Java标准库提供了很多集合类,但有一些集合类是线程不安全的,也就是说,在多线程环境下可能会出问题的。常用的ArrayList,LinkedList,HashMap,PriorityQueue等都是线程不安全的(Vector, Stack, HashTable是线程安全的,但实际并不建议用),它们在单线程的环境下没有问题,但如果在多线程环境下尤其是多个线程操作同一个集合类对象时,就可能出现麻烦。
如果这些单线程中的集合类确实需要在多线程中使用,该怎么办呢?思路有两个:
- 最直接的方式:使用锁,手动保证。如多个线程修改ArrayList对象,此时就可能有问题,就可以给修改操作进行加锁。但手动加锁的方式并不是很方便,因此标准库还提供了一些线程安全的集合类。
- 使用JUC提供的线程安全版本的集合类。
本文就第二点:线程安全的集合类来展开说明。
目录
一、多线程环境使用顺序表
1、Vector
2、Collections.synchronizedList(new ArrayList)
3、CopyOnWriteArrayList
二、多线程环境使用队列
三、多线程使用哈希表
***HashTable和ConcurrentHashMap的区别
1、加锁粒度不同,ConcurrentHashMap锁粒度更小
2、ConcurrentHashMap能更充分地利用CAS机制
3、ConcurrentHashMap优化了扩容策略
四、相关问题总结
1、ConcurrentHashMap的读是否要加锁,为什么?
2、ConcurrentHashMap的锁分段技术?
3、ConcurrentHashMap在jdk1.8做了哪些优化?
4、Hashtable和HashMap、ConcurrentHashMap 之间的区别?
一、多线程环境使用顺序表
1、Vector
如果要使用ArrayList,可以用Vector来代替。
Vector功能上和ArrayList类似,是一个可以实现随机存取的顺序表,区别在于Vector的关键方法都是带有synchronized的,它比直接使用ArrayList更线程安全。
特别注意:虽然Vector线程安全,但它作为一个“上古时期”的集合类,实际上已经被Java官方标记为不推荐使用了。
2、Collections.synchronizedList(new ArrayList)
synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List,Collections.synchronizedList()可以理解成一个“壳”,使用这个“壳”套一下你想用的List集合类对象,它就可以让被套的集合类对象变成线程安全的。
原理也很简单:这个方法使得被包裹的集合类对象的关键操作都带上 synchronized。
这样一来,如果使用时不需要考虑线程安全,那么直接使用集合类对象本身(如new ArrayList)即可;如果要考虑线程安全,给原来的集合类对象套一个壳,套完壳之后对象里的各种方法还能继续用,而内部也会帮我们把锁加好。
3、CopyOnWriteArrayList
CopyOnWrite容器即写时拷贝的容器。CopyOnWriteArrayList则是一个基于ArrayList的支持写时拷贝的集合类。
写时拷贝容器与用加锁的思路不同,没有加锁而是通过多个线程修改不同变量这一方式实现线程安全的(出现线程安全问题的条件之一是多个线程修改同一变量,写时拷贝破坏了这个条件)。
当我们修改一个容器的时候,不直接修改当前容器本身,而是先将当前容器进行Copy, 复制出一个新的容器,然后对新的容器进行修改。修改完成之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为在当前容器上并不执行任何修改操作。
因此,CopyOnWrite容器也是一种读写分离的思想,读和写采用不同的容器。可以简单将写时拷贝理解为:一要修改的时候就拷贝一份,过程如下:

假设此时要把arr1中的2改为100:
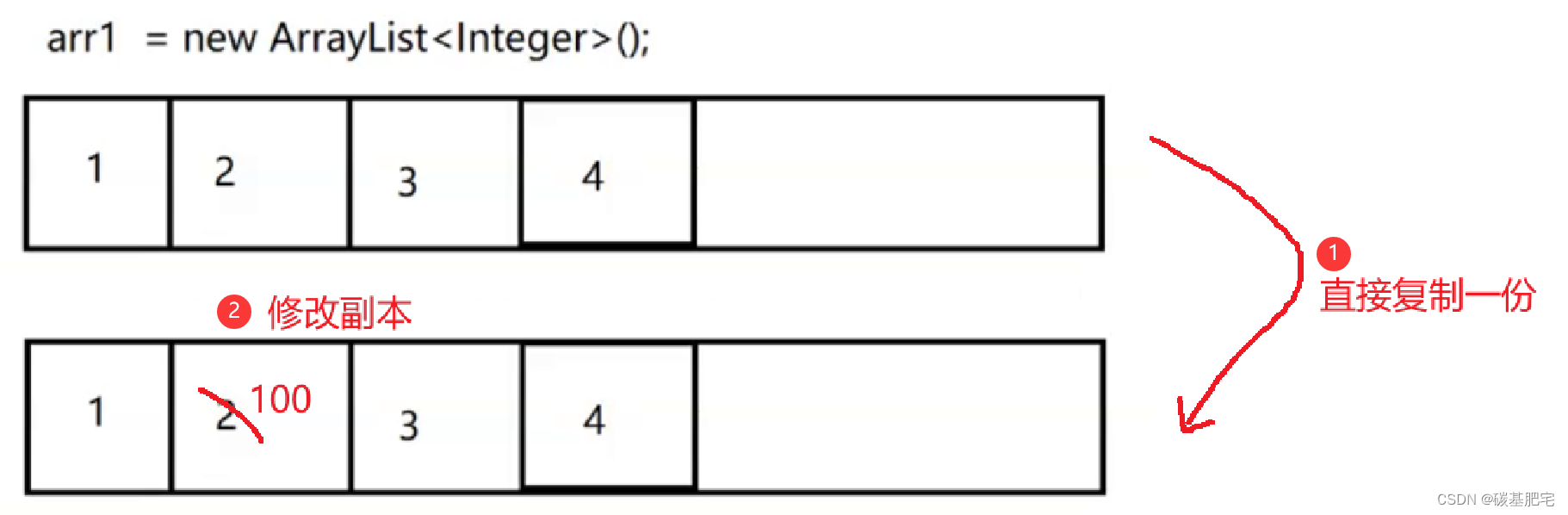
注意:在复制和修改副本时,别的线程如果读取arr1,读的还是旧的那一份内容。当已经对副本执行过修改操作后,直接将arr1指向副本内容,而旧的部分则被丢弃:

这样一来,修改操作就完成了。写时拷贝机制和顺序表的扩容操作有些类似,而由于这样的引用赋值操作本身就是原子的,写时拷贝就可以不用加锁也完成修改,保证线程安全。
写时拷贝机制也叫“双缓冲”,在日常中也是比较常见的。如显示器显示画面,也是通过上述类似的过程完成的。
我们知道,显示器中的画面是显卡来渲染的,显卡的任务就是不停地画图。如果显卡的频率为60hz,那就表示它1s要画60张图。
