Spring框架
spring
Bean线程安全问题
@Scope注解
我们可以在bean的类上加@Scope注解来声明这个Bean是单个实例还是多个实例。在默认情况下Bean是单个实例的,此时的注解中的属性默认为@Scope("singleton"),@Scope("prototype")则是一个bean的定义可以有多个实例。
线程安全
如果Bean是可以有多个实例的,每个Bean实例在Spring容器中都会被标记为prototype(原型)作用域,默认情况下,Spring容器会为每个请求创建一个新的实例。因此,每个线程在使用Bean时都会获得一个独立的实例,不会存在线程安全问题。
如果你将Bean的作用域设置为singleton(单例),那么多个线程共享同一个实例,这可能引发线程安全问题。下面举一个线程不安全的例子:
@Controller
@RequestMapping("/user")
public class UserController {
private int count;
@Autowired
private UserService userService;
@GetMapping("/getById/{id}")
public User getById(@PathVariable("id") Integer id){
count++;
System.out.println(count);
return userService.getById(id);
}
}对于UserController这个Bean实例线程就是不安全的,因为其成员变量count是可修改的,如果多个请求同时进入,不同的线程count值就不一样。但是userService实例就不会影响线程安全,因为它是无状态的(就是不可修改的)。
所以说如果一个Bean实例是无状态的,Spring bean并没有可变的状态(比如Service类和DAO类),那么说这个Bean就是线程安全的。
如果在bean中定义了可修改的成员变量,是要考虑线程安全问题的,可以使用多例或者加锁来解决。
AOP
具体可以看我之前写的下面这两篇文章
SpringAOP专栏一《使用教程篇》-CSDN博客
SpringAOP专栏二《原理篇》-CSDN博客
Spring中的事务
实现原理
Spring支持编程式事务管理和声明式事务管理两种方式。
- 编程式事务控制:需使用TransactionTemplate来进行实现,对业务代码有侵入性,项目中很少使用。
- 声明式事务管理:声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
事务失效的场景
异常捕获处理
@Transactional
public void update(Integer from, Integer to, Double money) {
try {
//转账的用户不能为空
Account fromAccount = accountDao.selectById(from);
//判断用户的钱是否够转账
if (fromAccount.getMoney() - money >= 0) {
fromAccount.setMoney(fromAccount.getMoney() - money);
}
accountDao.updateById(fromAccount);
//异常
int a = 1 / 0;
//被转账的用户
Account toAccount = accountDao.selectById(to);
toAccount.setMoney(toAccount.getMoney() + money);
accountDao.updateById(toAccount);
} catch (Exception e) {
e.printStackTrace();
}
}原因:事务通知只有捕捉到了目标抛出的异常,才能进行后续的回滚处理,如果目标自己处理掉异常(此处try catch已经把异常处理掉了),事务通知无法知悉。
解决:在catch块添加throw new RuntimeException(e)将异常抛出,这样让异常被事务捕获,才能进行事务回滚。
抛出检查异常
@Transactional
public void update(Integer from, Integer to, Double money) throws FileNotFoundException
{ //转账的用户不能为空
Account fromAccount = accountDao.selectById(from);
//判断用户的钱是否够转账
if (fromAccount.getMoney() - money >= 0) {
fromAccount.setMoney(fromAccount.getMoney() - money);
}
accountDao.updateById(fromAccount);
//读取文件
