应用场景
首先在linux中应用程序无法是直接访问驱动程序的数据的, 需要通过 copy_to_user 和 copy_from_user才能实现数据传输, 那么数据量大了以后如LCD的数据, 那么就会有很长的耗时, 为了解决这一问题, 引入mmap, 将底层物理地址映射出来, 让应用程序得以直接读写这一块内存. mmap的使用说白了, 很简单:
1, 有块虚拟地址
2, 找到要用的那块物理地址
3, 建立映射
内核应用程序开辟的虚拟地址
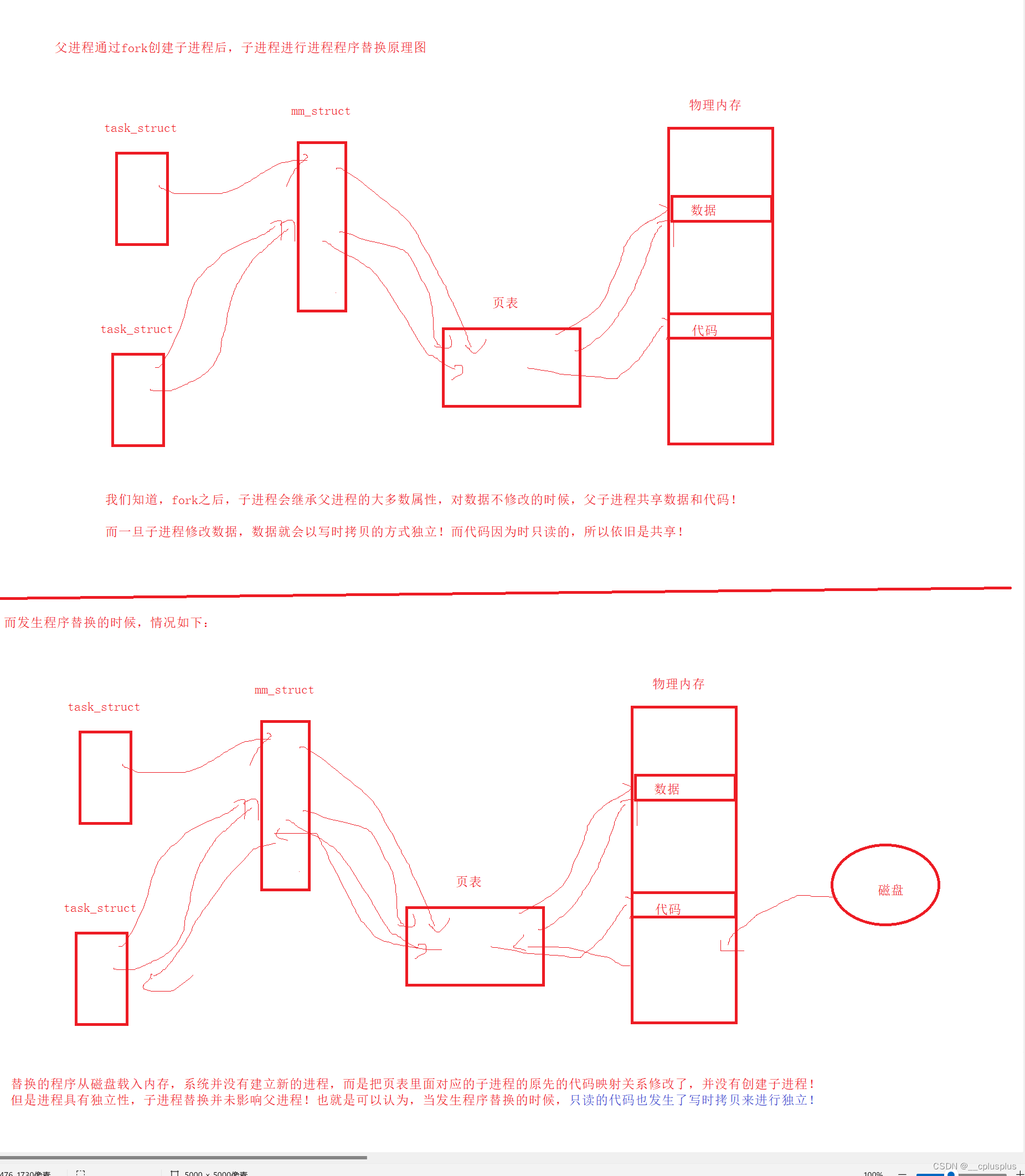
内核将每个进程都作为一个task_struct结构体存在一个双向循环链表中, 结构体在 include/linux/sched.h中定义. 其中有个struct mm_struct *mm成员, 记录着这个进程的虚拟地址的信息.duan0
在mm_struct中, struct vm_area_struct mmap 链表保存了每一块应用程序虚拟地址(堆空间, 栈空间, bss区, data常量空间, text代码0段)的起始位置和结束位置. 当然虚拟地址不可能是凭空产生, 自然是要有一块相应的物理地址来对应, 这一块物理地址就保存在pgd_t * pgd* 这个成员变量中叫做页目录表, pgd成员记录了对应的物理地址, 也记录了如何映射
进程启动时虚拟地址内核已经帮我们做好了, 当一段程序运行时,便开辟了一块4G虚拟地址(在32位系统中), 在linux中可以在 /proc/进程号/maps 来查看这个进程用到的虚拟地址
页表
将虚拟地址的某一段转换成物理地址的话, 就需要在页表pgd中添加一个页表项.