显卡在画图过程中显然是要消耗一定时间的,它的过程就类似于写时拷贝:显示器这边在显示上一张图,而显卡在偷偷地画下一张图;等到显卡的下一张画好了,来一个迅速的替换,这一显示器上的画面就到了下一帧。
由于换图的时候下一帧已经准备好了,所以整体的画面切换也就比较流畅。如果当前画面太复杂了(比如有4k分辨率的画面),而显卡又太烂跟不上,那它画图就画不过来了;如果在规定时间内没来得及画完,此时就可能出现掉帧或画面撕裂的情况(卡成PPT)。
CopyOnWriteArrayList的特点是虽然不加锁,没有锁竞争的开销,但是拷贝开销很大,因此适合于修改不频繁、元素个数少的场景。
二、多线程环境使用队列
多线程使用队列,直接有BlockingQueue:
1、BlockingQueue是一个接口,真正实现的类有:
- ArrayBlockingQueue:基于数组实现的阻塞队列。
- LinkedBlockingQueue:基于链表实现的阻塞队列。
- PriorityBlockingQueue:基于堆实现的带优先级的阻塞队列。
- TransferQueue:最多只包含一个元素的阻塞队列。
2、put 方法用于阻塞式的入队列,take 用于阻塞式的出队列。
3、BlockingQueue 也有 offer,poll,peek 等方法,但是这些方法不带有阻塞特性。
阻塞队列的经典应用是生产者消费者模型。具体介绍见:Java多线程基础-9:代码案例之阻塞队列
三、多线程使用哈希表
HashMap 本身不是线程安全的,在多线程环境下使用哈希表可以使用:
- HashTable
- ConcurrentHashMap
查看HashTable源码可知,它和上面的Vector类似,是直接给关键方法加synchronized(相当于给this加锁):
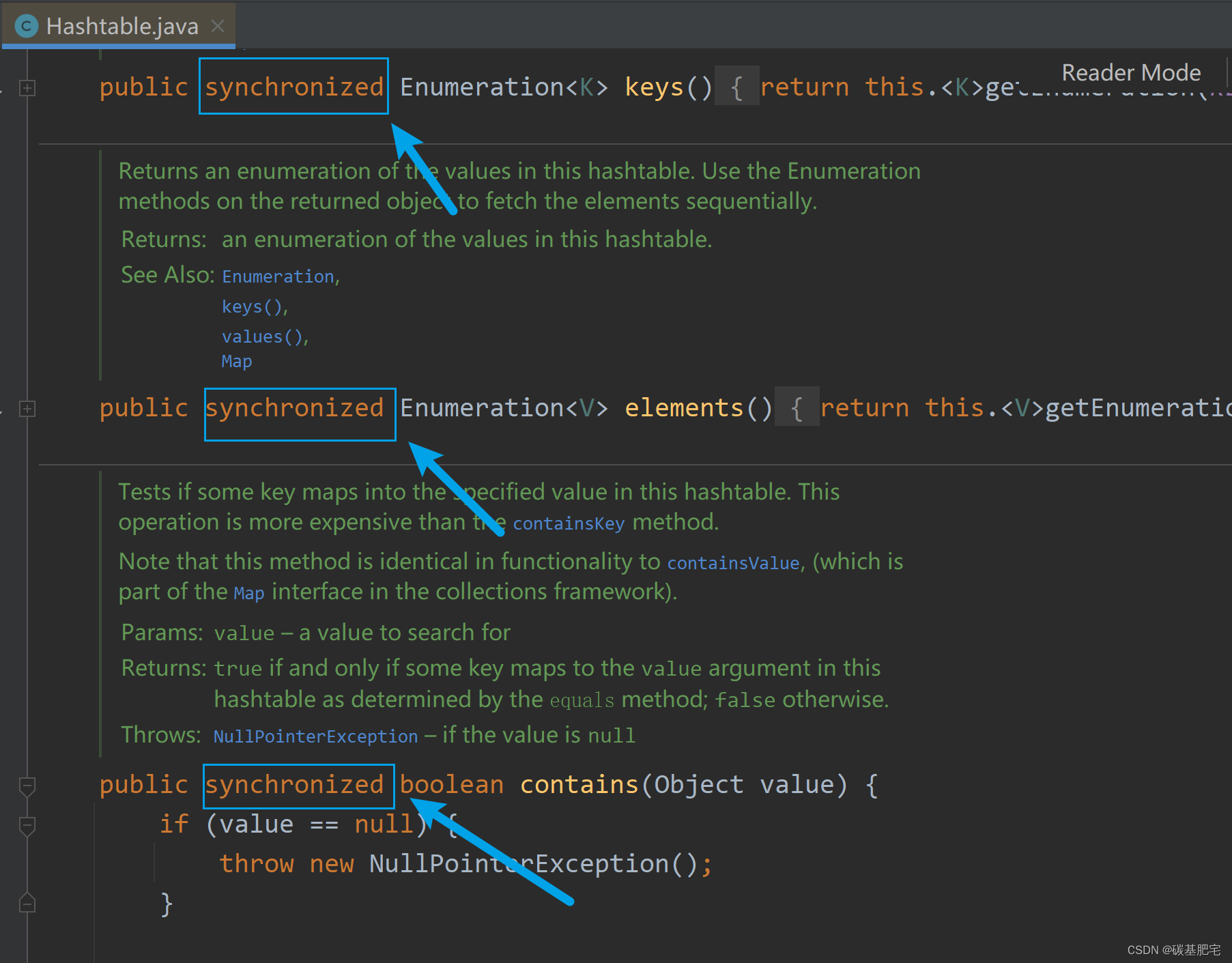
实际中HashTable并不是一个好的选择,ConcurrentHashMap是HashTable的全面升级版本,官方推荐使用。如果多线程中需要用到哈希表,应重点使用这个。
***HashTable和ConcurrentHashMap的区别
1、加锁粒度不同,ConcurrentHashMap锁粒度更小
锁粒度即加锁操作所涵盖的代码的范围,进一步可以引申出某个加锁操作触发锁冲突的频率。
HashTable是直接针对 Hashtable 对象本身加锁,也即对整个哈希表加锁,因此任何的增删改查操作都会触发加锁,也就都可能会有锁竞争。

