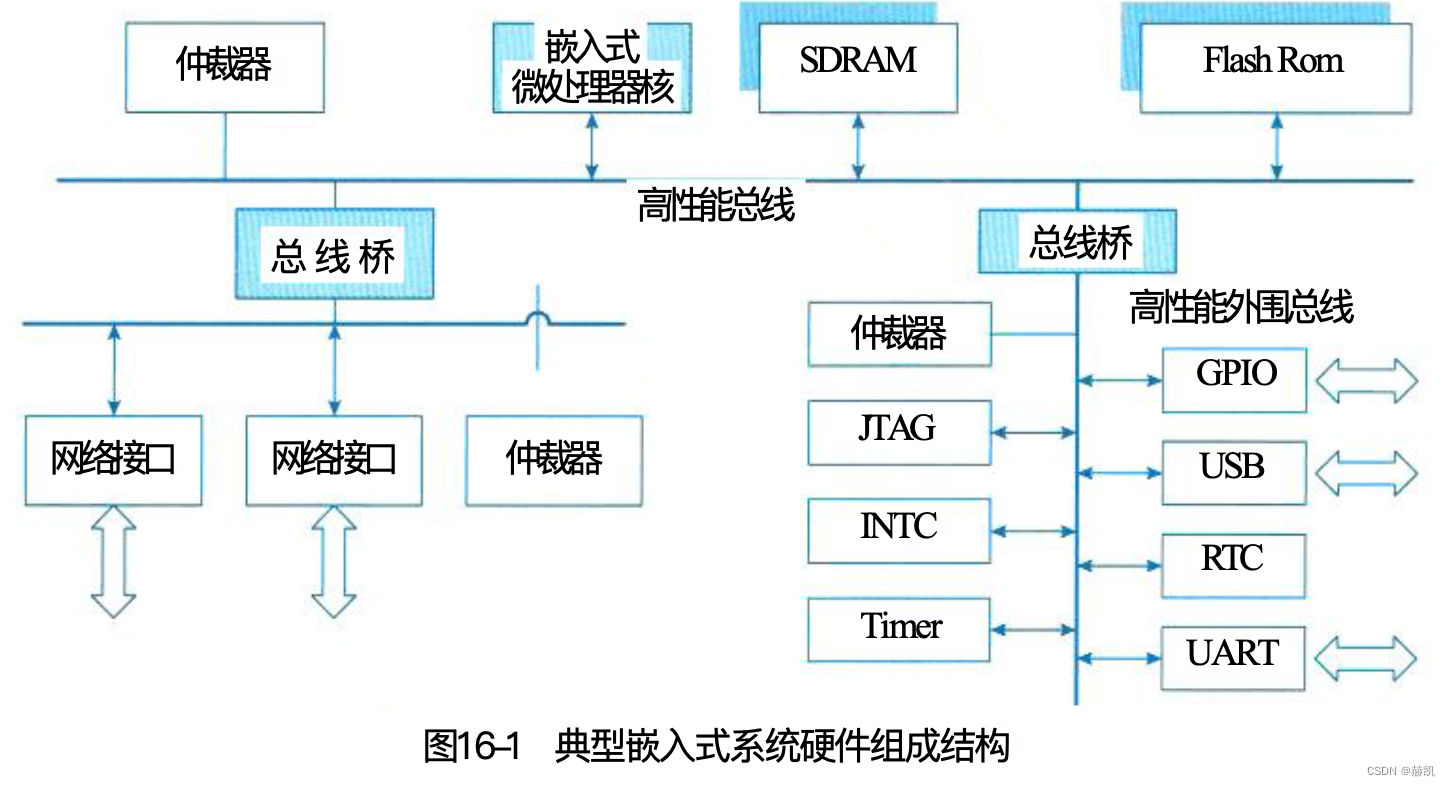
Amazon Bedrock 是一项完全托管的服务,通过单一 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先 AI 公司的高性能基础模型 (FMs) 选择,以及广泛的 构建生成式 AI 应用程序所需的功能,简化开发,同时维护隐私和安全。 由于 Amazon Bedrock 是无服务器的,因此你无需管理任何基础设施,并且可以使用你已经熟悉的 AWS 服务将生成式 AI 功能安全地集成和部署到你的应用程序中。
在此示例中,我们将文档拆分为段落,在 Elasticsearch 中索引该文档,使用 ELSER 执行语义搜索来检索相关段落。 通过相关段落,我们构建了上下文并使用 Amazon Bedrock 来回答问题。
1. 安装包并导入模块
首先我们需要安装模块。 确保 python 安装的最低版本为 3.8.1。
!python3 -m pip install -qU langchain elasticsearch boto3然后我们需要导入模块
from getpass import getpass
from urllib.request import urlopen
from langchain.vectorstores import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import Bedrock
from langchain.chains import RetrievalQA
import boto3
import json注意:boto3 是适用于 Python 的 AWS 开发工具包的一部分,并且需要使用 Bedrock LLM
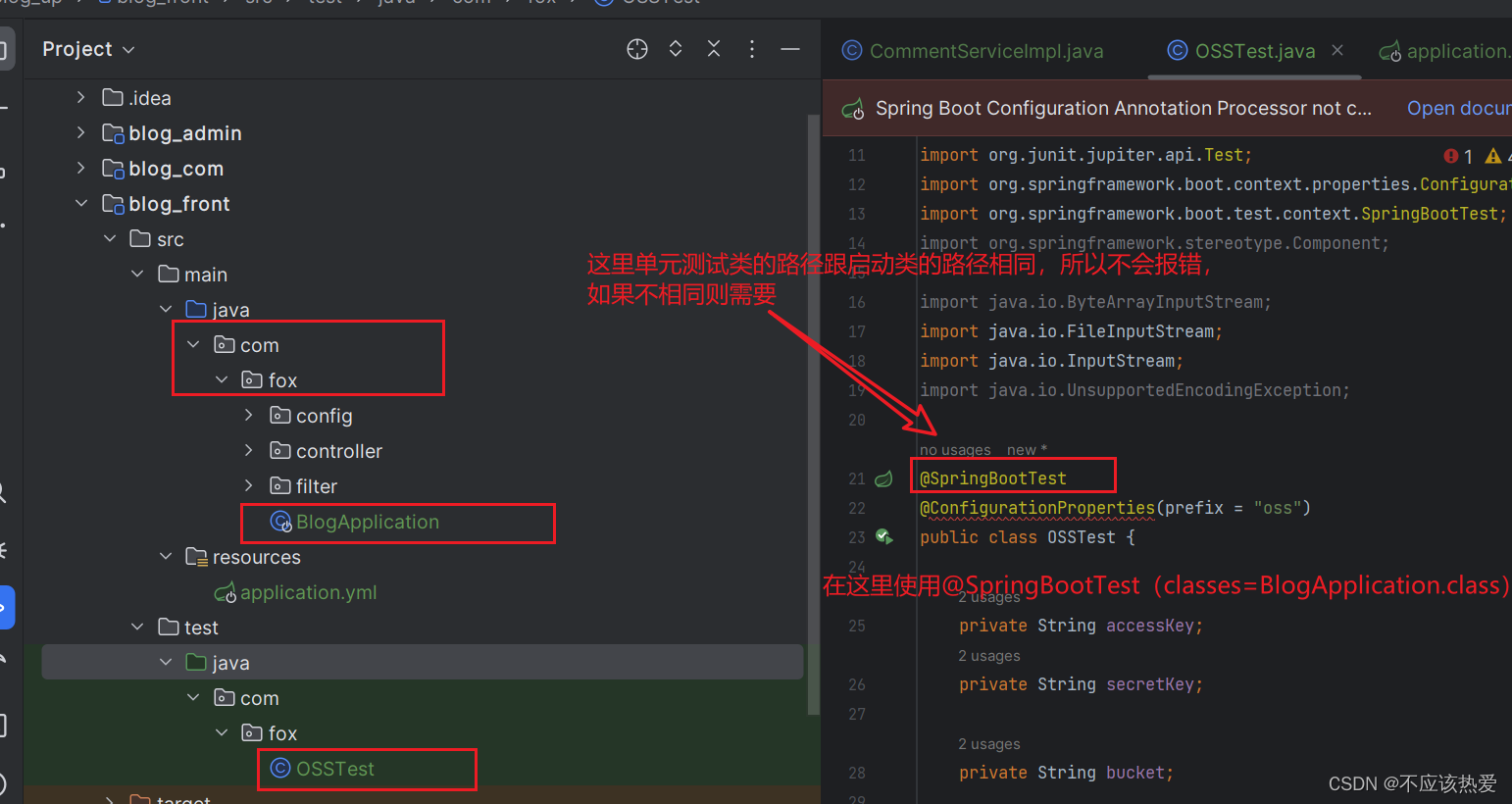
2. 初始化基岩客户端
要在 AWS 服务中授权,我们可以使用 ~/.aws/config 文件和配置凭证或将 AWS_ACCESS_KEY、AWS_SECRET_KEY、AWS_REGION 传递给 boto3 模块
我们的示例使用第二种方法。
default_region = "us-east-1"
AWS_ACCESS_KEY = getpass("AWS Acces key: ")
AWS_SECRET_KEY = getpass("AWS Secret key: ")
AWS_REGION = input(f"AWS Region [default: {default_region}]: ") or default_region
bedrock_client = boto3.client(
service_name="bedrock-runtime",
region_name=AWS_REGION,
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY
)3. 连接到 Elasticsearch
ℹ️ 我们为此 notebook 使用 Elasticsearch 的 Elastic Cloud 部署。 如果你没有 Elastic Cloud 部署,请在此处注册免费试用。
我们将使用 Cloud ID 来标识我们的部署,因为我们使用的是 Elastic Cloud 部署。 要查找你的部署的 Cloud ID,请转至 https://cloud.elastic.co/deployments 并选择你的部署。
