本文主要是个人笔记,记录与存储相关的ANN工作,想着写都写了不如发出来与大家分享,大多写得比较简单有些稍微详细一点,内容仅供参考。
CognitiveSSD S. Liang, Y. Wang, Y. Lu, et al. Cognitive SSD: A Deep Learning Engine for in-Storage Data Retrieval[C]//2019 USENIX annual technical conference (USENIX ATC 19). 2019: 395-410.
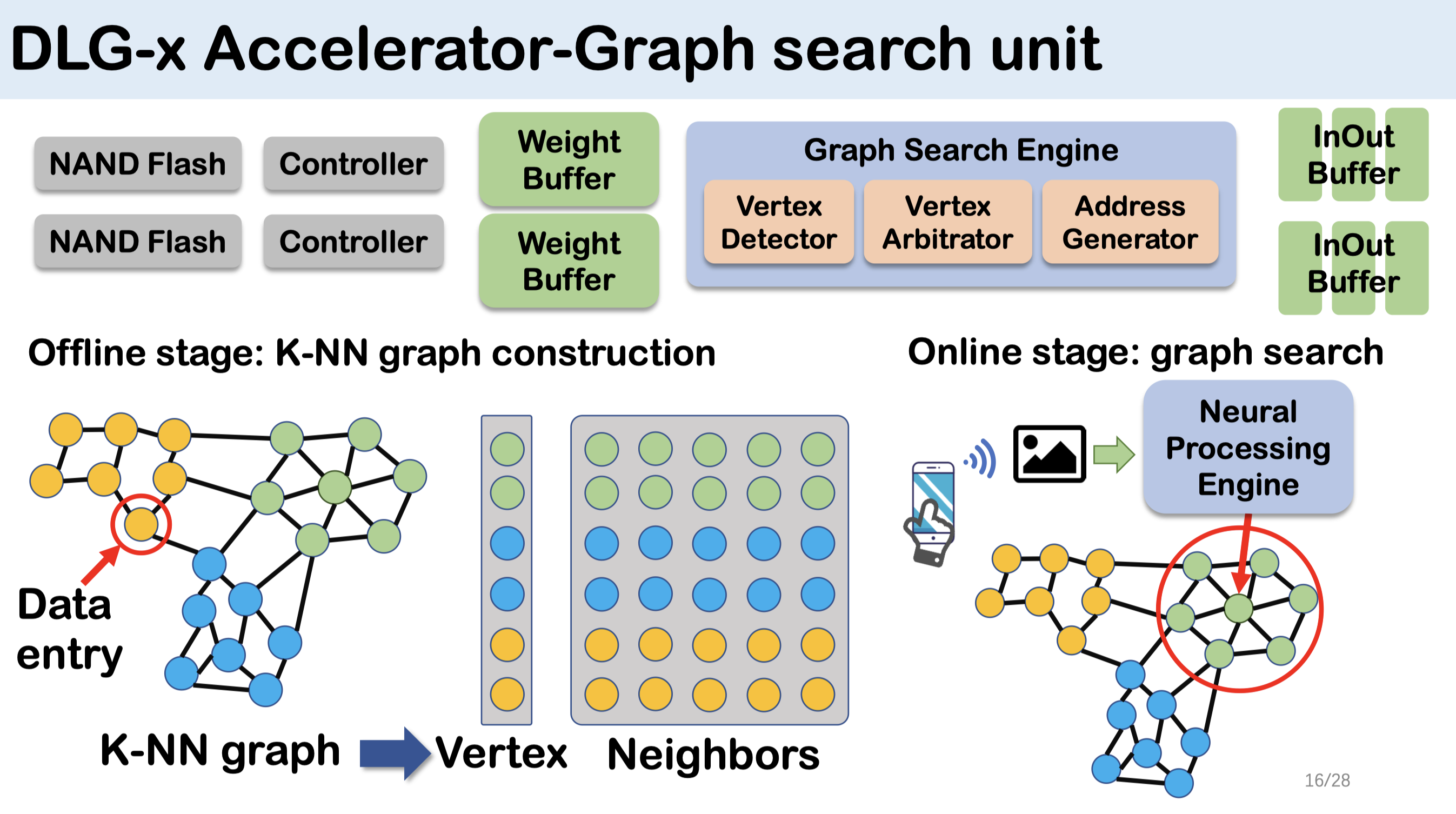
