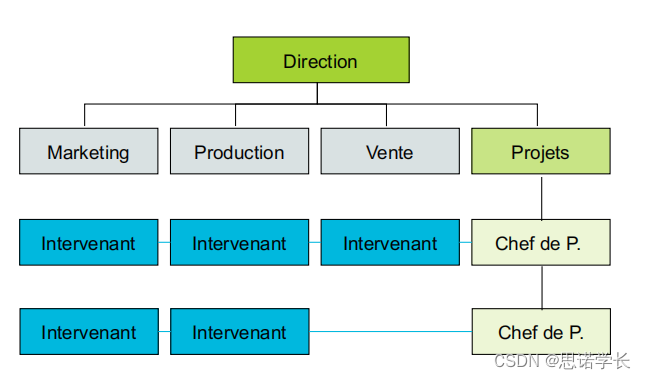
链路图
一个完整的RPC请求中,netty对请求数据和响应数据的处理流程如下图所示
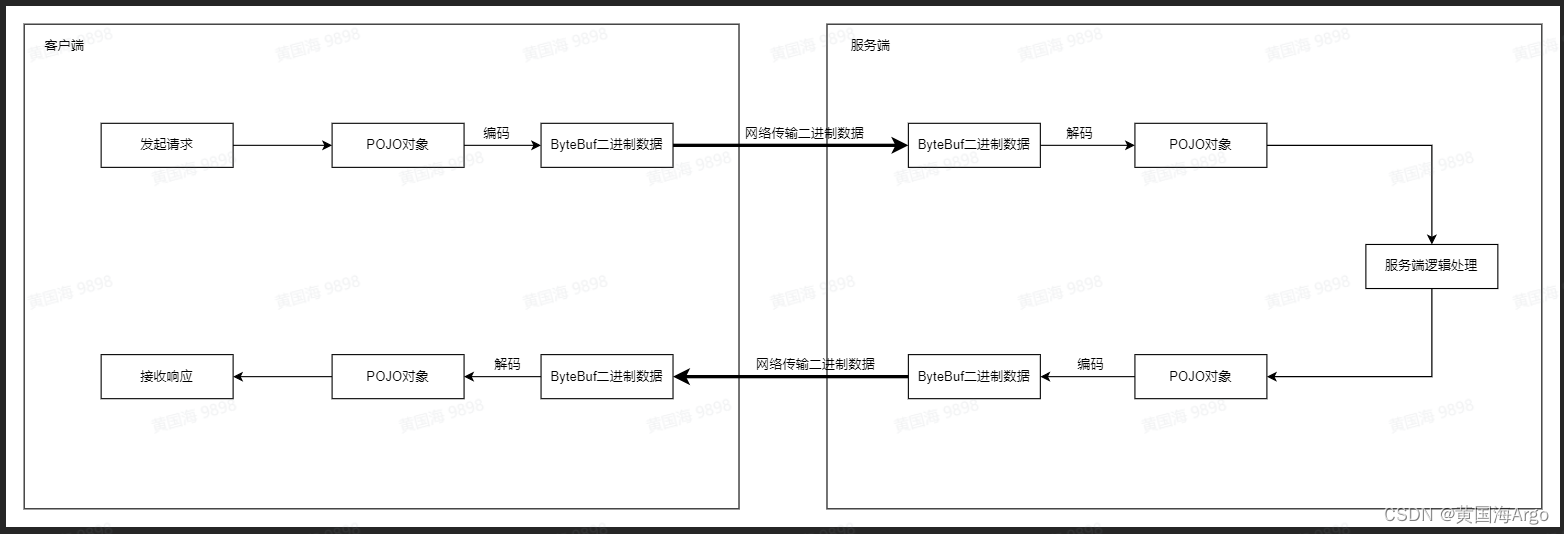
网络线路中传输的都是二进制数据,之后netty将二进制数据解码乘POJO对象,让客户端或者服务端程序处理。
解码的工具称为解码器,是一个入站处理器InBound。
编码的工具称为编码器,是一个处长处理器OutBound。
解码器
原理
解码器作为一个入站处理器,它需要将上一个入站处理器传过来的输入数据进行数据的编码或者格式转换,然后输出到下一站的入站处理器。
通常使用的ByteToMessageDecoder解码器将输入类型为ByteBuf缓冲区的数据进行解码,输出一个一个的POJO对象。
ByteToMessageDecoder是一个抽象类,继承关系如图
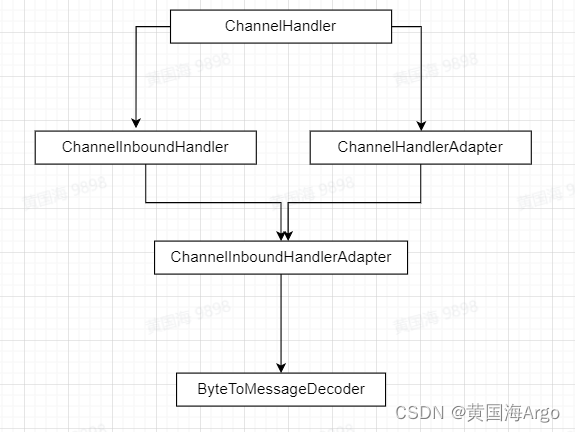
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;ByteToMessageDecoder使用了模板模式,只定义了解码的流程,具体的解码逻辑由子类完成。也就是开放了decode解码方法,由具体的解码器实现。
重申一下Netty对于handler的管理是通过通道pipeline完成的,所以解码器后面的处理器可以是业务处理器。
业务处理器接收解码结果,进行业务处理。
解码器中有一个比较重要的实现是ReplayingDecoder(也是一个抽象类),它在读取ByteBuf缓冲区的数据之前,需要检查缓冲区是否有足够的字节,如果缓冲区中字节足够,则会正常读取,反之,则会停止解码。等待下一次IO时间到来时再读取。
ReplayingDecoder在内部定义了一个新的二进制缓冲区类,对ByteBuf缓冲区进行了修饰,也就是ReplayingDecoderBuffer。
也就是说,继承ReplayingDecoder的子类解码器收到的二进制数据是经过ReplayingDecoderBuffer修饰过,判断过的。不是直接读取的ByteBuf中的数据。
ReplayingDecoder除了对ByteBuf数组的修饰以外,另一个作用,也更重要的作用是做分包传输。
我们知道底层通信协议是分包传输的。也就是我们预期的包大小和顺序可能和实际的并不一样,这时候就可以通过ReplayingDecoder来处理,ReplayingDecoder通过state属性来控制状态变化。比如如下sock鉴权解码器
public class SocksAuthRequestDecoder extends ReplayingDecoder<State> {
private String username;
public SocksAuthRequestDecoder() {
super(State.CHECK_PROTOCOL_VERSION);
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf byteBuf, List<Object> out) throws Exception {
switch (state()) {
case CHECK_PROTOCOL_VERSION: {
if (byteBuf.readByte() != SocksSubnegotiationVersion.AUTH_PASSWORD.byteValue()) {
out.add(SocksCommonUtils.UNKNOWN_SOCKS_REQUEST);
break;
}
checkpoint(State.READ_USERNAME);
}
case READ_USERNAME: {
int fieldLength = byteBuf.readByte();
username = SocksCommonUtils.readUsAscii(byteBuf, fieldLength);
checkpoint(State.READ_PASSWORD);
}
case READ_PASSWORD: {
int fieldLength = byteBuf.readByte();
String password = SocksCommonUtils.readUsAscii(byteBuf, fieldLength);
out.add(new SocksAuthRequest(username, password));
break;
}
default: {
throw new Error();
}
}
ctx.pipeline().remove(this);
}
