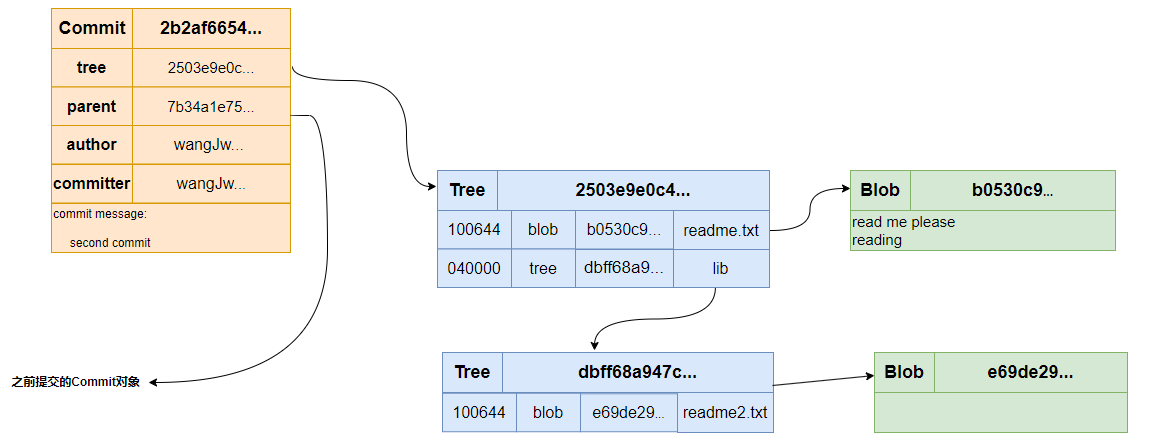
文章目录
- 第二课:BERT
- 1、学习总结:
- 为什么要学习BERT?
- 预训练模型的发展历程
- BERT结构
- BERT 输入
- BERT Embedding
- BERT 模型构建
- BERT self-attention 层
- BERT self-attention 输出层
- BERT feed-forward 层
- BERT 最后的Add&Norm
- BERT Encoder
- BERT 输出
- BERT Pooler
- BERT 预训练
- Masked LM
- NSP
- BERT预训练代码整合
- 课程ppt及代码地址
- 2、学习心得:
- 3、经验分享:
- 4、课程反馈:
- 5、使用MindSpore昇思的体验和反馈:
- 6、未来展望:
第二课:BERT
1、学习总结:
为什么要学习BERT?
虽然目前decoder only的模型是业界主流,但是encoder 的模型bert规模较小,更适合新手作为第一个上手的大模型,这样后面学习其他的大模型就不会感觉到过于困难。
-
Decoder only模型当道: GPT3、Bloom、LLAMA、GLM
-
Transformer Encoder结构在生成式任务上的缺陷
-
BERT模型规模小
-
Pretrain-Fintune范式的落寞
-
2022年以前,学术界还是在倒腾BERT
-
Finetune更容易针对单领域任务训练
-
BERT是首个大规模并行预训练的模型,也是当前的performance baseline
-
由BERT入手学大模型训练、微调、Prompt最简单
-
预训练模型的发展历程
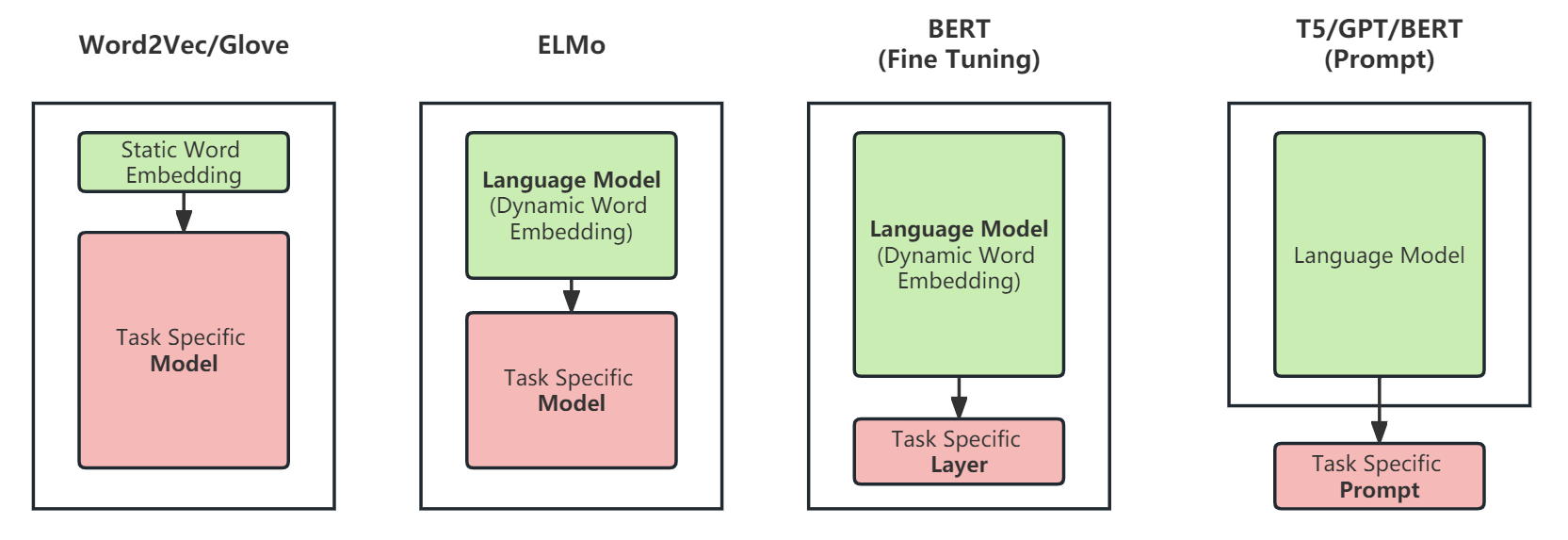
语言模型的演变经历了以下几个阶段:
-
word2vec/Glove将离散的文本数据转换为固定长度的静态词向量,后根据下游任务训练不同的语言模型; -
ELMo预训练模型将文本数据结合上下文信息,转换为动态词向量,后根据下游任务训练不同的语言模型; -
BERT同样将文本数据转换为动态词向量,能够更好地捕捉句子级别的信息与语境信息,后续只需finetune最后的输出层即可适配下游任务; -
GPT等预训练语言模型主要用于文本生成类任务,需要通过prompt方法来应用于下游任务,指导模型生成特定的输出。
BERT结构
BERT模型本质上是结合了ELMo模型与GPT模型的优势。
- 相比于ELMo,BERT仅需改动最后的输出层,而非模型架构,便可以在下游任务中达到很好的效果;
- 相比于GPT,BERT在处理词元表示时考虑到了双向上下文的信息;
BERT通过两种无监督任务(Masked Language Modelling 和 Next Sentence Prediction)进行预训练,其次,在下游任务中对预训练Transformer编码器的所有参数进行微调,额外的输出层将从头开始训练。
Reference: The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
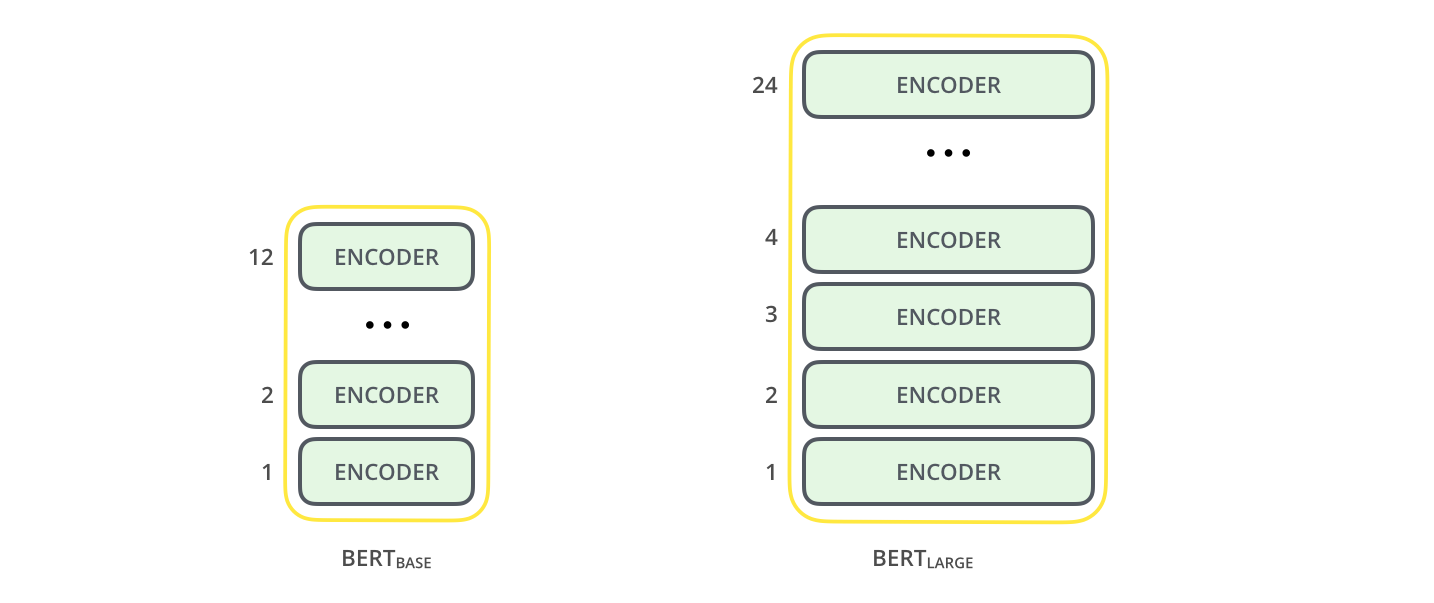
BERT(Bidirectional Encoder Representation from Transformers)是由Transformer的Encoder层堆叠而成,BERT的模型大小有如下两种:
- BERT BASE:与Transformer参数量齐平,用于比较模型效果(110M parameters)
- BERT LARGE:在BERT BASE基础上扩大参数量,达到了当时各任务最好的结果(340M parameters)
| model | blocks | hidden size | attention heads |
|---|---|---|---|
| Transformer | 6 | 512 | 8 |
| BERT BASE | 12 | 768 | 12 |
| BERT LARGE | 24 | 1024 | 16 |
Reference: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
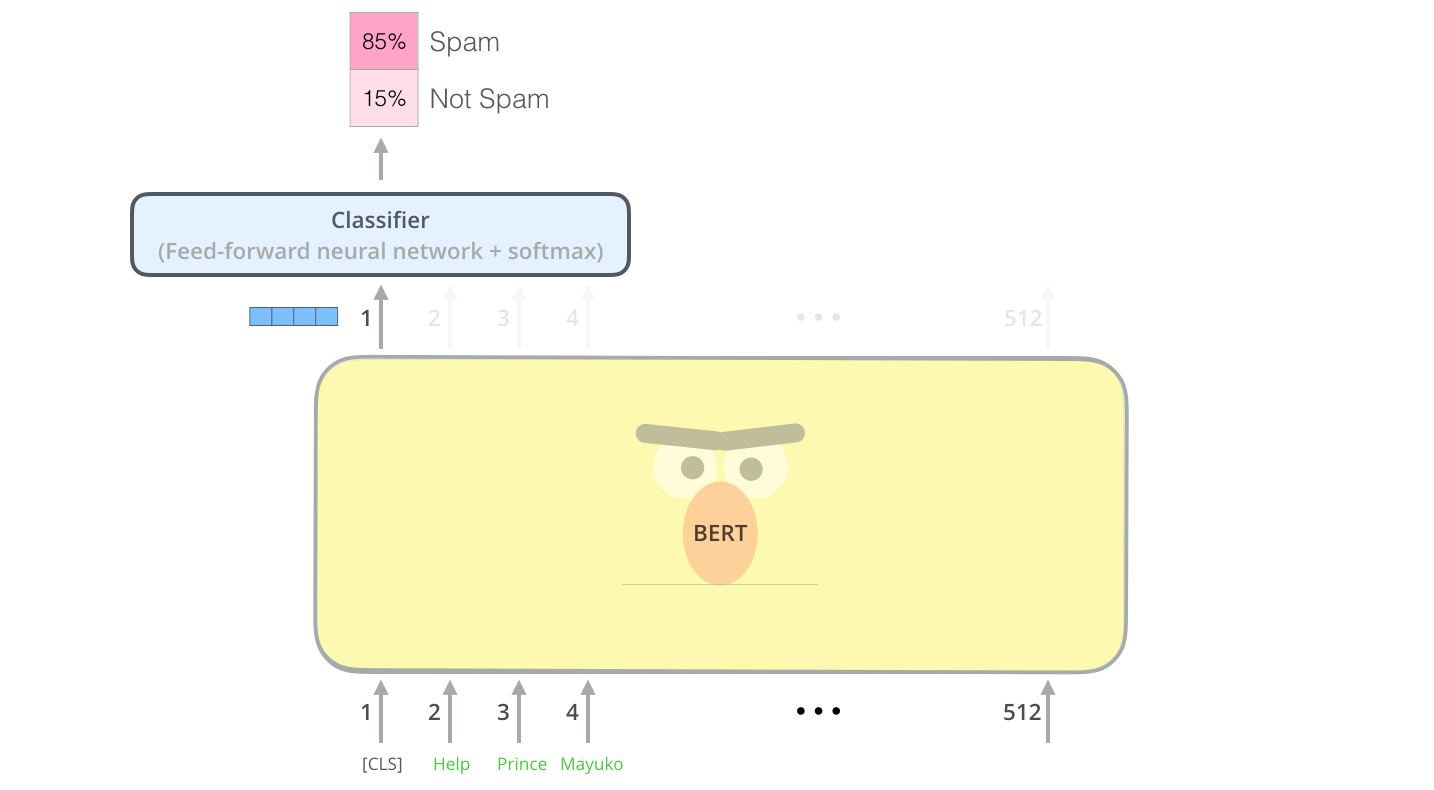
