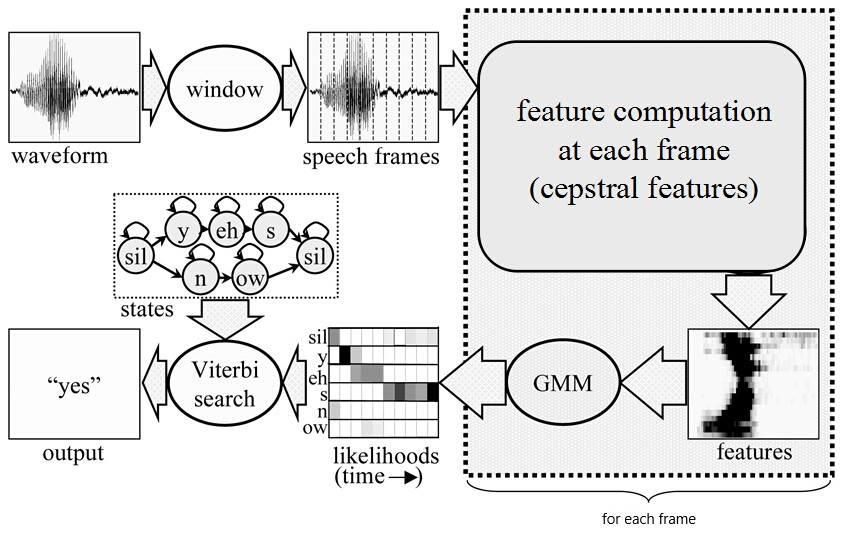
自媒体文章上下架

使用消息队列在自媒体下架时通知文章微服务。
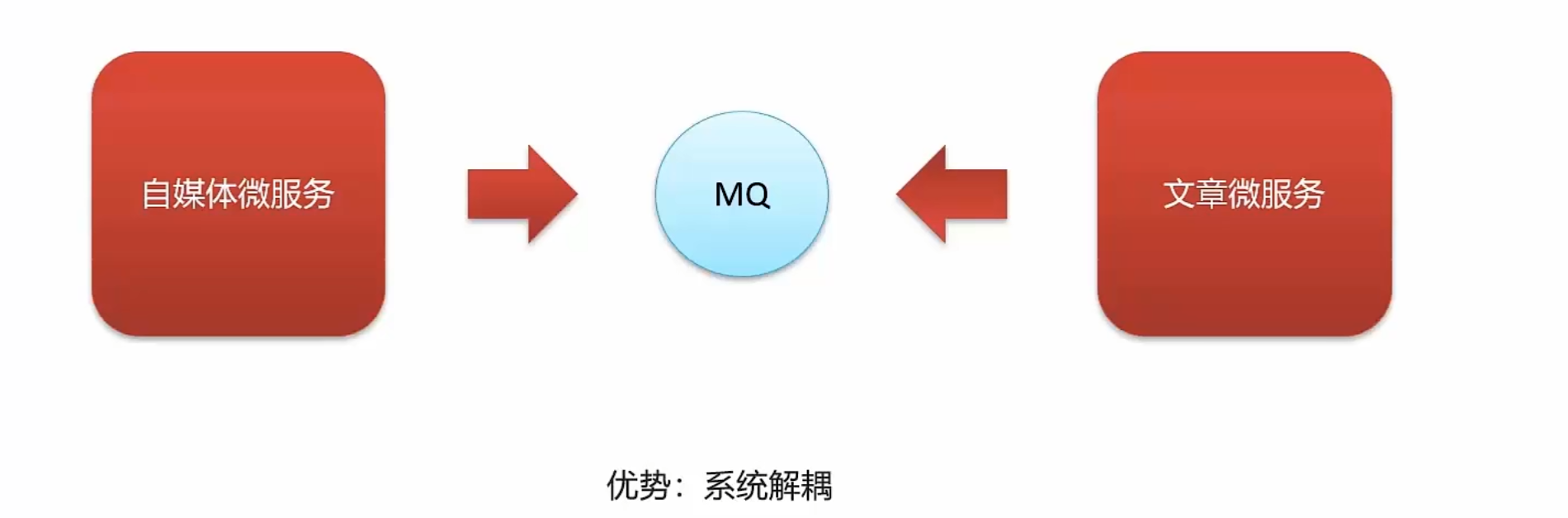
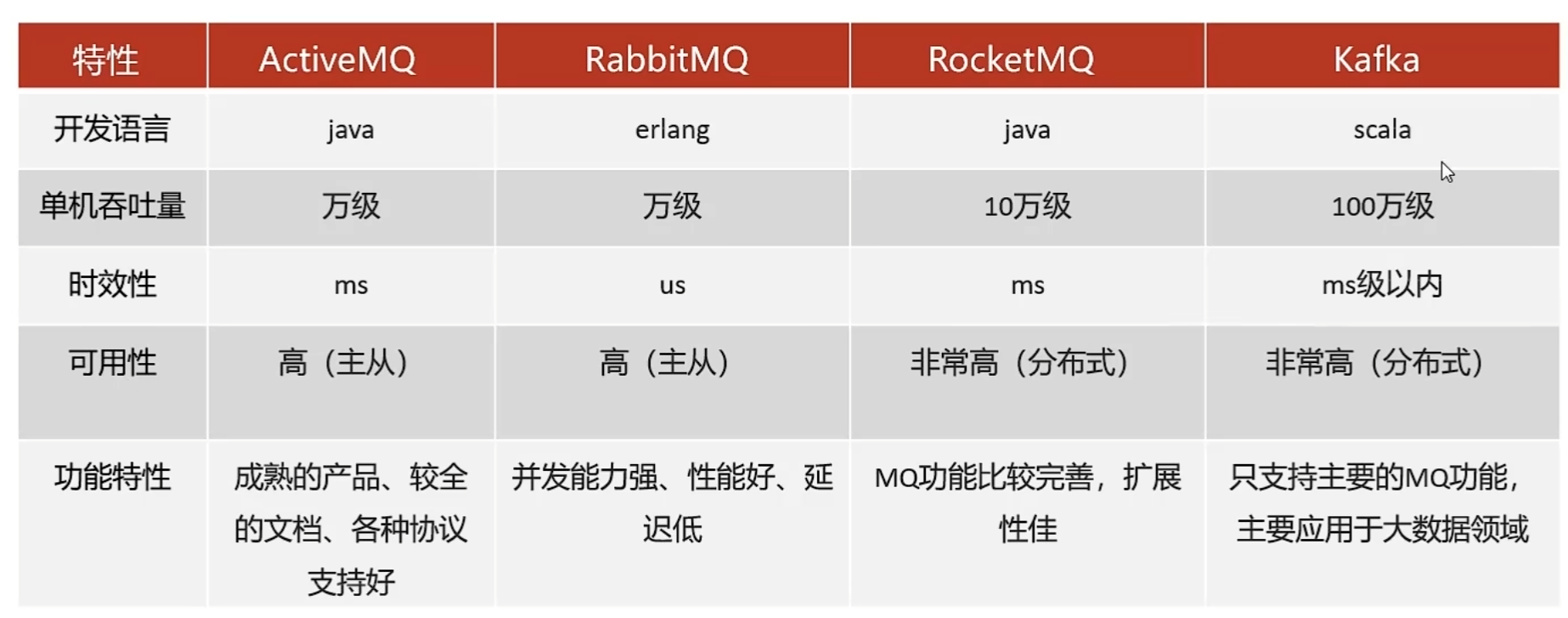
kafka概述


kafka环境搭建

docker pull zookeeper:3.4.14docker run -d --name zookeeper -p 2181:2181 zookeeper:3.4.14安装kafka