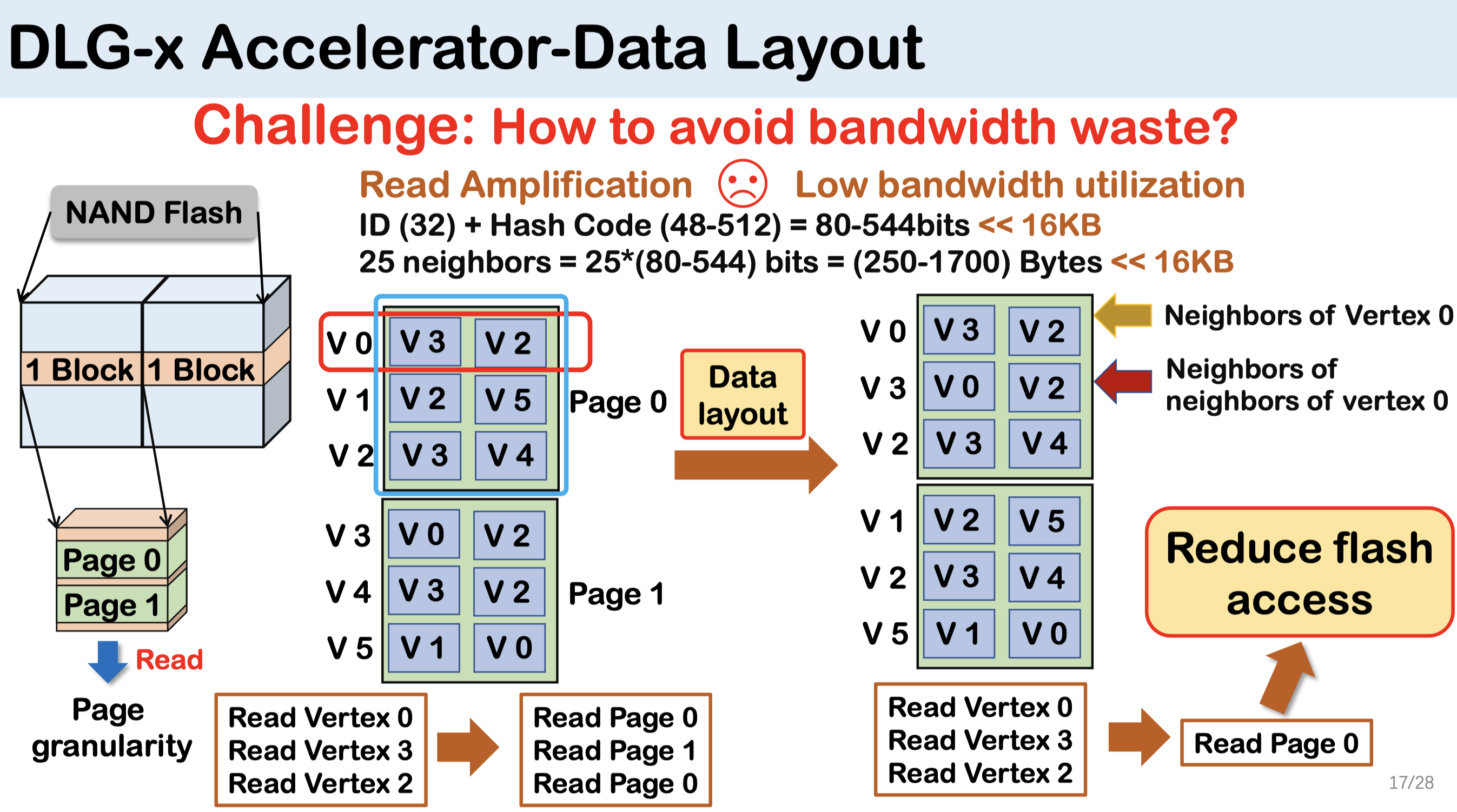
-
- 为了提高数据局部性,将节点的邻居节点保存在同一个闪存页中降低读放大。
- 但是,这种布局会导致存储中的顶点重复,并牺牲额外的存储空间以获得更好的数据访问性能
J. H. Kim, Y. R. Park, J. Do, et al. Accelerating Large-Scale Graph-Based Nearest Neighbor Search on a Computational Storage Platform[J]. IEEE Transactions on Computers, 2022, 72(1): 278-290.
