「发表于知乎专栏《移动端算法优化》」
本文首先给出 OpenCL 运行时 API 的整体编程流程图,然后针对每一步介绍使用的运行时 API,讲解 API 参数,并给出编程运行实例。总结运行时 API 使用的注意事项。最后展示基于 OpenCL 的图像转置代码。在 865 平台下,对于 4096x4096 的 8 位图像加速比达到 10 倍以上。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
一、概述
二、OpenCL 运行时 API 的编程流程
2.1 OpenCL Host 端编程全流程
2.2 OpenCL Host端编程分步详解
2.2.1 获取平台Platform
2.2.2 获取设备Device
2.2.3 创建上下文Context
2.2.4 创建命令队列 CommandQueue
2.2.5 创建并编译内核程序 Program
2.2.6 创建内核对象Kernel
2.2.7 创建内存对象
2.2.7.1 OpenCL Buffer API 说明
2.2.7.2 OpenCL Image API 说明
2.2.8 设置 kernel 参数
2.2.9 执行内核
2.2.10 主机和设备同步
2.2.11 读取 Device 处理结果
2.2.12 清理 OpenCL 资源
2.3 API 使用注意事项
三、OpenCL图像转置示例
3.1 代码展示
3.2 运行结果
3.3 说明
四、总结
五、工程代码
一、概述
OpenCL 作为一套通用异构平台编程框架,由两个部分组成:其一是在主机处理器(Host)执行的运行时 API;其二是基于 C99 标准扩展的 OpenCL C 语言,用于编写在设备处理器(OpenCL device)运行的内核(kernel)代码。
Host 端的运行时 API 负责管理资源,控制 host 和 device 端程序执行,构成了 OpenCL 程序的框架。不恰当地使用 OpenCL 运行时 API 可能带来极大的性能损失,甚至造成程序崩溃。
接下来我们会对 OpenCL 运行时 API 做系统而详细的介绍。首先给出 OpenCL 运行时 API 的整体编程流程图,然后针对每一步结合实例说明,最后展示基于 OpenCL 的图像转置代码并计算加速比。
二、OpenCL 运行时 API 的编程流程
2.1 OpenCL Host 端编程全流程
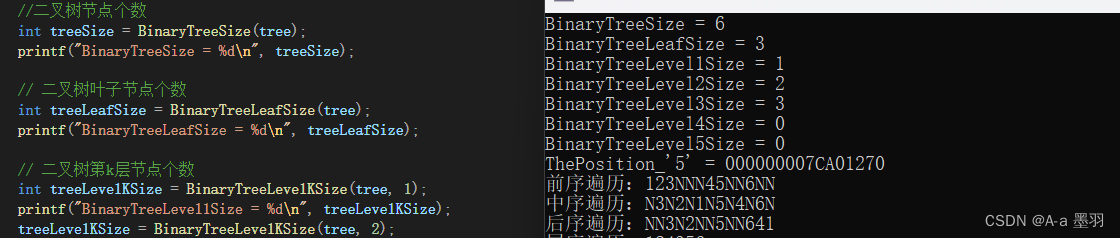
下图展示了一张典型的 OpenCL Host 端编程流程图。接下来我们会解释每一步的作用,列出相关的API并展示实例代码。

基于 OpenCL 运行时 API 的 Host 编程流程
使用 OpenCL API 编程务必及时检查 API 的返回值是否为 CL_SUCCESS。为了简化篇幅,第二节示例代码不检查 API 返回值,省略 malloc 内存释放。
2.2 OpenCL Host端编程分步详解
2.2.1 获取平台Platform
作用说明
Host 端编程第 1 步是获取硬件平台 Platform,查询 OpenCL 版本等平台信息。使用 clGetPlatformIDs 和 clGetPlatformInfo 两个API。
API函数说明
- clGetPlatformIDs
cl_int clGetPlatformIDs( cl_uint num_entries,
cl_platform_id *platforms,
cl_uint *num_platforms)
功能描述:
OpenCL 使用cl_platform_id表示平台,通过clGetPlatformIDs获取可使用的平台数组。当平台数未知,第一次调用clGetPlatformIDs获取平台个数,第二次调用clGetPlatformIDs获取平台对象。
参数说明:
- num_entries[IN] :要获取的平台数量,如果 platforms 非空,则 num_entries 不能为 0。
- platforms[OUT] :返回获取的平台对象数组。
-num_platforms[OUT] :用于查询返回可用的平台数目, num_platforms 可设为 NULL 忽略。
- Return :正常执行返回CL_SUCCESS,异常返回值请参考[1]中 4.1节。
- clGetPlatformInfo
cl_int clGetPlatformInfo( cl_platform_id platform,
cl_platform_info param_name,
size_t param_value_size,
void *param_value,
size_t *param_value_size_ret)
功能描述:
获取平台相关信息,如 OpenCL 配置版本。
参数说明:
- platform[IN] :查询的平台对象。
- param_name[IN] :表示平台查询参数的枚举常量,参考表 2-1。
- param_value_size [IN] : param_value 指向内存空间的字节数。
- param_value[OUT] :指向返回查询参数结果的内存指针。
- param_value_size_ret[OUT] :返回查询参数的实际长度。
- Return :正常执行返回CL_SUCCESS,异常返回值请参考[1]中 4.1 节。
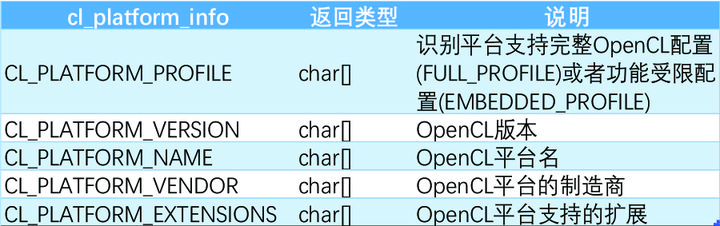
表2-1 OpenCL平台属性表
实例代码
下面给出两步查询法获取平台及相关信息的实例代码。
void PrintPlatformMsg(cl_platform_id *platform, cl_platform_info platform_info,
const char *platform_msg)
{
size_t size;
int err_num;
// 1. 第一步通过size获取打印字符串长度
err_num = clGetPlatformInfo(*platform, platform_info, 0, NULL, &size);
char *result_string = (char *)malloc(size);
// 2. 第二步获取平台信息到result_string
err_num = clGetPlatformInfo(*platform, platform_info, size, result_string, NULL);
printf("%s=%s\n", platform_msg, result_string);
free(result_string);
result_string = NULL;
}
cl_int err_num;
cl_uint num_platform;
cl_platform_id *platform_list;
// 1. 第一次调用获取平台数
err_num = clGetPlatformIDs(0, NULL, &num_platform);
printf("num_platform=%d\n", num_platform);
platform_list = (cl_platform_id *)malloc(sizeof(cl_platform_id) * num_platform);
// 2. 第二次调用获取平台对象数组
err_num = clGetPlatformIDs(num_platform, platform_list, NULL);
printf("err_num = %d\n", err_num);
// 打印平台信息
PrintPlatformMsg(&platform_list[0], CL_PLATFORM_PROFILE, "Platform Profile");
PrintPlatformMsg(&platform_list[0], CL_PLATFORM_VERSION, "Platform Version");
PrintPlatformMsg(&platform_list[0], CL_PLATFORM_NAME, "Platform Name");
PrintPlatformMsg(&platform_list[0], CL_PLATFORM_VENDOR, "Platform Vendor");
在高通865平台运行结果如下:
num_platform=1
err_num = 0
Platform Profile=FULL_PROFILE
Platform Version=OpenCL 2.0 QUALCOMM build: commit #d970ca5f2e changeid #Ifead41f47e Date: 07/14/21 Wed Local Branch: Remote Branch:
Platform Name=QUALCOMM Snapdragon(TM)
Platform Vendor=QUALCOMM2.2.2 获取设备Device
作用说明
获取平台下的 OpenCL 设备 Device,查询设备的硬件参数。使用 clGetDeviceIDs 和 clGetDeviceInfo两个API。
API函数说明
- clGetDeviceIDs
cl_int clGetDeviceIDs (cl_platform_id platform,
cl_device_type device_type,
cl_uint num_entries,
cl_device_id *devices,
cl_uint *num_devices)
功能描述:
获取平台可使用的 Device 对象数组。OpenCL 使用cl_device_id表示 Device 对象。
参数说明:
- platform[IN] :clGetPlatformIDs获取的 Platform ID。
- device_type[IN] :获取 OpenCL Device 的类型,参考表 2-2。
- num_entries[IN] :要获取的设备数量。
- devices[OUT] :返回获取的设备对象数组。
- num_devices[OUT]:返回平台连接 device_type 类型设备数目,可设为 NULL 忽略。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 4.2 节。
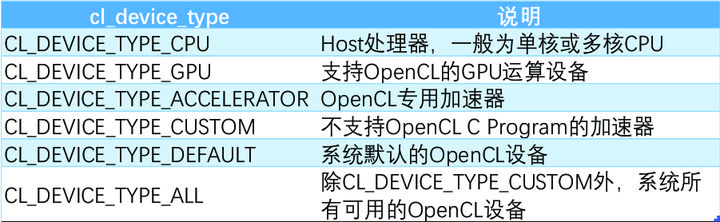
表2-2 OpenCL设备类型列表
- clGetDeviceInfo
cl_int clGetDeviceinfo(cl_device_id device,
cl_device_info param_name,
size_t param_value_size,
void *param_value,
size_t *param_value_size_ret)
功能描述:
获取设备相关信息,例如并行计算单元数,全局内存大小等等。
参数说明:
- device[IN] :clGetDeviceIDs获取的 Device ID。
- param_name[IN] :表示设备查询参数的枚举常量。