接受输入序列后,BERT会输出每个位置对应的向量(长度等于hidden size),在后续下游任务中,我们会选取与任务相关的位置的向量,输入到最终输出层中得到结果。
如在诈骗邮件分类任务中,我们会将表示句子级别信息的[CLS] token所对应的vector,放入classfier中,得到对spam/not spam分类的预测。
BERT 输入
- 针对句子对相关任务,将两个句子合并为一个句子对输入到Encoder中,
[CLS]+ 第一个句子 +[SEP]+ 第二个句子 +[SEP]; - 针对单个文本相关任务,
[CLS]+ 句子 +
[SEP]。
在诈骗邮件分类中,输入为单个句子,在拆分为tokens后,在序列首尾分别添加[CLS]与[SEP]即可。
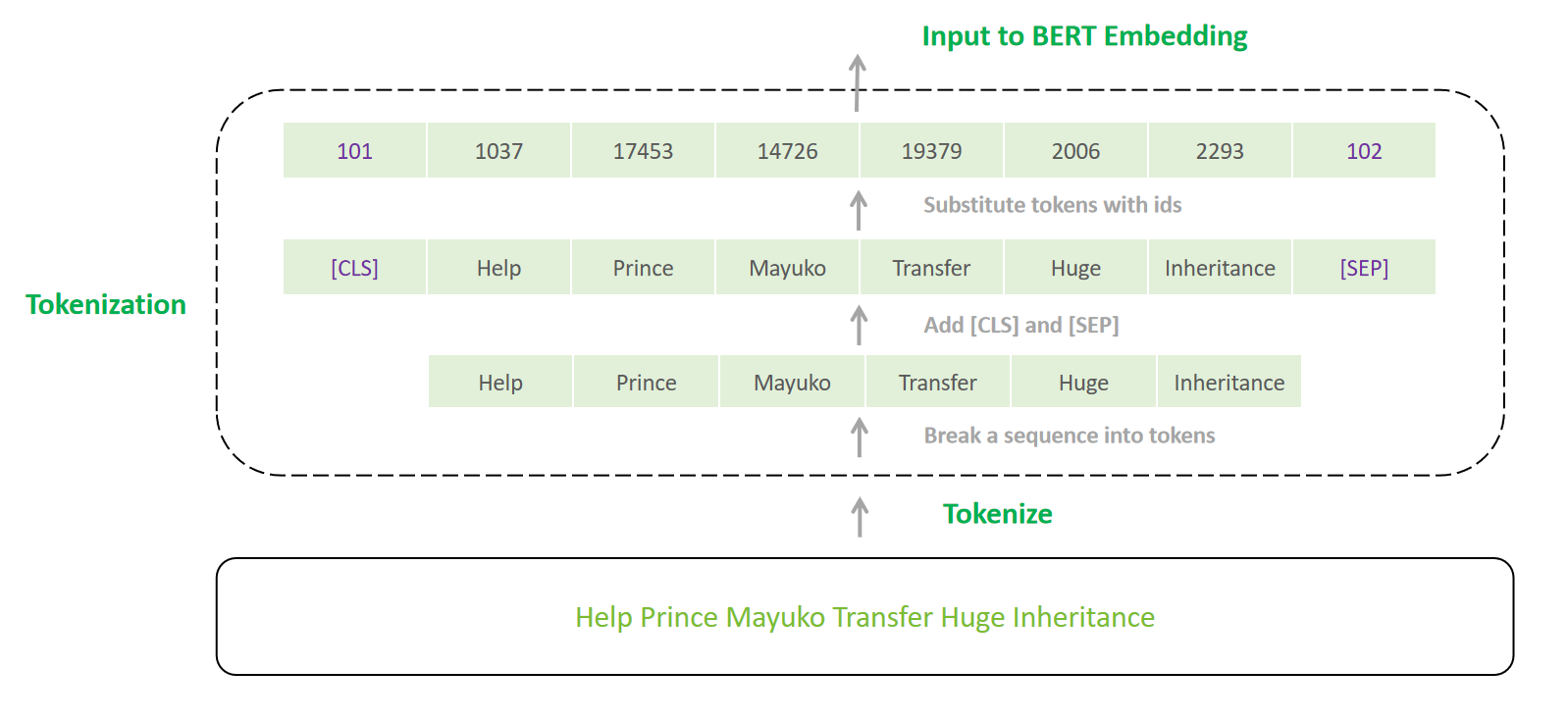
# install mindnlp
!pip install git+https://openi.pcl.ac.cn/lvyufeng/mindnlp
from mindnlp.transforms.tokenizers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
sequence = 'help prince mayuko transfer huge inheritance'
model_inputs = tokenizer(sequence)
print(model_inputs)
tokens = []
for index in model_inputs:
tokens.append(tokenizer.id_to_token(index))
print(tokens)
BERT Embedding
输入到BERT模型的信息由三部分内容组成:
- 表示内容的token ids
- 表示位置的position ids
- 用于区分不同句子的token type ids
三种信息分别进入Embedding层,得到token embeddings、position embeddings与segment embeddings;与Transformer不同,以上三种均为可学习的信息。
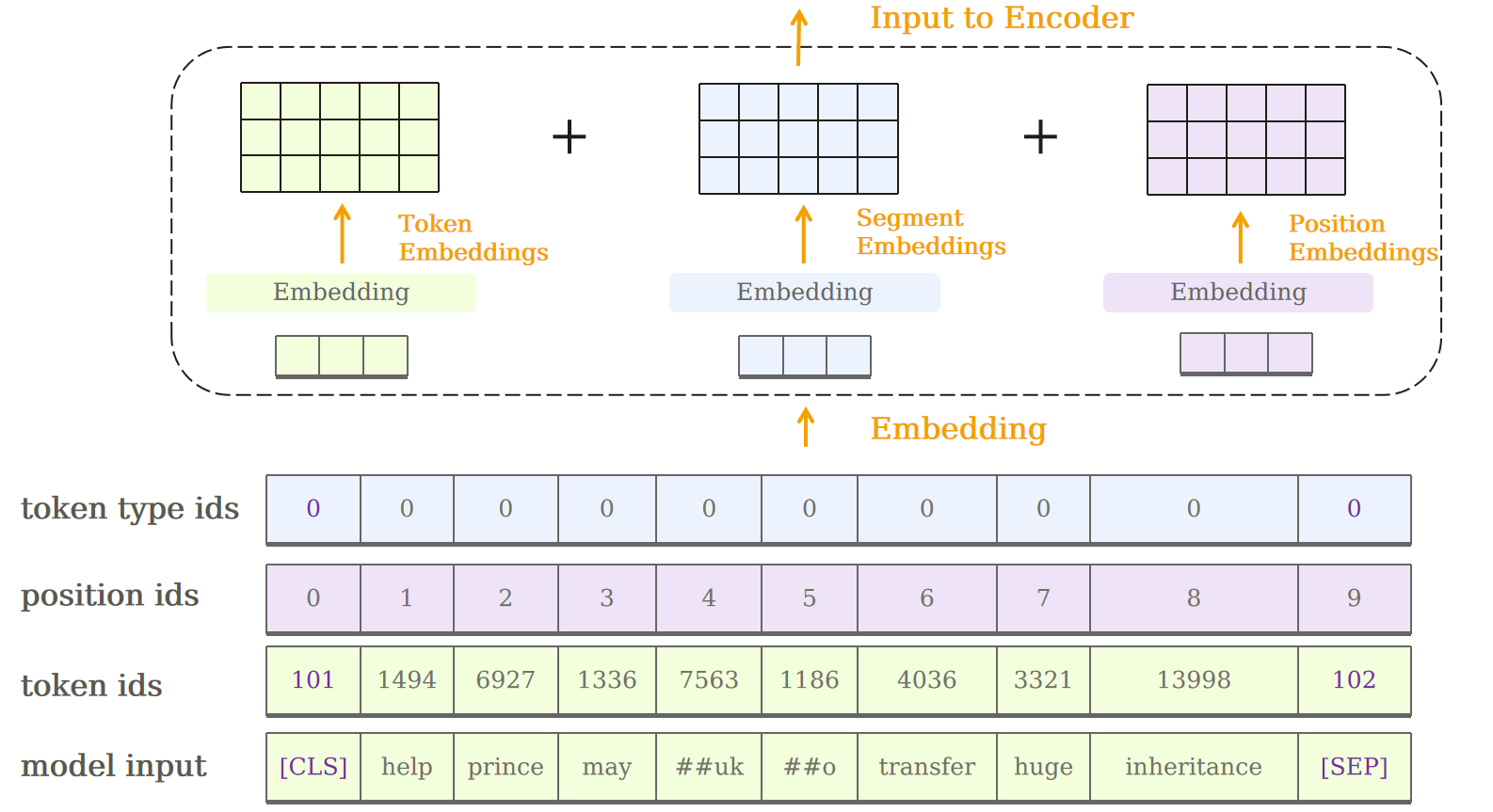
图片来源:Devlin, J.; Chang, M. W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
import mindspore
from mindspore import nn
import mindspore.common.dtype as mstype
from mindspore.common.initializer import initializer, TruncatedNormal
class BertEmbeddings(nn.Cell):
"""
Embeddings for BERT, include word, position and token_type
"""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, embedding_table=TruncatedNormal(config.initializer_range))
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size, embedding_table=TruncatedNormal(config.initializer_range))
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size, embedding_table=TruncatedNormal(config.initializer_range))
self.layer_norm = nn.LayerNorm((config.hidden_size,), epsilon=config.layer_norm_eps)
self.dropout = nn.Dropout(1 - config.hidden_dropout_prob)
def construct(self, input_ids, token_type_ids=None, position_ids=None):
seq_len = input_ids.shape[1]
if position_ids is None:
position_ids = mnp.arange(seq_len)
