🌈个人主页:Sarapines Programmer
🔥 系列专栏: 爬虫】网络爬虫探秘
⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。


目录
🌼实验目的
🌷实验要求
🏵️实验代码
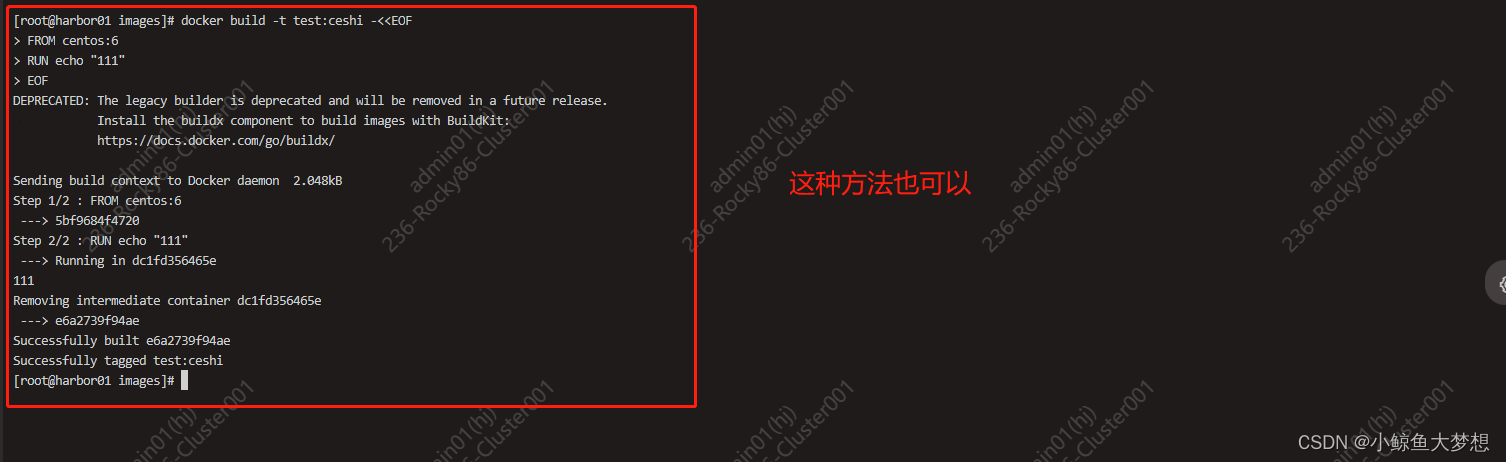
🌿1. 爬取并下载当当网某一本书的网页内容
🌿2. 在豆瓣网上爬取某本书的前50条短评内容并计算评分的平均值
🌿3. 从长沙房产网爬取长沙某小区的二手房信息
🌾实验结果
🌿1. 爬取并下载当当网某一本书的网页内容
🌿2. 在豆瓣网上爬取某本书的前50条短评内容并计算评分的平均值
🌿3. 从长沙房产网爬取长沙某小区的二手房信息
🌺实验体会
📝总结
🌼实验目的
-
Jupyter Notebook编程工具基本用法:
- 学习掌握Jupyter Notebook编程工具的基本用法。
-
Python读取CSV文件:
- 理解并熟悉使用Python编程语言读取CSV文件的方法。
-
学习使用爬虫:
- 通过学习,熟悉爬虫技术的使用,掌握在Python环境下进行网络爬取的基本知识和技能。
🌷实验要求
-
爬取并下载当当网某一本书的网页内容: 通过编写Python代码,实现对当当网上某一本书的网页内容进行爬取,并将其保存为HTML格式,这涉及到网络爬虫技术的应用。
-
在豆瓣网上爬取某本书的前50条短评内容并计算评分的平均值: 运用自学的正则表达式技能,爬取豆瓣网上某本书的前50条短评内容,并计算这些评分的平均值,为数据分析提供基础。
-
从长沙房产网爬取长沙某小区的二手房信息: 以名都花园为例,通过网络爬虫技术从长沙房产网(长沙链家网)上获取该小区的二手房信息,并将这些信息保存到EXCEL文件中,为房产数据的整理和分析提供便利
🏵️实验代码
🌿1. 爬取并下载当当网某一本书的网页内容
import urllib.request
#做爬虫时要用到的库
#定义百度函数
def dangdang_shuji(url,begin_page,end_page):
#三个参数: 链接+开始页数+结束页数
for i in range(begin_page, end_page+1):
#从开始页数到结束页数,因为range性质所以要想到达end_page得到达end_page+1
sName = str(i).zfill(5) + '.html'
#填充为.html文件名
#zfill(5)表示数字前自动补0,加上字符转化的整型i一共占五位
print ('正在下载第' + str(i) + '个网页,并将其存储为' + sName + '......')