@UnstableApi
public enum State {
CHECK_PROTOCOL_VERSION,
READ_USERNAME,
READ_PASSWORD
}
}以上是偏分阶段解码,适用于那些固定长度的数据,比如整型等,但对于字符串来说,可长可短,没有具体的长度限制。如果用ReplayingDecoder来实现
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf byteBuf, List<Object> out) throws Exception {
switch (state()) {
case PARSE_1: {
//基于Header-Content协议传输,Header中带有content长度,用一个int长度标识即可
length = in.readInt();
inBytes = new byte[];
break;
}
case PARSE_2: {
in.readBytes(inBytes,0,length);
out.add(new String(inBytes,"UTF-8"));
}
default: {
throw new Error();
}
}
ctx.pipeline().remove(this);
}但其实对于比较复杂的业务场景中,不太建议使用ReplayingDecoder,主要原因是ReplayingDecoer在解析速度上相对较差,试想一下,replayingDecoder长度不够时,会停止解码。也就是说一个请求会被解码多次才可能最终完成。
对于字符串分包传输来说,更适合直接继承ByteToMessageDecoder基类来完成Header-Content协议的解析
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf byteBuf, List<Object> out) throws Exception {
if(buf.readableBytes()<4){
//可读字节小于4,消息头还没读满,返回。(假设Header是一个int的数据
return;
}
buf.markReaderIndex();
int length = buf.readInt();
if(buf.readableBytes()<length){
buf.resetReaderIndex();
}
byte[] inBytes = new byte[length];
buf.readBytes(inBytes,0,length);
out.add(new String(inBytes,"UTF-8"));
}除了ByteToMessageDecoder这种将二进制数据转化为POJO对象的解码器以外,还有将一种POJO转为另一种POJO对象的解码器,MessageToMessageDecoder,不同的是,后者需要指明泛型类型。比如Integer转为String,这时候泛型类型为Integer。
Netty内置的开箱即用的Decoder
FixedLengthFrameDecoder-固定长度数据包解码器
他会把入站ByteBuf数据包拆分成一个个长度为n的数据包,然后发往下一个channelHandler入站处理器
LineBasedFrameDecoder-行分割数据包解码器
如果ByteBuf数据包使用换行符/回车符作为数据包的边界分隔符。这时他会把数据包按换行符/回车符拆分成一个个数据包。
有一个行最大长度限制,如果超过这个长度还没有发现分隔符,会抛出异常
DelimiterFrameDecoder-自定义分隔符数据包解码器
他会按照自定义分隔符将ByteBuf数据包进行拆分
LengthFieldBasedFrameDecoder-自定义长度数据包解码器
基于灵活长度的数据包,在ByteBuf数据包中,加了一个长度字段,保存了原始数据包长度,解码的时候,会按照这个长度进行原始数据包的提取。
一般基于Header-Content协议的数据包,都建议使用这个解码器
public class LengthFieldBasedFrameDecoder extends ByteToMessageDecoder {
private final int maxFrameLength; //发送的数据包最大长度
private final int lengthFieldOffset; //长度字段偏移量
private final int lengthFieldLength; //长度字段自己占用的字节数
private final int lengthAdjustment; //长度字段的偏移量矫正,比如长度后面还有两个字节用于存储别的信息,那么该值为2