position_ids = position_ids.expand_dims(0).expand_as(input_ids)
if token_type_ids is None:
token_type_ids = ops.zeros_like(input_ids)
words_embeddings = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + position_embeddings + token_type_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
BERT 模型构建
BERT模型的构建与上一节课程的Transformer Encoder构建类似。
分别构建multi-head attention层,feed-forward network,并在中间用add&norm连接,最后通过线性层与softmax层进行输出。

BERT self-attention 层
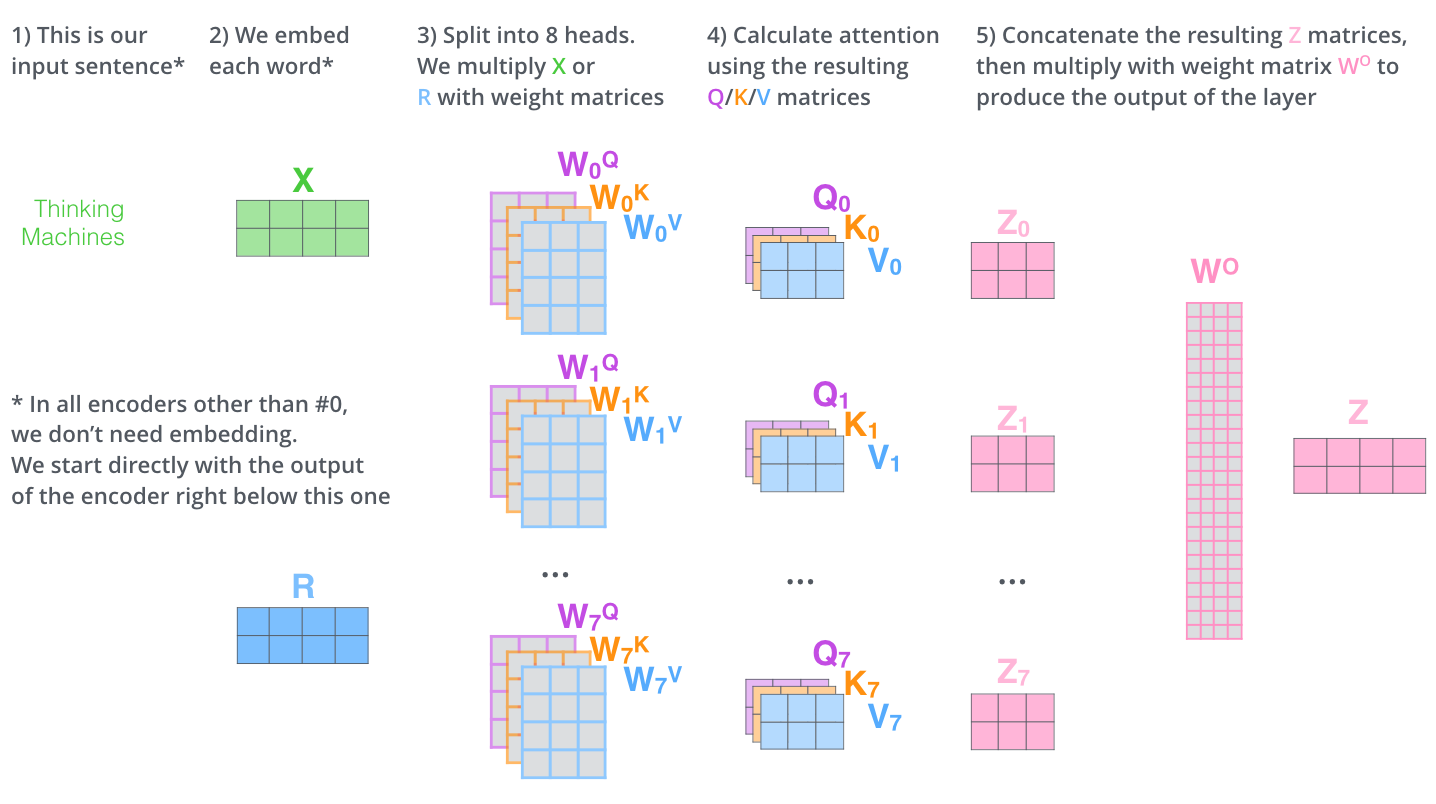
class BertSelfAttention(nn.Cell):
"""
Self attention layer for BERT.
"""
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
f"The hidden size {config.hidden_size} is not a multiple of the number of attention "
f"heads {config.num_attention_heads}"
)
self.output_attentions = config.output_attentions
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Dense(config.hidden_size, self.all_head_size, \
weight_init=TruncatedNormal(config.initializer_range))
self.key = nn.Dense(config.hidden_size, self.all_head_size, \
weight_init=TruncatedNormal(config.initializer_range))
self.value = nn.Dense(config.hidden_size, self.all_head_size, \
weight_init=TruncatedNormal(config.initializer_range))
self.dropout = Dropout(config.attention_probs_dropout_prob)
self.softmax = nn.Softmax(-1)
self.matmul = Matmul()
def transpose_for_scores(self, input_x):
"""
transpose for scores
[batch_size, seq_len, num_heads, head_size] to [batch_size, num_heads, seq_len, head_size]
"""
new_x_shape = input_x.shape[:-1] + (self.num_attention_heads, self.attention_head_size)
input_x = input_x.view(*new_x_shape)
return input_x.transpose(0, 2, 1, 3)
def construct(self, hidden_states, attention_mask=None, head_mask=None):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
attention_scores = self.matmul(query_layer, key_layer.swapaxes(-1, -2))
attention_scores = attention_scores / ops.sqrt(Tensor(self.attention_head_size, mstype.float32))
