前向推理在modelscope中开源了,但是训练没开源,且是基于TensorFlow的,复现起来是比较麻烦的。
1.Introduction
分割技术主要集中在像素级二元分类,抠图被建模为前景图像F和背景图像B的加权融合,大多数matte方法采用指定的trimap作为约束来减少解的空间,trimap将图像分成三个区域,包括明确的前景,明确的背景和未知区域。但是trimap的获取如果人工标注的话,成本太高。1.从粗到细自适应的学习trimap,2.在输入中丢弃裁剪图,并将其作为matte网络的隐式约束。依然依赖生成的裁剪图的质量,当隐式裁剪图不准确时,无法保留语义信息和高质量的细节。此外matte的标注数据也很难获取。

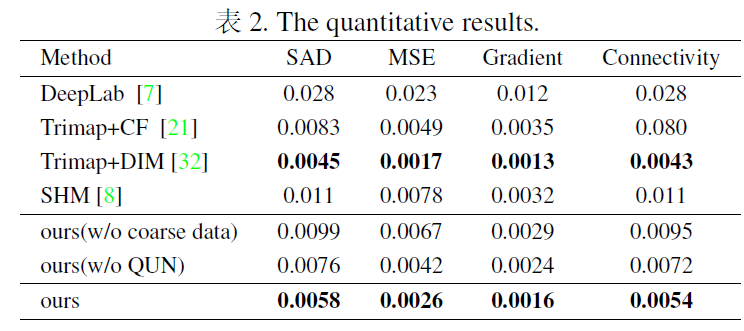
提出了一种利用粗略和精细注释数据进行matte的方法,是trimap-free的,提出了一个耦合的三个子网络来实现,Mask prediction network旨在预测低分辨率的粗略mask,使用粗粒度和细粒度的数据进行训练;引入一个在混合注释数据上训练的Quality unification network来矫正MPN输出质量,Matting Refinement network用于预测最终的alpha,输入为原始图像和粗略mask。

3.proposed approach
3.1 Mask prediction network
第一阶段预测的是粗糙的mask,所有的训练数据调整为192x160,使用所有数据进行训练,包括低质量和高质量的注释数据。使用L1损失,输出是一个具有2个通道的mask,第一个通道是预测的前景mask,第二个通道预测是背景mask。
3.2 Quality Unification network
由于标注高质量抠图数据成本较高,提出使用来自不同数据源的混合数据,其中一些数据被高质量标注,连细微的头发和背景都能分开,大部分数据标注质量相对较低,MPN用的精细标注和粗略标注数据进行训练。Matting预测网络只能在高质量标注数据上进行训练,粗略的mask质量的差异会导致推理阶段的抠图结果不一致。引入了QUN来消除训练抠图修正网络的数据偏差,QUN旨在将MPN的输出质量纠正到相同水平。训练QUN网络的损失包含两部分,identity loss迫使QUN的输出与原始输入变化不大,
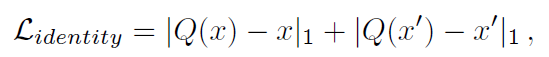
x表示concatenation of the input image和accurate mask,x'表示concatenation of the input image和inaccurate mask,consistence loss要求QUN对应accurate mask和inaccurate mask接近。



3.3 Matting Refinement network
MRN旨在预测准确的alpha matte。以768x768训练,来自MRN和QUN的粗糙mask是低分辨率的192x160,将粗糙mask作为外部输入特征图集成到MRN中,其中输入进过多次卷积后降低4倍,MRN的输出是4通道,三个RGB和一个alpha matte,L1损失:


3.4 Implementation details
tensorflow,按顺序对三个网络进行训练,在输入到MPN之前,对所有的图进行降采样处理,192x160,在每个训练上随机翻转,在MPN上训练20个epoch,将低分辨率图像和输出的前景mask连接起来作为输入来训练QUN,在训练QUN时,对精细化注释数据执行随机滤波(滤波器大小为3或5),二值化和形态学操作(腐蚀膨胀)以生成配对的高质量和低质量mask数据。只使用精细化注释数据的方式训练MRN,整个数据对(图像和mask)都被随机裁剪到768x640,所有网络学习率1e-3,MPN和QUN都使用bs=16训练,MRN仅使用高分辨率数据进行训练。
测试时,仅使用图像作为输入生成alpha mask,800x800上平均测试时间为0.08s。