我们将使用 ElasticsearchStore 连接到我们的 Elastic 云部署。 这将有助于轻松创建和索引数据。 在 ElasticsearchStore 实例中,将嵌入设置为 BedrockEmbeddings 以嵌入本示例中将使用的文本和 elasticsearch 索引名称。 在本例中,我们将 strategy 设置为 ElasticsearchStore.SparseVectorRetrievalStrategy(),因为我们使用此策略来拆分文档。
当我们使用 ELSER 时,我们使用 SparseVectorRetrievalStrategy 策略。 该策略使用 Elasticsearch 的稀疏向量检索来检索 top-k 结果。 Langchain 中还有更多其他 strategies 可以根据你的需要使用。
CLOUD_ID = getpass("Elastic deployment Cloud ID: ")
CLOUD_USERNAME = "elastic"
CLOUD_PASSWORD = getpass("Elastic deployment Password: ")
vector_store = ElasticsearchStore(
es_cloud_id=CLOUD_ID,
es_user=CLOUD_USERNAME,
es_password=CLOUD_PASSWORD,
index_name= "workplace_index",
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)4. 下载数据集
让我们下载示例数据集并反序列化文档。
url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/example-apps/chatbot-rag-app/data/data.json"
response = urlopen(url)
workplace_docs = json.loads(response.read())5. 将文档分割成段落
我们将把文档分成段落,以提高检索的特异性,并确保我们可以在最终问答提示的上下文窗口中提供多个段落。
在这里,我们将文档分块为 800 个标记段落,其中有 400 个标记重叠。
这里我们使用一个简单的拆分器,但 Langchain 提供了更高级的拆分器来减少上下文丢失的机会。
metadata = []
content = []
for doc in workplace_docs:
content.append(doc["content"])
metadata.append({
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions":doc["rolePermissions"]
})
text_splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=400)
docs = text_splitter.create_documents(content, metadatas=metadata)6. 将数据索引到 Elasticsearch 中
接下来,我们将使用 ElasticsearchStore.from_documents 将数据索引到 elasticsearch。 我们将使用在创建云部署步骤中设置的云 ID、密码和索引名称值。
在实例中,我们将策略设置为 SparseVectorRetrievalStrategy()
注意:在开始索引之前,请确保你已在部署中下载并部署了 ELSER 模型,并且正在 ml 节点中运行。
documents = vector_store.from_documents(
docs,
es_cloud_id=CLOUD_ID,
es_user=CLOUD_USERNAME,
es_password=CLOUD_PASSWORD,