if attention_mask is not None:
attention_scores = attention_scores + attention_mask
attention_probs = self.softmax(attention_scores)
attention_probs = self.dropout(attention_probs)
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = self.matmul(attention_probs, value_layer)
context_layer = context_layer.transpose(0, 2, 1, 3)
new_context_layer_shape = context_layer.shape[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
return outputs
BERT self-attention 输出层
- BERTSelfOutput:residual connection + layer normalization
- BERTAttention: self-attention + add&norm
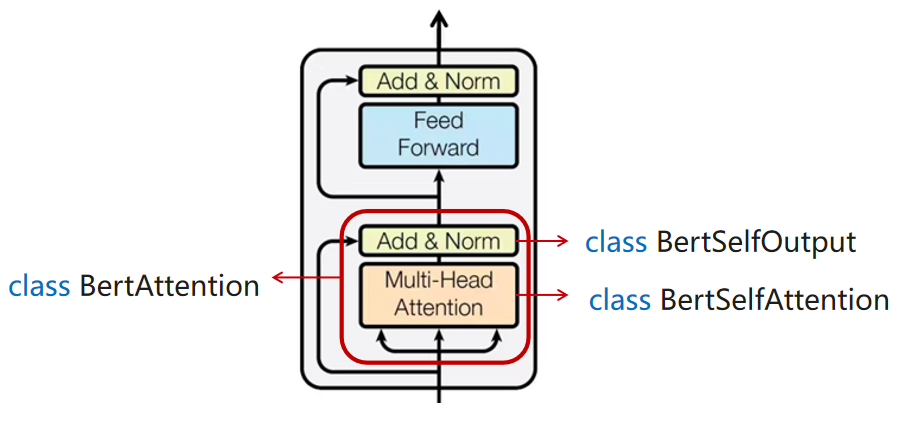
class BertSelfOutput(nn.Cell):
r"""
Bert Self Output
self-attention output + residual connection + layer norm
"""
def __init__(self, config):
super().__init__()
self.dense = nn.Dense(config.hidden_size, config.hidden_size, \
weight_init=TruncatedNormal(config.initializer_range))
self.layer_norm = nn.LayerNorm((config.hidden_size,), epsilon=1e-12)
self.dropout = Dropout(config.hidden_dropout_prob)
def construct(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.layer_norm(hidden_states + input_tensor)
return hidden_states
BERT feed-forward 层
class BertIntermediate(nn.Cell):
r"""
Bert Intermediate
"""
def __init__(self, config):
super().__init__()
self.dense = nn.Dense(config.hidden_size, config.intermediate_size, \
weight_init=TruncatedNormal(config.initializer_range))
self.intermediate_act_fn = ACT2FN[config.hidden_act]
def construct(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
BERT 最后的Add&Norm
class BertOutput(nn.Cell):
r"""
Bert Output
"""
def __init__(self, config):
super().__init__()
self.dense = nn.Dense(config.intermediate_size, config.hidden_size, \
weight_init=TruncatedNormal(config.initializer_range))
self.layer_norm = nn.LayerNorm((config.hidden_size,), epsilon=1e-12)
self.dropout = Dropout(config.hidden_dropout_prob)
def construct(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self. layer_norm(hidden_states + input_tensor)