#显示爬虫细节
f = open(sName,'wb+')
#w+以纯文本方式读写,而wb+是以二进制方式进行读写
m = urllib.request.urlopen(url+str(i)) .read()
#urllib.request请求模块
#urlopen实现对目标url的访问
#可用参数
#url: 需要打开的网址
#data:Post提交的数据
#timeout:设置网站的访问超时时间
f.write(m)
f.close()
#调用部分
bdurl = str(input('请输入您在当当网上搜索的关于某本书的网页地址:'))
# 注意输入网址 https://book.dangdang.com/
begin_page = int(input(u'请输入开始的页数:\n'))
#将输入的字符串类型转化为整型
end_page = int(input(u'请输入终点的页数:\n'))
#同上
dangdang_shuji(bdurl,begin_page,end_page)
#调用函数🌿2. 在豆瓣网上爬取某本书的前50条短评内容并计算评分的平均值
import requests, re, time
#获取响应时间与超时
count = 0
i = 0
sum, count_s = 0, 0
while(count < 50):
#访问前50条记录
if(i==0):
#首页内容
try:
proxies = {'http': '120.236.128.201:8060','https': '120.236.128.201:8060'}
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
url = 'https://book.douban.com/subject/3674537/comments/?limit=20&status=P&sort=score'
r = requests.get(url=url,headers=headers)
except Exception as err:
print(err)
#打印输出错误信息
break
#其他页的内容
else:
start = i*20
#url中start的值
try:
proxies = {'http': '120.236.128.201:8060','https': '120.236.128.201:8060'}
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
url='https://book.douban.com/subject/3674537/comments/?start='+str(start)+'&limit=20&status=P&sort=score'