- param_value_size[IN] : param_value 指向内存空间的字节数。
- param_value[OUT] :指向返回查询参数结果的内存指针。
- param_value_size_ret[OUT]:返回查询参数的实际长度。
- Return :正常执行返回CL_SUCCESS,异常返回值请参考[1]中 4.2 节。
clGetDeviceInfo与clGetPlatformInfo的使用方式基本一致,由于设备属性较多,表 2-3 仅列出部分常用设备硬件属性。设备属性全表请参考[1]中表 4.3。
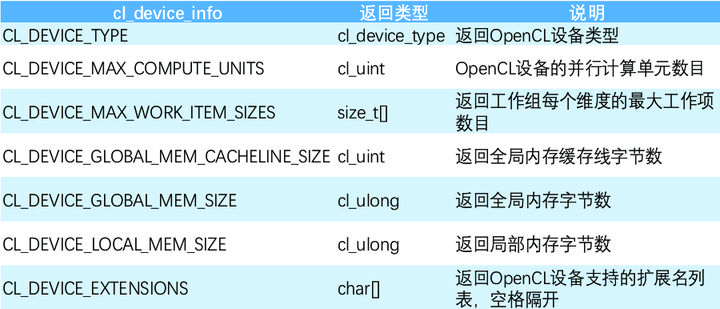
表 2-3 OpenCL 部分设备属性列表
实例代码
下面给出获取设备及设备参数的实例代码。
cl_uint num_device;
cl_device_id device;
// 1. 获取平台GPU类型OpenCL设备的数量
err_num = clGetDeviceIDs(platform_list[0], CL_DEVICE_TYPE_GPU, 0, NULL, &num_device);
printf("GPU num_device=%d\n", num_device);
// 2. 获取一个GPU类型的OpenCL设备
err_num = clGetDeviceIDs(platform_list[0], CL_DEVICE_TYPE_GPU, 1, &device, NULL);
// 对于cl_uint cl_ulong等返回类型参数只需要一步查询
cl_uint max_compute_units;
// 获取并打印OpenCL设备的并行计算单元数量
err_num = clGetDeviceInfo(device, CL_DEVICE_MAX_COMPUTE_UNITS, sizeof(cl_uint),
&max_compute_units, NULL);
printf("max_compute_units=%d\n", max_compute_units);
cl_ulong global_mem_size;
// 获取并打印OpenCL设备的全局内存大小
err_num = clGetDeviceInfo(device, CL_DEVICE_GLOBAL_MEM_SIZE, sizeof(cl_ulong),
&global_mem_size, NULL);
printf("global_mem_size=%ld\n", global_mem_size);
size_t *p_max_work_item_sizes=NULL;
size_t size;
// CL_DEVICE_MAX_WORK_ITEM_SIZES表示work_group每个维度的最大工作项数目
// 1. 返回类型是size_t[],首先查询返回信息的大小
err_num = clGetDeviceInfo(device, CL_DEVICE_MAX_WORK_ITEM_SIZES, 0, NULL, &size);
p_max_work_item_sizes = (size_t *)malloc(size);
// 2. 申请空间后查询结果并打印
err_num = clGetDeviceInfo(device, CL_DEVICE_MAX_WORK_ITEM_SIZES, size, p_max_work_item_sizes, NULL);
for (size_t i = 0; i < size / sizeof(size_t);i++)
{
printf("max_work_item_size_of_work_group_dim %zu=%zu\n", i, p_max_work_item_sizes[i]);
}
在高通865平台运行结果如下
GPU num_device=1
max_compute_units=3
global_mem_size=3988809728
max_work_item_size_of_work_group_dim 0=1024
max_work_item_size_of_work_group_dim 1=1024
max_work_item_size_of_work_group_dim 2=10242.2.3 创建上下文Context
作用说明
选择获取的设备,创建上下文 Context。使用的API是 clCreateContext。OpenCL 使用 Context 管理命令队列、程序内核、内存等资源对象。
API函数说明
- clCreateContext
cl_context clCreateContext(const cl_context_properties *properties,
cl_uint num_devices,
const cl_device_id *devices,
void ( CL_CALLBACK *pfn_notify)(const char *errinfo, const void *private_info, size_t cb, void *user_data),
void *user_data,
cl_int *errcode_ret)
功能描述:
基于获取的平台和设备,创建一个 OpenCL 上下文,类型是cl_context。
参数说明:
- properties[IN] :上下文属性数组,每一项属性包含一个枚举常量,一个属性值,数组以 0 结尾。 properties 指定了创建 Context 基于的 Platform,也可以设为 NULL,程序实现时自行选择 Platform。
- num_devices[IN] : devices 中指定的设备数。
- devices[IN] :clGetDeviceIDs返回的设备对象数组。
- pfn_notify[IN] :注册回调函数,当 OpenCL 创建上下文失败时会执行回调函数。没有回调可设为 NULL
- user_data[INOUT]:传递给回调函数 pfn_notify 的指针参数,可设为 NULL。
- errcode_ret[OUT] :返回错误码,如果 errcode_ret 设为 NULL 不再返回错误码。
- Return :OpenCL 上下文成功创建时,返回创建的 cl_contex t对象, errcode_ret 返回CL_SUCCESS。创建失败时返回 NULL, errorcode_ret 返回错误码。
实例代码
下面的代码使用高通 865 平台的 GPU 设备创建 Context。
cl_context_properties context_prop[16] = {0};
context_prop[0] = CL_CONTEXT_PLATFORM;
context_prop[1] = (cl_context_properties)platform_list[0];
context = clCreateContext(context_prop, 1, &device, NULL, NULL, &err_num);
if (err_num != CL_SUCCESS)
{
printf("Create Context failed with code=%d!\n", err_num);
}
else
{
printf("Context successfully created!\n");
}
在高通 865 平台运行结果如下:
Context successfully created!2.2.4 创建命令队列 CommandQueue
作用说明
为单个设备创建命令队列,使用的 API 是 clCreateCommandQueueWithProperties。操作命令入队后依据队列属性顺序或者乱序执行。
API函数说明
- clCreateCommandQueueWithProperties
cl_command_queue
clCreateCommandQueueWithProperties(cl_context context,
cl_device_id device,
const cl_queue_properties *properties,
cl_int *errcode_ret)
功能描述:
基于 Context 和唯一的 Device,按照 properties 属性创建命令队列cl_command_queue。
参数说明:
- context[IN] :有效的上下文对象cl_context。
- device[IN] :与 context 关联的设备。
- properties[IN] :命令队列属性数组,每一项属性包含一个枚举常量,一个属性值,数组以 0 结尾。参考表 2-4。
- errcode_ret[OUT]:返回错误码,如果 errcode_ret 设为 NULL 不再返回错误码。
- Return :OpenCL 命令队列成功创建时,返回创建的cl_command_queue对象, errcode_ret 返回CL_SUCCESS。创建失败时返回NULL, errorcode_ret 返回错误码。

表 2-4 命令队列属性表
实例代码
下面的代码创建一个 Host 端入队的命令队列,设置 CL_QUEUE_PROFILING_ENABLE 属性用于性能分析。
// OpenCL设备命令执行分为入队、提交、启动、结束和完成5个时间点,创建命令队列时使能CL_QUEUE_PROFILING_ENABLE才能获取设备记录的相应时间。
cl_command_queue_properties queue_prop[] = {CL_QUEUE_PROPERTIES, CL_QUEUE_PROFILING_ENABLE, 0};
cl_command_queue command_queue = NULL;
command_queue = clCreateCommandQueueWithProperties(context, device, queue_prop, &err_num);
if (err_num != CL_SUCCESS)
{
printf("Create CommandQueue failed with code=%d!\n", err_num);
}
else
{
printf("Host in-order profiling CommandQueue successfully created!\n");
}
在高通 865 平台运行结果如下
Host in-order profiling CommandQueue successfully created!2.2.5 创建并编译内核程序 Program
作用说明
这一步通过 OpenCL C 源码字符串或程序二进制两种方式之一创建内核程序 Program。编译 Program 生成二进制,检查编译错误并获取二进制代码。使用二进制代码创建 Program 能显著减少编译时间。
API函数说明
- clCreateProgramWithSource
cl_program clCreateProgramWithSource(cl_context context,
cl_uint count,
const char **strings,