new FileInputStream("dddd");
//被转账的用户
Account toAccount = accountDao.selectById(to);
toAccount.setMoney(toAccount.getMoney() + money);
accountDao.updateById(toAccount);
}原因:上面的代码中,抛出的异常是FileNotFoundException,这个异常是检查异常,但是Spring 默认只会回滚非检查异常。
解决:
配置rollbackFor属性
@Transactional(rollbackFor=Exception.class)
非public方法导致的事务失效
@Transactional(rollbackFor = Exception.class)
void update(Integer from, Integer to, Double money) throws FileNotFoundException {
//转账的用户不能为空
Account fromAccount = accountDao.selectById(from);
//判断用户的钱是否够转账
if (fromAccount.getMoney() - money >= 0) {
fromAccount.setMoney(fromAccount.getMoney() - money);
}
accountDao.updateById(fromAccount);
//读取文件
new FileInputStream("dddd");
//被转账的用户
Account toAccount = accountDao.selectById(to);
toAccount.setMoney(toAccount.getMoney() + money);
accountDao.updateById(toAccount);
}原因:Spring 为方法创建代理、添加事务通知、前提条件都是该方法是 public 的
解决:改为 public 方法
Bean的生命周期
BeanDefinition:Spring容器在进行实例化时,会将xml配置的<bean>的信息封装成一个BeanDefinition对象,Spring根据BeanDefinition来创建Bean对象,里面有很多的属性用来描述Bean。
<bean id="userDao" class="com.kjz.dao.impl.UserDaoImpl" lazy-init="true"/>
<bean id="userService" class="com.kjz.service.UserServiceImpl" scope="singleton">
<property name="userDao" ref="userDao"></property>
</bean>

- getBeanClassName:获取bean 的类名
- getInitMethodName:获取初始化方法名称
- getProperryValues:获取bean 的属性值
- getScope:获取作用域
- isLazyInit:是否延迟初始化
Bean的生命周期:
- 通过BeanDefinition获取bean的定义信息
- 调用构造函数实例化bean
- bean的依赖注入
- 处理Aware接口(BeanNameAware、BeanFactoryAware、ApplicationContextAware)
- Bean的后置处理器BeanPostProcessor-前置
- 初始化方法(InitializingBean、init-method)
- Bean的后置处理器BeanPostProcessor-后置
- 销毁bean

循环依赖
循环引用

在创建A对象的同时需要使用的B对象,在创建B对象的同时需要使用到A对象,因此形成了一个死循环。
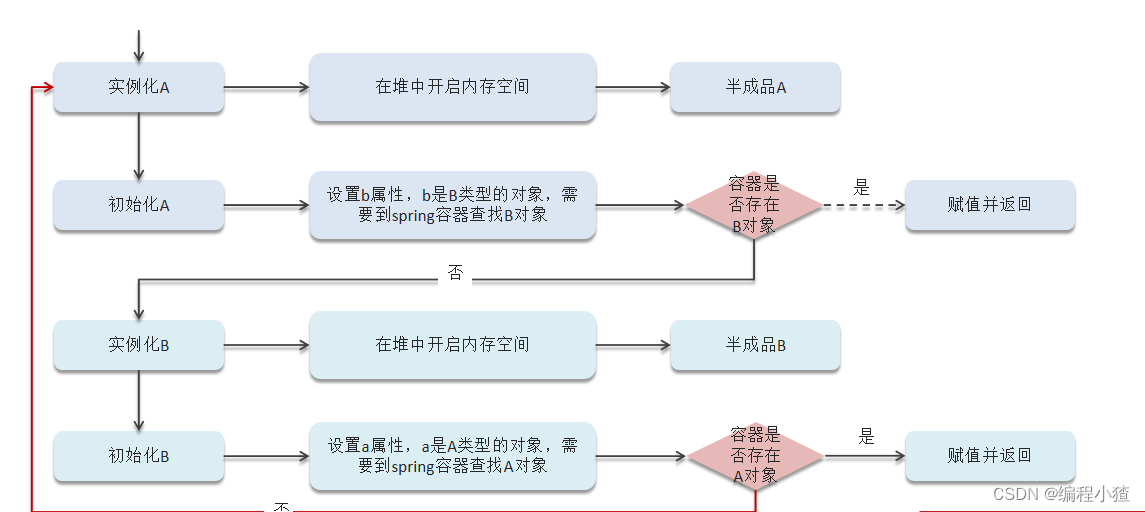
三级缓存
Spring解决循环依赖是通过三级缓存,对应的三级缓存如下所示:

| 缓存名称 | 对应类 | 作用 |
| 一级缓存 | singletonObjects | 单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象 |
| 二级缓存 | earlySingletonObjects | 缓存早期的bean对象(生命周期还没走完) |
| 三级缓存 | singletonFactories | 缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的 |
一级缓存
作用:限制bean在beanFactory中只存一份,即实现singleton scope,解决不了循环依赖
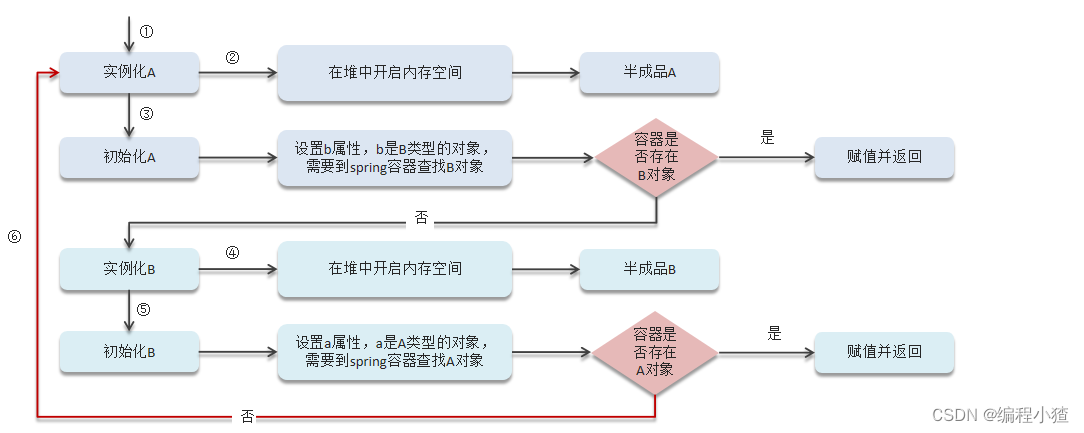
二级缓存