r = requests.get(url=url,headers=headers)
# print('第'+str(i)+'页内容')
except Exception as err:
print(err)
break
soup = BeautifulSoup(r.text, 'lxml')
# comments = soup.find_all('p', 'comment-content')
#查找所有tag值为p,class标签为comment-content的内容
comments = soup.find_all('span', class_='short')
for item in comments:
count = count + 1
# print(count, item.string)
print(count,item.get_text())
#打印用户评论
if count == 50:
break
pattern = re.compile('<span class="user-stars allstar(.*?) rating"')
#以正则表达式匹配网页中的内容
p = re.findall(pattern, r.text)
for star in p:
count_s = count_s + 1
sum += int(star)
time.sleep(5)
# 停顿5秒再开始
i += 1
if count == 50:
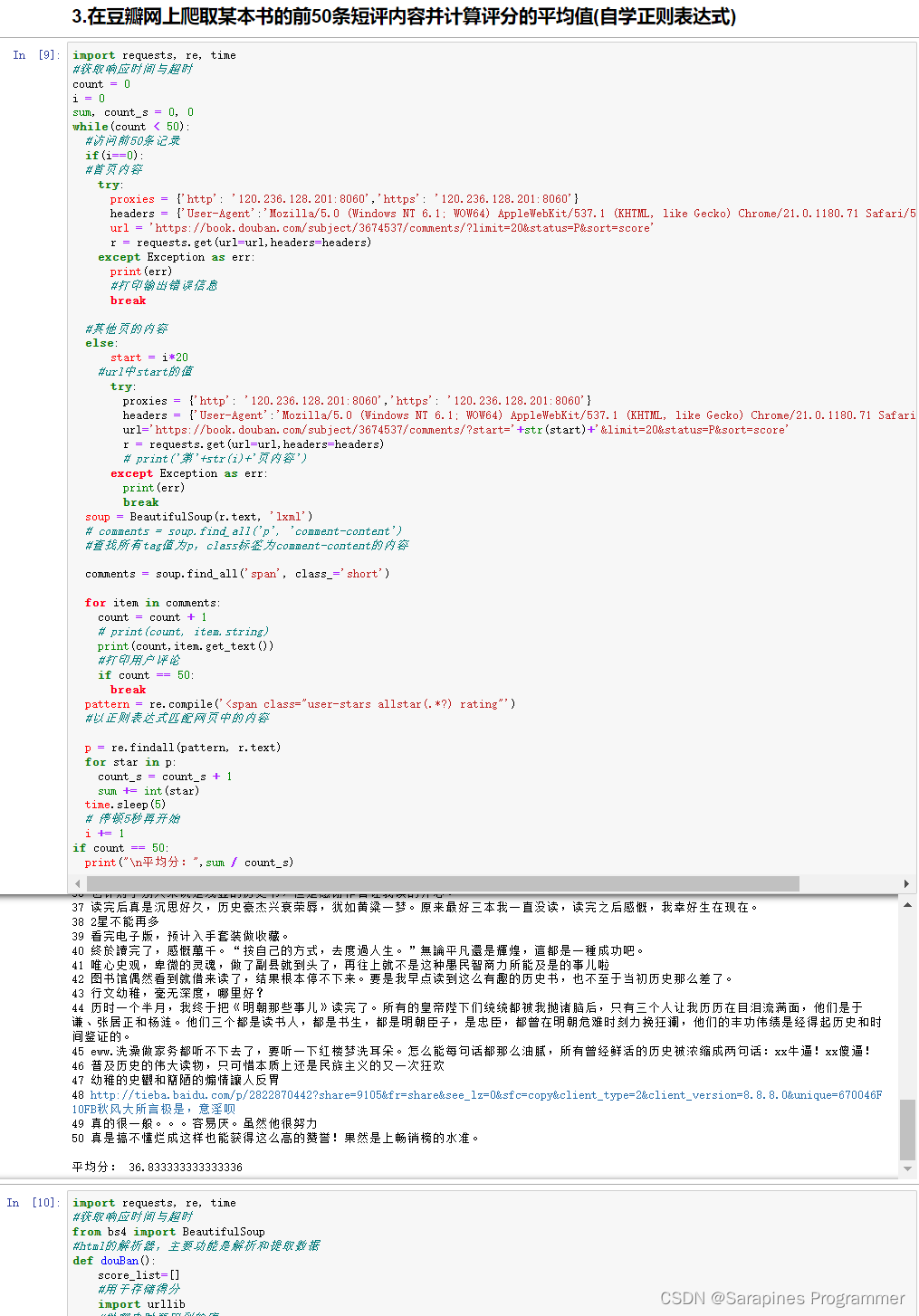
print("\n平均分:",sum / count_s)
import requests, re, time
#获取响应时间与超时
from bs4 import BeautifulSoup
#html的解析器,主要功能是解析和提取数据
def douBan():
score_list=[]
#用于存储得分
import urllib
#做爬虫时要用到的库
count=0
i=0
while(count<50):
#求50条评价记录
#首页内容
if(i==0):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
url = 'https://movie.douban.com/subject/35437938/comments?limit=20&status=P&sort=new_score'
r = requests.get(url=url,headers=headers)
except Exception as err:
#返回报错的原因
print(err)
break
#非首页内容
else:
start = i*20
#url中start的值
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