private final int initialBytesToStrip; //丢弃的起始字节数
...
}编码器
原理
所谓的编码器就是服务端应用程序处理完之后,一般会有一个响应结果Response。也就是一个Java POJO对象。需要将他编码为最终ByteBuf二进制类型。通过流水线写入到底层的Java通道。
上面说,解码器是一个入站处理器,那么编码器就是一个出站处理器。也就是OutboundHandler。处理逻辑为每个出站处理器会将上一个出站处理器的结果作为输入,经过处理后,传递给下一个出站处理器,直至最后写入Java通道。
由于出站处理器是从后向前执行的,所以第一个处理器一定是需要将结果处理成ByteBuf类型的数据。
MessageToByteEncoder同ByteToMessageDecoder一样都是一个抽象类,用模板模式。其中encode方法由子类实现。
在最后一步之前,可能会需要将一种POJO对象转成另一种POJO对象,就像解码器中的MessageToMessageDecoder一样,编码器也有同样的MessageToMessageEncoder解码器抽象类。
编解码器
所谓的编解码器也就是把解码器和编码器放在同一个类中,这个类就叫做ByteToMessageCodec,需要同时实现encode和decode方法。
不过这样的话,解码和编码的不同的代码就会出现在一个类中。出现逻辑混乱。Netty提供了另一种方式可以让编码代码和解码代码放在两个类,同时把编码工作和解码工作组合起来
编解码组合器
这个编解码组合器称为CombinedChanneldDuplexHandler组合器,比如客户端的编解码组合器就是用的这种方式
public final class HttpClientCodec extends CombinedChannelDuplexHandler<HttpResponseDecoder, HttpRequestEncoder>
implements HttpClientUpgradeHandler.SourceCodec {
...
}
public class HttpResponseDecoder extends HttpObjectDecoder {
...
}
public abstract class HttpObjectDecoder extends ByteToMessageDecoder {
private enum State {
SKIP_CONTROL_CHARS,
READ_INITIAL,
READ_HEADER,
READ_VARIABLE_LENGTH_CONTENT,
READ_FIXED_LENGTH_CONTENT,
READ_CHUNK_SIZE,
READ_CHUNKED_CONTENT,
READ_CHUNK_DELIMITER,
READ_CHUNK_FOOTER,
BAD_MESSAGE,
UPGRADED
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception {
if (resetRequested) {
resetNow();
}
switch (currentState) {
case SKIP_CONTROL_CHARS:
// Fall-through
case READ_INITIAL: try {
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
String[] initialLine = splitInitialLine(line);
if (initialLine.length < 3) {
// Invalid initial line - ignore.
currentState = State.SKIP_CONTROL_CHARS;
return;
}
message = createMessage(initialLine);
currentState = State.READ_HEADER;
// fall-through
} catch (Exception e) {
out.add(invalidMessage(buffer, e));
return;
}
case READ_HEADER: try {
State nextState = readHeaders(buffer);
if (nextState == null) {
return;
}
currentState = nextState;
switch (nextState) {
case SKIP_CONTROL_CHARS:
// fast-path
// No content is expected.
