1、加法运算
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]]),
# tensor([[ 0., 2., 4., 6.],
# [ 8., 10., 12., 14.],
# [16., 18., 20., 22.],
# [24., 26., 28., 30.],
# [32., 34., 36., 38.]])2、乘法运算

A * B
# tensor([[ 0., 1., 4., 9.],
# [ 16., 25., 36., 49.],
# [ 64., 81., 100., 121.],
# [144., 169., 196., 225.],
# [256., 289., 324., 361.]])将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
import torch
a = 2
X = torch.arange(24).reshape(2, 3, 4)
print(X)
# tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]])
print((a + X).shape)
# torch.Size([2, 3, 4])
print(a + X)
# tensor([[[ 2, 3, 4, 5],
# [ 6, 7, 8, 9],
# [10, 11, 12, 13]],
# [[14, 15, 16, 17],
# [18, 19, 20, 21],
# [22, 23, 24, 25]]])
3、降维
可以计算任意形状张量的元素和。

import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
print(A.sum())
# tensor(190.)指定张量沿哪一个轴来通过求和降低维度。
为了通过求和所有行的元素来降维(轴0),可以在调用函数时指定axis=0。 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
A_sum_axis0 = A.sum(axis=0)
print(A_sum_axis0)
# tensor([40., 45., 50., 55.])
A_sum_axis0 = A.sum(axis=1)
print(A_sum_axis0)
# tensor([ 6., 22., 38., 54., 70.])沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
print(A.sum(axis=[0, 1]))
# tensor(190.)平均值通过将总和除以元素总数来计算平均值。
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
print(A.mean())
# tensor(9.5000)
print(A.sum() / A.numel())
# tensor(9.5000)计算平均值的函数也可以沿指定轴降低张量的维度。
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
print(A.mean(axis=0))
# tensor([ 8., 9., 10., 11.])
print(A.sum(axis=0) / A.shape[0])
# tensor([ 8., 9., 10., 11.])4、非降维求和
有时在调用函数来计算总和或均值时保持轴数不变会很有用。
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
sum_A = A.sum(axis=1, keepdims=True)
print(sum_A)
# tensor([[ 6.],
# [22.],
# [38.],
# [54.],
# [70.]])
由于sum_A在对每行进行求和后仍保持两个轴,可以通过广播将A除以sum_A。
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
sum_A = A.sum(axis=1, keepdims=True)
# tensor([[ 6.],
# [22.],
# [38.],
# [54.],
# [70.]])
print(A / sum_A)
# tensor([[0.0000, 0.1667, 0.3333, 0.5000],
# [0.1818, 0.2273, 0.2727, 0.3182],
# [0.2105, 0.2368, 0.2632, 0.2895],
# [0.2222, 0.2407, 0.2593, 0.2778],
# [0.2286, 0.2429, 0.2571, 0.2714]])
沿某个轴计算A元素的累积总和, 比如axis=0(按行计算),可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
print(A.cumsum(axis=0))
# tensor([[ 0., 1., 2., 3.],
# [ 4., 6., 8., 10.],
# [12., 15., 18., 21.],
# [24., 28., 32., 36.],
# [40., 45., 50., 55.]])5、点积
torch.dot(x,y) 点积是两个向量相同位置的按元素乘积的和。
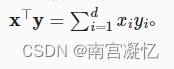
import torch
x = torch.arange(4, dtype=torch.float32)
print(x)
# tensor([0., 1., 2., 3.])
y = torch.ones(4, dtype = torch.float32)
print(y)
# tensor([1., 1., 1., 1.])
print(torch.dot(x, y))
# tensor(6.)也可以通过执行按元素乘法,然后进行求和来表示两个向量的点积。
import torch
x = torch.arange(4, dtype=torch.float32)
print(x)
# tensor([0., 1., 2., 3.])
y = torch.ones(4, dtype = torch.float32)
print(y)
# tensor([1., 1., 1., 1.])
print(torch.sum(x * y))
# tensor(6.)
6、矩阵-向量积
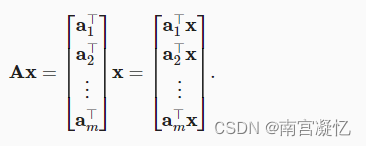
将矩阵A用它的行向量表示
每个ai⊤都是行向量,表示矩阵的第i行。

