上一篇文章:
大数据 - 大数据入门第一篇 | 关于大数据你了解多少?-CSDN博客
目录
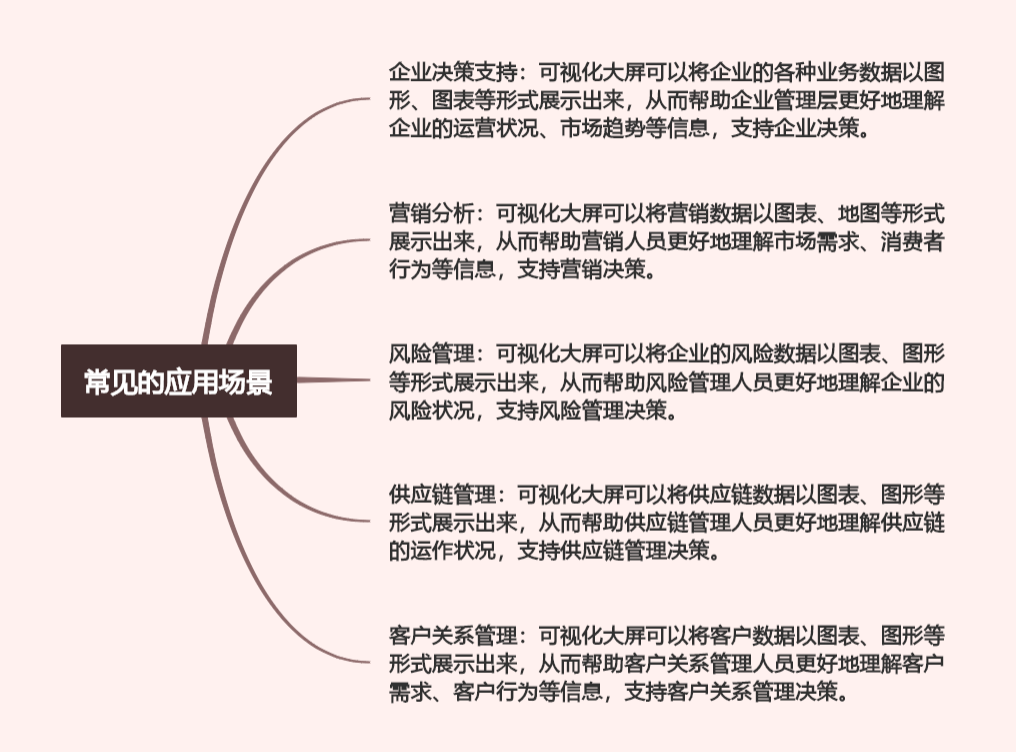
🐶1.ETL概念
🐶2. ETL的用处
🐶3.ETL实现方式
🐶4. ETL体系结构
🐶5. 什么是ETL技术?
🐶6. ETL工作流程
🐶7. ETL工程师的岗位价值
🐶8. ETL工程师进阶指南
🐶1.ETL概念
ETL是英文Extract-Transform-Load的缩写,用来描述将数据从源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,它能够对各种分布的、异构的源数据(如关系数据)进行抽取,按照预先设计的规则将不完整数据、重复数据以及错误数据等“脏"数据内容进行清洗,得到符合要求的“干净”数据,并加载到数据仓库中进行存储,这些“干净”数据就成为了数据分析、数据挖掘的基石
🐶2. ETL的用处
是实现商务智能(Business Intelligence,BI)的核心。一般情况下,ETL会花费整个BI项目三分之一的时间,因此ETL设计得好坏直接影响BI项目的成败。
🐶3.ETL实现方式
企业中常用的ETL实现有多种方式,常见的方式如下。
(1) 借助ETL工具(如Pentaho Kettle、Informatic等)。
(2) 编写SQL语句。
(3) 将ETL工具和SQL语句结合起来使用。
上述3种实现方式各有利弊,其中第1种方式可以快速建立ETL工程,屏蔽复杂的编码任务、加快速度和降低难度,但是缺少灵活性:第2种方式使用编写SQL语句的方式优占是灵活,可以提高ETL的运行效率,但是编码复杂,对技术要求比较高;第3种方式综合了前面两种方法的优点,可以极大地提高ETL的开发速度和效率。
🐶4. ETL体系结构
ETL主要是用来实现异构数据源数据集成的。多种数据源的所有原始数据大部分未作修改就被载入ETL,因而,无论数据源在关系型数据库、非关系型数据库,还是在外部文件.集成后的数据都将被置于数据库的数据表或数据仓库的维度表中,以便在数据库内或数据仓库中作进一步转换(因此,一般会将最终的数据存储到数据库或者数据仓库中)。ETL的体系结构如图下所示。
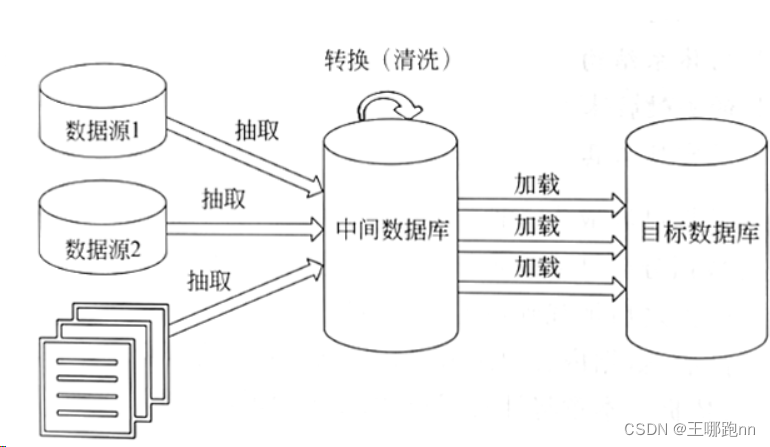
在上图中,若数据源1和数据源2均为功能较强大的DBMS(数据库管理系统),则可以使用SQL语句完成一部分数据清洗工作。但是,如果数据源为外部文件,就无法使用SQL语句进行数据清洗工作了,只能直接从数据源中抽取出来,然后在数据转换的时候进行数据清洗的工作。因此,数据仓库中的数据清洗工作主要还是在数据转换的时候进行。清洗好的数据将保存到目标数据库中,用于后续的数据分析、数据挖掘以及商业智能
