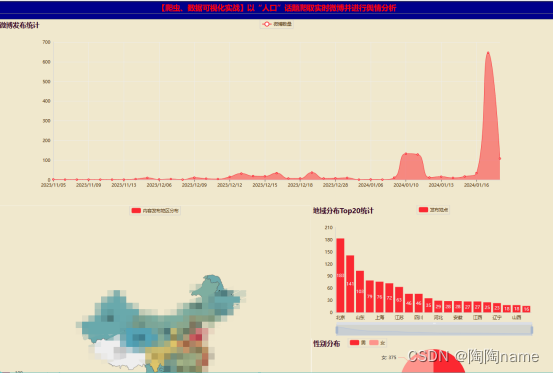
前言:
本人之前分享过一篇文章:使用pycharm连接远程GPU训练神经网络模型(超详细!),其中详细介绍了如何利用pycharm连接AutoDL算力云平台租用的GPU服务器训练网络模型。但有些小伙伴可能会因为一些原因而导致模型训练意外中止,这里博主说明一下如何在AutoDL终端进行模型训练,从而避免此类问题。
1、租用GPU服务器
2、资源的上传与下载
前两步在上一篇文章都详细介绍过,不清楚的小伙伴可查看一下。
3、终端训练神经网络模型
租用GPU并完成相关资源的上传后,大家进入控制台的容器实例界面,在快捷工具中点击进入JupyterLab,如下图所示。
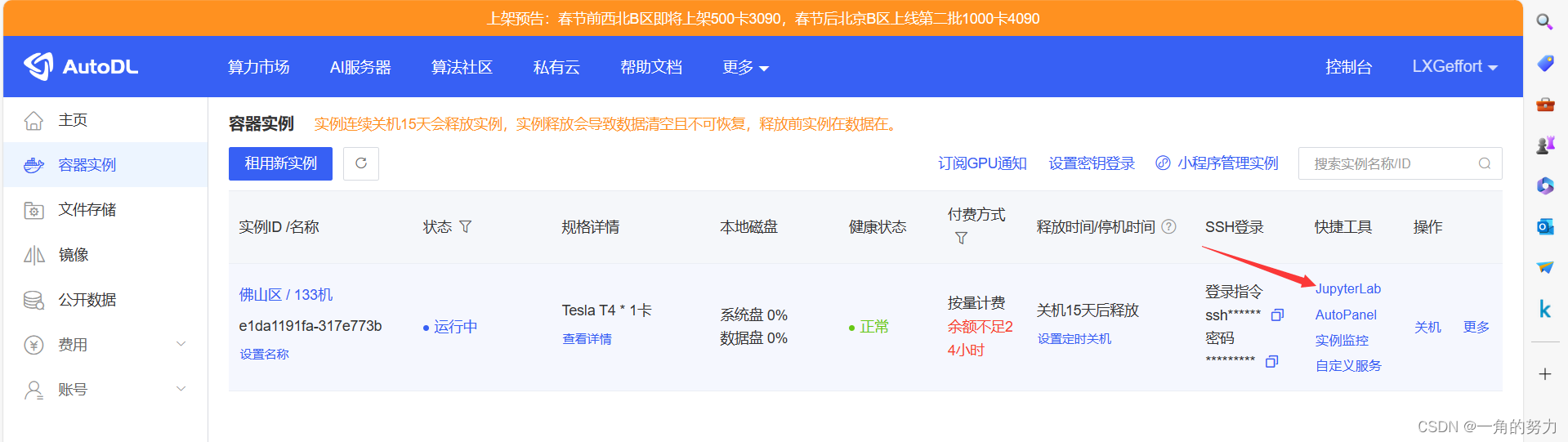
点击进入终端,如下所示。
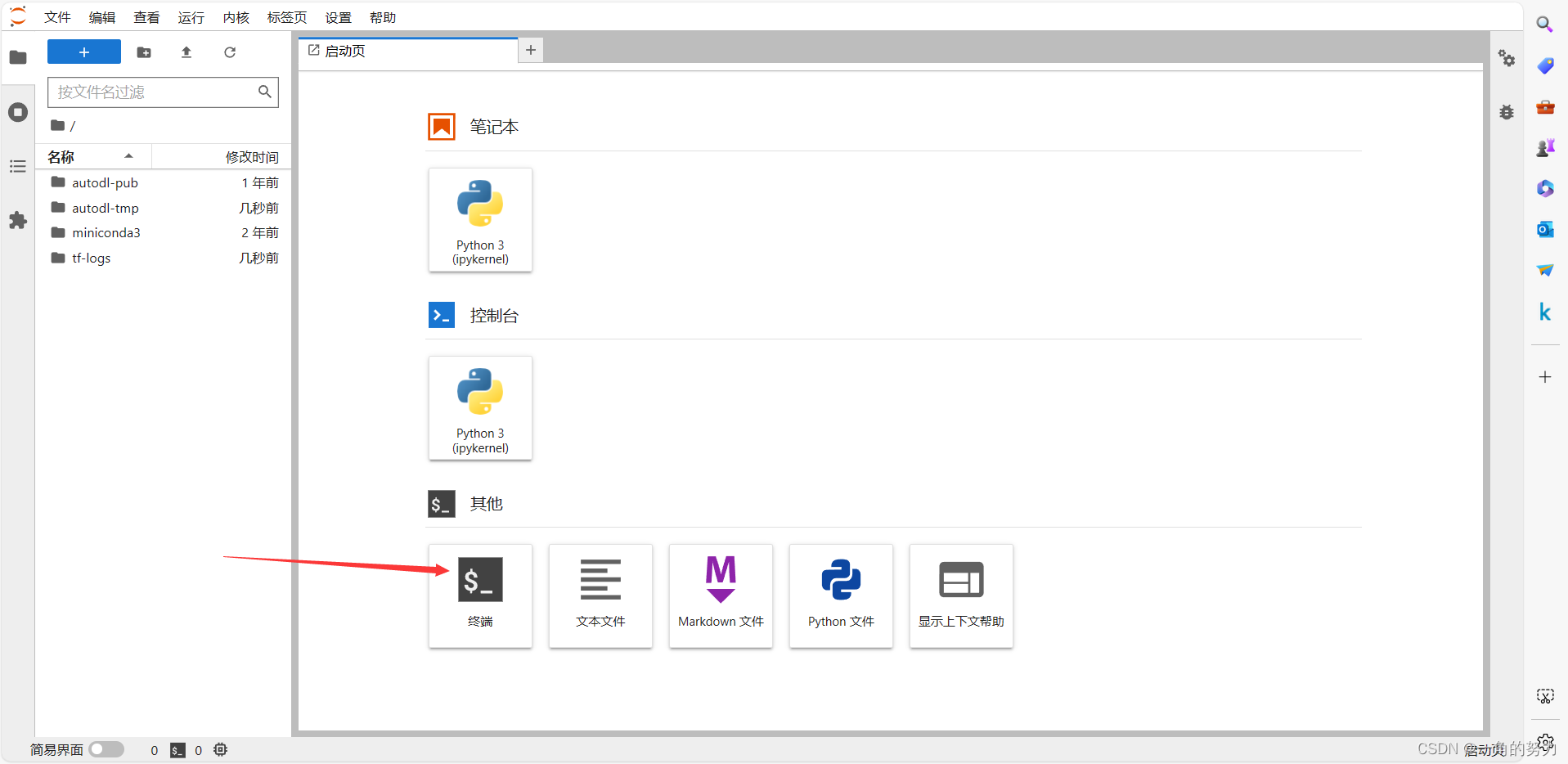
在终端输入相关命令:
(1)通过 'cd' 命令跳转到GPU服务器中已经上传的代码文件的目录(资源的上传与其相关目录上一篇文章已详细介绍);
