简介
网址:Apache Doris: Open-Source Real-Time Data Warehouse - Apache Doris
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
Apache Doris 最早是诞生于百度广告报表业务的 Palo 项目,2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。目前 Apache Doris 社区已经聚集了来自不同行业数百家企业的 400 余位贡献者,并且每月活跃贡献者人数也超过 100 位。 2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)
Apache Doris 如今在中国乃至全球范围内都拥有着广泛的用户群体,截止目前, Apache Doris 已经在全球超过 2000 家企业的生产环境中得到应用,在中国市值或估值排行前 50 的互联网公司中,有超过 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、腾讯、网易、快手、微博、贝壳等。同时在一些传统行业如金融、能源、制造、电信等领域也有着丰富的应用。
使用场景
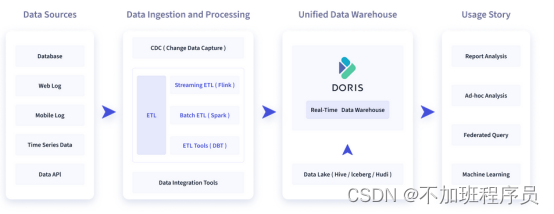
如下图所示,数据源经过各种数据集成和加工处理后,通常会入库到实时数仓 Doris 和离线湖仓(Hive, Iceberg, Hudi 中),Apache Doris 被广泛应用在以下场景中。
报表分析
-
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
即席查询(Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
统一数仓构建 :一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
技术概述
Doris整体架构如下图所示,Doris 架构非常简单,只有两类进程
Frontend(FE),主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
Backend(BE),主要负责数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
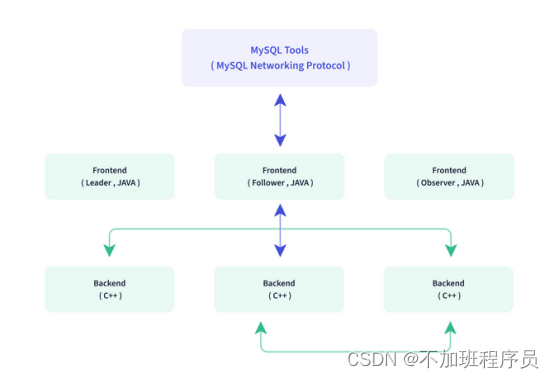
在使用接口方面,Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris,并支持与 BI 工具的无缝对接。
在存储引擎方面,Doris 采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
下载安装
注1:
- FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个 GB 不等。
- BE 的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量 * 3(3副本)计算,然后再预留额外 40% 的空间用作后台 compaction 以及一些中间数据的存放。
- 一台机器上可以部署多个 BE 实例,但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个 BE 实例(而不是1台机器部署3个BE实例)。多个FE所在服务器的时钟必须保持一致(允许最多5秒的时钟偏差)
- 测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定了整体查询延迟。
- 所有部署节点关闭 Swap。
注2:FE 节点的数量
- FE 角色分为 Follower 和 Observer,(Leader 为 Follower 组中选举出来的一种角色,以下统称 Follower)。
- FE 节点数据至少为1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时,可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
- Follower 的数量必须为奇数,Observer 数量随意。
- 根据以往经验,当集群可用性要求很高时(比如提供在线业务),可以部署 3 个 Follower 和 1-3 个 Observer。如果是离线业务,建议部署 1 个 Follower 和 1-3 个 Observer。
- 通常我们建议 10 ~ 100 台左右的机器,来充分发挥 Doris 的性能(其中 3 台部署 FE(HA),剩余的部署 BE)
- 当然,Doris的性能与节点数量及配置正相关。在最少4台机器(一台 FE,三台 BE,其中一台 BE 混部一个 Observer FE 提供元数据备份),以及较低配置的情况下,依然可以平稳的运行 Doris。
- 如果 FE 和 BE 混部,需注意资源竞争问题,并保证元数据目录和数据目录分属不同磁盘。
软硬件配置要求:
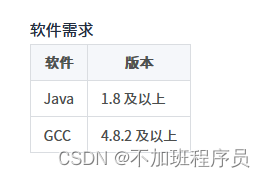
下载地址为http://archive.apache.org/dist/doris/
(安装doris需要最少100G磁盘)
根据需要下载指定版本即可,此处以1.2.4为例,下载apache-doris-be-1.2.4-bin-x86_64.tar.xz;apache-doris-dependencies-1.2.4-bin-x86_64.tar.xz;apache-doris-fe-1.2.4-bin-x86_64.tar.xz。
将指定安装包上传到服务器(以192.168.0.30为例)并解压:
tar -xvf apache-doris-fe-1.2.4-bin-x86_64.tar.xz
tar -xvf apache-doris-be-1.2.4-bin-x86_64.tar.xz
修改FE配置
首先进入到fe部分的conf中,修改fe.conf
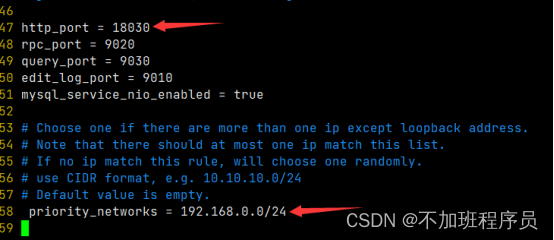
http_port默认为8030,如果机器上有大数据相关进程,该端口会被占用,自行修改,此处修改为18030。
priority_networks配置ip。
注意:这个参数我们在安装的时候是必须要配置的,特别是当一台机器拥有多个IP地址的时候,我们要为FE指定唯一的IP地址。这里假设你的节点IP是192.168.0.30,那么我们可以通过掩码的方式配置为192.168.0.0/24。
启动FE
./bin/start-fe.sh --daemon
通过监控log/fe.log查看启动日志。
通过WebUI查看是否启动成功,192.168.0.30:18030,出现登陆界面,默认用户为admin和root,没有密码。