解决问题:
-
- 需要大内存和高性能CPU,扩展性差
- We observe that the time spent for IO accounts for more than 70% of the total latency
方案:
-
- 数据集过大无法放入内存->将图划分为可以放入盘内DRAM的大小。然后在每个子图上进行近邻检索后合并、筛选结果。
- 原始的索引结构会导致无用数据的读取->分离表的结构,一次能够读取更多的邻居(没怎么看懂)
- 传统缓存方案命中率低(16.3%)->只缓存上层因为每次访问一定会用到
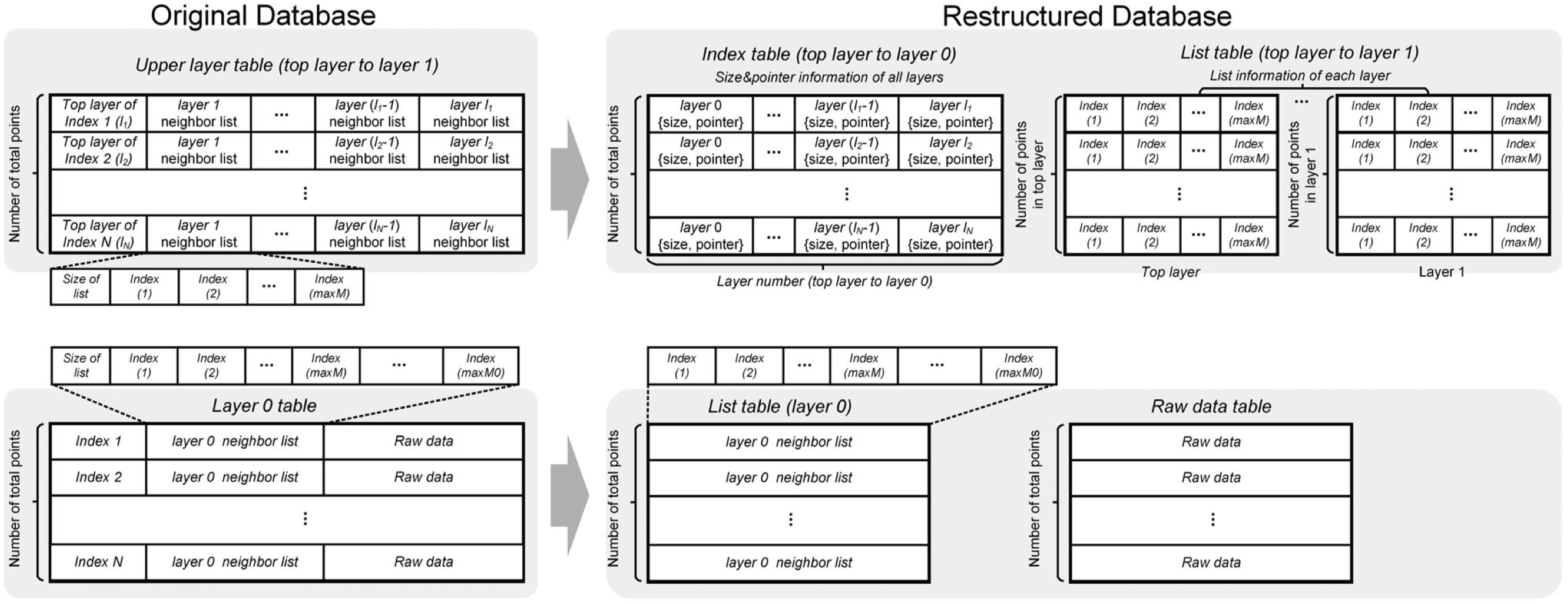
更新:这里重新解释一下数据布局的部分。他用的是HNSW算法,图有很多层,具体的图结构参考《HNSW算法》那篇博客。这里只解释一下他是怎么做数据重布局的。原始图结构和重布局后的结构如下图所示,左侧是原始的HNSW,包含2个表,一个表主要存储上层的邻居关系,一个表主要存储原始向量和底层的邻居。
至于为什么原来的图结构不行,原文并没有说清楚。原文说的是这种图结构“在上层中需要额外的计算来索引目标点,并且在0层和上层都会进行非对齐的内存访问。在图遍历的时候会增加外存访问次数”。我个人理解,是因为原始的HNSW图是存储在内存中的,所以没有考虑外存访问开销的问题,数据按照节点为中心进行组织,每个节点占用的内存空间比较大,因此想要访问一系列点的某项信息会导致很多无效数据的读取。例如,我要在顶层检索距离查询向量最近的点,那么我就要从入口点出发依次查询他的邻居。虽然入口点的邻居的index号可以很容易查询到,但是首先根据index读取原始向量需要查询maxM次0层表;其次是计算出最近点后,查询最近点的邻居又需要查询上层表并且偏移到其最后一个元素才能获取邻居的ID,访存次数十分可观。