return hidden_states
BERT Encoder
- BertLayer:Encoder Layer,集合了self-attention, feed-forward并通过add&norm连接
- BertEnocoder:通过Encoder Layer堆叠起来的Encoder结构

class BertLayer(nn.Cell):
r"""
Bert Layer
"""
def __init__(self, config):
super().__init__()
self.attention = BertAttention(config)
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def construct(self, hidden_states, attention_mask=None, head_mask=None):
attention_outputs = self.attention(hidden_states, attention_mask, head_mask)
attention_output = attention_outputs[0]
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
outputs = (layer_output,) + attention_outputs[1:]
return outputs
class BertEncoder(nn.Cell):
r"""
Bert Encoder
"""
def __init__(self, config):
super().__init__()
self.output_attentions = config.output_attentions
self.output_hidden_states = config.output_hidden_states
self.layer = nn.CellList([BertLayer(config) for _ in range(config.num_hidden_layers)])
def construct(self, hidden_states, attention_mask=None, head_mask=None):
all_hidden_states = ()
all_attentions = ()
for i, layer_module in enumerate(self.layer):
if self.output_hidden_states:
all_hidden_states += (hidden_states,)
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
hidden_states = layer_outputs[0]
if self.output_attentions:
all_attentions += (layer_outputs[1],)
if self.output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = (hidden_states,)
if self.output_hidden_states:
outputs += (all_hidden_states,)
if self.output_attentions:
outputs += (all_attentions,)
return outputs
BERT 输出
BERT会针对每一个位置输出大小为hidden size的向量,在下游任务中,会根据任务内容的不同,选取不同的向量放入输出层。
- 我们一般称
[CLS]经过线性层+激活函数tanh的输出为pooler output,用于句子级别的分类/回归任务; - 我们一般称BERT输出的每个位置对应的vector为sequence output,用于词语级别的分类任务;
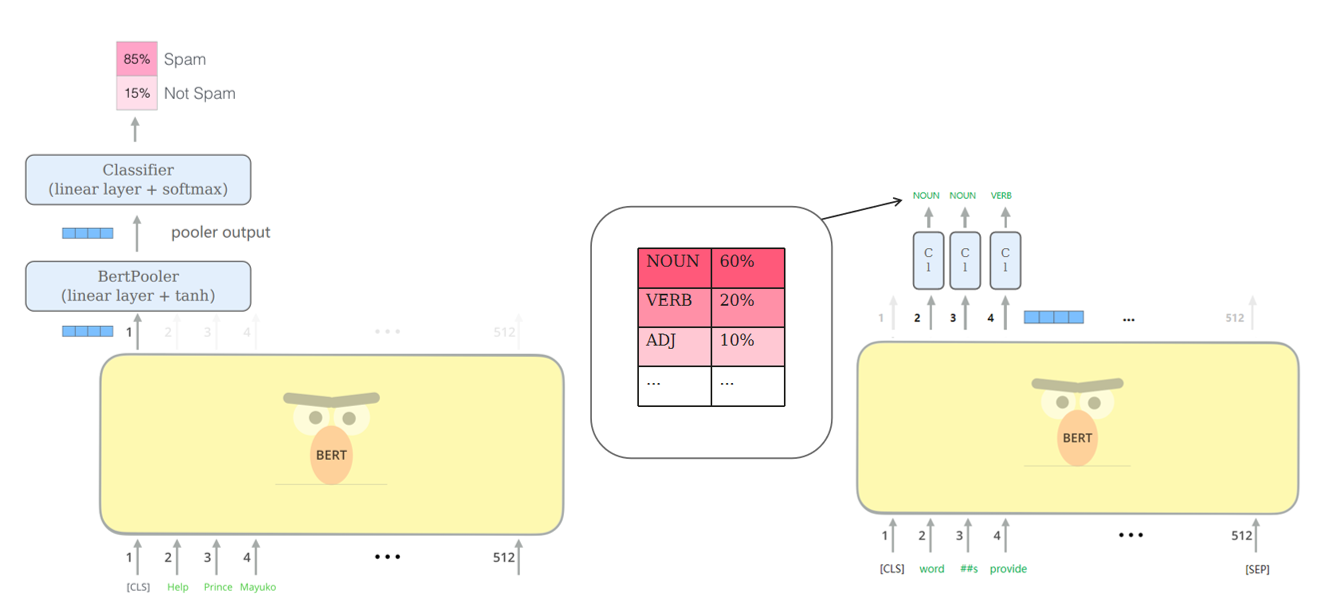
BERT Pooler
class BertPooler(nn.Cell):
r"""
Bert Pooler
"""
def __init__(self, config):
super().__init__()