docker pull wurstmeister/kafka:2.12-2.3.1docker run -d --name kafka \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.200.130 \
--env KAFKA_ZOOKEEPER_CONNECT=192.168.200.130:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.200.130:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \
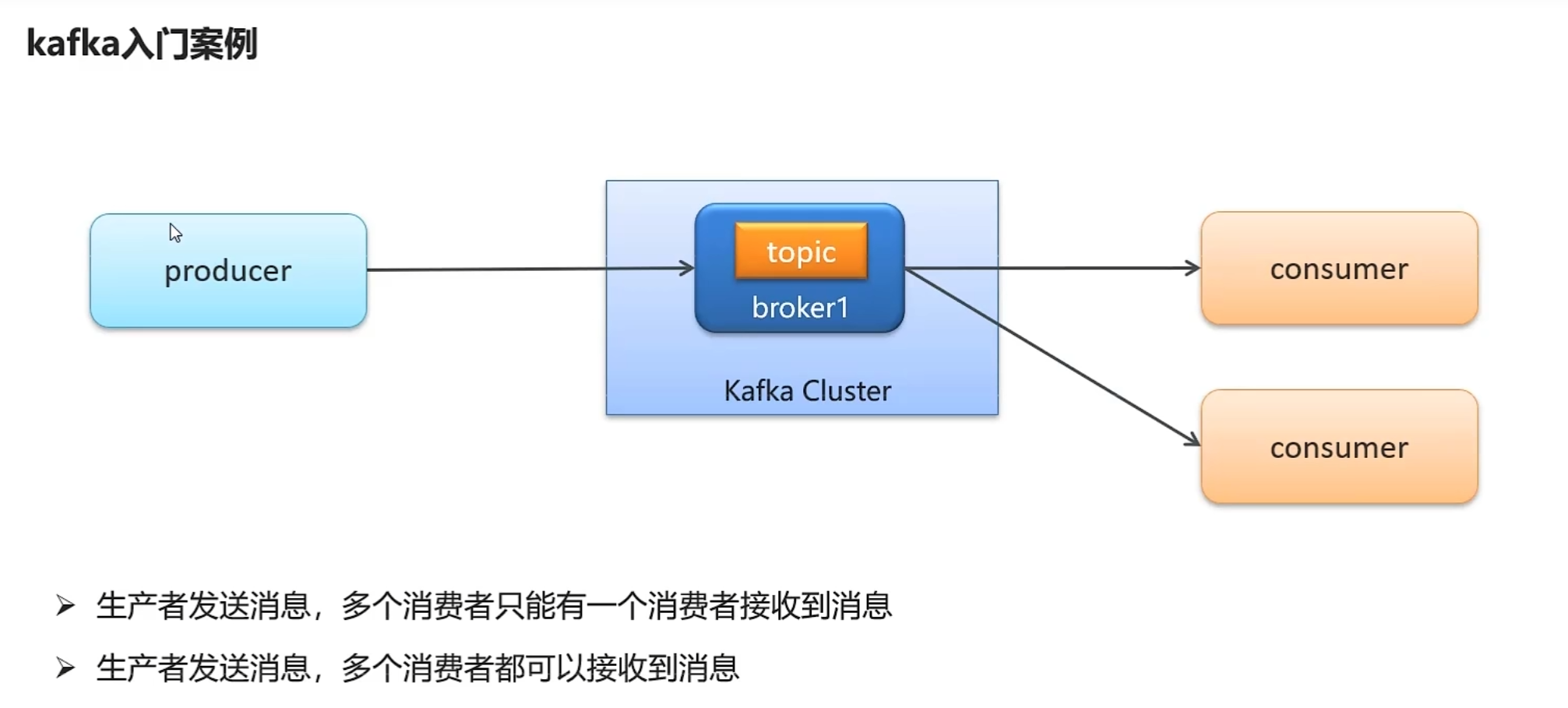
--net=host wurstmeister/kafka:2.12-2.3.1kafka入门案例
依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
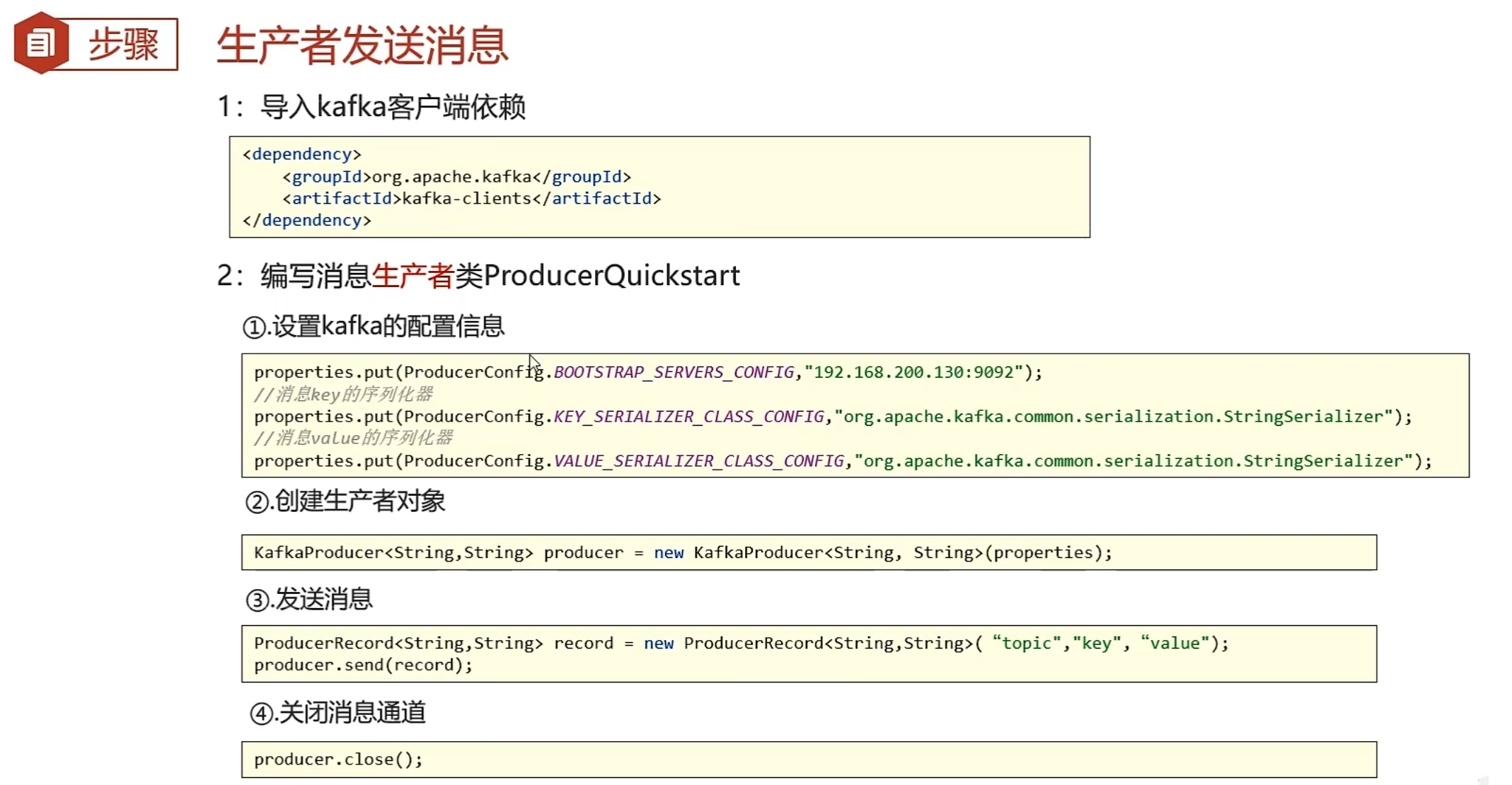
</dependency>生产者类
package com.heima.kafka.sample;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 生产者
*/
public class ProducerQuickStart {
public static void main(String[] args) {
//1.kafka的配置信息
Properties properties = new Properties();
