注,提供了边界框坐标信息,便于进行目标检测训练和测试。
Penn-Fudan数据集的文件结构如下:
PennFudanPed/
├── Annotation/ #包含每个图像的注释,包含有多少行人及行人位置等信息
│ ├── FudanPed00001.txt
│ ├── FudanPed00002.txt
│ └── ...
├── PedMasks/ #包含每个行人的掩码图像
│ ├── FudanPed00001_mask.png
│ ├── FudanPed00002_mask.png
│ └── ...
├── PNGImages/ # 图像文件夹
│ ├── FudanPed00001.png
│ ├── FudanPed00002.png
│ └── ...
└── readme.txt1.2 图像内容
- 场景:图像采集自多种环境,如校园、街道、人行横道等,涵盖了不同光照条件、行人姿态和遮挡情况。
- 行人数量:总计标注了345个行人的实例,每张图片中至少有一个行人,部分图片中有多个行人。
1.3 标注信息
Penn-Fudan数据集所有图像都按照PASCAL VOC格式进行标注,包括每个行人的精确边界框和像素级分割掩模。
- 边界框(Bounding Boxes):每个行人实例都有一个矩形边界框,用于表示行人在图像中的位置。
- 分割掩模(Segmentation Masks):除了边界框之外,还提供了每个行人实例的精细像素级分割标签,这对于训练和评估基于深度学习的语义分割模型非常有用。
1.4 应用示例
- 模型训练与验证:该数据集常被用于微调预训练的物体检测和实例分割模型,例如Mask R-CNN,以检验其对行人检测及分割任务的适应性。
- 算法比较:研究者使用Penn-Fudan数据集来对比不同行人检测和分割方法的效果,并以此来改进算法性能。
1.5 获取与使用
- 资源获取:用户通常需要从官方或相关学术项目网站下载该数据集,数据集中包含了图像文件夹(如“PNGImages”)和相应的XML标注文件。
- 数据加载:利用工具如`TorchVision`或其他计算机视觉库可以方便地加载和解析这些标注数据,进而进行模型训练和实验。
需要数据集的小伙伴可以留下邮箱。
2. Penn-Fudan数据集预处理过程
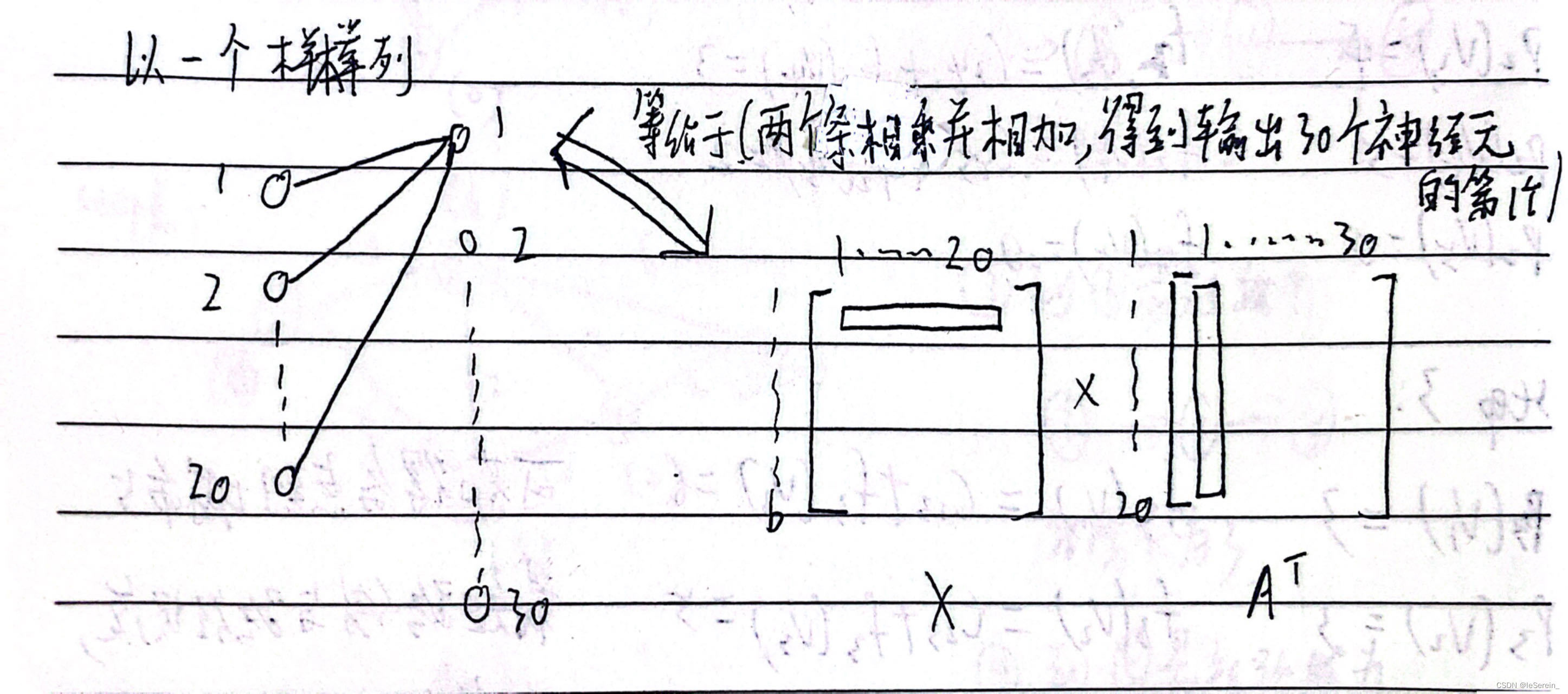
首先需要解释下PedMasks中的mask,mask是一个二维矩阵,用于标注图像中的行人:用“0”标注图像背景,用“1”标注“行人1”,“2”标注“行人2”,以此类推……
下面示意图可以更加形象地说明mask:

当然真实mask要达到像素级精度,比上面示意图密集得多。
Penn-Fudan数据集预处理过程可以分为以下几个步骤:
- 提取mask中的值mask_id,确认图像中有几个行人,例如上图mask_id = [1, 2];
- 按照mask_id把单个mask拆分成多个masks,拆分过程如下图;
- 确认masks中的每个行人的位置,即每个ground truth框的[x_min, y_min, x_max, y_max];

3. 结果展示
按上述过程对Penn-Fudan数据集进行预处理,结果如下:



其中绿色框代表行人的ground truth框,红色数字代表行人编号。
4. 完整代码
import os
import numpy as np
from PIL import Image
import cv2
class PFdataset():
def __init__(self, path):
self.path = path
self.imgs = list(sorted(os.listdir(os.path.join(path, 'PNGImages')))) #图像列表:['FudanPed00001.png', 'FudanPed00002.png'...]
self.masks = list(sorted(os.listdir(os.path.join(path, 'PedMasks')))) #Mask列表:['FudanPed00001_mask.png', 'FudanPed00002_mask.png'...]
def __getitem__(self, item):
img_path = os.path.join(self.path, 'PNGImages', self.imgs[item]) #输出单个图像的地址:Penn-Fudan\PNGImages\FudanPed00xxx.png
mask_path = os.path.join(self.path, 'PedMasks', self.masks[item]) #输出单个mask的地址:Penn-Fudan\PedMasks\PennPed00xxx_mask.png
img = Image.open(img_path).convert('RGB') #例 <PIL.Image.Image image mode=RGB size=559x536 at 0x2103A5ED790> , 可以用.show()看到图像, 可以用 numpy.array()看到图像数据
mask = np.array(Image.open(mask_path)) #例 <PIL.PngImagePlugin.PngImageFile image mode=L size=530x410 at 0x214FACC83D0>
mask_id = np.unique(mask) #提取mask的编码,例:编码有[0,1,2]。0代表背景,1代表人物1,2代表人物2
mask_id = mask_id[1:] #0是背景,进行切片,编码仅剩[1,2]
masks = mask == mask_id[:,None,None] #把不同对象的mask提取出来,mask_id[:,None,None]相当于array的升维
gt_boxs = [] #groundtruth框的坐标值list
for i in range(len(mask_id)):
box = np.where(masks[i])
xmin = np.min(box[1])
xmax = np.max(box[1])
ymin = np.min(box[0])
ymax = np.max(box[0])
gt_boxs.append([xmin, ymin, xmax, ymax, mask_id[i]])
#使用cv2画框并且标注序号
img_cv2 = cv2.imread(img_path)
for [xmin, ymin, xmax, ymax, mask_id] in gt_boxs:
cv2.rectangle(img_cv2,(xmin,ymin),(xmax,ymax),(0, 255, 0), 2)
text = '%s'%mask_id
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
color = (0, 0, 255) # 蓝色文本
thickness = 2
text_size, baseline = cv2.getTextSize(text, font, font_scale, thickness)
text_origin = (xmin,ymin + baseline*3)
# 在矩形框上方写入文本
cv2.putText(img_cv2, text, text_origin, font, font_scale, color, thickness, cv2.LINE_AA)
cv2.imshow('gt_box',img_cv2)
cv2.imwrite('Penn-Fudan/output/%s.jpg'%item, img_cv2)
dataset = PFdataset('Penn-Fudan')
dataset[1]