import numpy as np
import torch
from functools import partial
from PIL import Image
from torch. utils. data. dataset import Dataset
from torch. utils. data import DataLoader
import random
import albumentations as A
from pycocotools. coco import COCO
import os
import cv2
import matplotlib. pyplot as plt
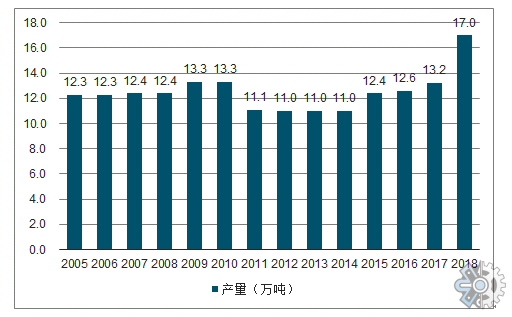
albumentations库自定义数据预处理/数据增强class Transform ( ) :
'''数据预处理/数据增强(基于albumentations库)
'''
def __init__ ( self, imgSize) :
maxSize = max ( imgSize[ 0 ] , imgSize[ 1 ] )
self. trainTF = A. Compose( [
A. BBoxSafeRandomCrop( p= 0.5 ) ,
A. LongestMaxSize( max_size= maxSize) ,
A. HorizontalFlip( p= 0.5 ) ,
A. HueSaturationValue( hue_shift_limit= 20 , sat_shift_limit= 30 , val_shift_limit= 20 , always_apply= False , p= 0.5 ) ,
A. RandomBrightnessContrast( p= 0.2 ) ,
A. GaussNoise( var_limit= ( 0.05 , 0.09 ) , p= 0.4 ) ,
A. OneOf( [
A. MotionBlur( p= 0.2 ) ,
A. MedianBlur( blur_limit= 3 , p= 0.1 ) ,
A. Blur( blur_limit= 3 , p= 0.1 ) ,
] , p= 0.2 ) ,
A. PadIfNeeded( imgSize[ 0 ] , imgSize[ 1 ] , border_mode= cv2. BORDER_CONSTANT, value= [ 0 , 0 , 0 ] ) ,
A. Normalize( mean= ( 0.485 , 0.456 , 0.406 ) , std= ( 0.229 , 0.224 , 0.225 ) ) ,
] ,
bbox_params= A. BboxParams( format = 'coco' , min_area= 0 , min_visibility= 0.1 , label_fields= [ 'category_ids' ] ) ,
)
self. validTF = A. Compose( [
A. LongestMaxSize( max_size= maxSize) ,
A. PadIfNeeded( imgSize[ 0 ] , imgSize[ 1 ] , border_mode= 0 , mask_value= [ 0 , 0 , 0 ] ) ,
A. Normalize( mean= ( 0.485 , 0.456 , 0.406 ) , std= ( 0.229 , 0.224 , 0.225 ) ) ,
] ,
bbox_params= A. BboxParams( format = 'coco' , min_area= 0 , min_visibility= 0.1 , label_fields= [ 'category_ids' ] ) ,
)
COCODataset实现
class COCODataset ( Dataset) :
def __init__ ( self, annPath, imgDir, inputShape= [ 800 , 600 ] , trainMode= True ) :
'''__init__() 为默认构造函数,传入数据集类别(训练或测试),以及数据集路径
Args:
:param annPath: COCO annotation 文件路径
:param imgDir: 图像的根目录
:param inputShape: 网络要求输入的图像尺寸
:param trainMode: 训练集/测试集
Returns:
FRCNNDataset
'''
self. mode = trainMode
self. tf = Transform( imgSize= inputShape)
self. imgDir = imgDir
self. annPath = annPath
self. DataNums = len ( os. listdir( imgDir) )
self. coco= COCO( annPath)
self. imgIds = list ( self. coco. imgs. keys( ) )
def __len__ ( self) :
'''重载data.Dataset父类方法, 返回数据集大小
'''
return len ( self. imgIds)
def __getitem__ ( self, index) :
'''重载data.Dataset父类方法, 获取数据集中数据内容
这里通过pycocotools来读取图像和标签
'''
imgId = self. imgIds[ index]
imgInfo = self. coco. loadImgs( imgId) [ 0 ]
image = Image. open ( os. path. join( self. imgDir, imgInfo[ 'file_name' ] ) )
image = np. array( image. convert( 'RGB' ) )
imgAnnIds = self. coco. getAnnIds( imgIds= imgId)
anns = self. coco. loadAnns( imgAnnIds)
labels, boxes = [ ] , [ ]
for ann in anns:
labelName = ann[ 'category_id' ]
labels. append( labelName)
boxes. append( ann[ 'bbox' ] )
labels = np. array( labels)
boxes = np. array( boxes)
if ( self. mode) :
transformed = self. tf. trainTF( image= image, bboxes= boxes, category_ids= labels)
else :
transformed = self. tf. validTF( image= image, bboxes= boxes, category_ids= labels)
image, box, label = transformed[ 'image' ] , transformed[ 'bboxes' ] , transformed[ 'category_ids' ]
return image. transpose( 2 , 0 , 1 ) , np. array( box) , np. array( label)
def frcnn_dataset_collate ( batch) :
images = [ ]
bboxes = [ ]
labels = [ ]
for img, box, label in batch:
images. append( img)
bboxes. append( box)
labels. append( label)
images = torch. from_numpy( np. array( images) )
return images, bboxes, labels
def worker_init_fn ( worker_id, seed) :
worker_seed = worker_id + seed
random. seed( worker_seed)
np. random. seed( worker_seed)
torch. manual_seed( worker_seed)
def seed_everything ( seed) :
random. seed( seed)