因此,重布局的核心思想就是解耦,每个表仅存储一种信息,因此一次IO可以读取很多点的相关信息。我认为解耦后。解耦后包含3种表:①首先是把原始数据按照数组的方式顺序存放的一张Raw data table表 ②然后是list table,list table存储的是每个层次中的邻居关系,有多少层就有多少张。因此除0层外,每张表的行数是不一样的,某个点在非0层list table中的位置是未知的,那么如何索引某个点非0层的邻居呢?这就是第③张表的作用,Index table存储了每个点在每个层的邻居信息的指针。如果某个点存在于某一层,那么可以直接通过Index table存储的指针找到list table中的那一行。
不过布局优化后的检索流程,文中并没有描述。根据我的理解,还是刚刚那个例子,当在顶层从入口点出发查找邻居时,仍然需要先在Index table查询到邻居表项的指针,然后访问顶层的list table后根据邻居的index号从Raw data table读取原始数据并计算,然后再从Index table读取最近的一个邻居的邻居表项,看起来并没有减少I/O次数。可能是我理解不到位吧。
但是解耦后是否会产生问题,例如更新的开销是否会急剧增加?(不过一般都没有考虑图更新的问题)其次这个是否还有可以优化的地方,例如每行之间是随机排布的吗,可以按照邻居关系对他进行排列提高读取数据的效率。
J. Jang, H. Choi, H. Bae, et al. CXL-ANNS:Software-Hardware Collaborative Memory Disaggregation and Computation for Billion-Scale Approximate Nearest Neighbor Search[C]//2023 USENIX Annual Technical Conference (USENIX ATC 23). 2023: 585-600.
