RPC定义
远程过程调用(Remote Procedure Call)。RPC的目的就是让构建分布式计算(应用)更加简单,在提供强大的调用远程调用的同时不失去简单的本地调用的语义简洁性
RPC整体架构
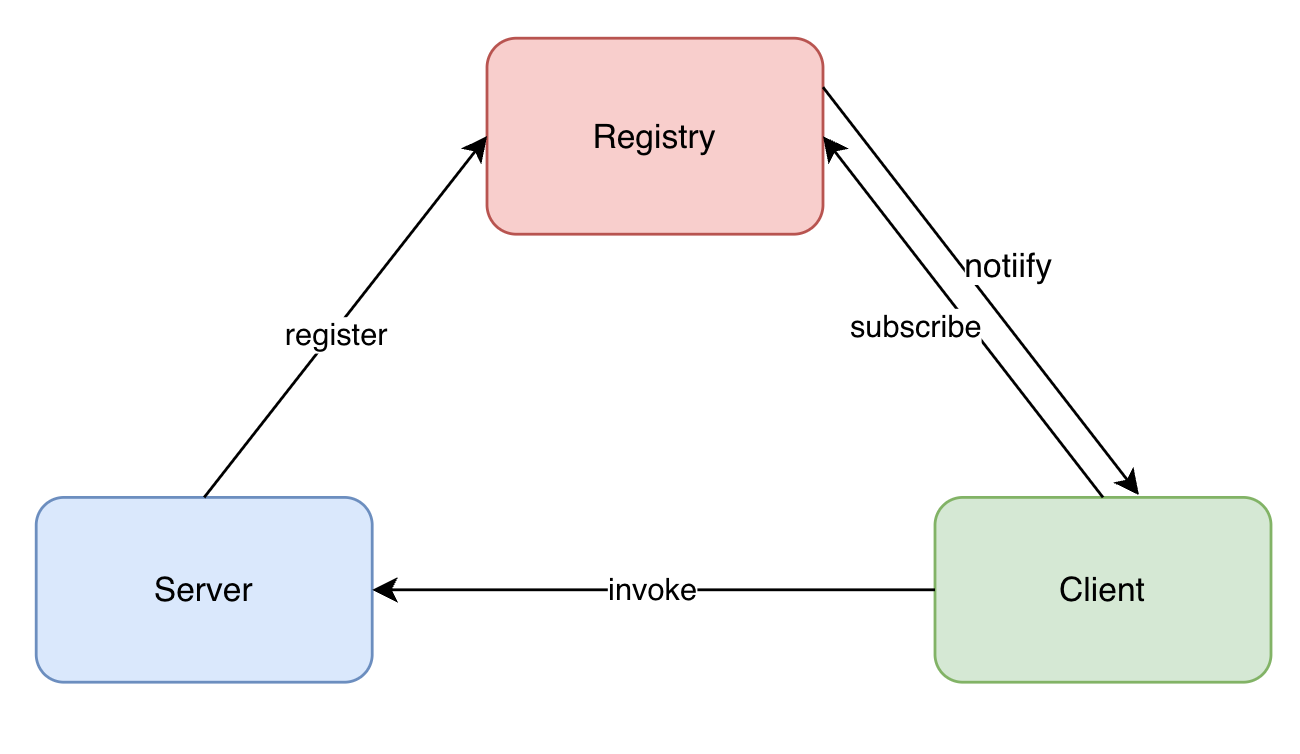
服务端启动时首先将自己的服务节点信息注册到注册中心,客户端调用远程方法时会订阅注册中心中的可用服务节点信息,拿到可用服务节点之后远程调用方法,当注册中心中的可用服务节点发生变化时会通知客户端,避免客户端继续调用已经失效的节点。那客户端是如何调用远程方法的呢,来看一下远程调用示意图:
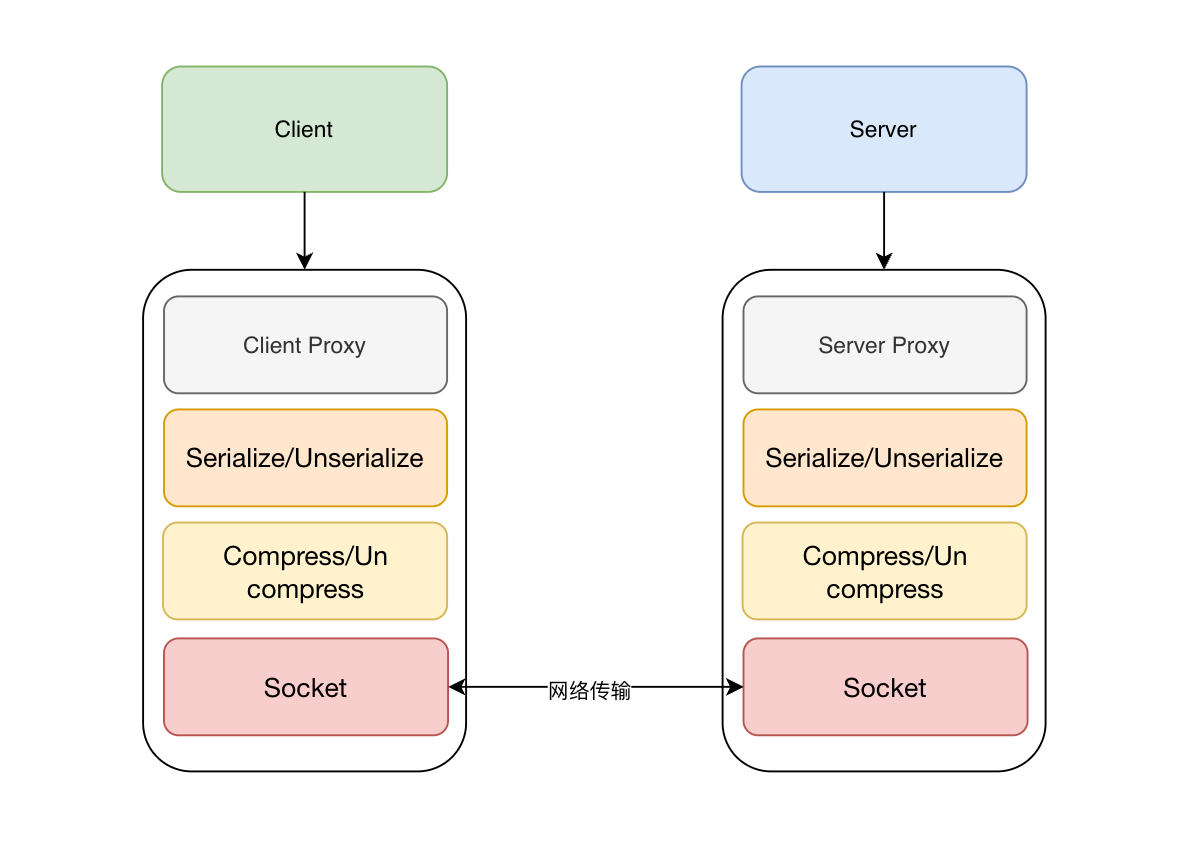
步骤:
- 服务消费者(client客户端)通过本地调用的方式调用服务。
- 客户端存根(client stub)接收到请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息
体。- 客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端。
- 服务端存根(server stub)收到消息后进行解码(反序列化操作)。
- 服务端存根(server stub)根据解码结果调用本地的服务进行相关处理。
- 本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub)。
- 服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方。
- 客户端存根(client stub)接收到消息,并进行解码(反序列化)。
- 服务消费方得到最终结果。
RPC的实现细节
服务注册与发现
服务注册:服务提供方将对外暴露的接口发布到注册中心内,注册中心为了检测服务的有效状态,一般会建立双向心跳机制。
服务订阅:服务调用方去注册中心查找并订阅服务提供方的 IP,并缓存到本地用于后续调用。
ZooKeeper节点
- 持久节点( PERSISENT ):一旦创建,除非主动调用删除操作,否则一直持久化存储。
- 临时节点( EPHEMERAL ):与客户端会话绑定,客户端会话失效,这个客户端所创建的所有临时节点都会被删除除。
- 节点顺序( SEQUENTIAL ):创建子节点时,如果设置SEQUENTIAL属性,则会自动在节点名后追加一个整形数字,上限是整形的最大值;同一目录下共享顺序,例如(/a0000000001,/b0000000002,/c0000000003,/test0000000004)。
服务注册
在 ZooKeeper 根节点下根据服务名创建持久节点 /rpc/{serviceName}/service ,将该服务的所有服务节点使用临时节点创建在 /rpc/{serviceName}/service目录下
服务发现
客户端启动后,不会立即从注册中心获取可用服务节点,而是在调用远程方法时获取节点信息(懒加载),并放入本地缓存 MAP 中,供后续调用,当注册中心通知目录变化时清空服务所有节点缓存
ZooKeeper方案的特点:
强一致性,ZooKeeper 集群的每个节点的数据每次发生更新操作,都会通知其它 ZooKeeper 节点同时执行更新。美团分布式 ID 生成系统Leaf就使用 Zookeeper 的顺序节点来注册 WorkerID ,临时节点保存节点 IP:PORT 信息。
动态代理技术
RPC实现远程调用与本地调用效果一样与Java的动态代理技术密不可分
DefaultRpcBaseProcessor 抽象类实现了 ApplicationListener , onApplicationEvent 方法在 Spring 项目启动完毕会收到时间通知,获取 ApplicationContext 上下文之后开始注入服务 injectService (有依赖服务)或者启动服务 startServer (有服务实现)。