self.dense = nn.Dense(config.hidden_size, config.hidden_size, \
activation='tanh', weight_init=TruncatedNormal(config.initializer_range))
def construct(self, hidden_states):
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
return pooled_output
BERT 预训练
BERT通过Masked LM(masked language model)与NSP(next sentence prediction)获取词语和句子级别的特征。

图片来源:Devlin, J.; Chang, M. W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
Masked LM
BERT模型通过Masked LM捕捉词语层面的信息。
我们随机将每个句子中15%的词语进行遮盖,替换成掩码<mask>。在训练过程中,模型会对句子进行“完形填空”,预测这些被遮盖的词语是什么,通过减小被mask词语的损失值来对模型进行优化。
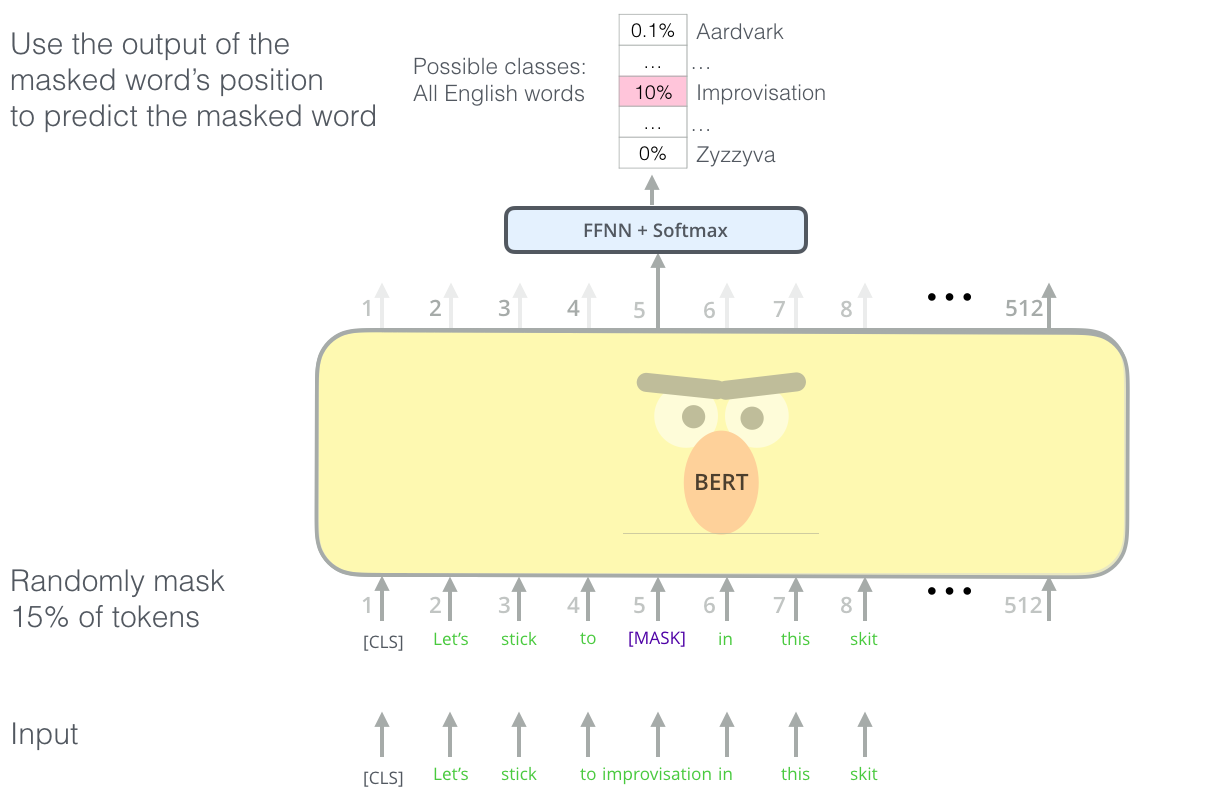
图片来源: The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
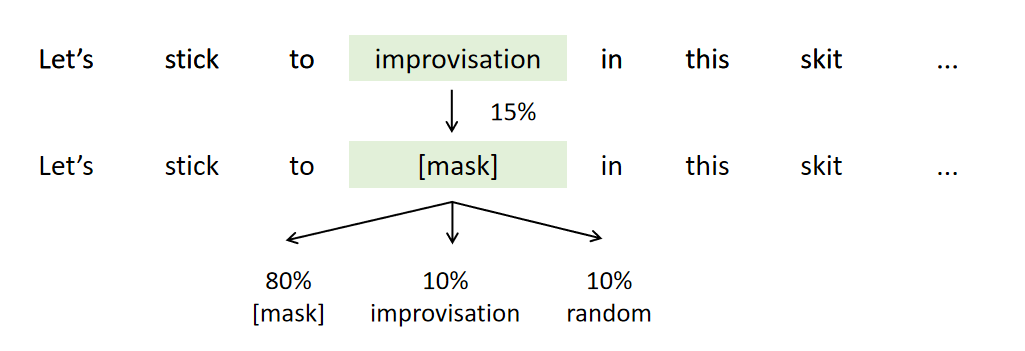
由于<mask>仅在预训练中出现,为了让预训练和微调中的数据处理尽可能接近,我们在随机mask的时候进行如下操作:
- 80%的概率替换为<mask>
- 10%的概率替换为文本中的随机词
- 10%的概率不进行替换,保持原有的词元
我们通过BERTPredictionHeadTranform实现单层感知机,对被遮盖的词元进行预测。在前向网络中,我们需要输入BERT模型的编码结果hidden_states。
activation_map = {
'relu': nn.ReLU(),
'gelu': nn.GELU(False),
'gelu_approximate': nn.GELU(),
'swish':nn.SiLU()
}
class BertPredictionHeadTransform(nn.Cell):
def __init__(self, config):
super().__init__()
self.dense = nn.Dense(config.hidden_size, config.hidden_size, weight_init=TruncatedNormal(config.initializer_range))
self.transform_act_fn = activation_map.get(config.hidden_act, nn.GELU(False))
self.layer_norm = nn.LayerNorm((config.hidden_size,), epsilon=config.layer_norm_eps)
def construct(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.layer_norm(hidden_states)
return hidden_states
根据被遮盖的词元位置masked_lm_positions,获得这些词元的预测输出。
import mindspore.ops as ops
import mindspore.numpy as mnp
from mindspore import Parameter, Tensor
class BertLMPredictionHead(nn.Cell):
def __init__(self, config):
super(BertLMPredictionHead, self).__init__()
self.transform = BertPredictionHeadTransform(config)
self.decoder = nn.Dense(config.hidden_size, config.vocab_size, has_bias=False, weight_init=TruncatedNormal(config.initializer_range))
