日前,国内知名IT垂直媒体&技术社区IT168公布2023年“技术卓越奖”评选结果,经由行业CIO/CTO大咖、技术专家及IT媒体三方的联合严格评审,阿里云瑶池数据库揽获两项大奖:云原生数据库PolarDB荣获“2023年度技术卓越奖”,阿里云瑶池一站式数据管理平台荣获“2023年度创新解决方案奖”。

自2004年设立以来,IT168技术卓越奖至今成功举办了19届。作为企业信息技术领域风向标式评选,“技术卓越奖”不仅成为技术创新的“代名词”,更与行业应用深度融合。本次评选整合业界资源,以技术创新带动产业变革为核心,以知名专家和用户评价为参考依据,寻找驱动数字经济发展的新标杆和新典范,打造科技强国的创新舞台。评判标准同时代表了用户和媒体声音,年度获奖产品及解决方案等通常也对第二年的企业采购、技术创新有一定的指导作用,对行业内有深刻的影响意义。
经过评审委员会专家的严格评审,云原生数据库PolarDB凭借其出众的表现斩获2023年度技术卓越奖。该奖项旨在表彰“在功能开发层面,具有一定领先性;在专业技术领域有重大成果,并获得用户良好反馈”的数据库产品,通过了评委会结合技术和产品能力的综合评价。

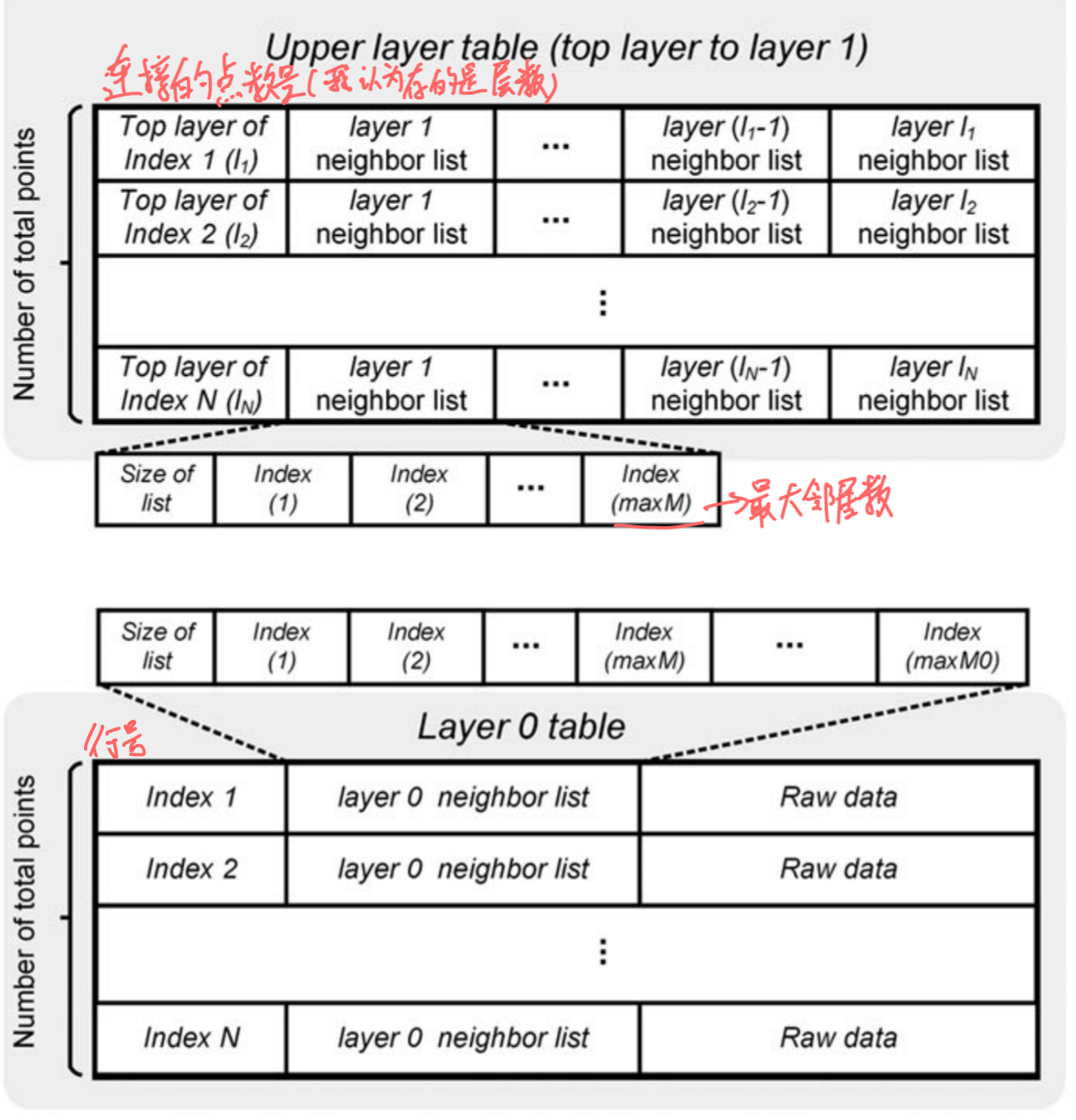
PolarDB是阿里云瑶池数据库旗下、国内首款自研的云原生数据库,在存储计算分离架构下,PolarDB利用软硬件结合等技术优势,为用户提供秒级弹性、高性能、海量存储、安全可靠的数据库服务。
产品具有多主多写、多活容灾、HTAP等特性,交易性能最高可达开源数据库的6倍,分析性能最高可达开源数据库的400倍,TCO低于自建数据库50%。100%兼容MySQL和PostgreSQL生态,高度兼容Oracle语法。无需修改代码即可使用,同时支持分布式扩展,用户可根据业务需求选择合适的版本。PolarDB分布式版支持分布式事务、全局二级索引等特性,让开发者像使用单机数据库一样、获得高性能分布式数据库的一体化体验。
阿里云瑶池持续推动以PolarDB为代表的云数据库向云原生纵深发展。1月17日,首届阿里云PolarDB开发者大会在京举办,会上,云原生数据库PolarDB发布“三层分离”全新版本,基于智能决策实现查询性能10倍提升、节省50%成本。面向开发者,阿里云全新推出数据库场景体验馆、训练营等系列新举措,广大开发者可率先免费体验PolarDB数据库核心特性及NL2BI等AI新功能。
据了解,PolarDB在过去3年实现400%的增速,目前用户数已超过10000家,广泛落地于政务、金融、电信、物流、互联网等领域的核心业务系统。
获奖理由
云原生数据库PolarDB始终以客户需求为导向,已上线的云原生HTAP、Serverless、PolarDB4AI、集中与分布式一体化等业内领先的新特性,帮助客户解决了众多业务问题。
此外,阿里云瑶池一站式数据管理平台荣膺“2023年度创新解决方案奖”。