如果要想打破循环依赖, 就需要一个中间人的参与, 这个中间人就是二级缓存。
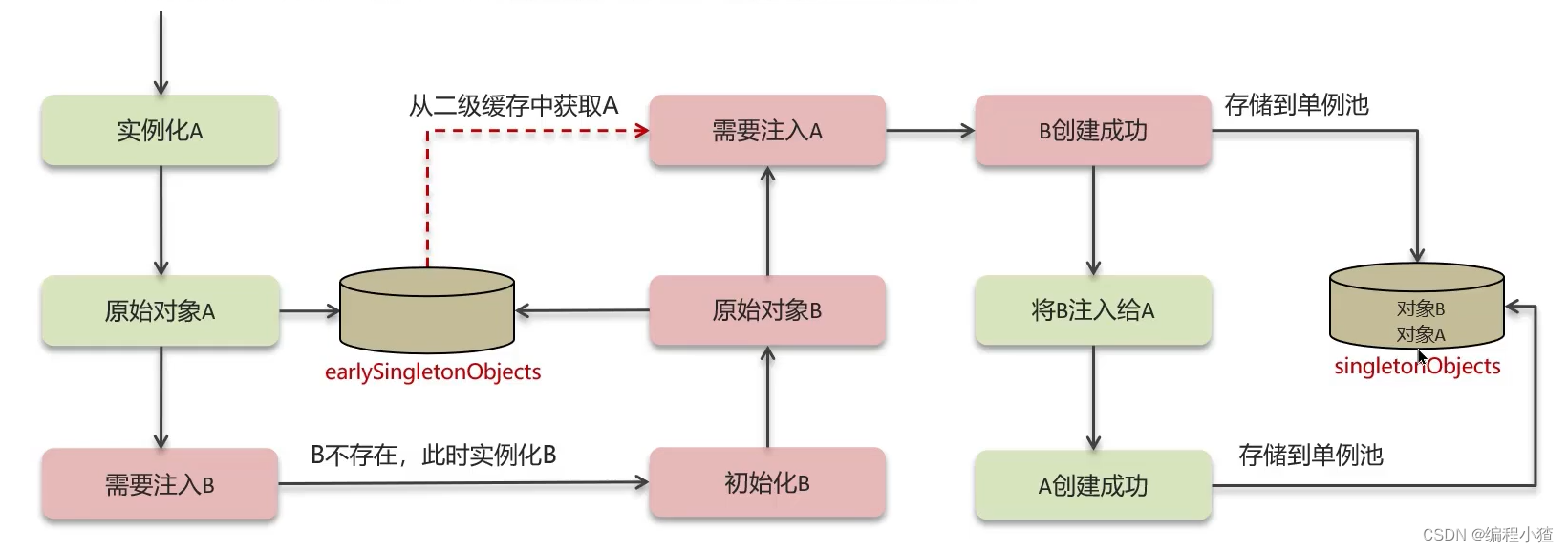
但是如果被实例化的对象是一个代理对象的话,如果只使用二级缓存,那么存入单例池的对象就不是代理对象,这时候就需要使用三级缓存了
三级缓存
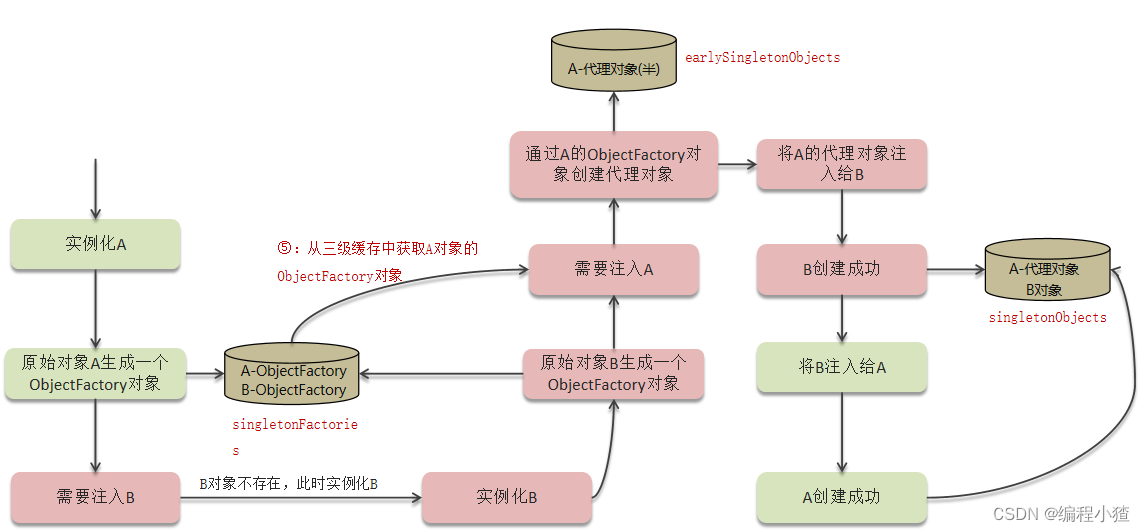
A的ObjectFactory对象能够生成A的普通对象或者代理对象,singletonFactories对象是用于存储ObjectFactory的。
构造方法的循环依赖
三级缓存帮我们解决了绝大部分的循环依赖问题,但是还是有少部分的循环依赖问题需要我们手动来解决,比如说构造方法的循环依赖。
下面举一个例子
@Componentpublic class A {
// B成员变量
private B b;
public A(B b){
System.out.println("A的构造方法执行了...");
this.b = b ;
}
}
@Component
public class B {
// A成员变量
private A a;
public B(A a){
System.out.println("B的构造方法执行了...");
this.a = a ;
}
}
报错信息:

解决:
public A(@Lazy B b){
System.out.println("A的构造方法执行了...");
this.b = b ;]
}
使用延时加载注解,也就是说:通过在构造器参数中标识@Lazy注解,Spring 生成并返回了一个代理对象,因此给A注入的B并非真实对象而是其代理。
Spring常见的注解
| 注解 | 说明 |
| @Component、@Controller、@Service、@Repository | 使用在类上用于实例化Bean |
| @Autowired | 使用在字段上用于根据类型依赖注入 |
| @Qualifier | 结合@Autowired一起使用用于根据名称进行依赖注入 |
| @Scope | 标注Bean的作用范围 |
| @Configuration | 指定当前类是一个 Spring 配置类,当创建容器时会从该类上加载注解 |
| @ComponentScan | 用于指定 Spring 在初始化容器时要扫描的包 |
| @Bean | 使用在方法上,标注将该方法的返回值存储到Spring容器中 |
| @Import | 使用@Import导入的类会被Spring加载到IOC容器中 |
| @Aspect、@Before、@After、@Around、@Pointcut | 用于切面编程(AOP) |
SpringMVC
执行流程
视图阶段(老旧JSP等)

- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet。
- DispatcherServlet调用HandlerAdapter(处理器适配器)
- HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
- Controller执行完成返回ModelAndView对象
- HandlerAdapter将Controller执行结果ModelAndView返回给DispatcherServlet
- DispatcherServlet将ModelAndView传给ViewReslover(视图解析器)
- ViewReslover解析后返回具体View(视图)
- DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet响应用户
前后端分离阶段(接口开发,异步)
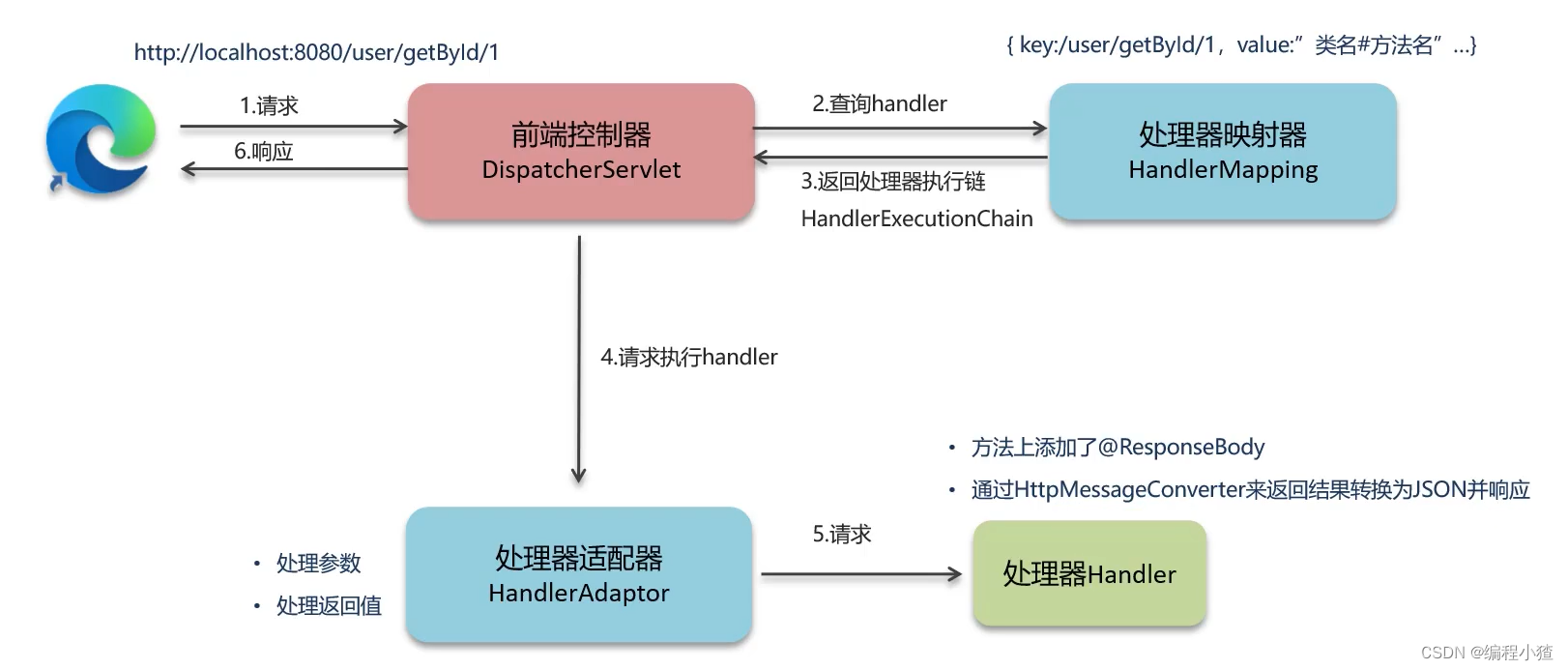
- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet。
- DispatcherServlet调用HandlerAdapter(处理器适配器)
- HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
- 方法上添加了@ResponseBody
- 通过HttpMessageConverter来返回结果转换为JSON并响应
SpringMVC常见的注解
| 注解 | 说明 |
| @RequestMapping | 用于映射请求路径,可以定义在类上和方法上。用于类上,则表示类中的所有的方法都是以该地址作为父路径 |
| @RequestBody | 注解实现接收http请求的json数据,将json转换为java对象 |
| @RequestParam | 指定请求参数的名称 |
| @PathViriable | 从请求路径下中获取请求参数(/user/{id}),传递给方法的形式参数 |