url='https://movie.douban.com/subject/35437938/comments?start='+str(start)+'&limit=20&status=P&sort=new_score'
r = requests.get(url=url,headers=headers)
# requests.get表示向服务器请求数据,服务器返回的结果是个Response对象
except Exception as err:
print(err)
break
req=urllib.request.Request(url,headers=headers)
#Request:构造一个基本的请求。headers可以模拟浏览器,url为目的网址
#urllib.request 模块提供了最基本的构造 HTTP 请求的方法,利用它可以
#模拟浏览器的一个请求发起过程,同时它还带有处理 authenticaton (授权验证),
#redirections (重定向), cookies (浏览器Cookies)以及其它内容
response=urllib.request.urlopen(req)
#urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False, context=None)。
#参数解释:
#url:请求网址
#data:请求时传送给指定url的数据,当给出该参数时,请求方式变为POST,未给出时为GET。
#timeout:设定超时时间。如果在设定时间内未获取到响应,则抛出异常。
#cafile, capath分别为CA证书及其路径
html=response.read().decode("utf-8")
#以utf-8方式读取爬取网页的内容
bs=BeautifulSoup(html,"html.parser")
#beautifulSoup:提取html对象中的内容
items=bs.find_all("div",class_="comment-item")
findScore=re.compile('<span class="allstar(.*?) rating"')
#匹配星级
findName=re.compile('<img alt="(.*?)"')
#正则表达式的字符串形式匹配电影名字
for item in items:
item=str(item)
#找出对应的五十个电影的得分
score=re.findall(findScore,item)[0]
score=float(score)
score_list.append(score)
#将得分存放在score_list列表中
count+=1
#计数器加1,当计数器大于等于50则结束循环
if(count>=50):
break