//kafka的连接地址
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");
//发送失败,失败的重试次数
properties.put(ProducerConfig.RETRIES_CONFIG,5);
//消息key的序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//消息value的序列化器
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//2.生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
//封装发送的消息
ProducerRecord<String,String> record = new ProducerRecord<String, String>("itheima-topic","100001","hello kafka");
//3.发送消息
producer.send(record);
//4.关闭消息通道,必须关闭,否则消息发送不成功
producer.close();
}
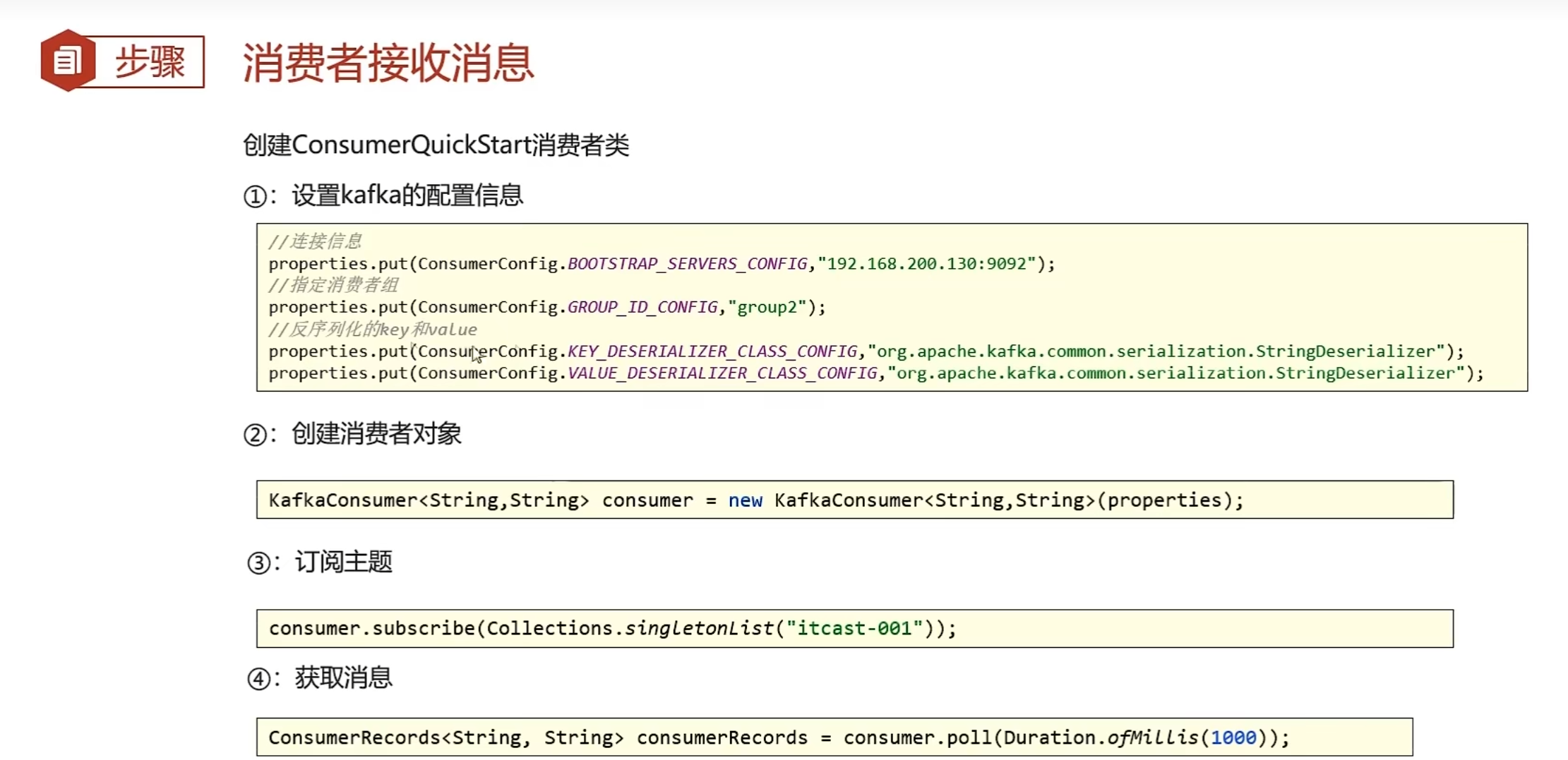
}消费者类
package com.heima.kafka.sample;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 消费者
*/
public class ConsumerQuickStart {
public static void main(String[] args) {
