文章目录
- 一、Unicode字符集与U8/U16/U32编码
- 二、编码
- 1. 占字节数
- 2. ASCII、GB2312、GBK、GB18030 以及 UTF8 的关系
- 3. BOM
- 4. UTF-8的存储实现
- 三、编译器字符集设置
- 1. GCC
- 语法
- Example
- 2. MSVC
- 语法
- Example
- 三、wchar_t
- 五、编码转换函数
- 六、代码 & 实践
- 1. UTF8与UTF16、UTF32的转换
- 2. GBK与UTF16的转换
- 七、参考资料 / 辅助网站
一、Unicode字符集与U8/U16/U32编码
Unicode 是国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换
Unicode 字符集的编码范围是 0x0000 - 0x10FFFF , 可以容纳一百多万个字符, 每个字符都有一个二进制数值和它对应,这个数值称为 码点 , 比如:汉字 “中” 的 码点是 0x4E2D, 大写字母 A 的码点是 0x41, 具体字符对应的 Unicode 编码可以查询 Unicode字符编码表
UTF-8、UTF-16、UTF-32编码是对Unicode字符集的实现,UTF的全称是Unicode Transformation Format,差别在于存储实现不同。
一个Unicode字符最多需要4个字节存储,但是如果每个字符都用4个字节存储,就会浪费很多空间,所以出现了U8、U16、U32的差异。
- UTF-8将Unicode字符按照变长存储,占1~6个字节;
- UTF-16将Unicode字符按照2个或4个字节存储;
- UTF-32将Unicode字符全部按照4个字节存储;
二、编码
1. 占字节数
注意ANSI和ASCII,ANSI是对ASCII的扩展。
不同地区对ANSI进行了不同的扩展,在中文windosw下,ANSI其实就代表GBK/GB2312/GB18030。在其他国家,比如日本就不一样了。
- ASCII字符占1个字节;
- U16一个汉字占2个字节;
- U32一个汉字占4个字节;
- U8常用汉字占3个字节;
- GBK和GB2312 每个汉字都占两个字节;
- GB18030 是变长多字节字符集,每个字或字符可以由一个,两个或四个字节组成;
2. ASCII、GB2312、GBK、GB18030 以及 UTF8 的关系
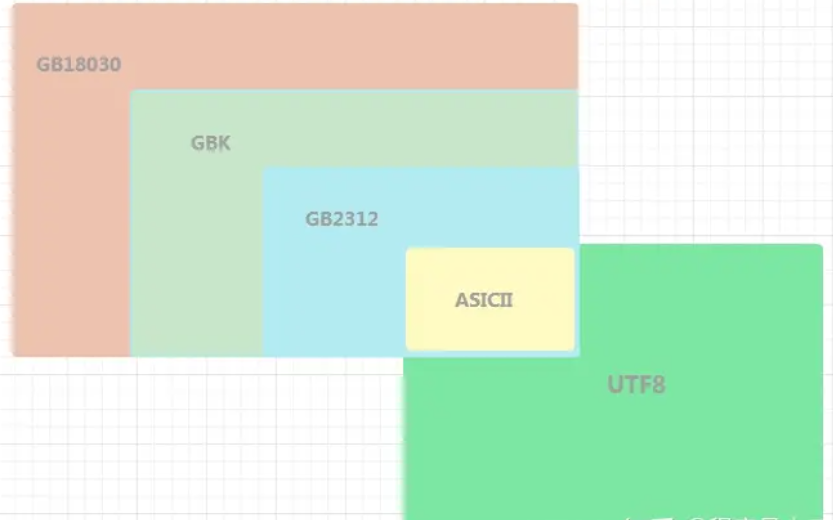
注意,UTF16、UTF32并不兼容ASCII,因为它们没有单字节编码。
3. BOM
BOM,全称Byte Order Mark,除了表示字节序外,还可以区分U8、U16、U32。
| 编码 | 16进制表示 | 10进制表示 | 解释为 Windows-1252 的字节 |
|---|---|---|---|
| UTF-8 | EF BB BF | 239 187 191 |  |
| UTF-16 (BE) | FE FF | 254 255 | þÿ |
| UTF-16 (LE) | FF FE | 255 254 | ÿþ |
| UTF-32 (BE) | 00 00 FE FF | 0 0 254 255 | ^@^@þÿ (^@ is the null character) |
| UTF-32 (LE) | FF FE 00 00 | 255 254 0 0 | ÿþ^@^@ (^@is the null character) |
(表格引自维基百科Byte order mark)
Unicode 标准允许UTF-8中的 BOM ,但不要求或建议使用它。字节顺序在 UTF-8 中没有意义,因此它在 UTF-8 中的唯一用途是在开始时发出信号,表明文本流是用 UTF-8 编码的,或者已转换为 UTF-8来自包含可选 BOM 的流。该标准也不建议删除 BOM,这样编码之间的往返就不会丢失信息,并且依赖它的代码可以继续工作。
(引自维基百科Byte order mark)
也就是说,windows下U8也可以用BOM,但是在其他平台不一定能被识别(GCC似乎也开始支持U8 BOM)。
4. UTF-8的存储实现
码点 ↔ UTF-8 的转换
| 第一个码点 | 最后一个码点 | 字节 1 | 字节 2 | 字节 3 | 字节 4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0xxxxxxx | —— | —— | —— |
| U+0080 | U+07FF | 110xxxxx | 10xxxxxx | —— | —— |
| U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | —— |
| U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
还有5、6字节的,维基百科没有列出,但Linux手册的utf-8可以查询到。
(表格引自维基百科UTF-8)
提醒:码点是字符在字符集中对应的二进制数值。
可以看到,当字符只需要一个字节就能表示时,UTF-8就只用一个字节存储,而且最高bit是0,这与ASCII也兼容。
需要几个字节编码,那么第一个字节的开头就有多少个连续的1,其余字节开头都用10表示( 我也不知道为什么)。
所以UTF-8下,
1个字节只能表示2^7个字符;
2个字节只能表示2^11个字符;
3个字节只能表示2^16个字符;
4个字节只能表示2^21个字符。
三、编译器字符集设置
1. GCC
-finput-charset=charset
Set the input character set, used for translation from the character set of the input file to the source
character set used by GCC. If the locale does not specify, or GCC cannot get this information from the
locale, the default is UTF-8. This can be overridden by either the locale or this command-line option.