i+=1
#下一页
time.sleep(5)
# 停顿5秒
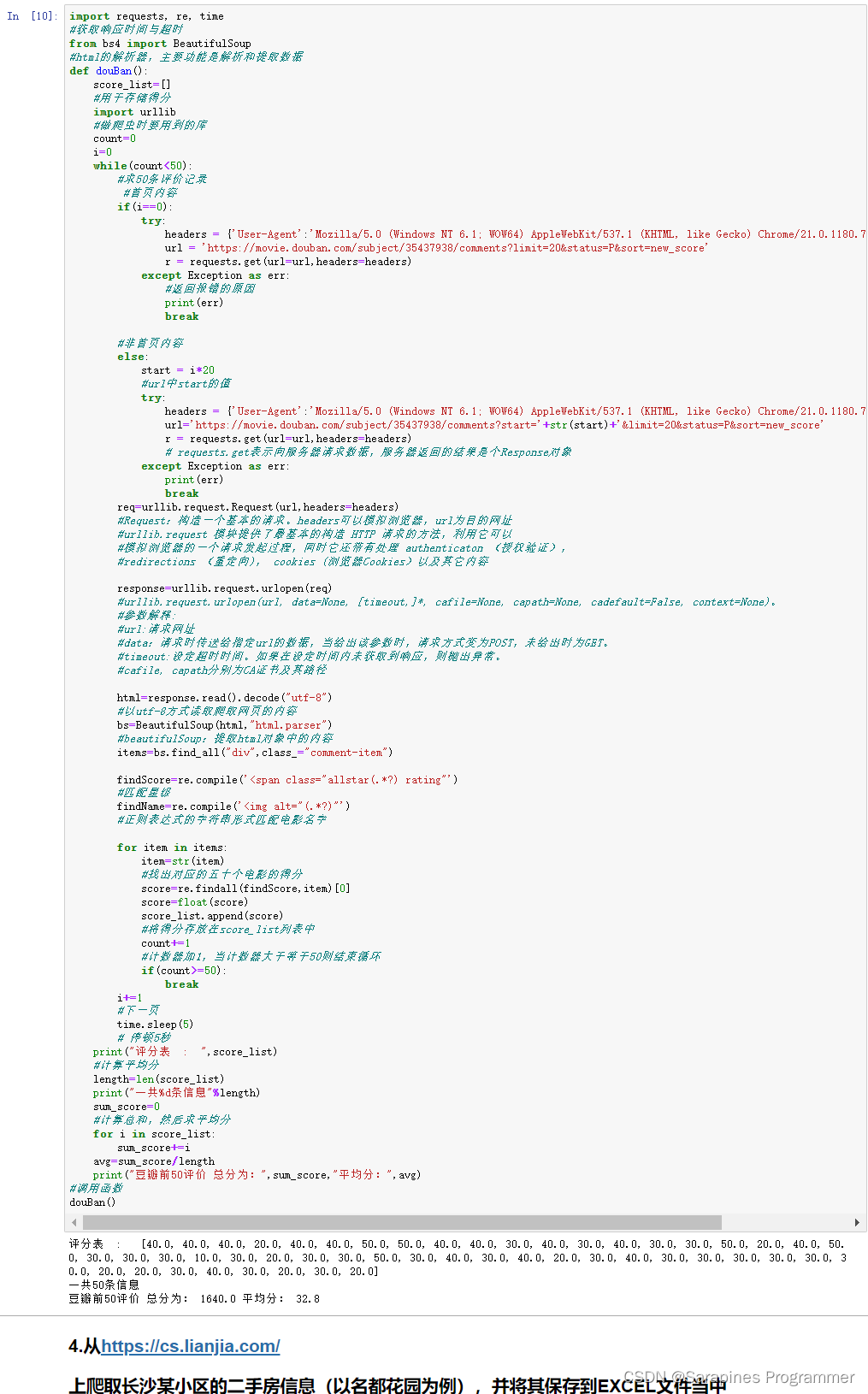
print("评分表 : ",score_list)
#计算平均分
length=len(score_list)
print("一共%d条信息"%length)
sum_score=0
#计算总和,然后求平均分
for i in score_list:
sum_score+=i
avg=sum_score/length
print("豆瓣前50评价 总分为:",sum_score,"平均分:",avg)
#调用函数
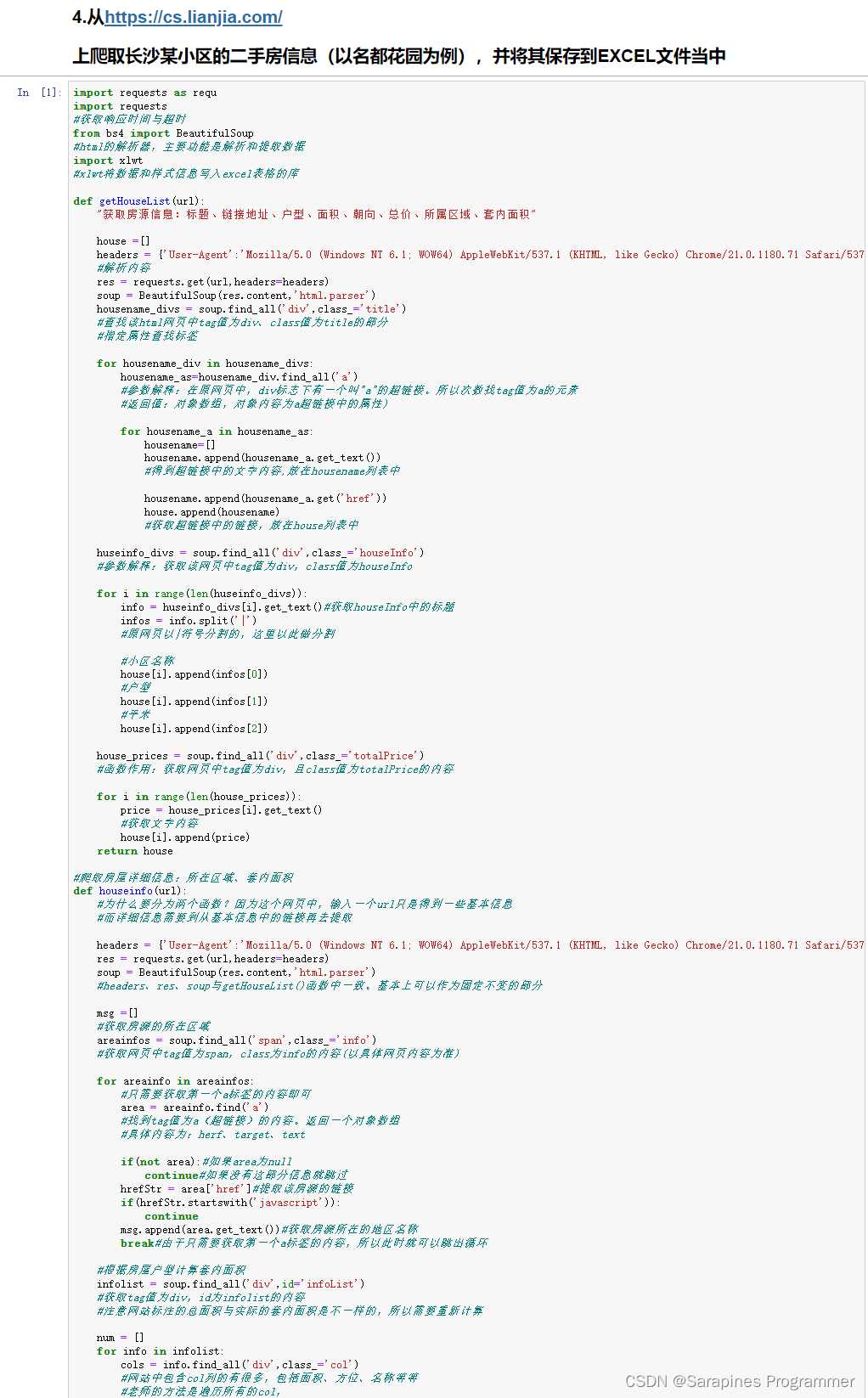
douBan()🌿3. 从长沙房产网爬取长沙某小区的二手房信息
import requests as requ
import requests
#获取响应时间与超时
from bs4 import BeautifulSoup
#html的解析器,主要功能是解析和提取数据
import xlwt
#xlwt将数据和样式信息写入excel表格的库
def getHouseList(url):
"获取房源信息:标题、链接地址、户型、面积、朝向、总价、所属区域、套内面积"
house =[]
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
#解析内容
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.content,'html.parser')
housename_divs = soup.find_all('div',class_='title')
#查找该html网页中tag值为div、class值为title的部分
#指定属性查找标签
for housename_div in housename_divs:
housename_as=housename_div.find_all('a')
#参数解释:在原网页中,div标志下有一个叫"a"的超链接。所以次数找tag值为a的元素
#返回值:对象数组,对象内容为a超链接中的属性)
for housename_a in housename_as:
housename=[]
housename.append(housename_a.get_text())
#得到超链接中的文字内容,放在housename列表中
housename.append(housename_a.get('href'))
house.append(housename)
#获取超链接中的链接,放在house列表中
huseinfo_divs = soup.find_all('div',class_='houseInfo')
