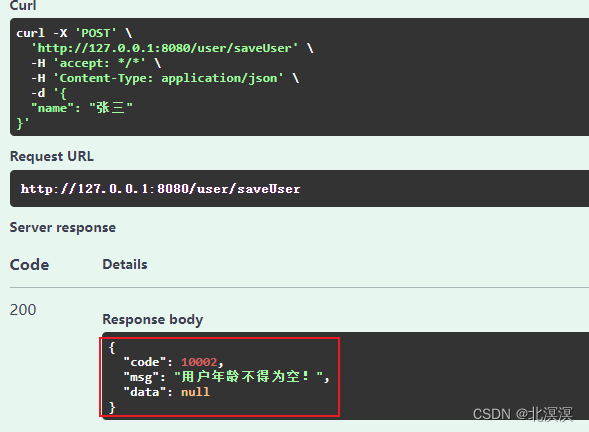
找出字符串中第一个匹配项的下标


思路分析:
- 思路一:直接调用String的API:indexOf
大道至简,String中的IndexOf是这样描述的:
/**
* Returns the index within this string of the first occurrence of the
* specified substring.
*
* <p>The returned index is the smallest value <i>k</i> for which:
* <blockquote><pre>
* this.startsWith(str, <i>k</i>)
* </pre></blockquote>
* If no such value of <i>k</i> exists, then {@code -1} is returned.
*
* @param str the substring to search for.
* @return the index of the first occurrence of the specified substring,
* or {@code -1} if there is no such occurrence.
*/
其中关于该API的描述与题目意思完全相符:返回指定子字符串第一次出现指定字符串的索引。
- 思路二:通过遍历字符串来解决
其实也就相当于自己实现indexOf函数,当然有暴力解法,举个例子:
needle:wlf
haystack:aswlfjqwlf

如上图,从前向后走,每个字母作为开头进行一次判断,如果当前字母相等,就向后走继续和目标字符串的下一个字母判断,如果走到某一个位置不相等,那就从之前判断起始位置那个字母的下一个字母判断。
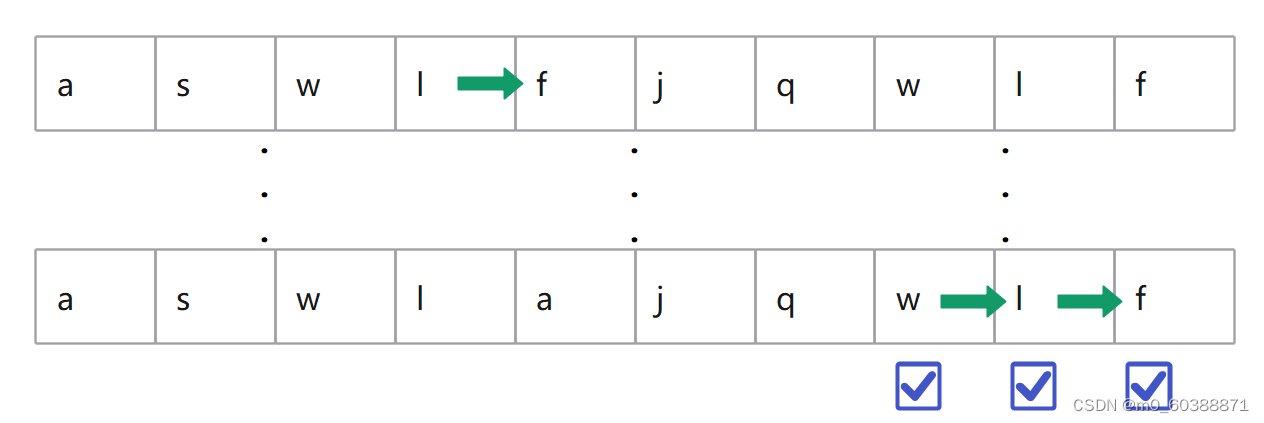
直到到达满足条件的位置。但是这样感觉时间复杂度太高,相当于O(MN),M和N分别未haystack和needle的字符串长度。
看一看String的IndexOf是如何实现的
测试用例:haystack = “sadbutsad”, needle = “sad”,下面是Debug进入的核心代码(附上了个人的一些理解):
/**
* Code shared by String and StringBuffer to do searches. The
* source is the character array being searched, and the target
* is the string being searched for.
*
* @param source the characters being searched.
也就是haystack
* @param sourceOffset offset of the source string.
初始偏移
* @param sourceCount count of the source string.
haystack长度
**********************下方三个参数为needle同理*********************
* @param target the characters being searched for.
* @param targetOffset offset of the target string.
* @param targetCount count of the target string.
* @param fromIndex the index to begin searching from.(从哪开始搜)
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
// 如果起始索引大于等于源字符数组的长度,且目标字符数组长度为0,返回源字符数组长度;
// 否则,返回-1表示未找到。
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
// 如果起始索引小于0,将其设置为0。
if (fromIndex < 0) {
fromIndex = 0;
}
// 如果目标字符数组长度为0,直接返回起始索引。
if (targetCount == 0) {
return fromIndex;
}
// 获取目标字符数组的第一个字符。
char first = target[targetOffset];
// 计算源字符数组最大的可比较范围。
int max = sourceOffset + (sourceCount - targetCount);
// 从指定起始索引开始,在源字符数组中查找目标字符数组的第一个字符。
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
// 如果当前位置的字符不等于目标字符数组的第一个字符,
// 则循环直到找到目标字符数组的第一个字符。
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
// 如果找到了目标字符数组的第一个字符,继续比较剩余部分。
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
// 如果整个目标字符数组都匹配,返回匹配的起始位置。
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
// 如果未找到,返回-1。
return -1;
}
可以看到实际上还是跟我们的思路二差不多的,所以就只贴上简化代码。
代码实现:
public static int strStr(String haystack, String needle) {
int ret = haystack.indexOf(needle);
return ret;
}
运行结果:

顺便推广一下个人公众号:

下一篇:KMP算法解决此题目,时间复杂度可以继续降低到O(M+N)


![WSL—子系统安装及其相关配置和[诸多报错问题]-修改默认安装位置](https://img-blog.csdnimg.cn/img_convert/a9112f44deb031dfa998847cfc60651d.png)