我们知道,哈希表结构一般是数组+链表,插入元素到哈希表的流程是先根据key计算出hash值得到数组下标,然后把这个要插入的新元素挂在对应下标的链表上(Java的HashMap还会在链表太长的时候把链表变成红黑树)。
思考一个场景:此时如果有两个线程,分别要插入一个元素到哈希表中,线程1插入的元素对应在下标为1的链表上,而线程2插入的元素对应在下标为2的链表上,此时会产生线程安全问题吗?
显然,这属于两个线程修改不同的变量,是线程安全的。但此时,一把全局的锁的弊病就显现出来了:虽然两个线程的插入操作各不相干,但由于所有的关键方法都是对同一个锁对象this加锁,造成明明两个操作没有线程安全问题,但线程之间还是会针对同一个锁对象产生锁竞争,产生阻塞等待!
实际上,没有必要把锁加得如此勤快。相比之下,ConcurrentHashMap就科学多了。
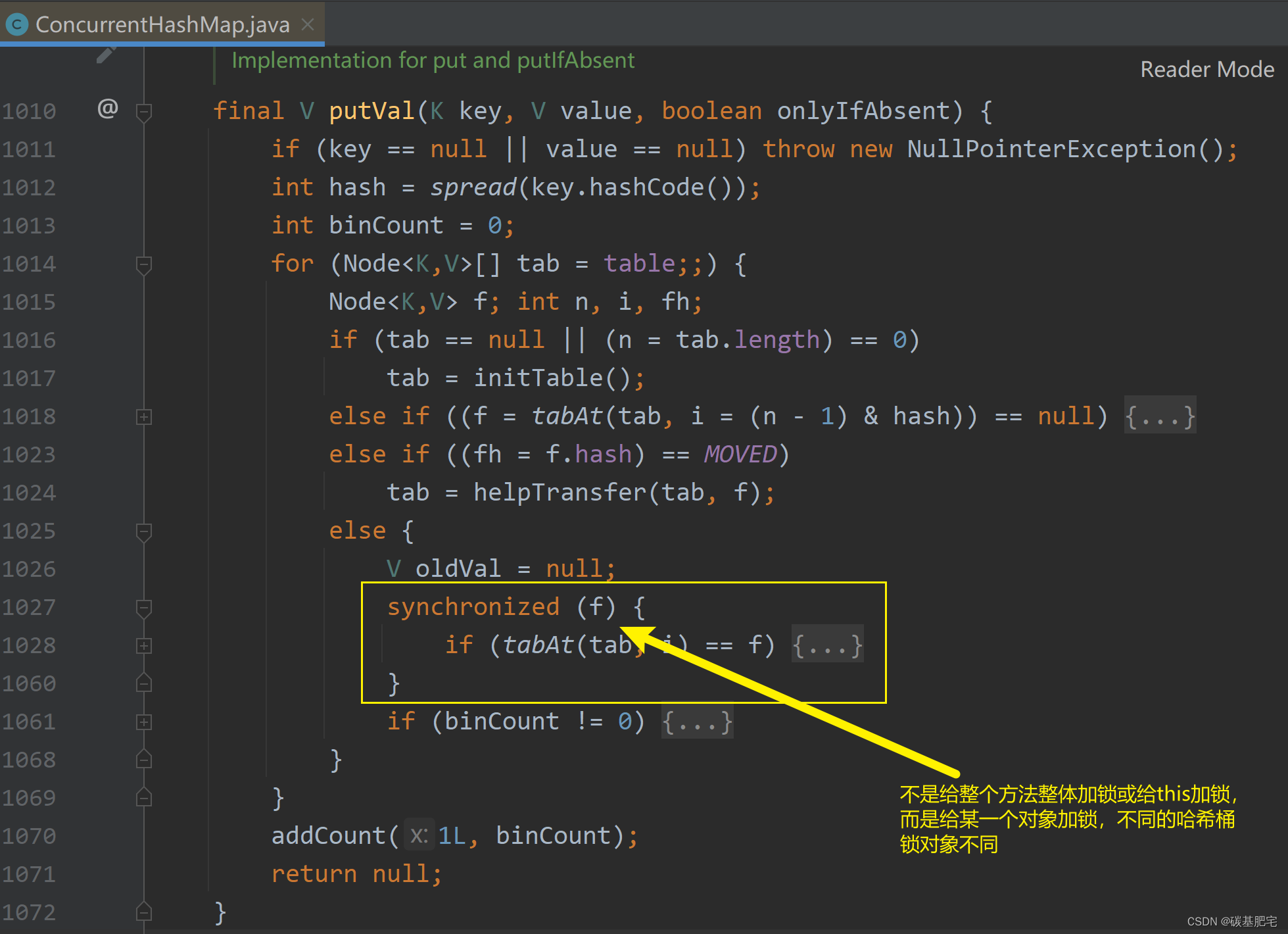
ConcurrentHashMap不是只有一把锁,而是给每一个链表都发了一把锁(把每个链表的头节点分别放入synchronized里面)。这样一来,每次进行操作都是针对对应链表的锁对象进行加锁;操作不同的链表就是针对不同的锁加锁,因此此时不会产生锁冲突。

以ConcurrentHashMap的put操作为例,伪代码如下:
void put(String key, String value) {
//先找到对应的头节点
int index = hashCode(key);
Node head = getHead(index);
synchronized(head) {
//执行链表插入节点的操作
}
}观察源码可以验证,伪代码的思路是正确的:
对于HashTable和ConcurrentHashMap锁粒度的区别,可以理解为HashTable是只有一个“坑”,所有人都来抢这一个“坑”,所以竞争就大,冲突的概率就大;而ConcurrentHashMap则是有很多个“坑”,数组长度有多大就有多少个“坑”,这样一来冲突的概率就小了,这也就导致了大部分的加锁操作是没有锁冲突的。没有锁冲突就没有阻塞等待,那么这里甚至可以直接用偏向锁来搞定……总之,这里加锁操作的开销就微乎其微了,效率是很高的。
