文章目录
- 两种灵活的使用场景
- 项目结构概览
- 简化的使用方式
- 项目结构解读
- 1. 代码的入口和训练的准备工作
- 2. data和model的创建
- 2.1 dataloader创建
- 2.2 model的创建
- 3. 训练过程
- 动态实例化的历史演进
- 1. If-else判断
- 2. 动态实例化
- 3. REGISTER注册机制
- REGISTER注册机制的实现
- 1. DATASET_REGISTRY
- 2. ARCH_REGISTRY
- 3. MODEL_REGISTRY
- 4. LOSS_REGISTRY
- 5. METRIC_REGISTRY
- 简化开发流程
- 训练codeformer过程的一个小记录
两种灵活的使用场景
BasicSR支持两种灵活的使用场景,以满足用户不同的需求:
-
本地克隆仓库使用: 用户可以直接克隆BasicSR的本地仓库,查看完整的代码并进行修改,例如在BasicSR中训练SRGAN或StyleGAN2。安装方式包括先执行
git clone,然后运行python setup.py develop/install。详细信息请参考安装指南。修改源码就即时生效,我推荐这个方式。 -
作为Python包使用: 用户可以通过pip安装BasicSR作为一个额外的Python包(basicsr)。这样可以方便地利用其提供的训练框架、流程和基本功能,更容易地构建自己的项目。例如,Real-ESRGAN和GFPGAN就是基于basicsr搭建的。安装方式为
pip install basicsr。
项目结构概览
在深度学习项目中,通常可以分为data、arch(网络结构和forward步骤)、model和training pipeline(训练流程)几个部分。BasicSR旨在简化这些共用的功能,使开发者能够更专注于主要功能的开发而不必重复造轮子。
简化的使用方式
BasicSR提供了basicsr package,通过pip install basicsr安装后,可以方便地使用BasicSR的训练流程和已经开发好的功能。
项目结构解读
1. 代码的入口和训练的准备工作
用户可以通过运行命令python basicsr/train.py -opt options/train/SRResNet_SRGAN/train_MSRResNet_x4.yml开始训练,其中-opt参数指定配置文件的路径。这个命令会调用train_pipeline函数作为训练的入口。
在train_pipeline函数中,会完成一系列基础工作,包括解析配置文件、设置分布式训练选项、创建相关文件夹、初始化日志系统等。
2. data和model的创建
2.1 dataloader创建
数据加载器(dataloader)的创建通过create_train_val_dataloader函数实现,其中包括build_dataset和build_dataloader两个主要函数。build_dataset根据配置文件中的dataset类型创建相应的实例,而build_dataloader则根据传入的dataset和其他参数构建数据加载器。
2.2 model的创建
模型的创建通过build_model函数完成,根据配置文件中的model类型创建相应的实例。在BasicSR框架中,主要有几个类型,如network architecture和loss,都是通过REGISTRY机制实例化的。
3. 训练过程
训练过程是一个循环过程,通过不断喂数据和执行训练步骤来完成。具体的训练过程包括网络的前向传播、损失计算、反向传播和优化器的更新。
动态实例化的历史演进