self.bias = Parameter(initializer('zeros', config.vocab_size), 'bias')
def construct(self, hidden_states, masked_lm_positions):
batch_size, seq_len, hidden_size = hidden_states.shape
if masked_lm_positions is not None:
flat_offsets = mnp.arange(batch_size) * seq_len
flat_position = (masked_lm_positions + flat_offsets.reshape(-1, 1)).reshape(-1)
flat_sequence_tensor = hidden_states.reshape(-1, hidden_size)
hidden_states = ops.gather(flat_sequence_tensor, flat_position, 0)
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states) + self.bias
return hidden_states
NSP
BERT通过NSP捕捉句子级别的信息,使其可以理解句子与句子之间的联系,从而能够应用于问答或者推理任务。
NSP本质上是一个二分类任务,通过输入一个句子对,判断两句话是否为连续句子。输入的两个句子A和B中,B有50%的概率是A的下一句。

图片来源: The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
另外,输入的内容最好是document-level的语料,而非sentence-level的语料,这样训练出的模型可以具备抓取长序列特征的能力。
在这里,我们使用一个单隐藏层的多层感知机BERTPooler进行二分类预测。因为特殊占位符在预训练中对应了句子级别的特征信息,所以多层感知机分类器只需要输出对应的隐藏层输出。
class BertPooler(nn.Cell):
def __init__(self, config):
super(BertPooler, self).__init__()
self.dense = nn.Dense(config.hidden_size, config.hidden_size, activation='tanh', weight_init=TruncatedNormal(config.initializer_range))
def construct(self, hidden_states):
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
return pooled_output
最后,多层感知机分类器的输出通过一个线性层self.seq_relationship,输出对nsp的预测。
在BERTPreTrainingHeads中,我们对以上提到的两种方式进行整合。最终输出Maked LM(prediction scores)和NSP(seq_realtionship_score)的预测结果。
class BertPreTrainingHeads(nn.Cell):
def __init__(self, config):
super(BertPreTrainingHeads, self).__init__()
self.predictions = BertLMPredictionHead(config)
self.seq_relationship = nn.Dense(config.hidden_size, 2, weight_init=TruncatedNormal(config.initializer_range))
def construct(self, sequence_output, pooled_output, masked_lm_positions):
prediction_scores = self.predictions(sequence_output, masked_lm_positions)
seq_relationship_score = self.seq_relationship(pooled_output)
return prediction_scores, seq_relationship_score