//1.添加kafka的配置信息
Properties properties = new Properties();
//kafka的连接地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");
//消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group2");
//消息的反序列化器
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
//2.消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
//3.订阅主题
consumer.subscribe(Collections.singletonList("itheima-topic"));
//当前线程一直处于监听状态
while (true) {
//4.获取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key());
System.out.println(consumerRecord.value());
}
}
}
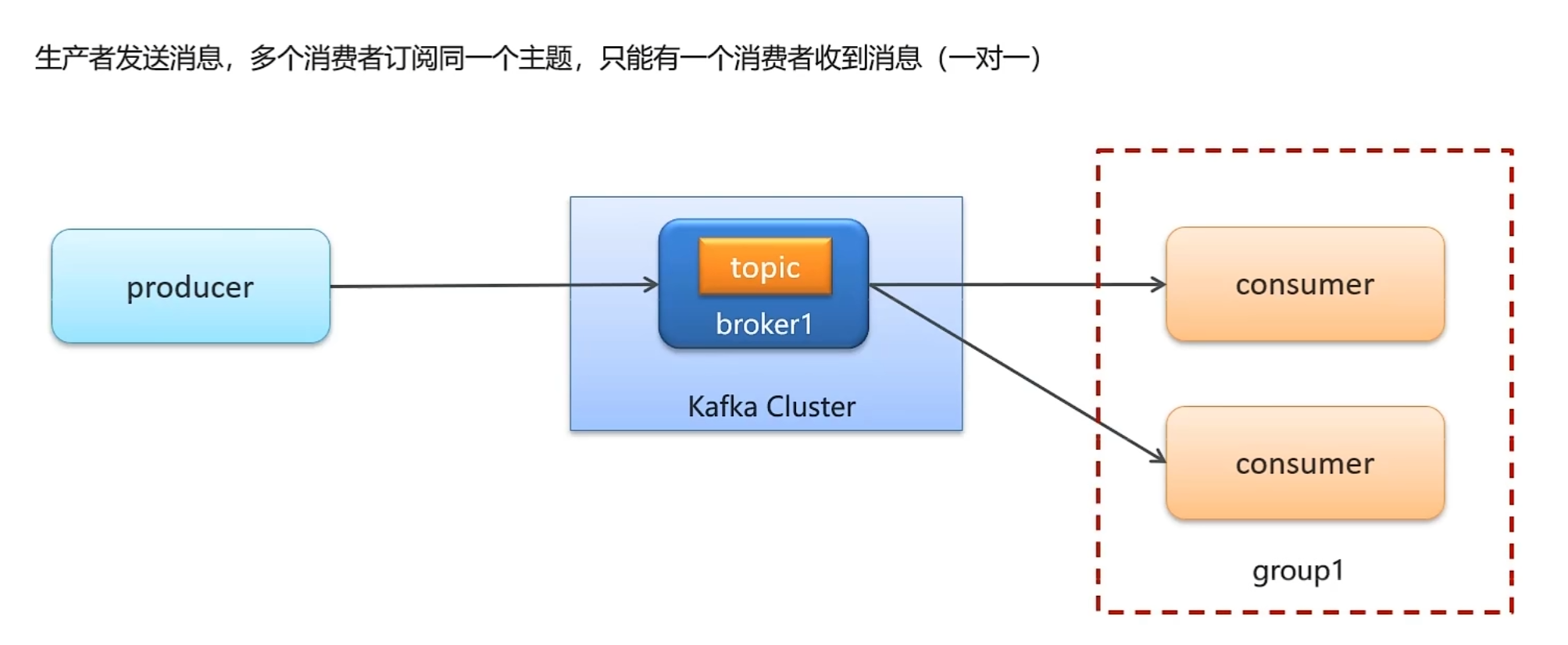
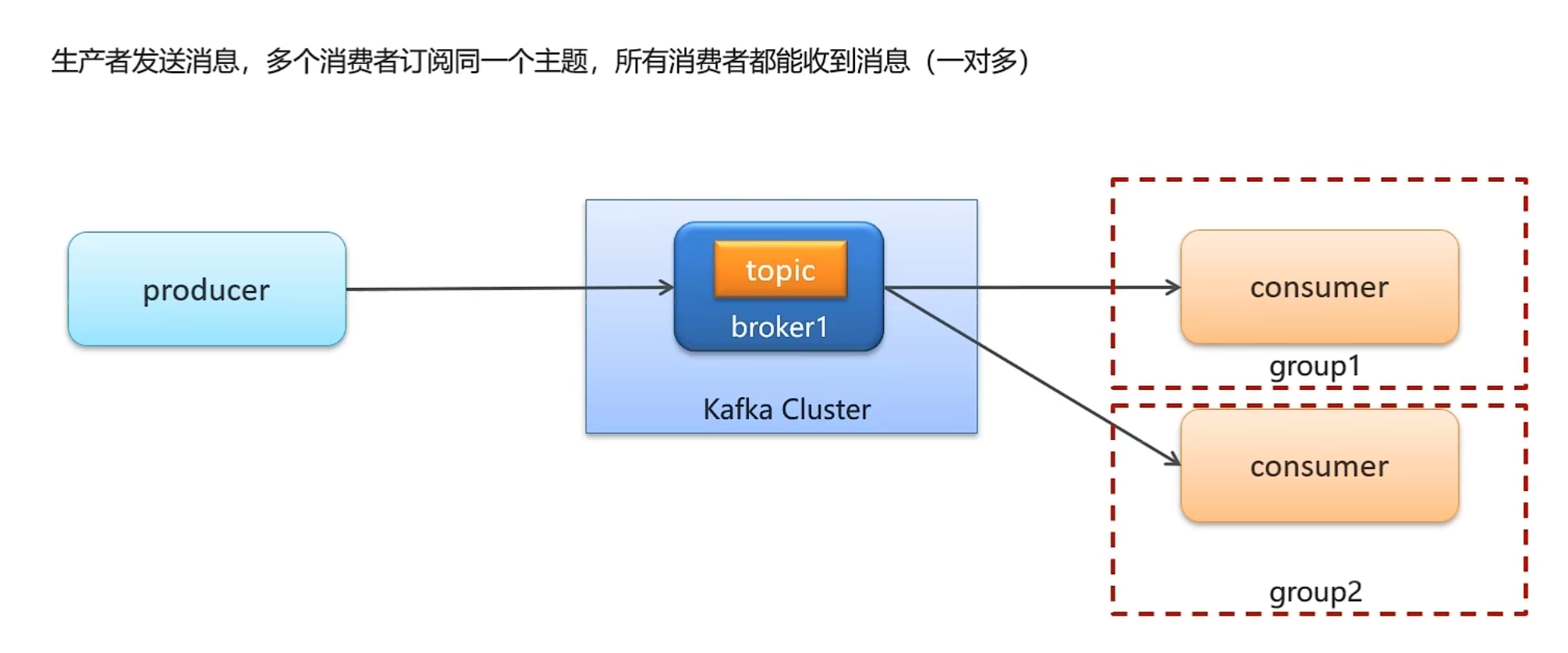
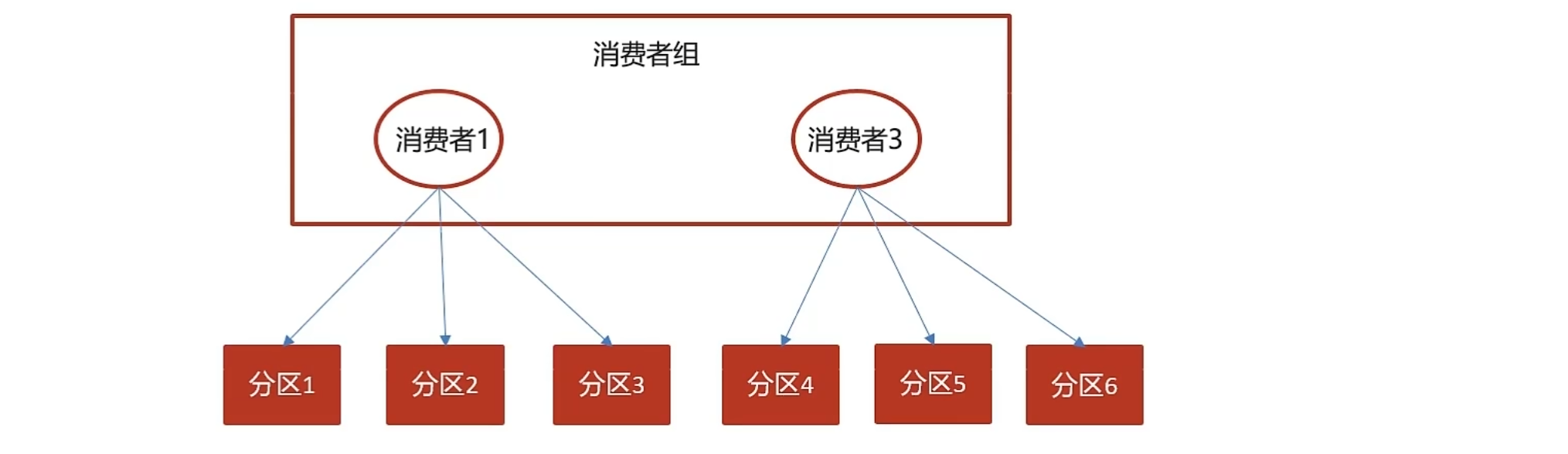
}存在一个消费者组和多个消费者组的区别
 分区机制
分区机制
相当于数据分片?redis也有这个机制。