injectService 方法会遍历 ApplicationContext 上下文中的所有 Bean , Bean 中是否有属性使用了 InjectService 注解。有的话生成代理类,注入到 Bean 的属性中。
public abstract class DefaultRpcBaseProcessor implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
//Spring启动完毕会收到Event
if (Objects.isNull(contextRefreshedEvent.getApplicationContext().getParent())) {
ApplicationContext applicationContext = contextRefreshedEvent.getApplicationContext();
//保存spring上下文 后续使用
Container.setSpringContext(applicationContext);
startServer(applicationContext);
injectService(applicationContext);
}
}
private void injectService(ApplicationContext context) {
String[] names = context.getBeanDefinitionNames();
for (String name : names) {
Object bean = context.getBean(name);
Class<?> clazz = bean.getClass();
if (AopUtils.isCglibProxy(bean)) {
//aop增强的类生成cglib类,需要Superclass才能获取定义的字段
clazz = clazz.getSuperclass();
} else if(AopUtils.isJdkDynamicProxy(bean)) {
//动态代理类,可能也需要
clazz = clazz.getSuperclass();
}
Field[] declaredFields = clazz.getDeclaredFields();
//设置InjectService的代理类
for (Field field : declaredFields) {
InjectService injectService = field.getAnnotation(InjectService.class);
if (injectService == null) {
continue;
}
Class<?> fieldClass = field.getType();
Object object = context.getBean(name);
field.set(object, clientProxyFactory.getProxy(fieldClass, injectService.group(), injectService.version()));
ServerDiscoveryCache.SERVER_CLASS_NAMES.add(fieldClass.getName());
}
}
}
protected abstract void startServer(ApplicationContext context);
}
调用 ClientProxyFactory 类的 getProxy ,根据服务接口、服务分组、服务版本、是否异步调用来创建该接口的代理类,对该接口的所有方法都会使用创建的代理类来调用。方法调用的实现细节都在 ClientInvocationHandler 中的 invoke 方法,主要内容是,获取服务节点信息,选择调用节点,构建 request 对象,最后调用网络模块发送请求。