🐶5. 什么是ETL技术?
ETL就是抽取、转换、加载这三个单词的缩写,所以顾名思义主要的工作就是把数据从哪块儿抽过来,然后进行一个清洗、加工,最后再存到哪块儿。
🐶6. ETL工作流程
ETL工作的环节也是见名知意。
抽取:这个环节可能主要是比如说Sqoop、Flume、Kafka、还有Kettle、DataX、Maxwell这些都是抽取工具。离线可能主要是用的Sqoop或者是DataX去进行离线数据的抽取,像实时可能会采用比如说Flume或者是Kafka、Maxwell,还有Kettle去进行抽取。
转换:转换包括清洗、合并、拆分、加工等等,可以用Hadoop生态的东西, MapReduce、Spark、Flink、Hive等去进行数据方面的清洗。
加载:抽取转换之后,就是将数据加载到目标数据库。可能会用到Hbase去存储一些大数据方面的东西,或者HDFS等等这些工具。
🐶7. ETL工程师的岗位价值
ETL的工作主要是对数仓的底层建设, ETL这个岗位是非常重要的,因为它属于是一个基础,如果ETL工作做好的话会有事半功倍的效果。
如果做不好可能后续会有很多的一些问题, 比如说数据如果没有清洗好,后续分析起来可能会有很多的脏数据等等。而且数据使用起来也非常的不方便。
🐶8. ETL工程师进阶指南
任何岗位都会有初、中、高级的一个划分,不管是在业务理解还是技术能力、需求理解沟通交流,以及在项目中的位置等等。ETL工程师的进阶方向也以此划分。
初级:对业务理解的不是特别的深入,技术上也就是会使用,出现一些问题可能不能独立解决或者是独立解决的问题数量会比较少,需要去咨询大牛之类的。
中级:对业务相对来说比较熟悉,另一方面就是理解能力也比较强,技术上可能已经比较熟练了,而且还对框架、原理都有一些了解,也会调优。而且中级可能会参与到管理中,分一个小组,做一些比较小的项目或者需求。
高级:对业务就是非常熟悉,技术是服务于业务的,所以熟悉业务非常重要,我们现在实现的功能,其实就是建立在业务的基础上去做的,另一方面高级的ETL工程师对各项技术、系统架构都非常熟悉或者是会设计这样的架构,同时具有管理能力,可以带领团队完成项目。





![[C++]使用纯opencv部署yolov8旋转框目标检测](https://img-blog.csdnimg.cn/direct/e509302a23f34c52aeb473fab2d4a092.jpeg)