const size_t *lengths,
cl_int *errcode_ret)
功能描述:
使用 OpenCL C 源代码创建cl_program,程序对象关联 context 中的所有设备。
参数说明:
- context[IN] :有效的Context对象。
- count[IN] :表示 strings 中字符串的个数。
- strings[IN] :字符串数组指针,所有的字符串构成设备源代码。
- lengths[IN] :表示 strings 每个字符串的长度。 lengths 可以设为 NULL,字符串以 0 结尾自动计算长度。
- errcode_ret[OUT]:返回错误码。 errcode_ret 设为 NULL 则不再返回错误码。
- Return :Program 对象成功创建时,返回创建的cl_program对象, errcode_ret 返回CL_SUCCESS。创建失败时返回 NULL, errorcode_ret 返回错误码。
- clCreateProgramWithBinary
cl_program clCreateProgramWithBinary(cl_context context,
cl_uint num_devices,
const cl_device_id *device_list,
const size_t *lengths,
const unsigned char **binaries,
cl_int *binary_status,
cl_int *errcode_ret)
功能描述:
向设备载入构建好的可执行程序二进制并创建cl_program。
参数说明:
- context[IN] : 有效的 Context 对象。
- num_devices[IN] : device_list 中设备个数。
- device_list[IN] : context 关联的设备数组。程序二进制需要载入 device_list 所列出的设备中,因此不能为NULL。
- lengths[IN] : binaries 数组中每个二进制文件的长度。
- binaries[IN] :二进制文件数组。对于设备 device_list[i],其程序二进制文件是 binaries[i],文件的长度是 lengths[i],三者一一对应。
- binary_status[OUT]:返回每个设备对应的二进制是否成功加载。成功加载返回CL_SUCCESS。 binary_status可设为NULL以忽略。
- errcode_ret[OUT] :返回错误码。 errcode_ret 设为NULL则不再返回错误码。
- Return :Program 对象成功创建时,返回创建的cl_program对象, errcode_ret 返回CL_SUCCESS。创建失败时返回NULL, errorcode_ret 返回错误码。
- clBuildProgram
cl_int clBuildProgram(cl_program program,
cl_uint num_devices,
const cl_device_id *device_list,
const char *options,
void (CL_CALLBACK *pfn_notify)( cl_program program, void *user_data),
void *user_data)
功能描述:
使用 Program 源代码或者二进制生成设备可执行程序。
参数说明:
- program[IN] :创建的程序对象。
- num_devices[IN] : device_list 中的设备数目。
- device_list[IN] : program 关联的设备对象数组。 device_list 设为 NULL 时,为 program 关联的所有设备编译可执行程序。 device_list 非空则仅为 device_list 中给出的设备编译可执行程序。
- options[IN] :表示编译选项的字符串,例如按 OpenCL2.0 标准编译,-cl-std=CL2.0。请参考[1]中5.8.4节 CompilerOptions。
- pfn_notify[IN] :注册回调函数。如果 pfn_notify 非空,clBuildProgram在编译开始后立即返回,生成结束时异步调用回调函数。如果 pfn_notify 为空,clBuildProgram必须等待生成结束才能返回。
- user_data[INOUT]:传递给回调函数的参数,可以设置为 NULL。
- Return :成功生成可执行程序返回CL_SUCCESS,错误码参考[1]中 5.8.2 节。
clBuildProgram包含编译和链接过程,OpenCL2.0 也可以单独调用clCompileProgram编译,调用clLinkProgram链接。
- clGetProgramBuildInfo
cl_int clGetProgramBuildInfo(cl_program program,
cl_device_id device,
cl_program_build_info param_name,
size_t param_value_size,
void *param_value,
size_t *param_value_size_ret)
功能描述:
查询 Program 对象关联设备的编译信息,尤其是 编译错误信息。
参数说明:
- program[IN] :查询的程序对象。
- device[IN] :指定查询编译信息的设备,设备必须与 program 关联。
- param_name[IN] :表示编译信息查询参数的枚举常量,参考表 2-5。
- param_value_size[IN] : param_value 指向内存空间的字节数。
- param_value[OUT] :指向返回查询参数结果的内存指针。
- param_value_size_ret[OUT]:返回查询参数的实际长度。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中 5.8.7 节。

表 2-5 Program 编译信息查询表
- clGetProgramInfo
cl_int clGetProgramInfo(cl_program program,
cl_program_info param_name,
size_t param_value_size,
void *param_value,
size_t *param_value_size_ret)
功能描述:
查询程序信息,例如获取clCreateProgramWithBinary所需的可执行二进制。
参数说明:
- program[IN] :查询的程序对象。
- param_name[IN] :表示编译信息查询参数的枚举常量,参考表 2-6。
- param_value_size[IN] : param_value 指向内存空间的字节数。
- param_value[OUT] :指向返回查询参数结果的内存指针。
- param_value_size_ret[OUT]:返回查询参数的实际长度。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中 5.8.7 节。

表 2-6 程序属性查询表
实例代码
下面代码使用 OpenCL C 代码创建 Program,编译生成后将可执行二进制保存到 bin 文件。
// 1. 读取OpenCL C源代码
char *source = ClUtilReadFileToString(prog_name);
cl_int err = 0;
// 2. 使用源代码创建program
program = clCreateProgramWithSource(context, 1, (const char **)&source, NULL, &err);
// 3. 使用OpenCL2.0标准编译Program
err |= clBuildProgram(program, 0, NULL, "-cl-std=CL2.0", NULL, NULL);
if (err != CL_SUCCESS)
{
// 如果编译失败,获取并打印错误信息
fprintf(stderr, "Error %d with clBuildProgram.", err);
static const size_t LOG_SIZE = 2048;
char log[LOG_SIZE];
log[0] = 0;
err = clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, LOG_SIZE, log, NULL);
if (CL_INVALID_VALUE == err)
{
fprintf(stderr, "There was a build error, but there is insufficient space allocated to "
"show the build logs.\n");
}
else
{
fprintf(stderr, "Build error:\n%s\n", log);
}
exit(-1);
}
else
{
// 4. 打印编译成功信息
printf("Program built Ok!\n");
}
cl_uint num_devices;
// 5. 获取程序关联设备数
err |= clGetProgramInfo(program, CL_PROGRAM_NUM_DEVICES, sizeof(cl_uint), &num_devices, NULL);
// 6. 获取程序关联设备ID
cl_device_id *p_devices = (cl_device_id *)malloc(sizeof(cl_device_id) * num_devices);
err |= clGetProgramInfo(program, CL_PROGRAM_DEVICES, sizeof(cl_device_id) * num_devices,
p_devices, NULL);
// 7. 获取设备程序二进制代码长度
size_t *p_program_binary_sizes = (size_t *)malloc(sizeof(size_t) * num_devices);
// 8. 获取设备程序二进制代码
err |= clGetProgramInfo(program, CL_PROGRAM_BINARY_SIZES, sizeof(size_t) * num_devices,
p_program_binary_sizes, NULL);
cl_uchar **p_program_binaries = (cl_uchar **)malloc(sizeof(cl_uchar *) * num_devices);
for (cl_uint i = 0; i < num_devices; i++)
{
p_program_binaries[i] = (cl_uchar *)malloc(p_program_binary_sizes[i]);