| @ResponseBody | 注解实现将controller方法返回对象转化为json对象响应给客户端 |
| @RequestHeader | 获取指定的请求头数据 |
| @RestController | @Controller + @ResponseBody |
Springboot
自动配置原理

Ctrl+B跟进查看@SpringBootApplication注解源码,发现@SpringBootApplication注解由以下注解组成。

其中的@EnableAutoConfiguration注解就是SpringBoot实现自动化配置的核心注解。
我们再Ctrl+B跟进查看@EnableAutoConfiguration源码。
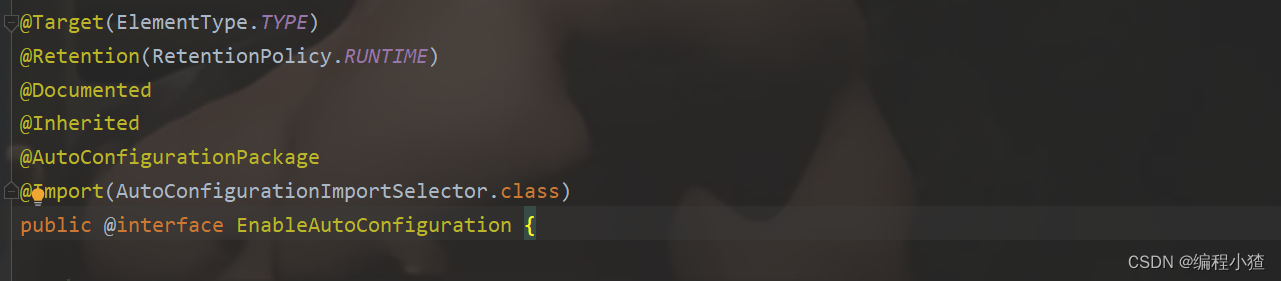
我们发现有一个@Import(AutoConfigurationImportSelector.class)注解,这个注解的作用是将指定的类作为组件导入到Spring Boot应用程序的自动配置中。在这个特定的注解中,使用了AutoConfigurationImportSelector类作为参数。这个类实现了ImportSelector接口,它负责选择要导入的配置类。AutoConfigurationImportSelector类会根据一些规则从classpath下的META-INF/spring.factories文件中加载所有的自动配置类(这个自动装配类的来源就是poom.xml文件中引入的依赖),并进行筛选和排序。然后,根据这些自动配置类的顺序,将它们逐个导入到应用程序的自动配置中。
SpringBoot常见的注解
| 注解 | 说明 |
| @SpringBootConfiguration | 组合了- @Configuration注解,实现配置文件的功能 |
| @EnableAutoConfiguration | 打开自动配置的功能,也可以关闭某个自动配置的选 |
| @ComponentScan | Spring组件扫描 |
Mybatis
执行流程

1.读取MyBatis的核心配置文件。mybatis-config.xml为MyBatis的全局配置文件,用于配置数据库连接、属性、类型别名、类型处理器、插件、环境配置、映射器(mapper.xml)等信息,这个过程中有一个比较重要的部分就是映射文件其实是配在这里的;这个核心配置文件最终会被封装成一个Configuration对象
2.加载映射文件。映射文件即SQL映射文件,该文件中配置了操作数据库的SQL语句,映射文件是在mybatis-config.xml中加载;可以加载多个映射文件。常见的配置的方式有两种,一种是package扫描包,一种是mapper找到配置文件的位置。
<!-- 使用包路径,扫描包下所有的接口,这种方式比较方便 -->
<package name="com.mybatis.demo"/>
<!-- resource:使用相对路径的资源引用-->
<!-- url:使用绝对类路径的资源引用-->
<!-- class:使用映射器接口实现类的完全限定类名-->
<mapper resource="xxx.xml"/>
3.构造会话工厂获取SqlSessionFactory。这个过程其实是用建造者设计模式使用SqlSessionFactoryBuilder对象构建的,SqlSessionFactory的最佳作用域是应用作用域。
//2. 创建SqlSessionFactory对象实际创建的是DefaultSqlSessionFactory对象
SqlSessionFactory builder = new SqlSessionFactoryBuilder().build(inputStream);
4.创建会话对象SqlSession。由会话工厂创建SqlSession对象,对象中包含了执行SQL语句的所有方法,每个线程都应该有它自己的 SqlSession 实例。SqlSession的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。
//3. 创建SqlSession对象实际创建的是DefaultSqlSession对象
SqlSession sqlSession = builder.openSession();
5.Executor执行器。是MyBatis的核心,负责SQL语句的生成和查询缓存的维护,它将根据SqlSession传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护
- SimpleExecutor – SIMPLE 就是普通的执行器。
- ReuseExecutor-执行器会重用预处理语句(PreparedStatements)
- BatchExecutor --它是批处理执行器