高可用设计方案
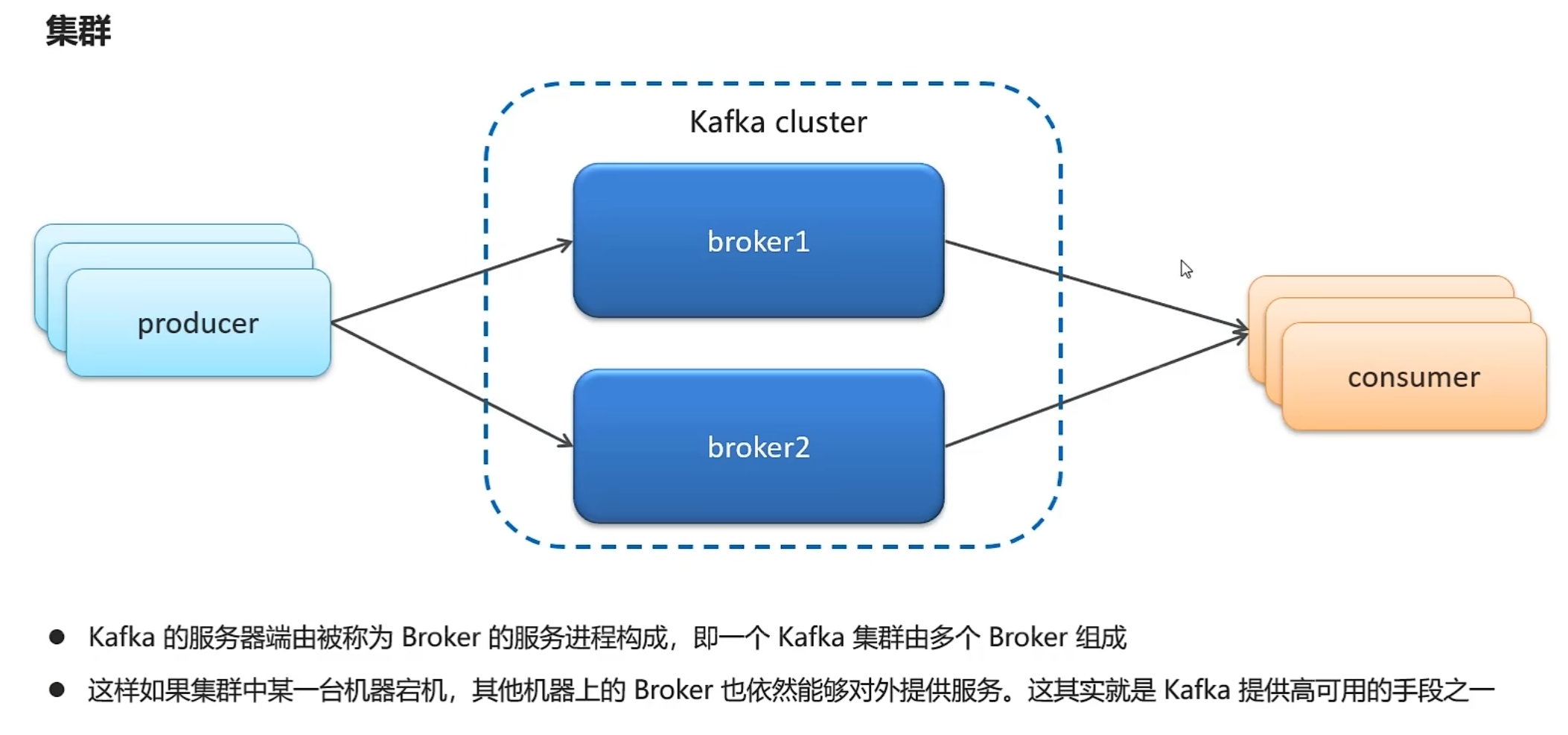

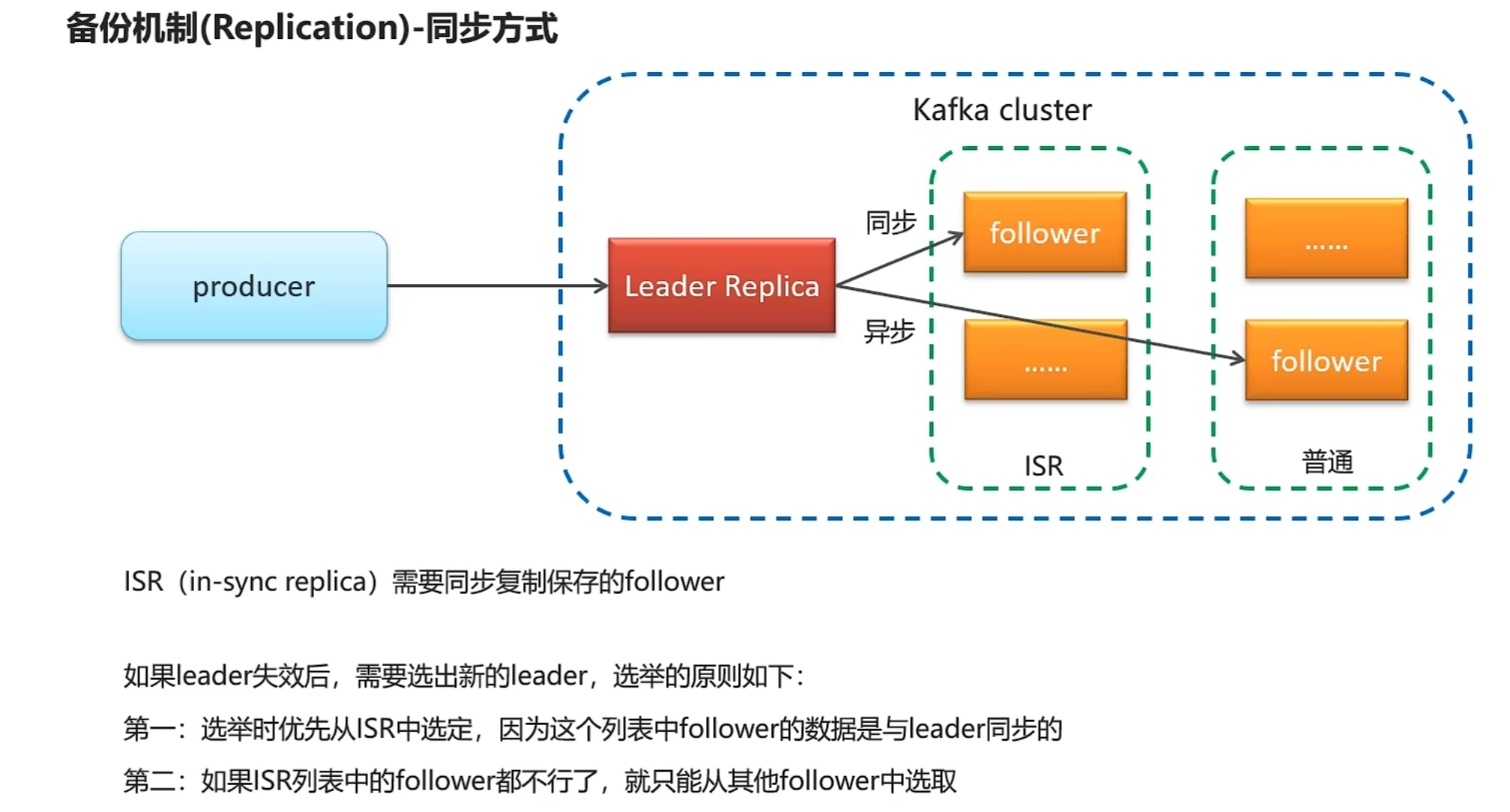

kafka生产者详解
发送类型


参数详解
acks=0和UDP很像

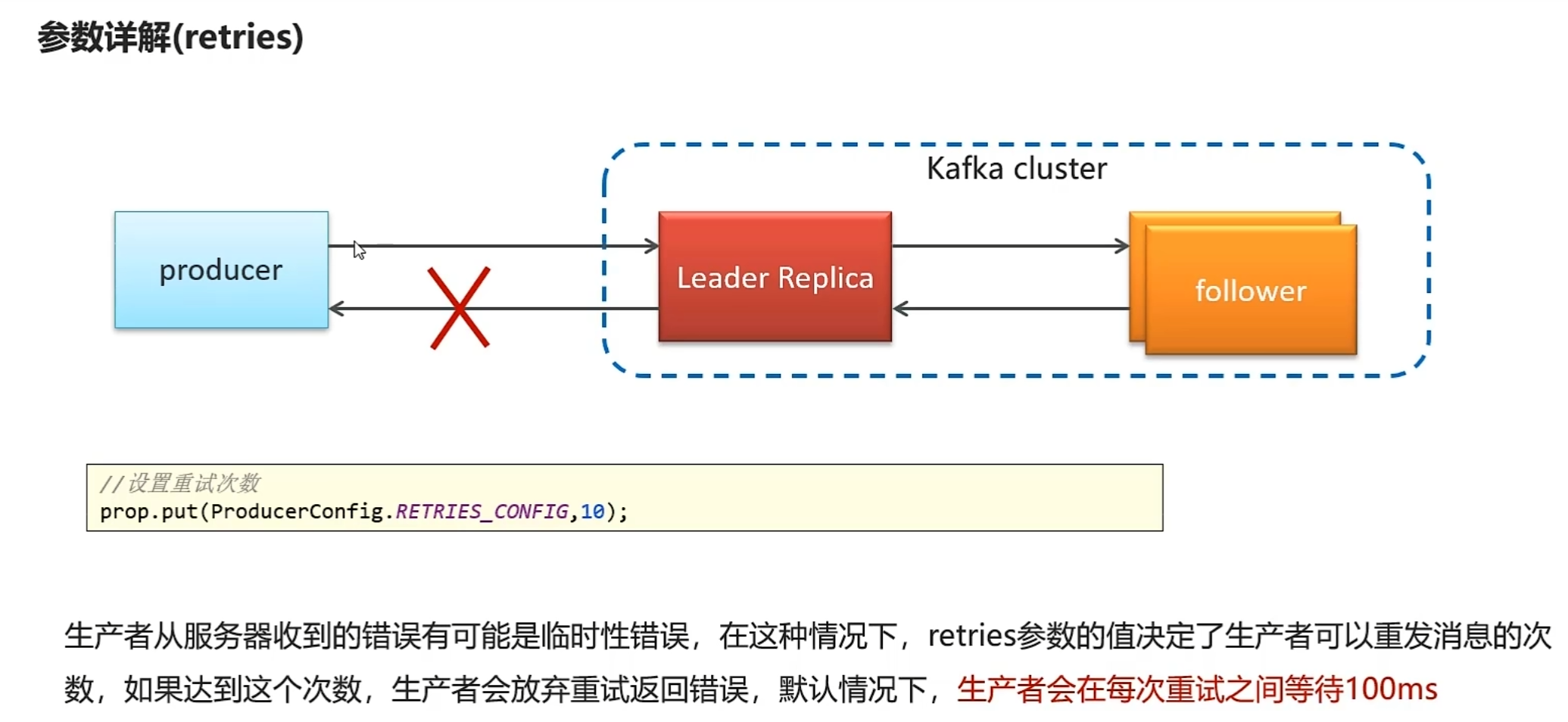

kafka消费者详解