页表项的内容是个32位的数据, 如下图

ARM架构内存映射:
RM架构支持一级页表映射,也就是说MMU根据CPU发来的虚拟地址可以找到第1个页表,从第1个页表里就可以知道这个虚拟地址对应的物理地址。一级页表里地址映射的最小单位是1M。
ARM架构还支持二级页表映射,也就是说MMU根据CPU发来的虚拟地址先找到第1个页表,从第1个页表里就可以知道第2级页表在哪里;再取出第2级页表,从第2个页表里才能确定这个虚拟地址对应的物理地址。二级页表地址映射的最小单位有4K、1K,Linux使用4K
一级页表映射过程
一线页表中每一个表项用来设置1M的空间,对于32位的系统,虚拟地址空间有4G,4G/1M=4096。所以一级页表要映射整个4G空间的话,需要4096个页表项。
第0个页表项用来表示虚拟地址第0个1M(虚拟地址为0~0xFFFFF)对应哪一块物理内存,并且有一些权限设置;
第1个页表项用来表示虚拟地址第1个1M(虚拟地址为0x100000~0x1FFFFF)对应哪一块物理内存,并且有一些权限设置;
使用一级页表时
① CPU发出虚拟地址vaddr,假设为0x12345678
② MMU根据vaddr[31:20]找到一级页表项:
在[1:0]发现是个一级页表
虚拟地址0x12345678是虚拟地址空间里第0x123个1M,所以找到页表里第0x123项,根据此项内容知道它是一个段页表项。
段内偏移是0x45678。
③ 从这个表项里取出物理基地址:Section Base Address,假设是0x81000000
④ 物理基地址加上段内偏移得到:0x81045678
所以CPU要访问虚拟地址0x12345678时,实际上访问的是0x81045678的物理地址
二级页表映射过程
① CPU发出虚拟地址vaddr,假设为0x12345678
② MMU根据vaddr[31:20]找到一级页表项:
虚拟地址0x12345678是虚拟地址空间里第0x123个1M,所以找到页表里第0x123项。根据此项的[1:0]内容知道它是一个二级页表项。
③ 从这个表项里取出地址,假设是address,这表示的是二级页表项的物理地址;
④ vaddr[19:12]表示的是二级页表项中的索引index即0x45,在二级页表项中找到第0x45项;
⑤二级页表项格式如下:

里面含有这4K或1K物理空间的基地址page base addr,假设是0x81889000:
它跟vaddr[11:0]组合得到物理地址:0x81889000 + 0x678 = 0x81889678。
所以CPU要访问虚拟地址0x12345678时,实际上访问的是0x81889678的物理地址
给APP新建一块内存映射
① 得到一个vm_area_struct,它表示APP的一块虚拟内存空间;
很幸运,APP调用mmap系统函数时,内核就帮我们构造了一个vm_area_stuct结构体。里面含有虚拟地址的地址范围、权限。
② 确定物理地址:
你想映射某个内核buffer,你需要得到它的物理地址,这得由你提供。
③ 给vm_area_struct和物理地址建立映射关系:
也很幸运,内核提供有相关函数。
APP里调用mmap时,导致的内核相关函数调用过程如下:
cache和buffer映射属性如何选择:
是否使用cache、是否使用buffer,就有4种组合(Linux内核文件arch\arm\include\asm\pgtable-2level.h):
第1种是不使用cache也不使用buffer,读写时都直达硬件,这适合寄存器的读写。
第2种是不使用cache但是使用buffer,写数据时会用buffer进行优化,可能会有“写合并”,这适合显存的操作。因为对显存很少有读操作,基本都是写操作,而写操作即使被“合并”也没有关系。
第3种是使用cache不使用buffer,就是“write through”,适用于只读设备:在读数据时用cache加速,基本不需要写。
第4种是既使用cache又使用buffer,适合一般的内存读写。
驱动程序要做的事
驱动程序要做的事情有3点:
① 确定物理地址
② 确定属性:是否使用cache、buffer
③ 建立映射关系
编码:
App
fd = open("/dev/hello", O_RDWR);
/* 2. mmap