6.MappedStatement对象。MappedStatement是对解析的SQL的语句封装,一个MappedStatement代表了一个sql语句标签,如下:
<!--一个动态sql标签就是一个`MappedStatement`对象-->
<select id="selectUserList" resultType="com.mybatis.User">
select * from t_user
</select>
7.输入参数映射。输入参数类型可以是基本数据类型,也可以是Map、List、POJO类型复杂数据类型,这个过程类似于JDBC的预编译处理参数的过程,有两个属性 parameterType和parameterMap
8.封装结果集。可以封装成多种类型可以是基本数据类型,也可以是Map、List、POJO类型复杂数据类型。封装结果集的过程就和JDBC封装结果集是一样的。也有两个常用的属性resultType和resultMap。
我们再来看一下这个完整的执行步骤,代码如下:
public class MybatisTest {
public static void main(String[]args) throws Exception {
// 1.加载配置文件
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
//2. 创建SqlSessionFactory对象实际创建的是DefaultSqlSessionFactory对象
SqlSessionFactory builder = new SqlSessionFactoryBuilder().build(inputStream);
//3. 创建SqlSession对象实际创建的是DefaultSqlSession对象
SqlSession sqlSession = builder.openSession();
//4. 创建代理对象
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//5. 执行查询语句
List<User> users = mapper.selectUserList();
//6. 释放资源
sqlSession.close();
inputStream.close();
}
}
延迟加载
什么是延迟加载
当我们在使用MyBatis进行数据库查询时,通常会使用一种称为“立即加载”的方式。这意味着当查询主对象时,MyBatis会立即加载该对象及其关联对象的所有数据。但是,有时关联对象的数据可能会很大,而且并不一定每次都需要完整加载所有的关联对象数据。这就是延迟加载的作用。
延迟加载是一种性能优化技术,它允许在需要的时候才去加载关联对象的数据,而不是在查询主对象时就一次性加载所有关联对象。这样可以避免不必要的数据库查询,提高查询性能和减轻数据库负载。
下面举个例子说明一下
有两个表,分别是用户表和订单表。表的结构如下:

查询用户的时候,把用户所属的订单数据也查询出来,这个是立即加载。
查询用户的时候,暂时不查询订单数据,当需要订单的时候,再查询订单,这个就是延迟加载。
如何开启延迟加载
局部开启
配置 MyBatis 的 Mybatis.config.xml 文件
在需要应用延迟加载的关联对象的映射文件中,使用 <association> 或 <collection> 元素来定义关联关系。在这些元素上添加 fetchType="lazy" 属性,以指定延迟加载模式。例如:
resultMap id="userResultMap" type="User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<association property="role" javaType="Role" fetchType="lazy">
<id property="id" column="role_id"/>
<result property="name" column="role_name"/>
</association>
</resultMap>全局开启
方法一
配置 MyBatis 的配置文件。
在 MyBatis 的配置文件中,需要添加以下配置项,以启用延迟加载的支持:
<configuration>
<!-- 其他配置项 -->
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
</settings>
</configuration>方法二
配置spring的配置文件
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydatabase
username: username
password: password
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
lazy-loading-enabled: true适合开启延迟加载的场景