public class ClientProxyFactory {
public <T> T getProxy(Class<T> clazz, String group, String version, boolean async) {
if (async) {
return (T) asyncObjectCache.computeIfAbsent(clazz.getName() + group + version, clz -> Proxy.newProxyInstance(clazz.getClassLoader(), new Class[]{clazz}, new ClientInvocationHandler(clazz, group, version, async)));
} else {
return (T) objectCache.computeIfAbsent(clazz.getName() + group + version, clz -> Proxy.newProxyInstance(clazz.getClassLoader(), new Class[]{clazz}, new ClientInvocationHandler(clazz, group, version, async)));
}
}
private class ClientInvocationHandler implements InvocationHandler {
private Class<?> clazz;
private boolean async;
private String group;
private String version;
public ClientInvocationHandler(Class<?> clazz, String group, String version, boolean async) {
this.clazz = clazz;
this.async = async;
this.group = group;
this.version = version;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//1. 获得服务信息
String serviceName = clazz.getName();
List<Service> serviceList = getServiceList(serviceName);
Service service = loadBalance.selectOne(serviceList);
//2. 构建request对象
RpcRequest rpcRequest = new RpcRequest();
rpcRequest.setServiceName(service.getName());
rpcRequest.setMethod(method.getName());
rpcRequest.setGroup(group);
rpcRequest.setVersion(version);
rpcRequest.setParameters(args);
rpcRequest.setParametersTypes(method.getParameterTypes());
//3. 协议编组
RpcProtocolEnum messageProtocol = RpcProtocolEnum.getProtocol(service.getProtocol());
RpcCompressEnum compresser = RpcCompressEnum.getCompress(service.getCompress());
RpcResponse response = netClient.sendRequest(rpcRequest, service, messageProtocol, compresser);
return response.getReturnValue();