printf("Binary size for device %d=%zu\n", i, p_program_binary_sizes[i]);
}
err |= clGetProgramInfo(program, CL_PROGRAM_BINARIES, sizeof(cl_uchar *) * num_devices,
p_program_binaries, NULL);
if (err != CL_SUCCESS)
{
printf("Error Occur!\n");
}
// 9. 保存可执行二进制代码到文件
for (cl_uint i = 0; i < num_devices; i++)
{
char fname[25];
sprintf(fname, "Device%dProg.bin", i);
ClUtilWriteStringToFile(p_program_binaries[i], p_program_binary_sizes[i], fname);
printf("Wrote file %s\n", fname);
}
在高通865平台运行结果如下
Program built Ok!
Binary size for device 0=3516
Wrote file Device0Prog.bin2.2.6 创建内核对象Kernel
作用说明
第 6 步使用生成好的 Program 对象创建内核对象 kernel,类型为 cl_kernel。查询 kernel 的工作组属性以设置第 9 步执行参数。
API函数说明
- clCreateKernel
cl_kernel clCreateKernel(cl_program program,
const char *kernel_name,
cl_int *errcode_ret)
功能描述:
根据内核函数名,从 program 对象创建 kernel 对象。
参数说明:
- program[IN] :已经生成可执行二进制的内核程序对象。
- kernel_name[IN] : program 中以__kernel修饰的函数名。
- errcode_ret[OUT]:返回错误码,如果 errcode_ret 设为 NULL 不再返回错误码。
- Return :Kernel对象成功创建时,返回创建的cl_kernel对象, errcode_ret 返回CL_SUCCESS。创建失败时返回 NULL, errorcode_ret 返回错误码。
- clGetKernelWorkGroupInfo
cl_int clGetKernelWorkGroupInfo(cl_kernel kernel,
cl_device_id device,
cl_kernel_work_group_info param_name,
size_t param_value_size,
void *param_value,
size_t *param_value_size_ret)
功能描述:
返回指定设备 kernel 对象的工作组信息,例如最大工作组尺寸。
参数说明:
- kernel[IN] :查询的内核对象。
- device[IN] :与 kernel 关联的指定 Device ID。 kernel 只与单个设备关联时,可以设为 NULL。
- param_name[IN] :表示工作组信息查询参数的枚举常量,参考表 2-7。
- param_value_size[IN] : param_value 指向内存空间的字节数。
- param_value[OUT] :指向返回查询参数结果的内存指针。
- param_value_size_ret[OUT]:返回查询参数的实际长度。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中 5.9.3 节。

表 2-7 Kernel 工作组属性查询表
实例代码
cl_kernel kernel;
// 1. 创建Kernel
kernel = clCreateKernel(program, kernel_name, &err_num);
if (err_num != CL_SUCCESS)
{
printf("create kernel failed.\n ");
return NULL;
}
size_t max_work_group_size;
size_t perferred_work_group_size_multiple;
err_num = clGetKernelWorkGroupInfo(kernel, device, CL_KERNEL_WORK_GROUP_SIZE, sizeof(size_t),
&max_work_group_size, NULL);
err_num |=
clGetKernelWorkGroupInfo(kernel, device, CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE,
sizeof(size_t), &perferred_work_group_size_multiple, NULL);
if (err_num != CL_SUCCESS)
{
printf("Get kernel info failed.\n ");
return NULL;
}
printf("Kernel %s max workgroup size=%zu\n", kernel_name, max_work_group_size);
printf("Kernel %s perferred workgroup size multiple=%zu\n", kernel_name,
perferred_work_group_size_multiple);
基于第三节转置 kernel,在高通 865 平台运行结果如下:
Kernel TransposeKernel max workgroup size=1024
Kernel TransposeKernel perferred workgroup size multiple=1282.2.7 创建内存对象
作用说明
创建内存对象并读入数据。OpenCL Buffer 对象用于存储一维的标量、向量或自定义结构体数据。Image 对象则专门用于保存一到三维的图像数据。OpenCL 通过这两种内存对象实现 Host 和 Device 之间大量数据交换。
2.2.7.1 OpenCL Buffer API 说明
本节介绍 Buffer 对象的创建和读写,给出实例代码。
- clCreateBuffer
cl_mem clCreateBuffer(cl_context context,
cl_mem_flags flags,
size_t size,
void *host_ptr,
cl_int *errcode_ret)
功能描述:
创建 Buffer 对象。
参数说明:
- context[IN] :为 context 对象分配 buffer 对象。
- flags[IN] :以组合 bit 位枚举常量的方式,指定 buffer 的分配和使用信息,参考表 2-8。
- size[IN] :申请内存空间字节数。
- host_ptr[IN] :应用程序在 Host 端已经申请的内存空间指针。
- errcode_ret[OUT]:返回错误码。 errcode_ret 设为 NULL 则不再返回错误码。
- Return :buffer 对象成功创建时,返回创建的cl_mem对象, errcode_ret 返回CL_SUCCESS。创建失败时返回 NULL, errorcode_ret 返回错误码。

表 2-8 OpenCL Mem 对象读写 flag 列表
- clEnqueueRead/WriteBuffer
cl_int clEnqueueReadBuffer (cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_read,
size_t offset,
size_t size,
void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
cl_int clEnqueueWriteBuffer(cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_write,
size_t offset,
size_t size,
const void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
功能描述:
clEnqueueReadBuffer从 buffer 对象读取数据到 Host 端内存,clEnqueueWriteBuffer将 Host 内存数据写入 buffer 对象。
参数说明:
- command_queue[IN] :读写指令入队的命令队列对象。命令队列和 buffer 应在同一 context 下创建。
- buffer[IN] :有效的 buffer 对象。
- blocking_write和 blocking_read[IN]:如果设置为CL_TRUE,表示阻塞式操作,数据传输结束才能返回。CL_FALSE表示非阻塞操作,命令入队立即返回。
- offset[IN] :读写 buffer object 的字节偏移量。
- size[IN] :读写数据的字节数。
- ptr[IN/OUT] :host 端内存缓冲区地址。
- num_events_in_wait_list[IN] : event_wait_list 内事件的数目。
- event_wait_list[IN] :cl_event数组。执行内核操作前,需要等待 event_wait_list 内事件执行完成。如果不需要等待, event_wait_list 设为 NULL, num_events_in_wait_list 设为 0。
- event[OUT] :如果非 NULL,则此参数用于查询命令执行状态,或等待命令完成。clEnqueue指令普遍包含 num_events_in_wait_list, event_wait_list, event 这三个参数。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中 5.2.2 节。
Buffer 操作实例代码
int num_of_elements = 512;
int err = 0;
cl_uchar *h_A = (cl_uchar *)malloc(num_of_elements);
cl_uchar *h_B = (cl_uchar *)malloc(num_of_elements);
for (int i = 0; i < num_of_elements; i++)
{
h_A[i] = i % 0xFF;
}
cl_mem buffer_A =
clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(cl_uchar) * num_of_elements, NULL, &err);