- 关联对象的数据量较大:当关联对象的数据量较大时,开启延迟加载可以避免一次性加载所有的关联对象数据,减少不必要的数据库查询和网络开销。特别是在一对多或多对多的关联关系中,延迟加载可以显著减少数据库查询次数和数据传输量,提高系统的性能。
- 访问关联对象数据比较少:当我们在查询主对象时,并不总是需要获取关联对象的所有数据。如果只有在实际需要使用关联对象数据时才加载,可以避免不必要的数据提取和传输,减少内存消耗,并提高系统的运行效率。
- 页面分页查询:在分页查询时,开启延迟加载可以避免一次性加载所有的关联对象数据。只有在需要显示关联对象数据的当前页时才加载,可以提高查询性能和用户体验。这种场景下,延迟加载可以很好地配合分页查询,避免查询大量的数据造成性能 bottleneck。
- 嵌套查询较深的情况:当查询的对象存在多层嵌套关系时,开启延迟加载可以避免层层递归查询造成的性能问题。只有在需要使用关联对象数据时才加载,可以减少多次递归查询的开销。
延迟加载的原理
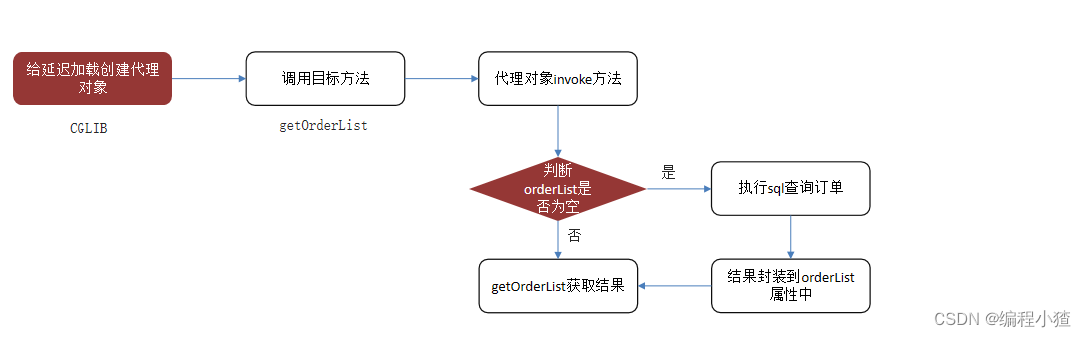
- 使用CGLIB创建目标对象的代理对象
- 当调用目标方法user.getOrderList()时,进入拦截器invoke方法,发现user.getOrderList()是null值,执行sql查询order列表
- 把order查询上来,然后调用user.setOrderList(List<Order> orderList) ,接着完成user.getOrderList()方法的调用
一二级缓存
一级缓存
基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当Session进行flush或close之后,该Session中的所有Cache就将清空,默认打开一级缓存。
下面进行一个测试证明
@Test
public void testSelectById() throws IOException {
//1. 加载mybatis的核心配置文件,获取 SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象,用它来执行sql
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 执行sql
//3.1 获取UserMapper接口的代理对象
UserMapper userMapper1 = sqlSession.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession.getMapper(UserMapper.class);
User user = userMapper1.selectById(6);
System.out.println(user);
System.out.println("---------------------");
User user1 = userMapper2.selectById(6);
System.out.println(user1);
//4.关闭资源
sqlSession.close();
}控制台信息如下

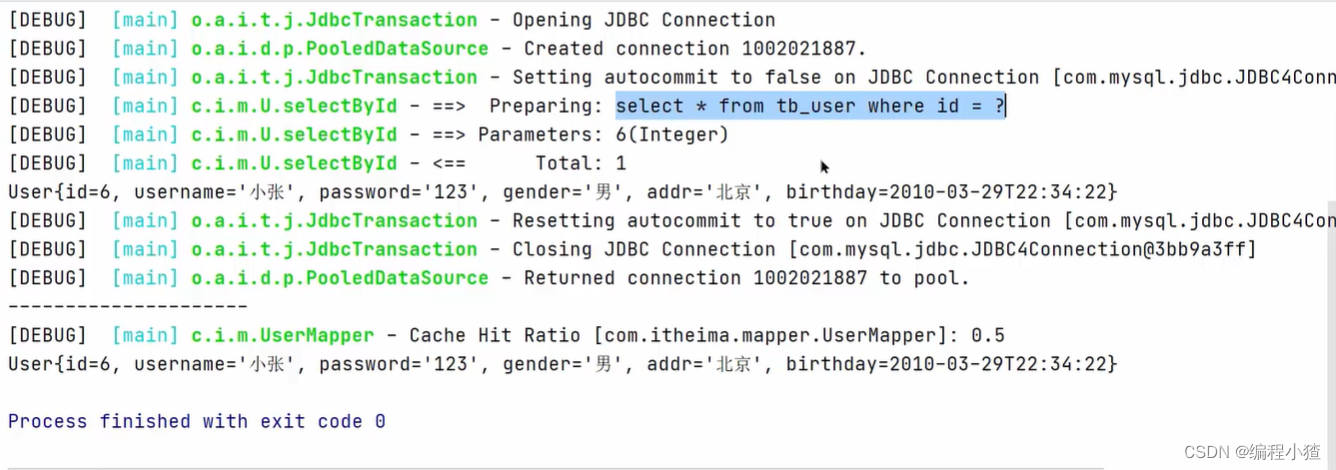
只打印了一次sql语句,说明只进行了一次sql查询。由此可以证明在第一次查询时会把得到的结果放到本地缓存中,在第二次查询时,就会直接到本地缓存中取。
二级缓存
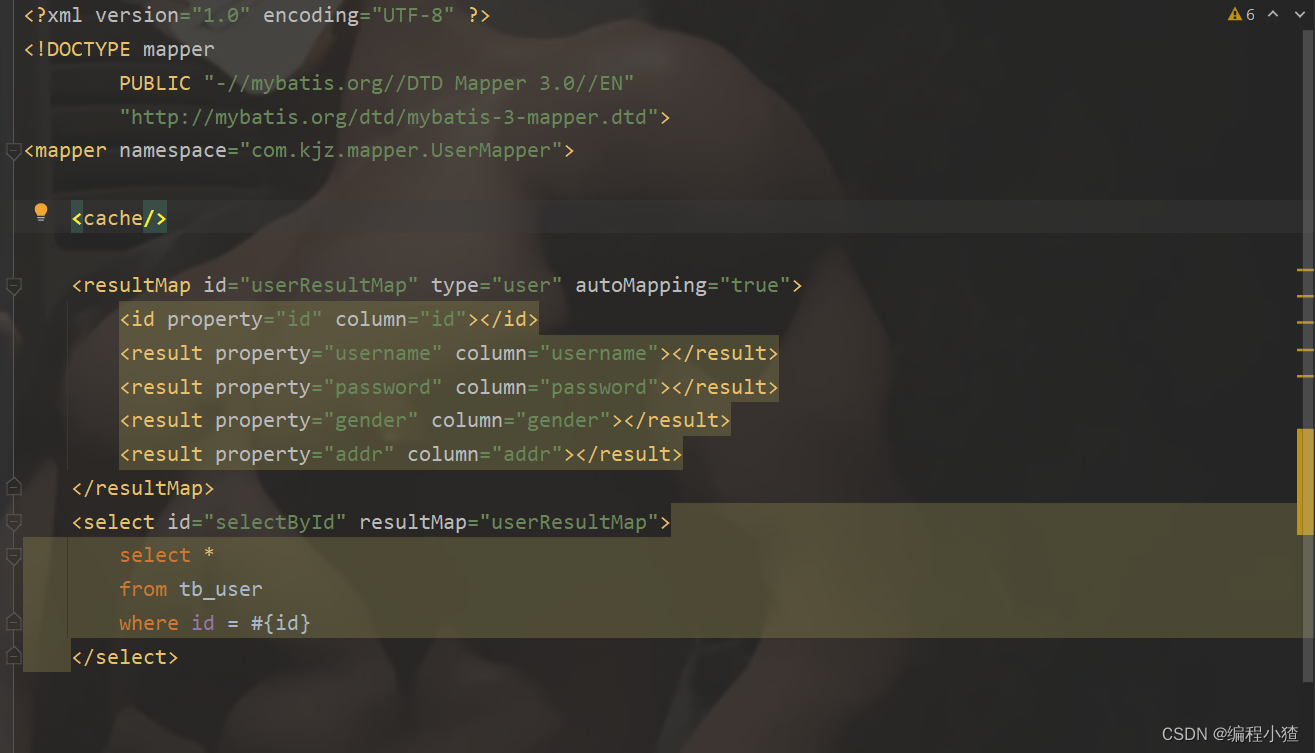
二级缓存是基于namespace和mapper的作用域起作用的,不是依赖于SQL session,默认也是采用 PerpetualCache,HashMap 存储。
二级缓存默认是关闭的。
开启方式,两步:
1,全局配置文件
<settings>
<setting name="cacheEnabled" value="true
</settings>
2,映射文件
使用<cache/>标签让当前mapper生效二级缓存
下面进行一个测试证明
@Test
public void testSelectById2() throws IOException {
//1. 加载mybatis的核心配置文件,获取 SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象,用它来执行sql
SqlSession sqlSession1 = sqlSessionFactory.openSession();
//3. 执行sql
//3.1 获取UserMapper接口的代理对象
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
User user1 = userMapper1.selectById(6);
System.out.println(user1);