Currently the command-line option takes precedence if there's a conflict. charset can be any encoding
supported by the system's "iconv" library routine.
-fexec-charset=charset
Set the execution character set, used for string and character constants. The default is UTF-8. charset
can be any encoding supported by the system's "iconv" library routine.
-fwide-exec-charset=charset
Set the wide execution character set, used for wide string and character constants. The default is UTF-32
or UTF-16, whichever corresponds to the width of "wchar_t". As with -fexec-charset, charset can be any
encoding supported by the system's "iconv" library routine; however, you will have problems with encodings
that do not fit exactly in "wchar_t".
语法
-finput-charset=charset
-fexec-charset=charset
Example
-finput-charset=gb2312
-finput-charset=gbk
-fexec-charset=utf-8
2. MSVC
源字符集是用于解释程序源文本的编码。它被转换为内部表示形式,用作编译前预处理阶段的输入。然后,内部表示形式将转换为执行字符集,以将字符串和字符值存储在可执行文件中。
当源文件包含基本源字符集中未表示的字符时,可以设置此选项指定要使用的扩展源字符集。
执行字符集是用于在所有预处理步骤之后输入到编译阶段的程序文本的编码。
该字符集用于编译代码中任何字符串或字符文字的内部表示。
设置此选项可指定当源文件包含基本执行字符集中无法表示的字符时要使用的扩展执行字符集。
(引自MSVC文档/execution-charset,/source-charset)
MSVC还有/validate-charset,详见官方文档。
语法
/source-charset:[IANA_name | .CPID]
/execution-charset:[IANA_name | .CPID]
如果要将源字符集和执行字符集都设置为UTF-8,可以使用
/utf-8*编译器选项作为快捷方式。
相当于/source-charset:utf-8 /execution-charset:utf-8在命令行上。
默认情况下,这些选项中的任何一个都会启用/validate-charset选项。
(该解释来自MSVC文档/execution-charset,/source-charset)
最后,有一个快捷开关
/utf-8,它同时设置了/source-charset:utf-8和/execution-charset:utf-8。
这些命令行选项与旧的#pragma setlocale和#pragma execution-character-set指令不兼容,它们全局应用于所有源文件。
对于停留在较早版本编译器上的用户,最好的选择仍然是使用BOM将源文件保存为UTF-8 (其他答案表明,IDE在保存时可以做到这一点)。编译器将自动检测到这一点,并进行适当的操作。GCC也是如此,他在源文件开始时也接受BOM,而不会窒息而死,因此这种方法在功能上是可移植的。
(引自MSVC++中的源字符集编码规范)
Example
/source-charset:utf-8
/source-charset:.65001
三、wchar_t
这个取决于系统。
wchar_t在Linux默认占4个字节,使用的是U32编码。
wchar_t在Windows默认占2个字节,使用的是U16编码。
Windows下的头文件<tchar.h>,定义了一些列的宽窄自动转换函数,如类型TCHAR、宏_T()和TEXT()。
在定义了_UNICODE宏和UNICODE宏时,会转为wchar_t相应的函数,在未定义时就转为char对应的函数。
windows的一些API也是如此,例如MessageBox()、MessageBoxA()、MessageBoxW()。
为了防止出现差异,需要保证UNICODE宏和_UNCIDEO宏 都定义或都不定义。
五、编码转换函数
- 待办
六、代码 & 实践
1. UTF8与UTF16、UTF32的转换
- 待办
2. GBK与UTF16的转换
- 待办
七、参考资料 / 辅助网站
-
一文读懂Unicode编码原理 - 一个汉字UTF8编码占用多少字节。
-
UTF8、UTF16编解码网站。
-
Codeblocks converting to execution character set: Illegal byte sequence错误解决办法
-
MSVC++中的源字符集编码规范
- /source-charset (Set source character set)
- New Options for Managing Character Sets in the Microsoft C/C++ Compiler
-
gcc中的-finput-charset和-fexec-charset开关
-
彻底搞明白 GB2312、GBK 和 GB18030
-
维基百科Byte order mark
-
GCC Manual
-
UTF8 UTF16 之间的互相转换
-
Unicode、UTF-8、UTF-16 终于懂了