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
case READ_CHUNK_SIZE:
if (!chunkedSupported) {
throw new IllegalArgumentException("Chunked messages not supported");
}
// Chunked encoding - generate HttpMessage first. HttpChunks will follow.
out.add(message);
return;
default:
/**
* <a href="https://tools.ietf.org/html/rfc7230#section-3.3.3">RFC 7230, 3.3.3</a> states that if a
* request does not have either a transfer-encoding or a content-length header then the message body
* length is 0. However for a response the body length is the number of octets received prior to the
* server closing the connection. So we treat this as variable length chunked encoding.
*/
long contentLength = contentLength();
if (contentLength == 0 || contentLength == -1 && isDecodingRequest()) {
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
}
assert nextState == State.READ_FIXED_LENGTH_CONTENT ||
nextState == State.READ_VARIABLE_LENGTH_CONTENT;
out.add(message);
if (nextState == State.READ_FIXED_LENGTH_CONTENT) {
// chunkSize will be decreased as the READ_FIXED_LENGTH_CONTENT state reads data chunk by chunk.
chunkSize = contentLength;
}
// We return here, this forces decode to be called again where we will decode the content
return;
}
} catch (Exception e) {
out.add(invalidMessage(buffer, e));
return;
}
case READ_VARIABLE_LENGTH_CONTENT: {
// Keep reading data as a chunk until the end of connection is reached.
int toRead = Math.min(buffer.readableBytes(), maxChunkSize);
if (toRead > 0) {
ByteBuf content = buffer.readRetainedSlice(toRead);
out.add(new DefaultHttpContent(content));
}
return;
}
case READ_FIXED_LENGTH_CONTENT: {
int readLimit = buffer.readableBytes();
// Check if the buffer is readable first as we use the readable byte count
// to create the HttpChunk. This is needed as otherwise we may end up with
// create an HttpChunk instance that contains an empty buffer and so is
// handled like it is the last HttpChunk.
//
// See https://github.com/netty/netty/issues/433
if (readLimit == 0) {
return;
}
int toRead = Math.min(readLimit, maxChunkSize);
if (toRead > chunkSize) {
toRead = (int) chunkSize;
}
ByteBuf content = buffer.readRetainedSlice(toRead);
chunkSize -= toRead;
if (chunkSize == 0) {
// Read all content.
out.add(new DefaultLastHttpContent(content, validateHeaders));
resetNow();
} else {
out.add(new DefaultHttpContent(content));
}
return;
}
/**
* everything else after this point takes care of reading chunked content. basically, read chunk size,
* read chunk, read and ignore the CRLF and repeat until 0
*/
case READ_CHUNK_SIZE: try {
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
int chunkSize = getChunkSize(line.toString());
this.chunkSize = chunkSize;
if (chunkSize == 0) {
currentState = State.READ_CHUNK_FOOTER;
return;
}
currentState = State.READ_CHUNKED_CONTENT;
// fall-through
} catch (Exception e) {
out.add(invalidChunk(buffer, e));
return;
}
case READ_CHUNKED_CONTENT: {
assert chunkSize <= Integer.MAX_VALUE;
int toRead = Math.min((int) chunkSize, maxChunkSize);
if (!allowPartialChunks && buffer.readableBytes() < toRead) {
return;
}
toRead = Math.min(toRead, buffer.readableBytes());
if (toRead == 0) {
return;
}
HttpContent chunk = new DefaultHttpContent(buffer.readRetainedSlice(toRead));
chunkSize -= toRead;
out.add(chunk);
if (chunkSize != 0) {
return;
}
currentState = State.READ_CHUNK_DELIMITER;
// fall-through
}
case READ_CHUNK_DELIMITER: {
final int wIdx = buffer.writerIndex();
int rIdx = buffer.readerIndex();
while (wIdx > rIdx) {
byte next = buffer.getByte(rIdx++);
if (next == HttpConstants.LF) {
currentState = State.READ_CHUNK_SIZE;
break;
}
}
buffer.readerIndex(rIdx);
return;
}
case READ_CHUNK_FOOTER: try {
LastHttpContent trailer = readTrailingHeaders(buffer);
if (trailer == null) {
return;
}
out.add(trailer);
resetNow();
return;
} catch (Exception e) {
out.add(invalidChunk(buffer, e));
return;
}
case BAD_MESSAGE: {
// Keep discarding until disconnection.
buffer.skipBytes(buffer.readableBytes());
break;
}
case UPGRADED: {
int readableBytes = buffer.readableBytes();
if (readableBytes > 0) {
// Keep on consuming as otherwise we may trigger an DecoderException,
// other handler will replace this codec with the upgraded protocol codec to
// take the traffic over at some point then.
// See https://github.com/netty/netty/issues/2173
out.add(buffer.readBytes(readableBytes));
}
break;
}
default:
break;
}
}
...
}