 多个分区无法保证消息的有序性,相当于,a先后发了两条消息给b,两条消息进了不同的分区,结果因为网络原因导致b先接收到了第二条消息。
多个分区无法保证消息的有序性,相当于,a先后发了两条消息给b,两条消息进了不同的分区,结果因为网络原因导致b先接收到了第二条消息。
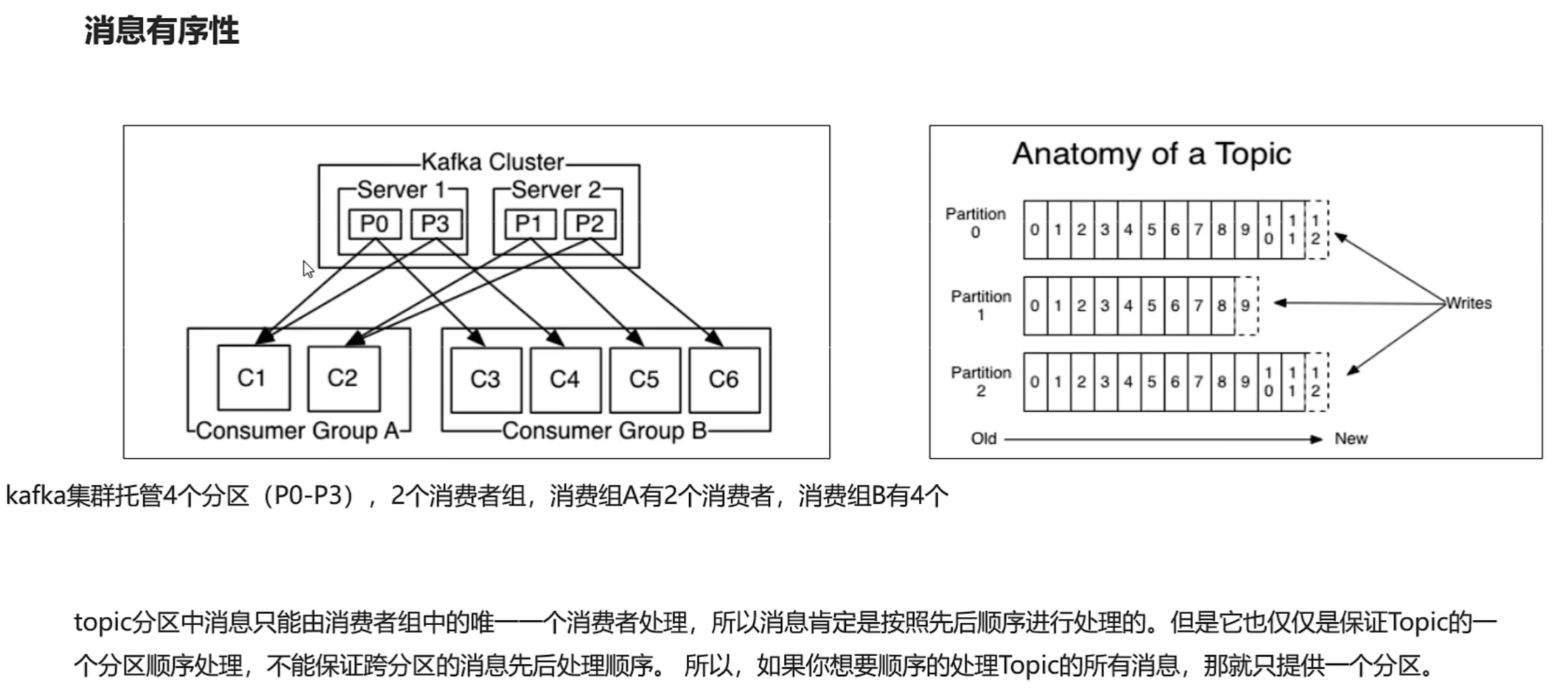
提交和偏移量