#参数解释:获取该网页中tag值为div,class值为houseInfo
for i in range(len(huseinfo_divs)):
info = huseinfo_divs[i].get_text()#获取houseInfo中的标题
infos = info.split('|')
#原网页以|符号分割的,这里以此做分割
#小区名称
house[i].append(infos[0])
#户型
house[i].append(infos[1])
#平米
house[i].append(infos[2])
house_prices = soup.find_all('div',class_='totalPrice')
#函数作用:获取网页中tag值为div,且class值为totalPrice的内容
for i in range(len(house_prices)):
price = house_prices[i].get_text()
#获取文字内容
house[i].append(price)
return house
#爬取房屋详细信息:所在区域、套内面积
def houseinfo(url):
#为什么要分为两个函数?因为这个网页中,输入一个url只是得到一些基本信息
#而详细信息需要到从基本信息中的链接再去提取
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.content,'html.parser')
#headers、res、soup与getHouseList()函数中一致。基本上可以作为固定不变的部分
msg =[]
#获取房源的所在区域
areainfos = soup.find_all('span',class_='info')
#获取网页中tag值为span,class为info的内容(以具体网页内容为准)
for areainfo in areainfos:
#只需要获取第一个a标签的内容即可
area = areainfo.find('a')
#找到tag值为a(超链接)的内容。返回一个对象数组
#具体内容为:herf、target、text
if(not area):#如果area为null
continue#如果没有这部分信息就跳过
hrefStr = area['href']#提取该房源的链接
if(hrefStr.startswith('javascript')):
continue
msg.append(area.get_text())#获取房源所在的地区名称
break#由于只需要获取第一个a标签的内容,所以此时就可以跳出循环
#根据房屋户型计算套内面积
infolist = soup.find_all('div',id='infoList')
#获取tag值为div,id为infolist的内容