* MAP_SHARED : 多个APP都调用mmap映射同一块内存时, 对内存的修改大家都可以看到。
* 就是说多个APP、驱动程序实际上访问的都是同一块内存
* MAP_PRIVATE : 创建一个copy on write的私有映射。
* 当APP对该内存进行修改时,其他程序是看不到这些修改的。
* 就是当APP写内存时, 内核会先创建一个拷贝给这个APP,
* 这个拷贝是这个APP私有的, 其他APP、驱动无法访问。
*/
buf = mmap(NULL, 1024*8, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (buf == MAP_FAILED)
{
printf("can not mmap file /dev/hello\n");
return -1;
}
mmap函数MAP_SHARED、MAP_PRIVATE参数。使用MAP_PRIVATE映射时,
在没有发生写操作时,APP、驱动访问的都是同一块内存;当APP发起写操作时,
就会触发“copy on write”,即内核会先创建该内存块的拷贝,
APP的写操作在这个新内存块上进行,这个新内存块是APP私有的,
别的APP、驱动看不到。
仅用MAP_SHARED参数时,
多个APP、驱动读、写时,操作的都是同一个内存块,“共享”。
printf("mmap address = 0x%x\n", buf);
printf("buf origin data = %s\n", buf); /* old */
/* 3. write */
strcpy(buf, "new");
read(fd, str, 1024);
if (strcmp(buf, str) == 0)
{
/* 对于MAP_SHARED映射,APP写的数据驱动可见
* APP和驱动访问的是同一个内存块
*/
printf("compare ok!\n");
}
驱动程序:
分配内存的函数:
kmalloc 分配到的内存物理地址是连续的
kzalloc 分配到的内存物理地址是连续的,内容清0
vmalloc 分配到的内存物理地址不保证是连续的
vzalloc 分配到的内存物理地址不保证是连续的,内容清0
提供mmap函数
static int _drv_mmap(struct file *file, struct vm_area_struct *vma)
{
//获得物理地址
unsigned long phy = virt_to_phys(bernel_buf);
得到物理地址, kernel_buf是内核使用的虚拟地址用kmalloc分配
//设置属性:cache, buffer
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
设置属性, 不使用 cache 使用buffer
映射
if(remap_pfn_range(vma, vma->vm_start, phy>>PAGE_SHIFT,
vma->vm_end - vma->vm_start, vma->vm_page_prot)){
printk("mmap remap_pfn_range failed\n");
return -ENOBUFS;
}
return 0;
}
remap_pfn_range中,pfn的意思是“Page Frame Number”
在Linux中,整个物理地址空间可以分为第0页、第1页、第2页,诸如此类,这就是pfn。
假设每页大小是4K,那么给定物理地址phy,它的pfn = phy / 4096 = phy >> 12。内核的page一般是4K,但是也可以配置内核修改page的大小。所以为了通用,pfn = phy >> PAGE_SHIFT。
![[附源码]java毕业设计兰州市邮政公司新邮预订户管理信息系统](https://img-blog.csdnimg.cn/9f259891745f4d8b928db1eacc02f828.png)





![[附源码]SSM计算机毕业设计成都团结石材城商家协作系统JAVA](https://img-blog.csdnimg.cn/2895f2ff261345278b2045921ddd30b6.png)