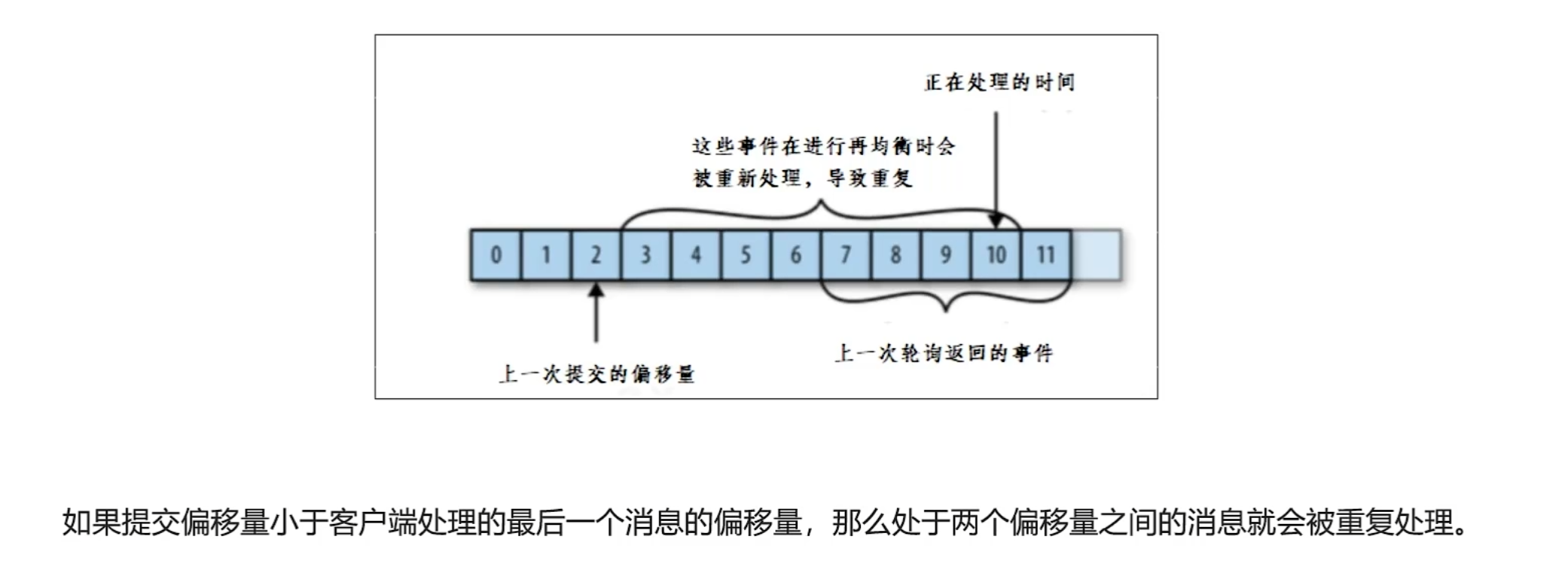
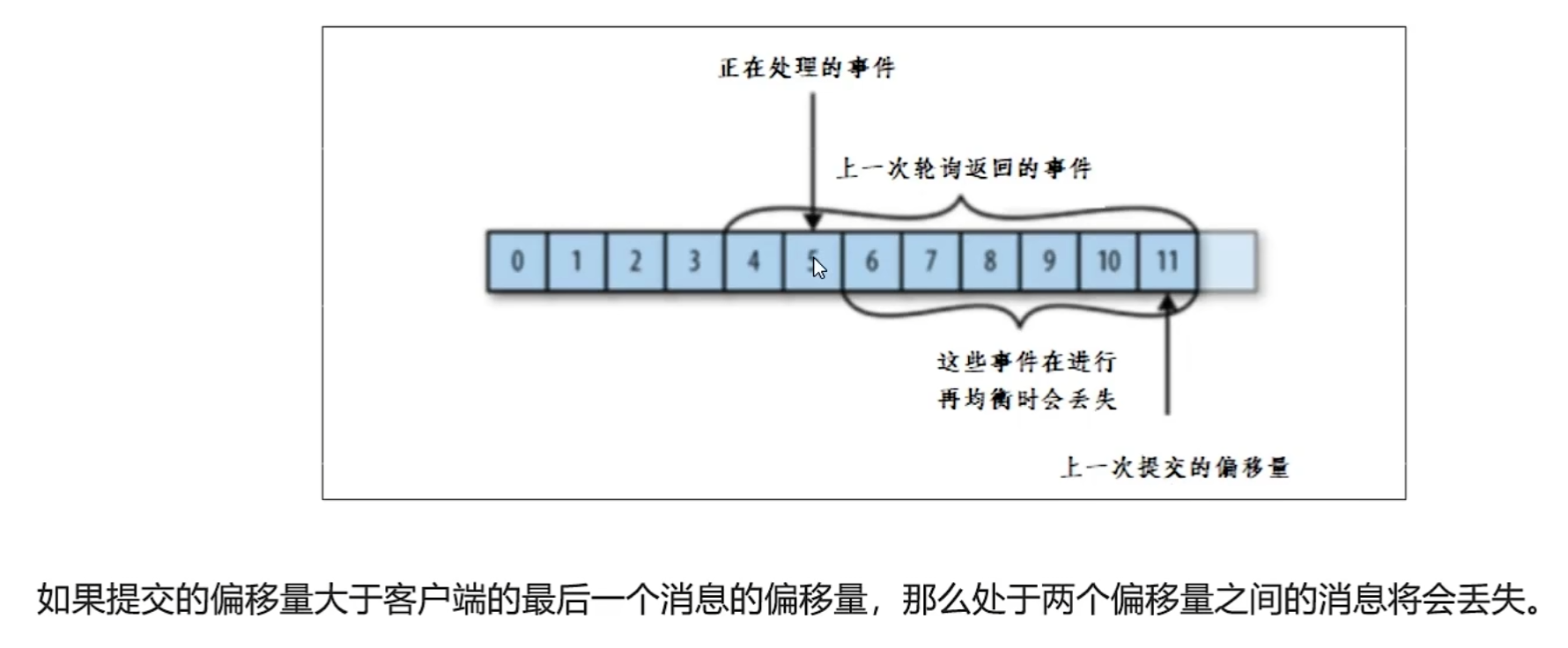
这里因为不是每次消费都提交就会出现丢失和重复的问题。
偏移量提交方式




SpringBoot集成kafka收发消息
1.导入spring-kafka依赖信息
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- kafkfa -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</dependency>
</dependencies>2.在resources下创建文件application.yml
server:
port: 9991
spring:
application:
name: kafka-demo
kafka:
bootstrap-servers: 192.168.200.130:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: ${spring.application.name}-test
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer3.消息生产者
package com.heima.kafka.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
@GetMapping("/hello")
public String hello(){
kafkaTemplate.send("itcast-topic","黑马程序员");
return "ok";
}
}4.消息消费者
package com.heima.kafka.listener;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
@Component
public class HelloListener {
@KafkaListener(topics = "itcast-topic")
public void onMessage(String message){
if(!StringUtils.isEmpty(message)){
System.out.println(message);
}
}
}传递消息为对象时

发送
@GetMapping("/hello")
public String hello(){
User user = new User();
user.setUsername("xiaowang");
user.setAge(18);
kafkaTemplate.send("user-topic", JSON.toJSONString(user));
return "ok";
}接受
@Component
public class HelloListener {
@KafkaListener(topics = "user-topic")
public void onMessage(String message){
if(!StringUtils.isEmpty(message)){
User user = JSON.parseObject(message, User.class);
System.out.println(user);
}
}
}自媒体文章上下架功能实现

-
已发表且已上架的文章可以下架
-
已发表且已下架的文章可以上架
流程说明

文章表存在一个属性字段是否上架
功能接口开发
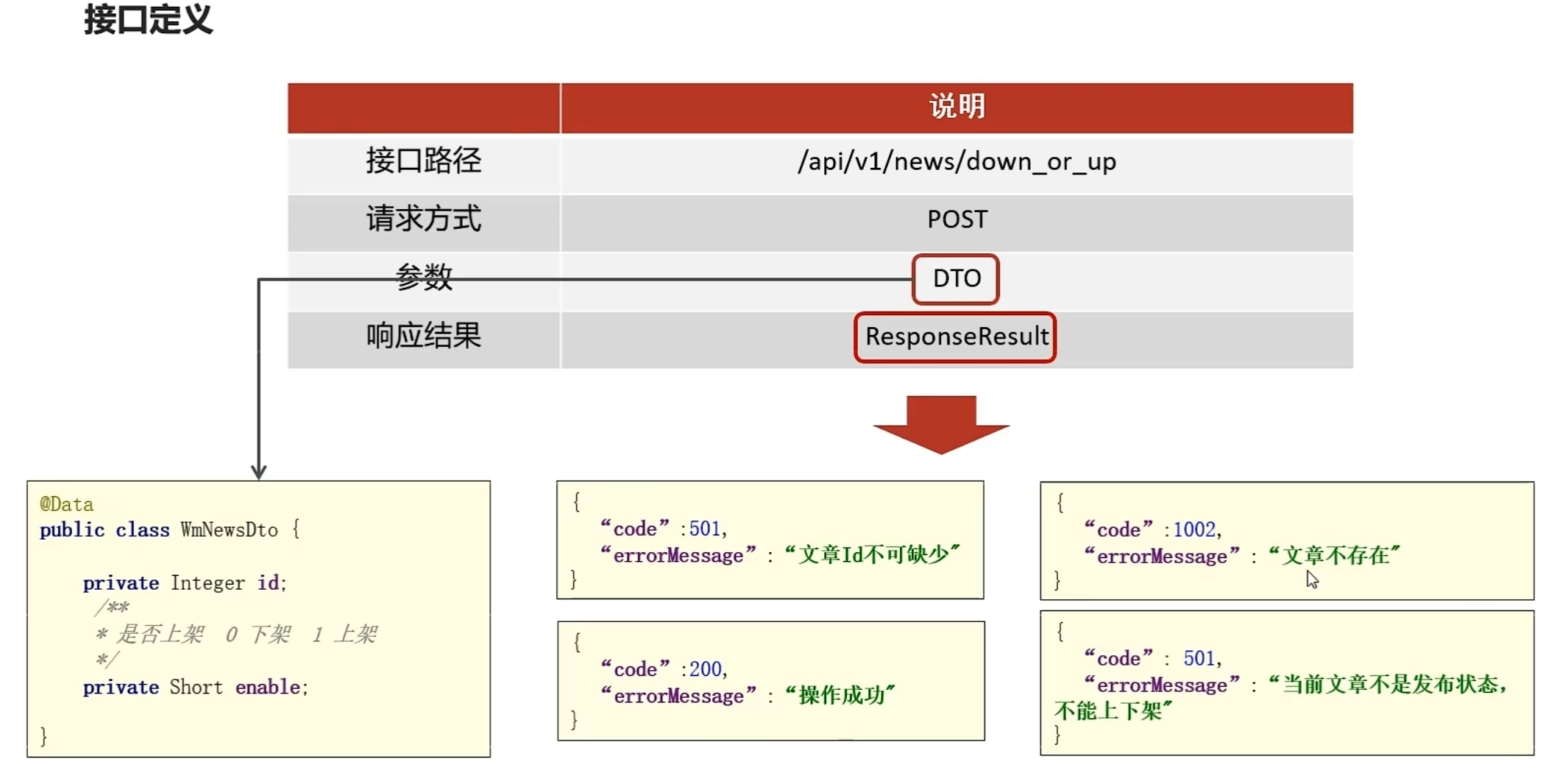
在heima-leadnews-wemedia工程下的WmNewsController新增方法
@PostMapping("/down_or_up")
public ResponseResult downOrUp(@RequestBody WmNewsDto dto){
return wmNewsService.downOrUp(dto);
}在WmNewsDto中新增enable属性
/**
* 上下架 0 下架 1 上架
*/
private Short enable;在WmNewsService新增方法
/**
* 文章的上下架
* @param dto
* @return
*/
public ResponseResult downOrUp(WmNewsDto dto);实现方法
/**
* 文章的上下架
* @param dto
* @return
*/
@Override
public ResponseResult downOrUp(WmNewsDto dto) {
//1.检查参数
if(dto.getId() == null){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
//2.查询文章
WmNews wmNews = getById(dto.getId());
if(wmNews == null){
return ResponseResult.errorResult(AppHttpCodeEnum.DATA_NOT_EXIST,"文章不存在");
}
//3.判断文章是否已发布
if(!wmNews.getStatus().equals(WmNews.Status.PUBLISHED.getCode())){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID,"当前文章不是发布状态,不能上下架");
}
//4.修改文章enable
if(dto.getEnable() != null && dto.getEnable() > -1 && dto.getEnable() < 2){
update(Wrappers.<WmNews>lambdaUpdate().set(WmNews::getEnable,dto.getEnable())
.eq(WmNews::getId,wmNews.getId()));
}
return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}测试通过