云原生数据库正在快速向一站式数据管理与服务演进,阿里云瑶池一站式数据管理平台通过实现“云原生化、平台化、一体化、智能化”,不断为客户创造价值。
作为AIGC应用的基础设施,以PolarDB、AnalyticDB、Lindorm、RDS为核心的阿里云瑶池数据库在AI领域也在不断进行技术布局与应用探索。通过扩展面向Al的数据管理与服务能力,打造智能化的一站式数据管理平台,让云原生数据库更易用,助力用户抢占商业先机。目前,平台已全面拥抱向量检索能力,并与通义等大模型深度集成,为用户提供智能化的一站式数据管理平台,加速业务数智创新。
其他核心技术包括云原生一体化HTAP等:采用Zero-ETL技术,“PolarDB+AnalyticDB”、“RDS+ClickHouse”之间可实现亚秒级数据同步,提供统一入口的一站式HTAP体验,为用户节省10倍链路同步成本,建仓速度提升高达7倍。
获奖理由
随着云原生+Serverless的不断深入,「阿里云瑶池一站式数据管理平台」将让数据管理开发像“搭积木”一样简单实用,以性价比更高、体验更优、全链路生命周期的云数据库服务,助推用户业务提效增速。
2023年,生成式AI、大模型的火热引爆了新一轮的数智技术革命,为数据库的发展带来新的挑战和机遇。
此次入选,代表了权威媒体对阿里云瑶池数据库的深度认可。未来,瑶池数据库将在云原生的加持下,持续挖掘AI新潜力,加速迈向智能化,让个人开发者和企业用户可以像“搭积木”一样开发和管理数据库,降低数据库使用门槛,为云上AI创新的涌现夯实基础底座。
最新数据显示,目前,阿里云已连续多年位居中国云数据库市场份额第一,并在全球范围各行业的核心业务中应用落地,服务于自然人税收管理系统、全国60%的省级医保信息平台、上海证券交易所、中国移动、中国人寿、中国邮政、小米、丝芙兰Sephora、极氪汽车、美柚APP等金融、政务、电信、互联网等领域的领军企业。






![[Python] 机器学习 - 常用数据集(Dataset)之鸢尾花(Iris)数据集介绍,数据可视化和使用案例](https://img-blog.csdnimg.cn/direct/5b8ae74be2534b98b2fbb3de2b633ae6.png)