cl_mem buffer_B =
clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(cl_uchar) * num_of_elements, NULL, &err);
// write from host ptr to buffer
err = clEnqueueWriteBuffer(cmd_queue, buffer_A, CL_TRUE, 0, sizeof(cl_uchar) * num_of_elements, h_A,
0, NULL, NULL);
/* Run a device kernel copy data from buffer_A to buffer_B */
// Read from buffer to host ptr
err = clEnqueueReadBuffer(cmd_queue, buffer_B, CL_TRUE, 0, sizeof(cl_uchar) * num_of_elements, h_B, 0,
NULL, NULL);
clReleaseMemObject(buffer_A);
clReleaseMemObject(buffer_B);
// Return true if two arrays match
bool match = CompareArray(h_A, h_B, num_of_elements);
if (match)
printf("A and B match!\n");
else
printf("A and B mismatch!\n");
free(h_A);
free(h_B);
高通865平台运行结果如下
A and B match!2.2.7.2 OpenCL Image API 说明
Image 对象封装了图像大小、图像格式、坐标模式、插值模式等多种信息。Image 对象在 Device 端可使用采样器 Sampler 方便地读取图像。本节介绍 Image 对象和采样器对象的创建,Image 对象的读写并给出实例代码。
- clCreateImage
cl_mem clCreateImage(cl_context context,
cl_mem_flags flags,
const cl_image_format *image_format,
const cl_image_desc *image_desc,
void *host_ptr,
cl_int *errcode_ret)
功能描述:
创建指定格式、类型、尺寸的图像。
参数说明:
- context[IN] :为 context 对象分配 Image 对象。
- flags[IN] :指定缓冲区的分配和使用信息,枚举类型与clCreateBuffer一致。
- image_format[IN]:图像格式,包括图像通道顺序和数据类型。
- image_desc[IN] :图像描述,包括图像类型、图像宽高和 pitch 等参数。
- host_ptr[IN] :host端内存地址,可用于初始化图像数据或设为 NULL。
- errcode_ret[OUT] :返回错误码。 errcode_ret 设为 NULL 则不再返回错误码。
- Return :buffer 对象成功创建时,返回创建的cl_mem对象, errcode_ret 返回CL_SUCCESS。创建失败时返回 NULL, errorcode_ret 返回错误码。
cl_image_format结构体包含image_channel_order和image_channel_data_type两个成员,详情查询[1]中表 5.6 和 5.7。举例来说,image_channel_order=CL_RGBA,image_channel_data_type=CL_UNSIGNED_INT8表示图像每个像素包括 RGBA 四个通道,每个通道的数据都是 8 位无符号整数。内存布局如下。

cl_image_desc结构体包含图像类型,图像尺寸和一个cl_mem对象,参考[1]中 5.3.1.2 节。
以 2D 图像为例,关键的尺寸参数image_height,image_width和image_row_pitch。其中image_height和image_width以像素为单位。为了内存对齐,往往在图像每一行结尾填充位数,image_row_pitch表示图像每一行的字节数。

// 图像format 根据具体的数据确定
cl_image_format image_format;
image_format.image_channel_order = CL_RGBA;
image_format.image_channel_data_type = CL_UNSIGNED_INT8;
cl_image_desc image_desc;
cl_uint pitch_align;
// 查询设备的2Dimage对齐字节
err_num = clGetDeviceInfo(device, CL_DEVICE_IMAGE_PITCH_ALIGNMENT, sizeof(cl_uint),
&pitch_align, NULL);
printf("image2D pitch align=%d\n", pitch_align);
memset(&image_desc, 0, sizeof(cl_image_desc));
image_desc.image_type = CL_MEM_OBJECT_IMAGE2D;
image_desc.image_height = height;
image_desc.image_width = width;
// 图像每一行的字节数,宽度*通道*元素大小,做内存对齐
image_desc.image_row_pitch = (width*channels*sizeof(cl_uchar) + pitch_align - 1) / pitch_align * pitch_align;
高通865平台的查询结果是
image2D pitch align=64- clEnqueueRead/WriteImage
cl_int clEnqueueReadImage(cl_command_queue command_queue,
cl_mem image,
cl_bool blocking_read,
const size_t *origin,
const size_t *region,
size_t row_pitch,
size_t slice_pitch,
void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
cl_int clEnqueueWriteImage(cl_command_queue command_queue,
cl_mem image,
cl_bool blocking_write,
const size_t *origin,
const size_t *region,
size_t input_row_pitch,
size_t input_slice_pitch,
const void * ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
功能描述:
clEnqueueReadImage从 image 对象读取数据到 host 内存,clEnqueueWriteImage将 host 内存数据写入 image 对象。
参数说明:
- command_queue[IN] :读写指令入队的命令队列对象。命令队列和 image 应在同一 context 下创建
- image[IN] :有效的 image 或 image array 对象。
- blocking_read/ blocking_write[IN]:如果设置为CL_TRUE,表示阻塞式操作,数据传输结束才能返回。CL_FALSE表示非阻塞操作,命令入队立即返回。
- origin[IN] :定义 image 对象的三维原点坐标 (x,y,z),用于控制像素数据读写偏移。
- region[IN] :定义 image 对象的 (width,height,depth) 坐标范围。因此图像数据读写的坐标范围是 (x,y,z) 到 (x+width,y+height,z+depth)。
- row_pitch[IN] :表示 2D 以上图像每行的字节数。
- slice_pitch[IN] :表示 3D 图像每层的字节数。
- ptr[IN/OUT] :host 端内存缓冲区地址。
- num_events_in_wait_list[IN] : event_wait_list 内事件的数目。
- event_wait_list[IN] :cl_event数组。执行内核操作前,需要等待 event_wait_list 内事件执行完成。如果不需要等待, event_wait_list 设为NULL, num_events_in_wait_list 设为 0。
- event[OUT] :如果非 NULL,则此参数用于查询命令执行状态,或等待命令完成。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中 5.3.3 节。
- clCreateSampler
cl_sampler clCreateSamplerWithProperties (cl_context context,
const cl_sampler_properties *sampler_properties,
cl_int *errcode_ret)
功能描述:
创建 Sampler 对象。GPU 设备通过 Sampler 读取图像时,使用更高效的纹理处理器和纹理缓存提高读取效率;使用硬件内建的边界及插值处理,降低编程复杂度。
参数说明:
- context[IN] :为 context 对象分配 Sampler 对象。
- sampler_properties[IN]:采样器属性,包括坐标归一化,采样边界处理模式和采样插值滤波模式。
- errcode_ret[OUT] :返回错误码。 errcode_ret 设为 NULL 则不再返回错误码。
- Return :sampler 对象成功创建时,返回创建的cl_sampler对象, errcode_ret 返回`CL_SUCCESS`。创建失败时返回 NULL, errorcode_ret 返回错误码。
Image操作实例代码
下面例子通过 OpenCV 读取图像,展示了 Image 对象的运行时 API 操作。
cl_mem memobject[2] = {0, 0};
cv::Mat src = cv::imread("./lena512x512.jpg", 1);
cv::cvtColor(src, src, cv::COLOR_BGR2BGRA);
// create opencl memobject
cl_image_format image_format;
image_format.image_channel_order = CL_RGBA;