修改BE配置
进入到be中的conf修改be.conf
主要是配置storage_root_path:数据存放目录。默认在be/storage下,如果需要自定义,需要手动创建该目录。
通过mysql-client链接:
mysql -h 192.168.0.30 -P 9030 -uroot
alter system add backend '192.168.0.30:9050';
如果有多个be节点 将指定的IP:port依次全部加入即可。
启动BE
./bin/start-be.sh --daemon
启动报错如下:

在be节点执行 sysctl -w vm.max_map_count=2000000
重新启动后报如下错误:
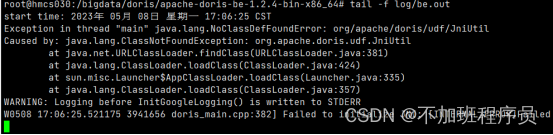
原因∶安装Java UDF函数因为从1.2版本开始支持Java UDF函数,需要从官网下载Java UDF函数的JAR包放到BE的lib目录下.否则可能会启动失败。在官网下载依赖的jar包。下载完成后拷贝到BE的lib目录下即可。
前面下载的apache-doris-dependencies-1.2.4-bin-x86_64.tar.xz压缩包解压后里面有java-udf-jar-with-dependencies.jar文件,将该jar文件复制到be模块中的lib中,重新启动。
注意:如果be部署在hadoop集群中,注意调整be.conf中的webserver_port = 8040 (hadoop集群中,nodemanager进程默认使用的是8040端口号),以免造成端口冲突。否则会报如下错误︰
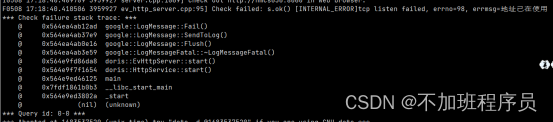
此处修改为18040后启动正常。
查看be状态
1:通过mysql-client 执行如下命令:
show proc '/backends';

2:通过WebUI查看
192.168.0.30:18040
192.168.0.30:18040/api/health
![]()
查看fe状态
- WebUI
通过http://192.168.0.30:18030/api/bootstrap
![]()
通过mysql连接工具能够正常操作doris,如Navicat、DataGrip等。