Knowledge:
-
- Microsoft search engines (used in Bing/Outlook) require 100B+ vectors, each being explained by 100 dimensions, which consume more than 40TB memory space
- Alibaba’s e-commerce platforms need TB-scale memory spaces to accommodate their 2B+ vectors (128 dimensions)
解决问题:
传统的量化方案会导致精度损失,而非量化方案又会导致大量的内存占用,难以在单机上满足需求,CXL的出现使其成为了可能。然而CXL内存池的访问延迟比本地DRAM延迟高很多,如果单纯的将ANN部署在CXL内存池上会出现性能的严重下降(约3-5x,图8)。
方案:
为了提高在CXL扩展内存上执行ANN的性能,CXL-ANN做了以下工作:
-
- 分区缓存。因为许多ANN算法的入口点都是一样的,因此CXL-ANN将入口点附近N条的邻居缓存到本地内存中,而不是采用动态缓存替换。
- 预取邻居。CXL-ANN观察到(图18)有80%左右的后续访问都是候选列表更新前的节点。因此CXL-ANN在图遍历立即读取候选列表中前面的节点,而不是等主机更新候选列表后再发起读请求。提高命中率降低I/O开销。
- 在CXL设备上进行近存处理。因为主机只需要获取两个节点的距离,不需要读取完整的节点,因此在CXL设备上进行距离计算后返回结果,可以节约大量的I/O开销。
- 任务调度。候选列表的更新包含插入、排序、选取三个步骤。为了尽快发起图遍历请求,CXL-ANN优先执行节点选取操作,选出节点发起I/O请求后再进行耗时的插入和排序。
Z. Zhu, J. Liu, G. Dai, et al. Processing-In-Hierarchical-Memory Architecture for Billion-Scale Approximate Nearest Neighbor Search[C]//2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023: 1-6.
Knowledge:
-
- The memory capacity of main memory level NMC (e.g., 64GB) cannot meet the storage requirement of ANNS on billion-scale datasets (e.g., 800GB)
- The major performance bottleneck of CPU-based ANNS systems is the tremendous amount of data access that accounts for 80% of the total search time.