import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
x = torch.arange(4, dtype=torch.float32)
print(x)
# tensor([0., 1., 2., 3.])
print(torch.mv(A, x))
# tensor([ 14., 38., 62., 86., 110.])7、矩阵-矩阵乘法
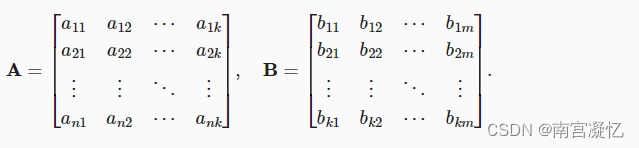
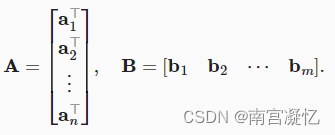 ai行向量, bj列向量。
ai行向量, bj列向量。
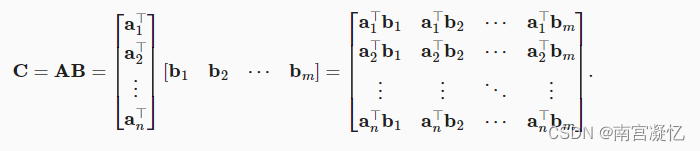
import torch
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
B = torch.ones(4, 3)
print(B)
# tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]])
print(torch.mm(A, B))
# tensor([[ 6., 6., 6.],
# [22., 22., 22.],
# [38., 38., 38.],
# [54., 54., 54.],
# [70., 70., 70.]])8、范数
向量的范数是表示一个向量有多大。这里考虑的大小(size)概念不涉及维度,而是分量的大小。
向量范数是将向量映射到标量的函数f。
给定任意向量X,向量范数要满足一些属性。
第一个性质是:如果我们按常数因子a缩放向量的所有元素, 其范数也会按相同常数因子的绝对值缩放:

第二个性质是熟悉的三角不等式:
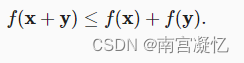
第三个性质简单地说范数必须是非负的:
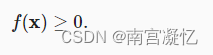
L2范数是向量元素平方和的平方根(向量)
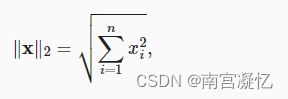
import torch
u = torch.tensor([3.0, -4.0])
print(torch.norm(u))
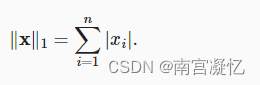
# tensor(5.)L1范数是向量元素的绝对值
import torch
u = torch.tensor([3.0, -4.0])
print(torch.abs(u).sum())
# tensor(7.)Lp一般范数
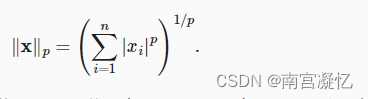
Frobenius范数是矩阵元素平方和的平方根(矩阵的L2范数)
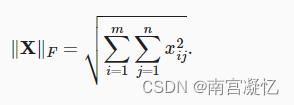
import torch
z = torch.ones((4, 9))
# tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1., 1., 1., 1.]])
print(torch.norm(z))
# tensor(6.)
# (9*4)^(1/2)范数和目标
在深度学习中,我们经常试图解决优化问题:
- 最大化分配给观测数据的概率;
- 最小化预测和真实观测之间的距离。
用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。
目标是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。





![[BUG] Authentication Error](https://img-blog.csdnimg.cn/direct/a145274518aa41e9a92c02cd79f35425.png)