image_format.image_channel_data_type = CL_UNORM_INT8;
cl_image_desc image_desc;
memset(&image_desc, 0, sizeof(cl_image_desc));
image_desc.image_type = CL_MEM_OBJECT_IMAGE2D;
image_desc.image_width = src.cols;
image_desc.image_height = src.rows;
// Create Image with CL_MEM_COPY_HOST_PTR
memobject[0] = clCreateImage(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, &image_format, &image_desc, src.data, &err_num);
memobject[1] = clCreateImage(context, CL_MEM_WRITE_ONLY, &image_format, &image_desc, NULL, &err_num);
/**************Set Arg and Run Kenel*********************/
// copy result from device to host
cv::Mat gpu_dst(src.size(), src.type());
size_t origin[3] = {0, 0, 0};
size_t region[3] = {(size_t)src.cols, (size_t)src.rows, 1};
err_num = clEnqueueReadImage(command_queue, memobject[1], CL_TRUE, origin, region,
0, 0, gpu_dst.data, 0, NULL, NULL);
2.2.8 设置 kernel 参数
作用说明
准备好 kernel 对象和输入输出 mem 对象后,这一步设置 kernel 函数参数。
API函数说明
- SetKernelArg
cl_int clSetKernelArg(cl_kernel kernel,
cl_uint arg_index,
size_t arg_size,
const void *arg_value)
功能描述:
设置kernel函数的单个参数。
参数说明:
- kernel[IN] :有效的内核对象。
- arg_index[IN]:内核函数参数索引,对于 n 个参数的内核函数, arg_index 从 0 编号到 n-1。
- arg_size[IN] :第 arg_index 个参数占内存大小。
- arg_value[IN]:指向传入参数数据的指针。
- Return :成功生成可执行程序返回CL_SUCCESS,错误码参考[1]中 5.9.2 节。
实例代码
例如对于下面的 kernel 函数
// 依次设置参数
err |= clSetKernelArg(kernel, 0, sizeof(cl_mem), &image_src);
err |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &image_dst);
err |= clSetKernelArg(kernel, 2, sizeof(cl_sampler), &sampler);
err |= clSetKernelArg(kernel, 3, sizeof(int), &image_width);
err |= clSetKernelArg(kernel, 4, sizeof(int), &image_height);
/* // 对应的 kernel 代码
__kernel
void kernel_func(__read_only image2d_t src_img, // arg_idx=0
__write_only image2d_t dst_img, // arg_idx=1
sampler_t sampler, // arg_idx=2
int width, // arg_idx=3
int height) // arg_idx=4
*/
2.2.9 执行内核
作用说明
设置 kernel 的任务网格尺寸,并执行内核。
API 函数说明
- clEnqueueNDRangeKernel
cl_int clEnqueueNDRangeKernel(cl_command_queue command_queue,
cl_kernel kernel,
cl_uint work_dim,
const size_t *global_work_offset,
const size_t *global_work_size,
const size_t *local_work_size,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
功能描述:
提交内核执行命令,提交后 API 立即返回 Host。设备会按照设定的 work-item 网格尺寸启动内核函数执行。
参数说明:
- command_queue[IN] :提交内核执行命令的命令队列。
- kernel[IN] :在设备上执行的内核函数。
- work_dim[IN] :work-item 的组织维度,0 < work_dim <= 3,全局 work-item 和工作组内work-item维度相同。
- global_work_offset[IN] :数组,表示 0~ work_dim-1 维全局工作项 ID 的偏移量。可设为 NULL,每个维度偏移量为 0。
- global_work_size[IN] :全局工作项尺寸数组,全局工作项总数为global_work_size[0]*...* global_work_size[work_dim-1]。
- local_work_size[IN] :工作组尺寸数组,工作组内工作项个数为local_work_size[0]*...* local_work_size[work_dim-1]。
- num_events_in_wait_list[IN]: event_wait_list 内事件的数目。
- event_wait_list[IN] :cl_event数组。执行内核操作前,需要等待 event_wait_list 内事件执行完成。如果不需要等待, event_wait_list 设为 NULL, num_events_in_wait_list 设为 0。
- event[OUT] :如果非 NULL,则此参数用于查询命令执行状态,或等待命令完成。
实例代码
下面的代码按照图像数据的 width 和 height 划分全局工作项,以 16x16 个工作项为单位构建工作组。
size_t global_worksize[2] = {width, height};
// work_group尺寸不能超过clGetKernelWorkGroupInfo查询的CL_KENREL_WORK_GROUP_SIZE
size_t local_worksize[2] = {16, 16};
err_num = clEnqueueNDRangeKernel(command_queue, buffer_kernel, 2, NULL,
global_worksize, local_worksize, 0, NULL, NULL);
2.2.10 主机和设备同步
作用说明
OpenCL Host 和 Device 之间为异步操作,Host 读取 Device 数据前应确保 Device 端相关命令执行完成。可使用 clFinish 或 clWaitForEvents 进行同步。此外 clEnqueueRead/WriteBuffer 等也能起到阻塞同步的作用。
API函数说明
- clFinsh
cl_int clFinish (cl_command_queue command_queue)
功能描述:
阻塞 Host 直到 command_queue 中入队命令全部执行完成,应谨慎使用。
参数说明:
- command_queue[IN]:要阻塞等待的命令队列。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中5.15节。
- clWaitForEvents
cl_int clWaitForEvents (cl_uint num_events, const cl_event *event_list)
功能描述:
等待事件列表关联的设备命令执行完成。
参数说明:
- num_events[IN]: event_list 中事件数量。
- event_list[IN] :所有要等待执行完成的事件。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中 5.11 节。
- clGetProfilingInfo
cl_int clGetEventProfilingInfo (cl_event event,
cl_profiling_info param_name,
size_t param_value_size,
void *param_value,
size_t *param_value_size_ret)
功能描述:
使用clEnqueue命令返回的 Event 对象抓取设备计时。命令队列属性需要使能CL_QUEUE_PROFILING_ENABLE。
参数说明:
- event[IN] :clEnqueue命令返回的 Event 对象。
- param_name[IN] :表示 Profiling 信息查询参数的枚举常量,参考表 2-9。
- param_value_size[IN] : param_value 指向内存空间的字节数。
- param_value[OUT] :指向返回查询参数结果的内存指针。
- param_value_size_ret[OUT]:返回查询参数的实际长度。
- Return :正常执行返回CL_SUCCESS,异常返回查询[1]中 5.14 节。

表 2-9 Profiling 时间点查询列表
表 2-9 列出了命令执行的入队(queue)、提交(submit)、启动(start)、结束(end)和完成(complete)五个时间点,按时间线分为4个时间段。其中最值得关注的是启动到结束的时间,表示kernel函数的运行时间。

下面给出 Host 端打印各阶段时长的代码
void PrintProfilingInfo(cl_event event)
{
cl_ulong t_queued;
cl_ulong t_submitted;
cl_ulong t_started;
cl_ulong t_ended;
cl_ulong t_completed;
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_QUEUED, sizeof(cl_ulong), &t_queued, NULL);