}
}
}
网络传输
客户端封装调用请求对象之后需要通过网络将调用信息发送到服务端,在发送请求对象之前还需要经历序列化、压缩两个阶段。
序列化与反序列化
序列化与反序列化的核心作用就是对象的保存与重建,方便客户端与服务端通过字节流传递对象,快速对接交互。
- 序列化就是指把 Java 对象转换为字节序列的过程。
- 反序列化就是指把字节序列恢复为 Java 对象的过程。
常用序列化技术
- 1、JDK原生序列化,通过实现Serializable接口。通过ObjectOutPutSream和ObjectInputStream对象进行序列化及反序列化.
- 2、JSON序列化。一般在HTTP协议的RPC框架通信中,会选择JSON方式。JSON具有较好的扩展性、可读性和通用性。但JSON序列化占用空间开销较大,没有JAVA的强类型区分,需要通过反射解决,解析效率和压缩率都较差。如果对并发和性能要求较高,或者是传输数据量较大的场景,不建议采用JSON序列化方式。
- 3、Hessian2序列化。Hessian 是一个动态类型,二进制序列化,并且支持跨语言特性的序列化框架。Hessian 性能上要比 JDK、JSON 序列化高效很多,并且生成的字节数也更小。有非常好的兼容性和稳定性,所以 Hessian 更加适合作为 RPC 框架远程通信的序列化协议
压缩与解压
网络通信的成本很高,为了减小网络传输数据包的体积,将序列化之后的字节码压缩不失为一种很好的选择。Gzip 压缩算法比率在3到10倍左右,可以大大节省服务器的网络带宽,各种流行的 web 服务器也都支持 Gzip 压缩算法。 Java 接入也比较容易,接入代码可以查看下方接口的实现。
public interface Compresser {
byte[] compress(byte[] bytes);
byte[] decompress(byte[] bytes);
}
网络通信
万事俱备只欠东风。将请求对象序列化成字节码,并且压缩体积之后,需要使用网络将字节码传输到服务器。常用网络传输协议有 HTTP 、 TCP 、 WebSocke t等。HTTP、WebSocket 是应用层协议,TCP 是传输层协议。有些追求简洁、易用的 RPC 框架也有选择 HTTP 协议的。TCP传输的高可靠性和极致性能是主流RPC框架选择的最主要原因。谈到 Java 生态的通信领域,Netty的领衔地位短时间内无人能及。选用 Netty 作为网络通信模块, TCP 数据流的粘包、拆包不可避免。
粘包、拆包
TCP的粘包和拆包问题往往出现在基于TCP协议的通讯中,比如我们学习的RPC框架、Netty
粘包拆包发生场景
因为TCP是面向流,没有边界,而操作系统在发送TCP数据时,会通过缓冲区来进行优化,例如缓冲区为1024个字节大小。
如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题。
如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包。
Netty对粘包和拆包问题的处理
Netty对解决粘包和拆包的方案做了抽象,提供了一些解码器(Decoder)来解决粘包和拆包的问题。如:
- LineBasedFrameDecoder:以行为单位进行数据包的解码;
- DelimiterBasedFrameDecoder:以特殊的符号作为分隔来进行数据包的解码;
- FixedLengthFrameDecoder:以固定长度进行数据包的解码;
- LenghtFieldBasedFrameDecode:适用于消息头包含消息长度的协议(最常用);
基于Netty进行网络读写的程序,可以直接使用这些Decoder来完成数据包的解码。对于高并发、大流量的系统来说,每个数据包都不应该传输多余的数据(所以补齐的方式不可取),LenghtFieldBasedFrameDecode更适合这样的场景。