#注意网站标注的总面积与实际的套内面积是不一样的,所以需要重新计算
num = []
for info in infolist:
cols = info.find_all('div',class_='col')
#网站中包含col列的有很多,包括面积、方位、名称等等
#老师的方法是遍历所有的col,
#我觉得更好的方法是将包含平米的col单独提取出来,这样就无需使用try
for i in cols:
pingmi = i.get_text()#获取标题(面积,即xxx平米)
try:
#尝试从string中提取数字
a = float(pingmi[:-2])#从开头到距离尾部2个字符,即把"平米"汉字去掉了
num.append(a)
except ValueError:
#如果出错就跳出
continue
msg.append(sum(num))#计算各户型的总面积
return msg
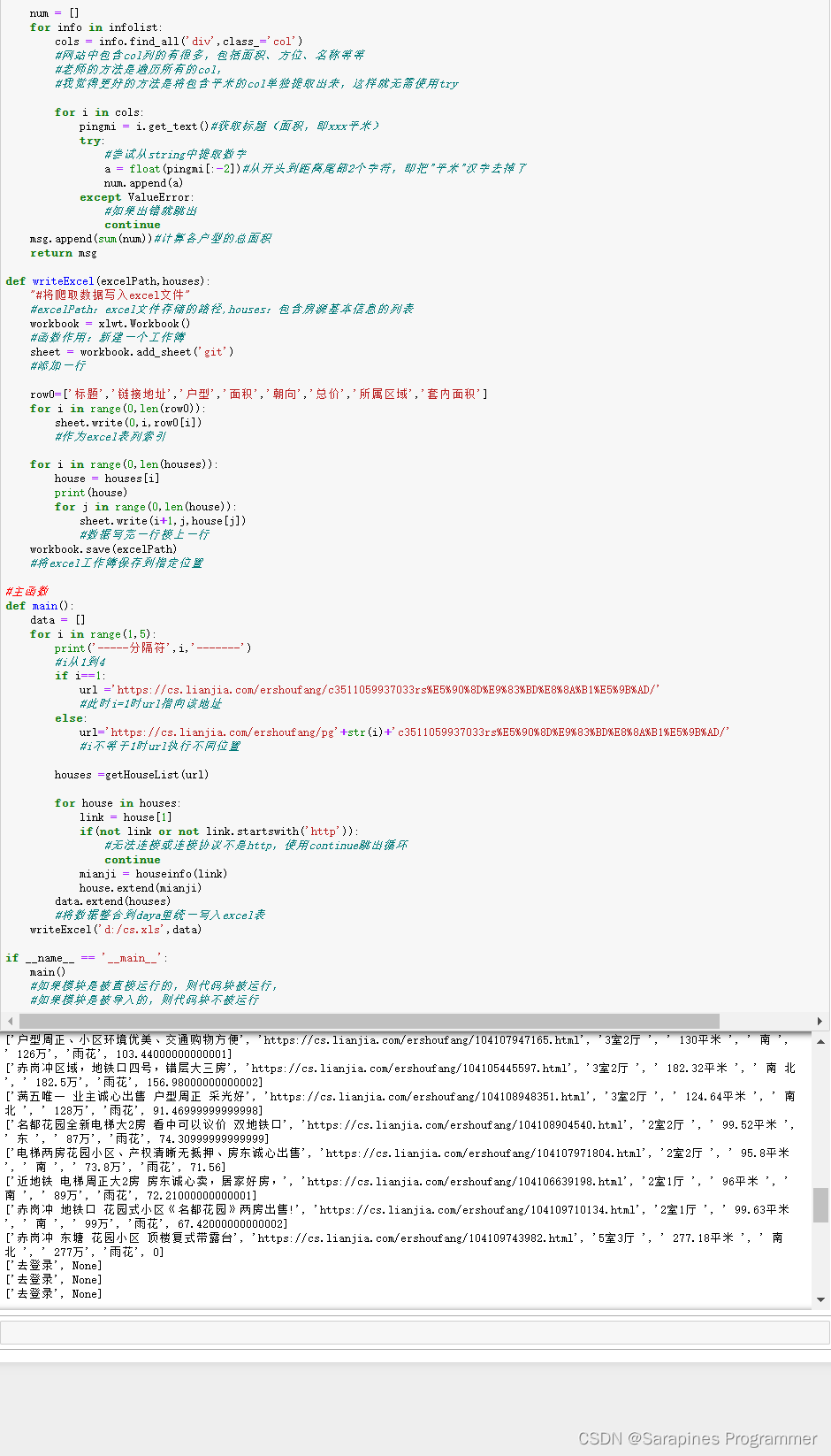
def writeExcel(excelPath,houses):
"#将爬取数据写入excel文件"
#excelPath:excel文件存储的路径,houses:包含房源基本信息的列表
workbook = xlwt.Workbook()
#函数作用:新建一个工作簿
sheet = workbook.add_sheet('git')
#添加一行
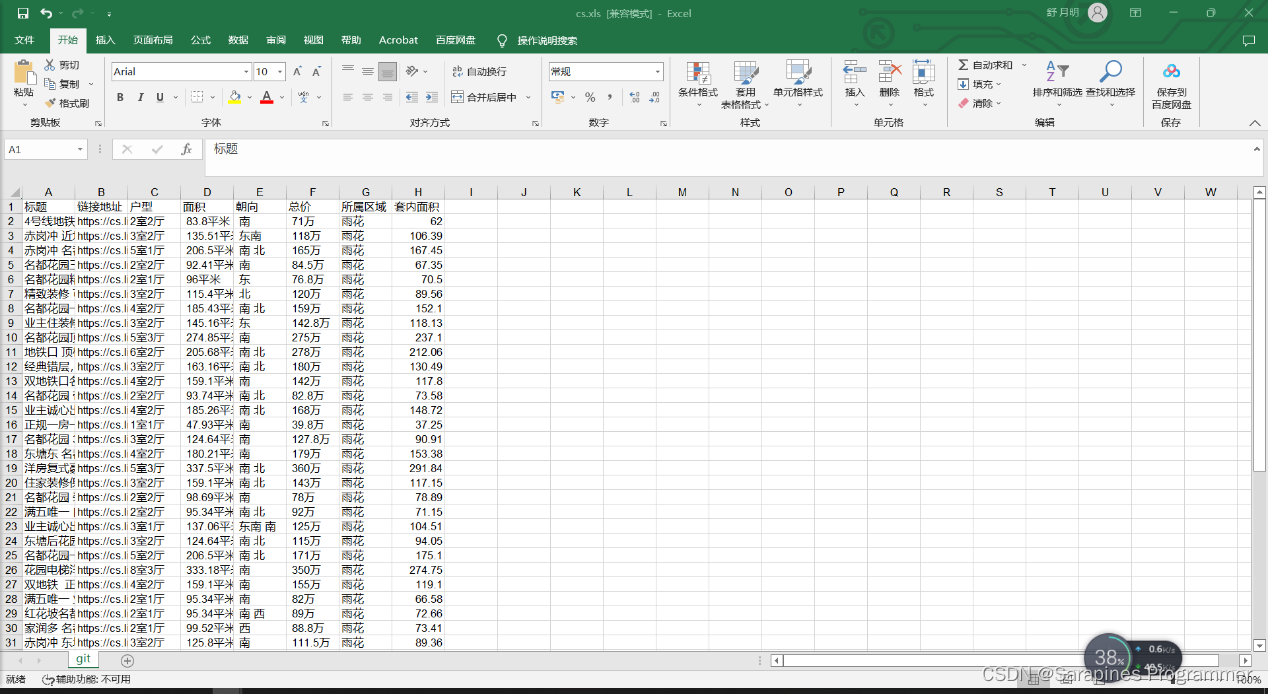
row0=['标题','链接地址','户型','面积','朝向','总价','所属区域','套内面积']
for i in range(0,len(row0)):
sheet.write(0,i,row0[i])
#作为excel表列索引
for i in range(0,len(houses)):
house = houses[i]
print(house)
for j in range(0,len(house)):
sheet.write(i+1,j,house[j])
#数据写完一行接上一行
workbook.save(excelPath)
#将excel工作簿保存到指定位置
#主函数
def main():
data = []
for i in range(1,5):
print('-----分隔符',i,'-------')
#i从1到4
if i==1:
url ='https://cs.lianjia.com/ershoufang/c3511059937033rs%E5%90%8D%E9%83%BD%E8%8A%B1%E5%9B%AD/'
#此时i=1时url指向该地址
else:
url='https://cs.lianjia.com/ershoufang/pg'+str(i)+'c3511059937033rs%E5%90%8D%E9%83%BD%E8%8A%B1%E5%9B%AD/'