index_name="workplace_index",
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)7. 初始 Bedrock 硕士
接下来,我们将初始化 Bedrock LLM。 在 Bedrock 实例中,将传递 bedrock_client 和特定 model_id:amazon.titan-text-express-v1、ai21.j2-ultra-v1、anthropic.claude-v2、cohere.command-text-v14 等。你可以看到列表 Amazon Bedrock 用户指南上的可用基本模型
default_model_id = "amazon.titan-text-express-v1"
AWS_MODEL_ID = input(f"AWS model [default: {default_model_id}]: ") or default_model_id
llm = Bedrock(
client=bedrock_client,
model_id=AWS_MODEL_ID
)8. 提出问题
现在我们已经将段落存储在 Elasticsearch 中并且 LLM 已初始化,我们现在可以提出问题来获取相关段落。
retriever = vector_store.as_retriever()
qa = RetrievalQA.from_llm(
llm=llm,
retriever=retriever,
return_source_documents=True
)
questions = [
'What is the nasa sales team?',
'What is our work from home policy?',
'Does the company own my personal project?',
'What job openings do we have?',
'How does compensation work?'
]
question = questions[1]
print(f"Question: {question}\n")
ans = qa({"query": question})
print("\033[92m ---- Answer ---- \033[0m")
print(ans["result"] + "\n")
print("\033[94m ---- Sources ---- \033[0m")
for doc in ans["source_documents"]:
print("Name: " + doc.metadata["name"])
print("Content: "+ doc.page_content)
print("-------\n")尝试一下
Amazon Bedrock LLM 是一个功能强大的工具,可以通过多种方式使用。 你可以尝试使用不同的基本模型和不同的问题。 你还可以使用不同的数据集进行尝试,看看它的表现如何。 要了解有关 Amazon Bedrock 的更多信息,请查看文档。
你可以尝试在 Google Colab 中运行此示例。


![[BT]小迪安全2023学习笔记(第15天:PHP开发-登录验证)](https://img-blog.csdnimg.cn/direct/73286e3bbd6343b990a9436e057b7dee.png)


![[Linux基础开发工具---vim]关于vim的介绍、vim如何配置及vim的基本操作方法](https://img-blog.csdnimg.cn/direct/e89beae8517b4cacbea462343868986d.png)