解决问题:
使用近存架构处理ANN时,近内存计算可能内存容量不足,近存储计算会由于不规则的I/O访问导致高I/O开销,读有效率和命中率分别只有39% 和16%。需要结合近内存和近存储的优势以提高性能。
方案:
-
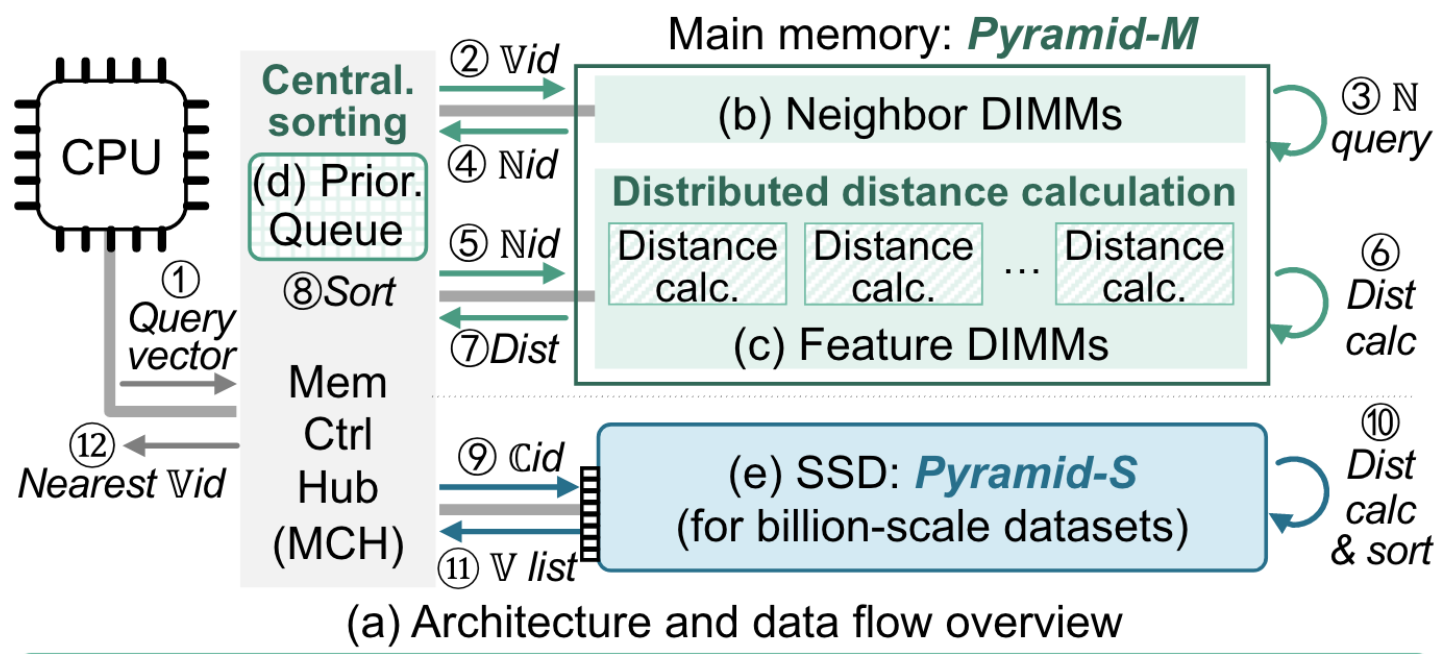
- 所谓的充分利用近内存和近存储的优势,就是把节点聚类后,将中心点存到内存中便于索引图,然后这个聚类中的其他节点集中存到存储器中便于集中读取。
- 整体架构如下图。现在内存中读取到邻居,然后返回邻居的索引Nid。然后根据Nid获取到邻居的向量并且计算邻居和查询节点的距离,这一步用近内存计算加速计算。获取到最近的邻居后,根据最近的邻居的Cid去SSD中获取到该聚类中的所有向量,然后返回topK个节点,这一步用近存储计算做加速。
-
- 还有一些加速器的工作,例如近存计算的距离计算加速器、topK排序加速器和SSD中的每个通道上的距离计算加速器。
- 为了提高吞吐量,一批一批地处理查询以便于充分利用SSD的多通道并行性。(感觉这个不算一个设计点,因为并发地发起查询请求自然就能达到这个效果)。
问题:
-
-
- 需要将图划分得比较细然后建立索引,内存开销仍然很高。
-
Q. Chen, B. Zhao, H. Wang, et al. Spann: Highly-Efficient Billion-Scale Approximate Nearest Neighborhood Search[J]. Advances in Neural Information Processing Systems, 2021, 34: 5199-5212.
解决问题:单个磁盘访问粒度在几十到几百 KB 不等,且不具备访问的局部性,因此不能有效地利用外部存储器件的预读机制和操作系统的缓存机制,同时产生读放大。
方案:针对大规模向量近似搜索场景,采用小内存和大硬盘混合存储的策略。SPANN 基于倒排文件设计,能够有效地将相似的向量以小规模聚类集合的方式连续地存储在磁盘上,通过加载有限个数的聚类集合来减少磁盘访问。
SPANN 采用查询感知的剪枝方法来调整不同查询向量需要加载的候选聚类的数目。通常,在倒排文件的检索过程中,首先会找到相同个数个最近的聚类中心点,然后对固定个聚类进行全量的搜索。然后,由于查询向量具有差异,有的“容易”查询向量只需要检索少数的聚类就能够获得高召回,而有的“难”查询向量需要检索更多的聚类。倒排文件使用相同的查找聚类个数会导致“容易”的查询向量需要检索很多召回收益不高的聚类。SPANN 通过查询向量与聚类中心点的距离远近程度来确定对该聚类的搜索是否是高召回收益的。SPANN 利用查询向量到与其最近的聚类中心点 的距离 作为尺度,使用搜索参数 来控制动态剪枝的程度。当查询向量和某聚类中心点的距离大于 ,则认为是查询向量和中心点距离较远,对这一聚类进行进一步搜索的收益不高,可以进行剪枝,不对其进行搜索。