#i不等于1时url执行不同位置
houses =getHouseList(url)
for house in houses:
link = house[1]
if(not link or not link.startswith('http')):
#无法连接或连接协议不是http,使用continue跳出循环
continue
mianji = houseinfo(link)
house.extend(mianji)
data.extend(houses)
#将数据整合到daya里统一写入excel表
writeExcel('d:/cs.xls',data)
if __name__ == '__main__':
main()
#如果模块是被直接运行的,则代码块被运行,
#如果模块是被导入的,则代码块不被运行
🌾实验结果
🌿1. 爬取并下载当当网某一本书的网页内容
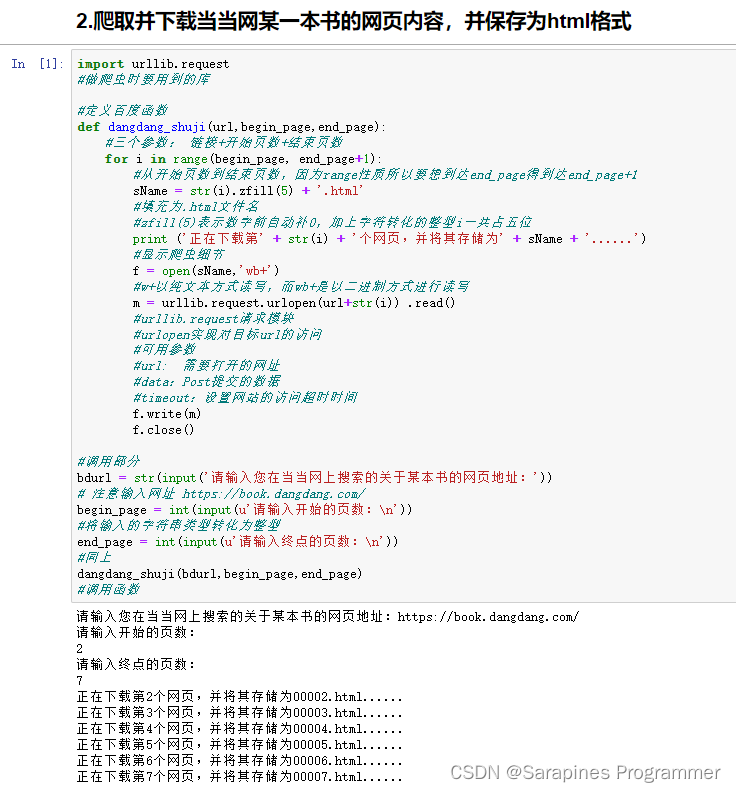
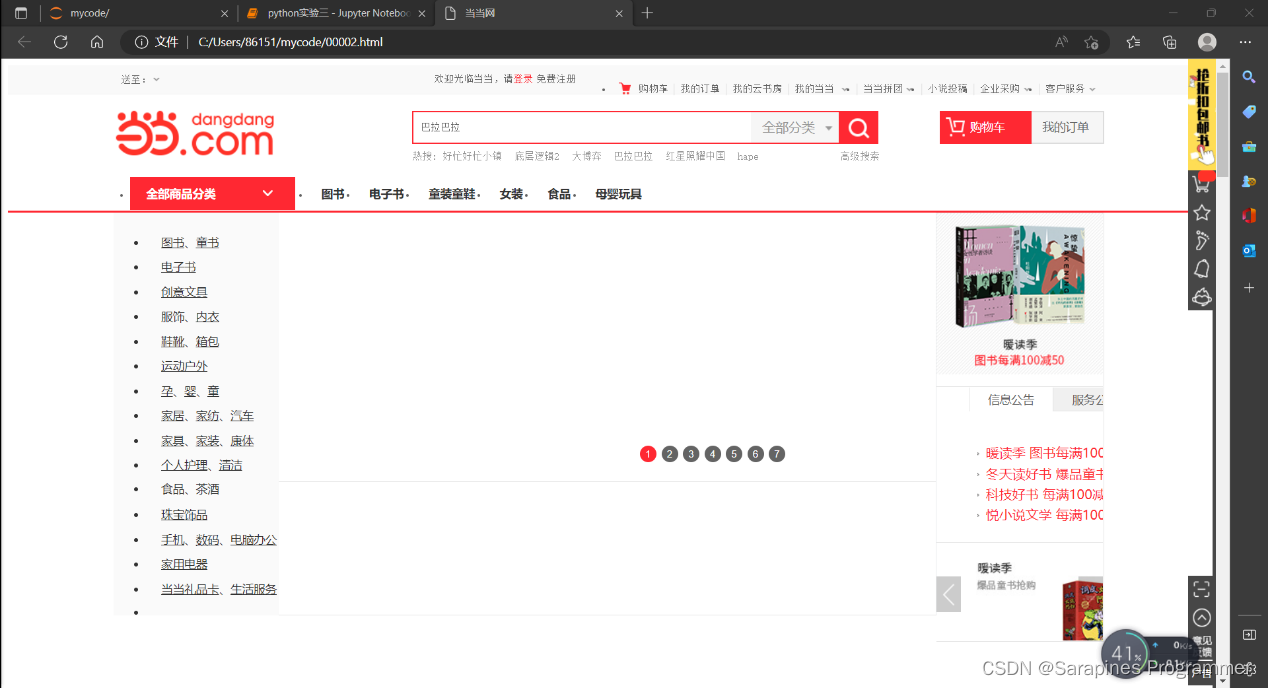
🌿2. 在豆瓣网上爬取某本书的前50条短评内容并计算评分的平均值
🌿3. 从长沙房产网爬取长沙某小区的二手房信息
🌺实验体会
-
实验学习和爬虫指令使用
- 通过实验首次接触了使用Python进行爬虫,学到了相关爬虫指令,并成功爬取了当当网和长沙二手房的信息。
- 发现在Linux系统下使用cat语法访问.csv文件,而在Windows系统下要使用type,需要注意斜线的差异。
-
对Python库的认识和意识拓展
- 在此实验中,通过社区查阅了相关资源,附上了详细注释,深化了对爬虫的理解。
- 意识到Python语言的强大之处,不论是机器学习的scikit-learn库还是爬虫的requests库,都涉及到Python,并体会到其调用封装在不同的库中。
-
爬虫问题解决和环境疑惑
- 遇到在Jupyter Notebook中出现‘int’ object is not callable的问题,通过重新创建文件解决,但对问题原因产生疑惑。
- 怀疑问题可能与装了PyTorch导致与Python两个虚拟环境冲突,但并未做实质修改,问题自行解决,留下疑惑。
📝总结
Python领域就像一片未被勘探的信息大海,引领你勇敢踏入Python数据科学的神秘领域。这是一场独特的学习冒险,从基本概念到算法实现,逐步揭示更深层次的模式分析、匹配算法和智能模式识别的奥秘。
渴望挑战Python信息领域的技术?不妨点击下方链接,一同探讨更多Python数据科学的奇迹吧。我们推出了引领趋势的💻 Python数据科学专栏:【爬虫】网络爬虫探秘,旨在深度探索Python模式匹配技术的实际应用和创新。🌐🔍