在网络结构的开发过程中,经历了三个阶段的发展:If-else判断、动态实例化、REGISTER注册机制。
1. If-else判断
最初的方法是通过if-else判断实现动态实例化。在这种方式中,根据配置文件中的参数进行判断,选择实例化哪个网络结构。虽然这种方式能够实现目的,但频繁开发网络结构时会显得繁琐。
2. 动态实例化
为了简化动态实例化的过程,BasicSR引入了动态实例化的方法。使用getattr函数,根据配置文件中指定的Class name,实现了网络结构的自动实例化。这一方法在一定程度上提高了开发效率,但还存在一些问题,如需要手动import网络结构的module。
3. REGISTER注册机制
为解决上述问题,BasicSR引入了REGISTER注册机制,借鉴了fvcore仓库的Registry类。这一机制通过注册机制实现了网络结构的自动化实例化,避免了手动import的问题。注册时进行强制检查,防止同名类的出现,同时减少了冗余的import。
REGISTER注册机制的实现
在REGISTER注册机制中,BasicSR定义了五个REGISTER,分别用于DATASET、ARCH、MODEL、LOSS、METRIC。注册时通过python装饰器,在类或函数前添加注册语句,实现注册。
1. DATASET_REGISTRY
DATASET_REGISTRY用于注册数据集相关的类,约定以_dataset.py结尾。
2. ARCH_REGISTRY
ARCH_REGISTRY用于注册网络结构相关的类,约定以_arch.py结尾。通过约定的文件名和自动扫描import,实现网络结构的自动注册。
3. MODEL_REGISTRY
MODEL_REGISTRY用于注册模型相关的类,约定以_model.py结尾。
4. LOSS_REGISTRY
LOSS_REGISTRY用于注册损失函数相关的类,约定以_loss.py结尾。
5. METRIC_REGISTRY
METRIC_REGISTRY用于注册评估指标相关的函数,约定在__init__.py文件中进行import。
简化开发流程
如今,在BasicSR的新版本中,开发者在新开发网络结构时只需进行两个步骤:写具体的网络结构文件和修改配置文件。其余的工作交由BasicSR的动态实例化和REGISTER注册机制来完成。这一机制的引入使得开发者能够更专注于网络结构的改进,同时提高了项目的整体开发效率。
REGISTER注册机制为BasicSR注入了更为灵活和自动化的元素,为深度学习项目的构建提供了更加便捷的途径。如果你对该机制感兴趣,可以前往BasicSR GitHub仓库查看更多信息。
训练codeformer过程的一个小记录
codeformer使用了BasicSR后端。
启动单机多卡分布式训练:
CUDA_VISIBLE_DEVICES=0,2,3 python -m torch.distributed.launch --nproc_per_node=3 --master_port=4322 basicsr/train.py -opt options/CodeFormer_stage2.yml --launcher pytorch
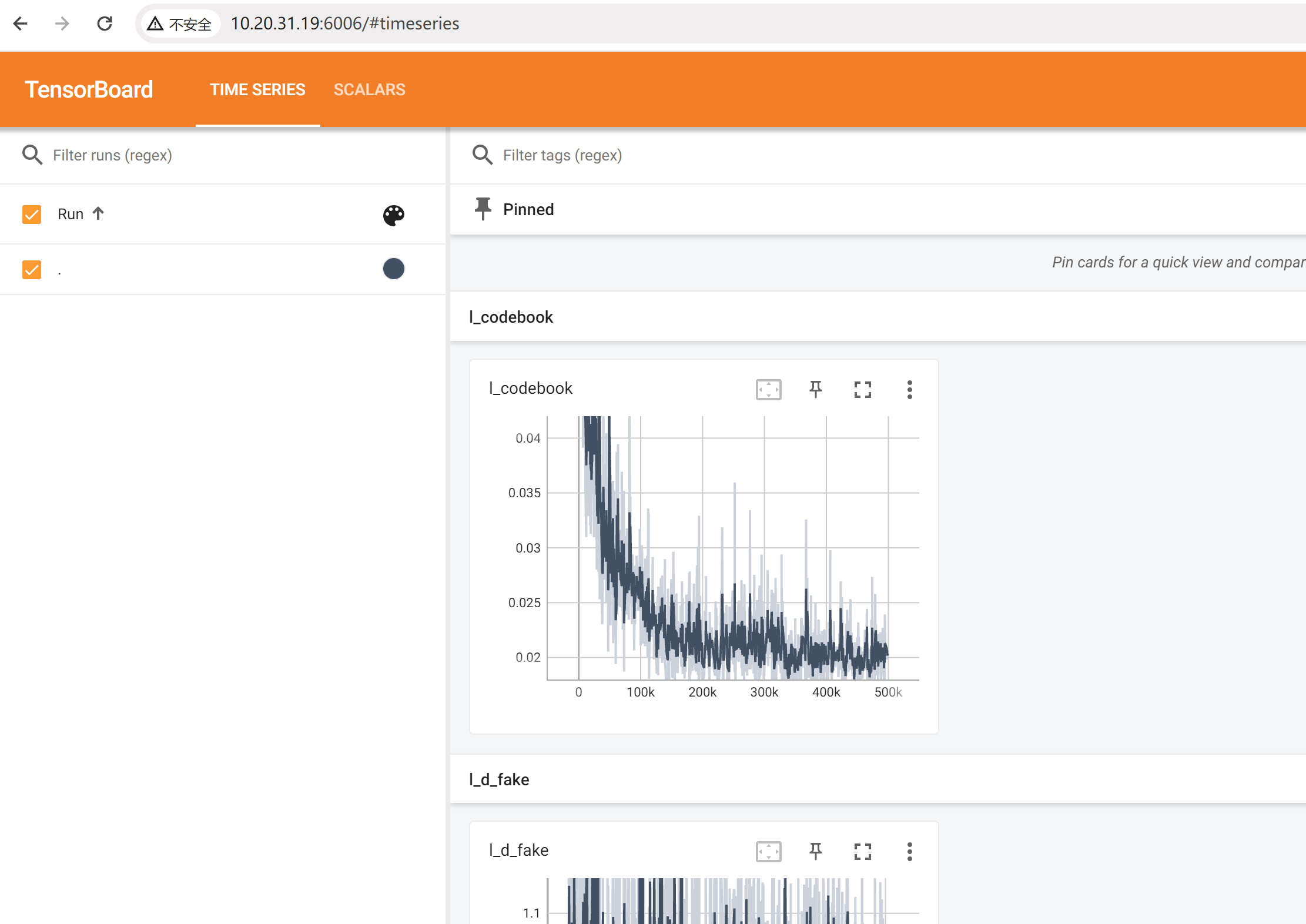
日志文件查看:
tensorboard --logdir="/ssd/xiedong/CodeFormer/tb_logger/20240116_182107_VQGAN-512-ds32-nearest-stage1" --bind_all
参考:https://zhuanlan.zhihu.com/p/409675896