上述内容也即锁粒度的不同,是ConcurrentHashMap和HashTable之间最大的区别,通过对加锁粒度的调整使得ConcurrentHashMap的并发能力大大提升。
(补充:上述内容是从 Java 8 开始的。在 Java 1.7 及其之前,ConcurrentHashMap使用的是“分段锁”。它的目的和上述是类似的,只是它相当于是好几个链表共用同一把锁。这个设定其实不太科学,因为不仅效率不够高,代码写起来也麻烦。只要了解到分段锁是ConcurrentHashMap历史上的一种实现方式即可。)
2、ConcurrentHashMap能更充分地利用CAS机制
什么是CAS机制:Java多线程基础-12:详解CAS算法
CAS机制最大的作用是实现无锁编程。在ConcurrentHashMap中做了一些改进:部分操作如获取/更新元素个数,就可以直接使用CAS完成而不必加锁了。
CAS也能保证线程安全,且往往比锁更高效。不过CAS并不会经常使用,因为它的适用范围有限,不像锁那么广,有的操作如维护一个整数变量值的变化就比较适合CAS。
总之,ConcurrentHashMap更充分地利用了CAS,能提高它自身的效率。
3、ConcurrentHashMap优化了扩容策略
对于HashTable,如果元素太多,就会涉及到扩容,这里就涉及哈希表的负载因子的概念。
负载因子=整个哈希表中已存的总元素个数 ➗ 数组的长度,即平均每个哈希桶(链表)上有多少个元素。
当负载因子达到阈值(比如0.75),就需要把哈希表扩容。扩容需要重新申请内存空间并且搬运元素(把元素从旧的哈希表上删掉,然后插入新的哈希表)。可见,如果当前哈希表内元素非常多(比如有上亿个),搬运一次成本就非常高,从而导致这一次put操作非常卡顿。put操作原本是O(1)的,但当出发扩容操作并引发卡顿时效率会非常低,作为用户我们又无法预知哪一次put会触发卡顿,因此这个事情还是比较让人头疼的。
ConcurrentHashMap采用了化整为零的策略。它并不会试图一次性把所有元素都搬运过去,而是每次搬运一部分,是一个渐进的过程。当put触发扩容时,此时仍然会直接创建更大的内存空间,但并不会直接把所有元素都搬运到新的哈希表上,而是只搬运一小部分(速度较快)。此时相当于同时存在新旧两份哈希表(新表指扩容后的哈希表,旧表指扩容前的):
- 插入元素,直接往新的哈希表中插入。