sqlSession1.close();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
System.out.println("---------------------");
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
User user2 = userMapper2.selectById(6);
System.out.println(user2);
//4.关闭资源
sqlSession2.close();
}控制台如下:
面试题实例问答
框架篇面试题-参考回答
面试官:Spring框架中的单例bean是线程安全的吗?
候选人:
嗯!
不是线程安全的,是这样的
当多用户同时请求一个服务时,容器会给每一个请求分配一个线程,这是多个线程会并发执行该请求对应的业务逻辑(成员方法),如果该处理逻辑中有对该单列状态的修改(体现为该单例的成员属性),则必须考虑线程同步问题。
Spring框架并没有对单例bean进行任何多线程的封装处理。关于单例bean的线程安全和并发问题需要开发者自行去搞定。
比如:我们通常在项目中使用的Spring bean都是不可可变的状态(比如Service类和DAO类),所以在某种程度上说Spring的单例bean是线程安全的。
如果你的bean有多种状态的话(比如 View Model对象),就需要自行保证线程安全。最浅显的解决办法就是将多态bean的作用由“singleton”变更为“prototype”。
面试官:什么是AOP
候选人:
aop是面向切面编程,在spring中用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取公共模块复用,降低耦合,一般比如可以做为公共日志保存,事务处理等
面试官:你们项目中有没有使用到AOP
候选人:
我们当时在后台管理系统中,就是使用aop来记录了系统的操作日志
主要思路是这样的,使用aop中的环绕通知+切点表达式,这个表达式就是要找到要记录日志的方法,然后通过环绕通知的参数获取请求方法的参数,比如类信息、方法信息、注解、请求方式等,获取到这些参数以后,保存到数据库
面试官:Spring中的事务是如何实现的
候选人:
spring实现的事务本质就是aop完成,对方法前后进行拦截,在执行方法之前开启事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
面试官:Spring中事务失效的场景有哪些
候选人:
嗯!这个在项目中之前遇到过,我想想啊
第一个,如果方法上异常捕获处理,自己处理了异常,没有抛出,就会导致事务失效,所以一般处理了异常以后,别忘了跑出去就行了
第二个,如果方法抛出检查异常,如果报错也会导致事务失效,最后在spring事务的注解上,就是@Transactional上配置rollbackFor属性为Exception,这样别管是什么异常,都会回滚事务
第三,我之前还遇到过一个,如果方法上不是public修饰的,也会导致事务失效
嗯,就能想起来那么多
面试官:Spring的bean的生命周期
候选人:
嗯!,这个步骤还是挺多的,我之前看过一些源码,它大概流程是这样的
首先会通过一个非常重要的类,叫做BeanDefinition获取bean的定义信息,这里面就封装了bean的所有信息,比如,类的全路径,是否是延迟加载,是否是单例等等这些信息
在创建bean的时候,第一步是调用构造函数实例化bean
第二步是bean的依赖注入,比如一些set方法注入,像平时开发用的@Autowire都是这一步完成
第三步是处理Aware接口,如果某一个bean实现了Aware接口就会重写方法执行
第四步是bean的后置处理器BeanPostProcessor,这个是前置处理器
第五步是初始化方法,比如实现了接口InitializingBean或者自定义了方法init-method标签或@PostContruct
第六步是执行了bean的后置处理器BeanPostProcessor,主要是对bean进行增强,有可能在这里产生代理对象
最后一步是销毁bean
面试官:Spring中的循环引用
候选人:
嗯,好的,我来解释一下
循环依赖:循环依赖其实就是循环引用,也就是两个或两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于A
循环依赖在spring中是允许存在,spring框架依据三级缓存已经解决了大部分的循环依赖
①一级缓存:单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象
②二级缓存:缓存早期的bean对象(生命周期还没走完)
③三级缓存:缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的
面试官:那具体解决流程清楚吗?