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_SUBMIT, sizeof(cl_ulong), &t_submitted, NULL);
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_START, sizeof(cl_ulong), &t_started, NULL);
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_END, sizeof(cl_ulong), &t_ended, NULL);
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_COMPLETE, sizeof(cl_ulong), &t_completed, NULL);
printf("queue -> submit : %fus\n", (t_submitted - t_queued) * 1e-3);
printf("submit -> start : %fus\n", (t_started - t_submitted) * 1e-3);
printf("start -> end : %fus\n", (t_ended - t_started) * 1e-3);
printf("end -> finish : %fus\n", (t_completed - t_ended) * 1e-3);
}
对第三节示例代码的 kernel 做 Profiling 分析,可以看到 start -> end 的 kernel 函数执行时间占主体。kernel 函数内没有设备端入队指令,end->finish 耗时为 0。
queue -> submit : 145.920000us
submit -> start : 88.064000us
start -> end : 10540.032000us
end -> finish : 0.000000us2.2.11 读取 Device 处理结果
作用说明
OpenCL Device kernel 以 buffer 或者 Image 的方式向 Host 返回数据,可使用 clEnqueueReadBuffer 或 clEnqueueReadImage 读取计算处理结果。
2.2.12 清理 OpenCL 资源
作用说明
OpenCL 程序执行的最后一步是手动清理在 Context 上申请的全部资源。我们建议停止使用的 OpenCL 资源尽早释放,按照与创建时相反的次序释放 OpenCL 系统资源。
OpenCL 资源普遍采用引用计数机制进行管理,当引用计数降为 0,且相关设备命令执行完成、附属资源释放后,资源对象删除。
API函数说明
- clReleaseMemObject
cl_int clReleaseMemObject(cl_mem memobj)
参数说明:
- memobj[IN]:减少 memobj 的引用计数。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 5.5.1 节。
- clReleaseEvent
cl_int clReleaseEvent (cl_event event)
参数说明:
- event[IN]:减少 event 的引用计数。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 5.11 节。
- clReleaseSampler
cl_int clReleaseSampler (cl_sampler sampler)
参数说明:
- sampler[IN]:减少 sampler 的引用计数。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 5.7.1 节。
- clReleaseKernel
cl_int clReleaseKernel (cl_kernel kernel)
参数说明:
- kernel[IN]:减少 kernel 的引用计数。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 5.9.1 节。
- clReleaseProgram
cl_int clReleaseProgram (cl_program program)
参数说明:
- program[IN]:减少 program 的引用计数。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 5.8.1 节。
- clReleaseCommandQueue
cl_int clReleaseCommandQueue (cl_command_queue command_queue)
参数说明:
- command_queue[IN]:减少 command_queue 的引用计数。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 5.1 节。
- clReleaseContext
cl_int clReleaseContext (cl_context context)
参数说明:
- context[IN]:减少 context 的引用计数。
- Return :正常执行返回CL_SUCCESS,异常返回值参考[1]中 4.4 节。
2.3 API 使用注意事项
OpenCL API 函数在 CPU 主机上执行,用于管理 OpenCL 资源和控制应用程序的执行。API 函数相较于设备内核代码,计算工作量更低,但不恰当地使用 API 函数可能带来很大的性能损失。开发人员可参考以下几点注意事项。
(1)内存资源的使用
- 尽可能重用 OpenCL 内存和上下文对象,避免高开销的资源创建工作。
- 避免在
clEnqueueNDRangeKernel之间创建或释放 OpenCL 内存对象。 - 由于主机和设备之间内存拷贝成本高昂,可以依据硬件厂商支持,采用不同的零拷贝机制。例如 Intel HD Graphics 使用 Map 取代 Copy,OpenCL2.0 支持的 SVM 内存,高通平台扩展的 ION 内存等等。
(2)二进制程序加载
- 运行时加载编译 OpenCL C 源代码极为耗时。首次使用
clCreateProgramWithSource创建 program 并编译生成后,可保存设备的可执行二进制到文件。之后使用clCreateProgramWithBinary加载 program。下面是同一段 OpenCL C 代码使用源码加载编译和二进制加载编译的时间对比,可以看到程序加载时间显著降低。 - 编译好的二进制代码只适用于指定设备,如果设备加载了不匹配的二进制代码,应退回使用源码编译。
# clCreateProgramWithSource and clBuildProgram
Source Compiling consumes average time: 41441 us
# clCreateProgramWithBinary and clBuildProgram
Binary Compiling consumes average time: 39 us(3)基于事件驱动(Event-driven)设备命令运行
- 调用阻塞式 API 会挂起主机端 CPU 进程/线程,OpenCL 程序应尽可能避免阻塞式 API 调用。

- OpenCL enqueue API 可以接收事件列表作为输入参数,列表中所有事件完成后,命令开始在设备端执行。使用事件列表建立命令之间的依赖关系,主机端只要将
clEnqueue命令入队,交由设备按事件依赖执行,无需在主机端做阻塞式的同步操作。

// CL_FALSE表示 Non-blocking API,命令入队后立即返回
clEnqueueWriteBuffer(command_queue, buffer_src, CL_FALSE, 0, buffer_size_in_bytes,
host_src_matrix, 0, NULL, &write_event);
// 命令依次入队,在Device端按照event依赖执行
clEnqueueNDRangeKernel(command_queue, native_kernel, 2, NULL, global_work_size, local_work_size, 1,
&write_event, &kernel_event);
clEnqueueReadBuffer(command_queue, buffer_dst, CL_FALSE, 0, buffer_size_in_bytes,
host_dst_matrix, 1, &kernel_event, &read_event);
/*CPU do something*/
// Sync between host and device
clWaitForEvents(1, &read_event);
三、OpenCL图像转置示例
3.1 代码展示
以 8 位灰度图像转置为例编写 CPU C 代码和 OpenCL 代码,压缩包下载链接参见附录。为简化图像格式操作,用cl_uchar 矩阵表示图像。CPU 代码采用行读列写的方式,
void CpuTranspose(cl_uchar *src, cl_uchar *dst, int src_width, int src_height)
{
for (int src_row = 0; src_row < src_height; src_row++)
{
for (int src_col = 0; src_col < src_width; src_col++)
{
//执行主体
dst[src_col * src_height + src_row] = src[src_row * src_width + src_col];
}
}
}
OpenCL C 源码的 kernel 函数只需要执行 CPU 循环的主体,每个工作项处理一个像素。
__kernel void TransposeKernel(__global uchar *src, __global uchar *dst, int width, int height)
{
uint g_idx = get_global_id(0);
uint g_idy = get_global_id(1);
if ((g_idx >= width) || (g_idy >= height))
return;
dst[g_idx * height + g_idy] = src[g_idy * width + g_idx];
}
在 Host 端,使用本文介绍的 API,按步骤完成 OpenCL 设置,调用 clEnqueueNDRangeKernel 在设备端执行。
cl_device_id device;
cl_context context;
cl_command_queue command_queue;
cl_program program;
cl_kernel kernel;
cl_mem buffer_src;