- 删除元素,看待删元素在新表还是旧表。先在新表中查找待删元素,如果元素在新表中被找到并成功删除,则删除操作完成;如果新表里没找到,就在旧表里找并删除。
- 查找元素,在新表旧表中都查,步骤和删除操作类似。
并且,在每次操作过程中都会再搬运一部分。就和蚂蚁搬家一样,虽然每次搬的少,但多搬几次,也就很快搬完了。通过这样化整为零的方式,就避免了某一次扩容操作特别卡顿。
具体流程见这位大佬的博客:ConcurrentHashMap1.8 - 扩容详解
当然,ConcurrentHashMap避免卡顿、保持程序运行稳定的代价是消耗了更多的空间。
(另外,如果要在多线程环境下使用Set,也可以借助ConcurrentHashMap,只使用key而不使用value(如将value全置0)即可。)
四、ConcurrentHashMap相关问题总结
1、ConcurrentHashMap的读是否要加锁,为什么?
读操作没有加锁,目的是为了进一步降低锁冲突的概率。为了保证读到刚修改的数据, 搭配了volatile 关键字。
2、ConcurrentHashMap的锁分段技术?
这个是 Java1.7 中采取的技术,Java1.8 中已经不再使用了。简单的说就是把若干个哈希桶分成一个 “段” (Segment),针对每个段分别加锁。
它的目的也是为了降低锁竞争的概率。当两个线程访问的数据恰好在同一个段上的时候,才触发锁竞争。
3、ConcurrentHashMap在jdk1.8做了哪些优化?
取消了分段锁,直接给每个哈希桶(每个链表)分配了一个锁(就是以每个链表的头结点对象作为锁对象)。
将原来数组 + 链表的实现方式改进成数组 + 链表 / 红黑树的方式。当链表较长的时候(大于等于8个元素)就转换成红黑树。
4、Hashtable和HashMap、ConcurrentHashMap 之间的区别?
- HashMap:线程不安全,key 允许为 null。
- Hashtable:线程安全,使用 synchronized 锁整个 Hashtable 对象,效率较低。key 不允许为 null。
- ConcurrentHashMap:线程安全,使用 synchronized 锁每个链表头结点,锁冲突概率低;充分利用 CAS 机制;优化了扩容方式。key 不允许为 null。
ConcurrentHashMap源码分析见这位大佬的博客:ConcurrentHashMap源码分析(JDK8版本)