候选人:
第一,先实例A对象,同时会创建ObjectFactory对象存入三级缓存singletonFactories
第二,A在初始化的时候需要B对象,这个走B的创建的逻辑
第三,B实例化完成,也会创建ObjectFactory对象存入三级缓存singletonFactories
第四,B需要注入A,通过三级缓存中获取ObjectFactory来生成一个A的对象同时存入二级缓存,这个是有两种情况,一个是可能是A的普通对象,另外一个是A的代理对象,都可以让ObjectFactory来生产对应的对象,这也是三级缓存的关键
第五,B通过从通过二级缓存earlySingletonObjects 获得到A的对象后可以正常注入,B创建成功,存入一级缓存singletonObjects
第六,回到A对象初始化,因为B对象已经创建完成,则可以直接注入B,A创建成功存入一次缓存singletonObjects
第七,二级缓存中的临时对象A清除
面试官:构造方法出现了循环依赖怎么解决?
候选人:
由于bean的生命周期中构造函数是第一个执行的,spring框架并不能解决构造函数的的依赖注入,可以使用@Lazy懒加载,什么时候需要对象再进行bean对象的创建
面试官:SpringMVC的执行流程知道嘛
候选人:
嗯,这个知道的,它分了好多步骤
1、用户发送出请求到前端控制器DispatcherServlet,这是一个调度中心
2、DispatcherServlet收到请求调用HandlerMapping(处理器映射器)。
3、HandlerMapping找到具体的处理器(可查找xml配置或注解配置),生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet。
4、DispatcherServlet调用HandlerAdapter(处理器适配器)。
5、HandlerAdapter经过适配调用具体的处理器(Handler/Controller)。
6、Controller执行完成返回ModelAndView对象。
7、HandlerAdapter将Controller执行结果ModelAndView返回给DispatcherServlet。
8、DispatcherServlet将ModelAndView传给ViewReslover(视图解析器)。
9、ViewReslover解析后返回具体View(视图)。
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
11、DispatcherServlet响应用户。
当然现在的开发,基本都是前后端分离的开发的,并没有视图这些,一般都是handler中使用Response直接结果返回
面试官:Springboot自动配置原理
候选人:
嗯,好的,它是这样的。
在Spring Boot项目中的引导类上有一个注解@SpringBootApplication,这个注解是对三个注解进行了封装,分别是:
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan
其中
@EnableAutoConfiguration是实现自动化配置的核心注解。该注解通过
@Import注解导入对应的配置选择器。关键的是内部就是读取了该项目和该项目引用的Jar包的的classpath路径下META-INF/spring.factories文件中的所配置的类的全类名。在这些配置类中所定义的Bean会根据条件注解所指定的条件来决定是否需要将其导入到Spring容器中。
一般条件判断会有像
@ConditionalOnClass这样的注解,判断是否有对应的class文件,如果有则加载该类,把这个配置类的所有的Bean放入spring容器中使用。面试官:Spring 的常见注解有哪些?
候选人:
嗯,这个就很多了
第一类是:声明bean,有@Component、@Service、@Repository、@Controller
第二类是:依赖注入相关的,有@Autowired、@Qualifier、@Resourse
第三类是:设置作用域 @Scope
第四类是:spring配置相关的,比如@Configuration,@ComponentScan 和 @Bean
第五类是:跟aop相关做增强的注解 @Aspect,@Before,@After,@Around,@Pointcut
面试官:SpringMVC常见的注解有哪些?
候选人:
嗯,这个也很多的
有@RequestMapping:用于映射请求路径;
@RequestBody:注解实现接收http请求的json数据,将json转换为java对象;
@RequestParam:指定请求参数的名称;
@PathViriable:从请求路径下中获取请求参数(/user/{id}),传递给方法的形式参数;@ResponseBody:注解实现将controller方法返回对象转化为json对象响应给客户端。@RequestHeader:获取指定的请求头数据,还有像@PostMapping、@GetMapping这些。
面试官:Springboot常见注解有哪些?
候选人:
嗯~~
Spring Boot的核心注解是@SpringBootApplication , 他由几个注解组成 :
@SpringBootConfiguration: 组合了- @Configuration注解,实现配置文件的功能;
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项
@ComponentScan:Spring组件扫描
面试官:MyBatis执行流程
候选人:
好,这个知道的,不过步骤也很多
①读取MyBatis配置文件:mybatis-config.xml加载运行环境和映射文件
②构造会话工厂SqlSessionFactory,一个项目只需要一个,单例的,一般由spring进行管理
③会话工厂创建SqlSession对象,这里面就含了执行SQL语句的所有方法
④操作数据库的接口,Executor执行器,同时负责查询缓存的维护
⑤Executor接口的执行方法中有一个MappedStatement类型的参数,封装了映射信息
⑥输入参数映射
⑦输出结果映射
面试官:Mybatis是否支持延迟加载?
候选人:
是支持的~
延迟加载的意思是:就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。
Mybatis支持一对一关联对象和一对多关联集合对象的延迟加载
在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false,默认是关闭的
面试官:延迟加载的底层原理知道吗?
候选人:
嗯,我想想啊
延迟加载在底层主要使用的CGLIB动态代理完成的
第一是,使用CGLIB创建目标对象的代理对象,这里的目标对象就是开启了延迟加载的mapper
第二个是当调用目标方法时,进入拦截器invoke方法,发现目标方法是null值,再执行sql查询
第三个是获取数据以后,调用set方法设置属性值,再继续查询目标方法,就有值了
面试官:Mybatis的一级、二级缓存用过吗?
候选人:
嗯~~,用过的~
mybatis的一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当Session进行flush或close之后,该Session中的所有Cache就将清空,默认打开一级缓存
关于二级缓存需要单独开启
二级缓存是基于namespace和mapper的作用域起作用的,不是依赖于SQL session,默认也是采用 PerpetualCache,HashMap 存储。
如果想要开启二级缓存需要在全局配置文件和映射文件中开启配置才行。
面试官:Mybatis的二级缓存什么时候会清理缓存中的数据
候选人:
嗯!!
当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了新增、修改、删除操作后,默认该作用域下所有 select 中的缓存将被 clear。