消息通知article数据同步
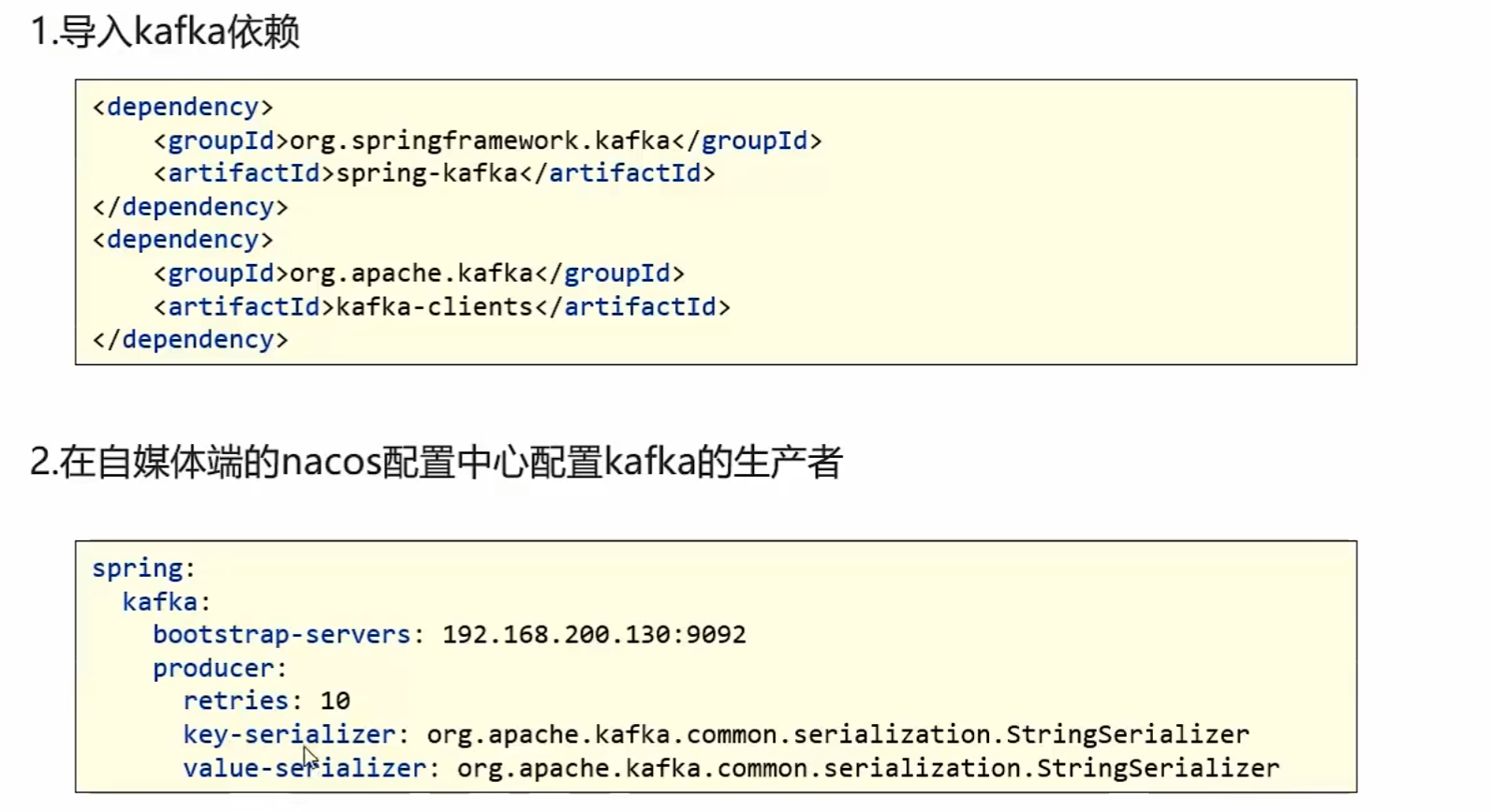


在heima-leadnews-common模块下导入kafka依赖
<!-- kafkfa -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>在自媒体端的nacos配置中心配置kafka的生产者
spring:
kafka:
bootstrap-servers: 192.168.200.130:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer在自媒体端文章上下架后发送消息
//发送消息,通知article端修改文章配置
if(wmNews.getArticleId() != null){
Map<String,Object> map = new HashMap<>();
map.put("articleId",wmNews.getArticleId());
map.put("enable",dto.getEnable());
kafkaTemplate.send(WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC,JSON.toJSONString(map));
}在article端的nacos配置中心配置kafka的消费者
spring:
kafka:
bootstrap-servers: 192.168.200.130:9092
consumer:
group-id: ${spring.application.name}
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer在article端编写监听,接收数据
import com.alibaba.fastjson.JSON;
import com.heima.article.service.ApArticleConfigService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.Map;
@Component
@Slf4j
public class ArtilceIsDownListener {
@Autowired
private ApArticleConfigService apArticleConfigService;
@KafkaListener(topics = WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC)
public void onMessage(String message){
if(StringUtils.isNotBlank(message)){
Map map = JSON.parseObject(message, Map.class);
apArticleConfigService.updateByMap(map);
log.info("article端文章配置修改,articleId={}",map.get("articleId"));
}
}
}新建ApArticleConfigService
public interface ApArticleConfigService extends IService<ApArticleConfig> {
/**
* 修改文章配置
* @param map
*/
public void updateByMap(Map map);
}实现
@Service
@Slf4j
@Transactional
public class ApArticleConfigServiceImpl extends ServiceImpl<ApArticleConfigMapper, ApArticleConfig> implements ApArticleConfigService {
/**
* 修改文章配置
* @param map
*/
@Override
public void updateByMap(Map map) {
//0 下架 1 上架
Object enable = map.get("enable");
boolean isDown = true;
if(enable.equals(1)){
isDown = false;
}
//修改文章配置
update(Wrappers.<ApArticleConfig>lambdaUpdate().eq(ApArticleConfig::getArticleId,map.get("articleId")).set(ApArticleConfig::getIsDown,isDown));
}
}测试成功tmd