BERT预训练代码整合
我们将上述的类进行实例化,并借此回顾一下BERT预训练的整体流程。
BertModel构建BERT模型;BertPretrainingHeads整合了Masked LM与NSP两个训练任务, 输出预测结果;BertLMPredictionHead:输入BERT编码与<mask>的位置,输出对应位置词元的预测;BERTPooler:输入BERT编码,输出对<cls>的隐藏状态,并在BertPretrainingHeads中通过线性层输出预测结果;
class BertForPretraining(nn.Cell):
def __init__(self, config, *args, **kwargs):
super().__init__(config, *args, **kwargs)
self.bert = BertModel(config)
self.cls = BertPreTrainingHeads(config)
self.vocab_size = config.vocab_size
self.cls.predictions.decoder.weight = self.bert.embeddings.word_embeddings.embedding_table
def construct(self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, masked_lm_positions=None):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask
)
sequence_output, pooled_output = outputs[:2]
prediction_scores, seq_relationship_score = self.cls(sequence_output, pooled_output, masked_lm_positions)
outputs = (prediction_scores, seq_relationship_score,) + outputs[2:]
return outputs
课程ppt及代码地址
-
github地址(网络不好的可以访问下面我克隆到gitee上的地址):BERT
-
gitee地址:BERT
2、学习心得:
通过本次学习,熟悉了Mindspore这个国产深度学习框架,也对BERT的基本技术原理有所了解,最重要的是能够通过BERT完成一个简单的情感分类的任务,这让我十分有成就感!!!另外除了bert相关的技术原理,峰哥还拓展了混合精度训练原理,分布式并行原理,真的非常不错!
3、经验分享:
在启智openI上的npu跑时记得使用mindspore1.7的镜像,同时安装对应mindnlp的版本,不然可能会因为版本不兼容而报错。
4、课程反馈:
本次课程中的代码串讲我觉得是做的最好的地方,没有照着ppt一直念,而是在jupyter上把代码和原理结合到一块进行讲解,让学习者对代码的理解更加深入。我觉得内容的最后可以稍微推荐一下与Mindspore大模型相关的套件,让学习者在相关套件上可以开发出更多好玩和有趣的东西!
5、使用MindSpore昇思的体验和反馈:
MindSpore昇思的优点和喜欢的方面:
- 灵活性和可扩展性: MindSpore提供了灵活的编程模型,支持静态计算图和动态计算图。这种设计使得它适用于多种类型的机器学习和深度学习任务,并且具有一定的可扩展性。
- 跨平台支持: MindSpore支持多种硬件平台,包括CPU、GPU和NPU等,这使得它具有在不同设备上运行的能力,并能充分利用各种硬件加速。
- 自动并行和分布式训练: MindSpore提供了自动并行和分布式训练的功能,使得用户可以更轻松地处理大规模数据和模型,并更高效地进行训练。
- 生态系统和社区支持: MindSpore致力于建立开放的生态系统,并鼓励社区贡献,这对于一个开源框架来说非常重要,能够帮助用户更好地学习和解决问题。
一些建议和改进方面:
- 文档和教程的改进: 文档和教程并不是很详细,希望能够提供更多实用的示例、详细的文档和教程,以帮助用户更快速地上手和解决问题。
- 更多的应用场景示例: 提供更多真实场景的示例代码和应用案例,可以帮助用户更好地了解如何在实际项目中应用MindSpore。
6、未来展望:
大模型的内容还是很多的,希望自己能坚持打卡,将后面的内容都学习完,并做出一些有趣好玩的东西来!