cl_mem buffer_dst;
cl_int err_num = CL_SUCCESS;
cl_uint buffer_size_in_bytes;
timeval start;
// Step 1-3 查询平台设备并创建context
context = CreateContext(&device);
if (NULL == context)
{
printf("MainError:Create Context Failed!\n");
return -1;
}
// Step 4 创建command queue
command_queue = CreateCommandQueue(context, device);
if (NULL == command_queue)
{
printf("MainError:Create CommandQueue Failed!\n");
return -1;
}
// 读取OpenCL C源代码
char *device_source_str = ClUtilReadFileToString("kerneltest.cl");
program = CreateProgram(context, device, device_source_str);
// Step 5 创建编译program
if (NULL == program)
{
printf("MainError:Create CommandQueue Failed!\n");
return -1;
}
// Step 6 创建编译kernel
kernel = CreateKernel(program, "TransposeKernel", device);
if (NULL == kernel)
{
printf("MainError:Create Kernel Failed!\n");
return -1;
}
const int c_loop_count = 30;
int width = 4096;
int height = 4096;
buffer_size_in_bytes = width * height * sizeof(cl_uchar);
cl_uchar *host_src_matrix = (cl_uchar *)malloc(buffer_size_in_bytes);
cl_uchar *host_transposed_matrix = (cl_uchar *)malloc(buffer_size_in_bytes);
cl_uchar *device_transposed_matrix = (cl_uchar *)malloc(buffer_size_in_bytes);
memset(device_transposed_matrix, 0, buffer_size_in_bytes);
DataInit(host_src_matrix, width, height);
printf("Matrix Width =%d Height=%d\n", width, height);
gettimeofday(&start, NULL);
for (int i = 0; i < c_loop_count; i++)
{
CpuTranspose(host_src_matrix, host_transposed_matrix, width, height);
}
// 计算CPU多次运行的平均时间
PrintDuration(&start, "Cpu Transpose", c_loop_count);
// Step 7 创建内存对象
buffer_src = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
buffer_size_in_bytes, host_src_matrix, &err_num)
CheckClStatus(err_num, "Create src buffer");
buffer_dst = clCreateBuffer(context, CL_MEM_WRITE_ONLY, buffer_size_in_bytes, NULL, &err_num);
CheckClStatus(err_num, "Create dst buffer");
// Step 8 设置kernelArg
err_num = clSetKernelArg(kernel, 0, sizeof(cl_mem), &buffer_src);
err_num |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &buffer_dst);
err_num |= clSetKernelArg(kernel, 2, sizeof(int), &width);
err_num |= clSetKernelArg(kernel, 3, sizeof(int), &height);
size_t global_work_size[3];
size_t local_work_size[3];
// 设置NDRange尺寸
local_work_size[0] = 32;
local_work_size[1] = 32;
local_work_size[2] = 0;
global_work_size[0] =
(width + local_work_size[0] - 1) / local_work_size[0] * local_work_size[0];
global_work_size[1] =
(height + local_work_size[1] - 1) / local_work_size[1] * local_work_size[1];
global_work_size[2] = 0;
printf("global_work_size=(%zu,%zu)\n", global_work_size[0], global_work_size[1]);
printf("local_work_size=(%zu,%zu)\n", local_work_size[0], local_work_size[1]);
cl_event kernel_event = NULL;
gettimeofday(&start, NULL);
for (int i = 0; i < c_loop_count; i++)
{
// Step 9 入队kernel执行
err_num = clEnqueueNDRangeKernel(command_queue, kernel, 2, NULL, global_work_size,
local_work_size, 0, NULL, &kernel_event);
CheckClStatus(err_num, "ClEnqueueNDRangeKernel");
// Step 10 同步
err_num = clWaitForEvents(1, &kernel_event);
CheckClStatus(err_num, "ClWaitForEvents");
}
// 计算GPU多次运行的平均时间
PrintDuration(&start, "OpenCL Transpose", c_loop_count);
// Step 11 读取OpenCL计算结果
err_num = clEnqueueReadBuffer(command_queue, buffer_dst, CL_TRUE, 0, buffer_size_in_bytes,
device_transposed_matrix, 0, NULL, NULL);
compare(host_transposed_matrix, device_transposed_matrix, width, height);
free(device_source_str);
free(host_src_matrix);
free(host_transposed_matrix);
free(device_transposed_matrix);
// Step 12 清理OpenCL资源
clReleaseEvent(kernel_event);
clReleaseMemObject(buffer_src);
clReleaseMemObject(buffer_dst);
CleanUp(context, command_queue, program, kernel);
3.2 运行结果
在高通 865 平台,对 4096x4096 图像做转置,运行结果如下,CPU 运行时间除以 OpenCL 运行时间作为加速比,约 10.1 倍。
Cpu Transpose consume average time: 135815 us
Kernel TransposeKernel max workgroup size=1024
Kernel TransposeKernel perferred workgroup size multiple=128
global_work_size=(4096,4096)
local_work_size=(32,32)
OpenCL Transpose consume average time: 13412 us
A and B match!使用不同尺寸图像计算 OpenCL 转置加速比。随着数据量上升,OpenCL 相较于 CPU 加速优势显著。

3.3 说明
本节 OpenCL 转置示例仅为展示 OpenCL 运行时 API 的使用,程序可以深度优化并得到数倍的性能提升。优化措施包括且不限于:

四、总结
本文首先给出 OpenCL 运行时 API 的整体编程流程图,然后针对每一步介绍使用的运行时 API,讲解 API 参数,并给出编程运行实例。总结运行时 API 使用的注意事项。最后展示基于 OpenCL 的图像转置代码。在 865 平台下,对于 4096x4096 的 8 位图像加速比达到 10 倍以上。
五、工程代码
guide/OpenCLTranspose at main · mobile-algorithm-optimization/guidegithub.com/mobile-algorithm-optimization/guide/tree/main/OpenCLTranspose编辑
参考资料
[1] https://www.khronos.org/registry/OpenCL/specs/opencl-2.0.pdf
[2] Qualcomm snapdragon mobile platform opencl general programming and optimization
[3] OpenCL 异构并行计算
[4] Heterogeneous Computing with OpenCL 2.0
[5] https://www.khronos.org/registry/OpenCL/sdk/2.1/docs/man/xhtml/
[6] OpenCL in Action
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!