np. random. seed( seed)
torch. manual_seed( seed)
torch. cuda. manual_seed( seed)
torch. cuda. manual_seed_all( seed)
torch. backends. cudnn. deterministic = True
torch. backends. cudnn. benchmark = False
def visBatch ( dataLoader: DataLoader) :
'''可视化训练集一个batch
Args:
dataLoader: torch的data.DataLoader
Retuens:
None
'''
catName = { 1 : 'person' , 2 : 'bicycle' , 3 : 'car' , 4 : 'motorcycle' , 5 : 'airplane' , 6 : 'bus' ,
7 : 'train' , 8 : 'truck' , 9 : 'boat' , 10 : 'traffic light' , 11 : 'fire hydrant' ,
13 : 'stop sign' , 14 : 'parking meter' , 15 : 'bench' , 16 : 'bird' , 17 : 'cat' , 18 : 'dog' ,
19 : 'horse' , 20 : 'sheep' , 21 : 'cow' , 22 : 'elephant' , 23 : 'bear' , 24 : 'zebra' , 25 : 'giraffe' ,
27 : 'backpack' , 28 : 'umbrella' , 31 : 'handbag' , 32 : 'tie' , 33 : 'suitcase' , 34 : 'frisbee' ,
35 : 'skis' , 36 : 'snowboard' , 37 : 'sports ball' , 38 : 'kite' , 39 : 'baseball bat' ,
40 : 'baseball glove' , 41 : 'skateboard' , 42 : 'surfboard' , 43 : 'tennis racket' ,
44 : 'bottle' , 46 : 'wine glass' , 47 : 'cup' , 48 : 'fork' , 49 : 'knife' , 50 : 'spoon' , 51 : 'bowl' ,
52 : 'banana' , 53 : 'apple' , 54 : 'sandwich' , 55 : 'orange' , 56 : 'broccoli' , 57 : 'carrot' ,
58 : 'hot dog' , 59 : 'pizza' , 60 : 'donut' , 61 : 'cake' , 62 : 'chair' , 63 : 'couch' ,
64 : 'potted plant' , 65 : 'bed' , 67 : 'dining table' , 70 : 'toilet' , 72 : 'tv' , 73 : 'laptop' ,
74 : 'mouse' , 75 : 'remote' , 76 : 'keyboard' , 77 : 'cell phone' , 78 : 'microwave' ,
79 : 'oven' , 80 : 'toaster' , 81 : 'sink' , 82 : 'refrigerator' , 84 : 'book' , 85 : 'clock' ,
86 : 'vase' , 87 : 'scissors' , 88 : 'teddy bear' , 89 : 'hair drier' , 90 : 'toothbrush' }
for step, batch in enumerate ( dataLoader) :
images, boxes, labels = batch[ 0 ] , batch[ 1 ] , batch[ 2 ]
if step > 0 : break
mean = np. array( [ 0.485 , 0.456 , 0.406 ] )
std = np. array( [ [ 0.229 , 0.224 , 0.225 ] ] )
plt. figure( figsize = ( 8 , 8 ) )
for idx, imgBoxLabel in enumerate ( zip ( images, boxes, labels) ) :
img, box, label = imgBoxLabel
ax = plt. subplot( 4 , 4 , idx+ 1 )
img = img. numpy( ) . transpose( ( 1 , 2 , 0 ) )
img = img * std + mean
for instBox, instLabel in zip ( box, label) :
x, y, w, h = round ( instBox[ 0 ] ) , round ( instBox[ 1 ] ) , round ( instBox[ 2 ] ) , round ( instBox[ 3 ] )
ax. add_patch( plt. Rectangle( ( x, y) , w, h, color= 'blue' , fill= False , linewidth= 2 ) )
ax. text( x, y, catName[ instLabel] , bbox= { 'facecolor' : 'white' , 'alpha' : 0.5 } )
plt. imshow( img)
plt. axis( "off" )
plt. subplots_adjust( left= 0.05 , bottom= 0.05 , right= 0.95 , top= 0.95 , wspace= 0.05 , hspace= 0.05 )
plt. show( )
if __name__ == "__main__" :
seed = 23
seed_everything( seed)
BS = 16
imgSize = [ 800 , 800 ]
trainAnnPath = "E:/datasets/Universal/COCO2017/annotations/instances_train2017.json"
testAnnPath = "E:/datasets/Universal/COCO2017/annotations/instances_val2017.json"
imgDir = "E:/datasets/Universal/COCO2017/train2017"
trainDataset = COCODataset( trainAnnPath, imgDir, imgSize, trainMode= True )
trainDataLoader = DataLoader( trainDataset, shuffle= True , batch_size = BS, num_workers= 2 , pin_memory= True ,
collate_fn= frcnn_dataset_collate, worker_init_fn= partial( worker_init_fn, seed= seed) )
print ( f'训练集大小 : { trainDataset. __len__( ) } ' )
visBatch( trainDataLoader)
for step, batch in enumerate ( trainDataLoader) :
images, boxes, labels = batch[ 0 ] , batch[ 1 ] , batch[ 2 ]
print ( f'images.shape : { images. shape} ' )
print ( f'len(boxes) : { len ( boxes) } ' )
print ( f'len(labels) : { len ( labels) } ' )
break
images.shape : torch.Size( [ 16 , 3 , 800 , 800 ] )
len( boxes) : 16
len( labels) : 16





![[C#]winform部署openvino官方提供的人脸检测模型](https://img-blog.csdnimg.cn/direct/3ba91b7e5e204a1681ee6dd9815e4af4.jpeg)