(2)通过命令:python 训练文件.py进行模型的训练。
如下所示:
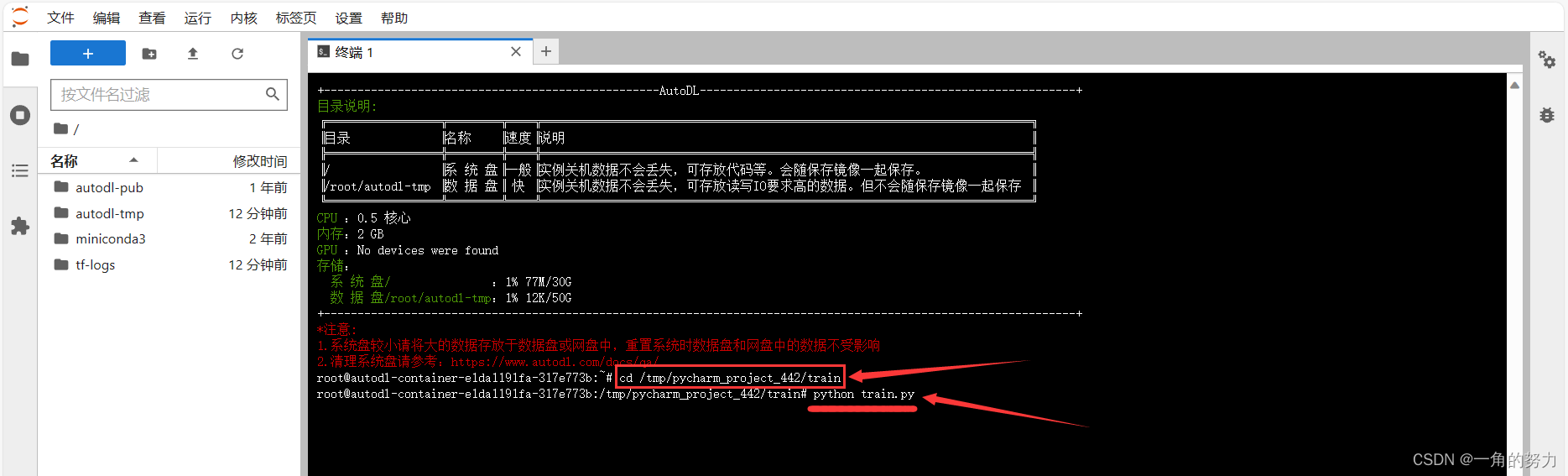
注意:跳转的资源文件目录随大家自己的情况进行更改
此方法无需pycharm连接GPU服务器,且可避免因网络、电脑本身等原因而导致的训练意外中止的问题(即训练开始后本地问题都可忽略)。建议大家使用pycharm连接GPU服务器时用于调试代码,而训练在终端进行。
训练效果如下所示:
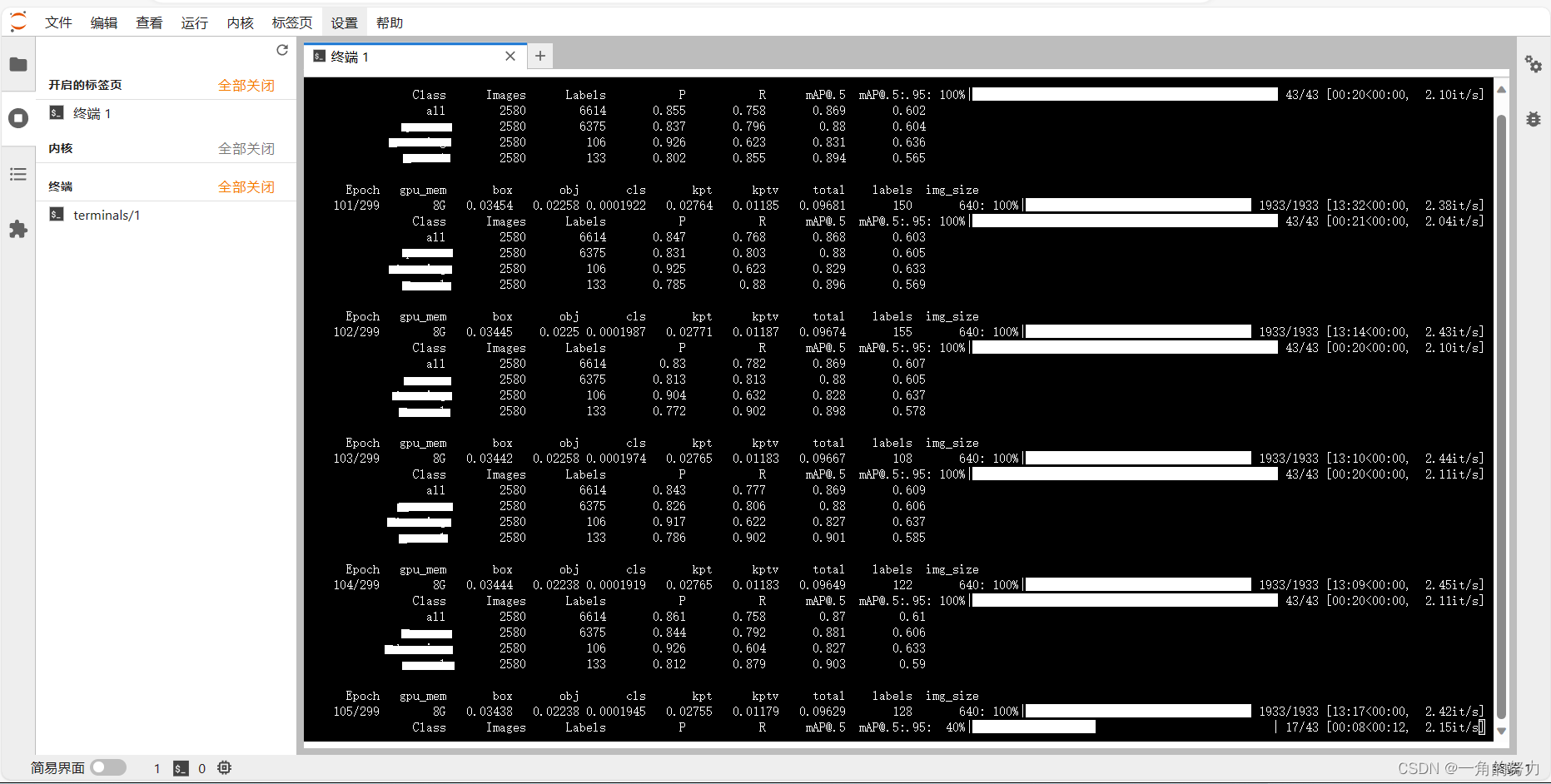
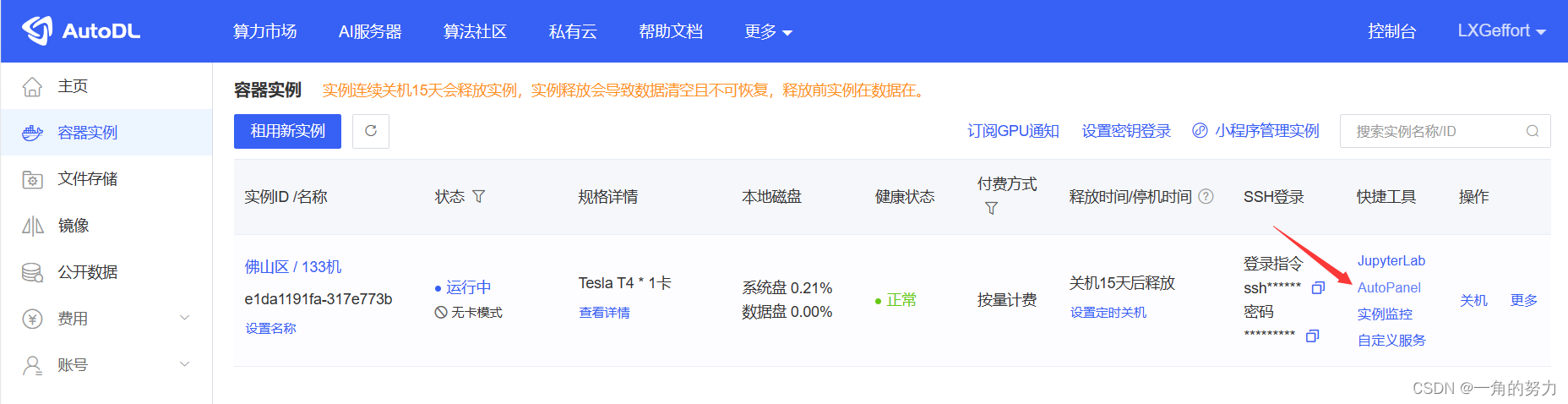
(3)大家可开启第二个终端界面,输入命令:nvidia-smi 查看GPU监控信息,不过这种方法得到的GPU训练数据不直观,大家可直接在容器实例中进入AutoPanel,里面可以很直观地查看GPU训练时的相关信息。
OK,以上就是本次文章的全部内容,有任何疑问大家可在评论区进行留言讨论,感谢大家的阅读!