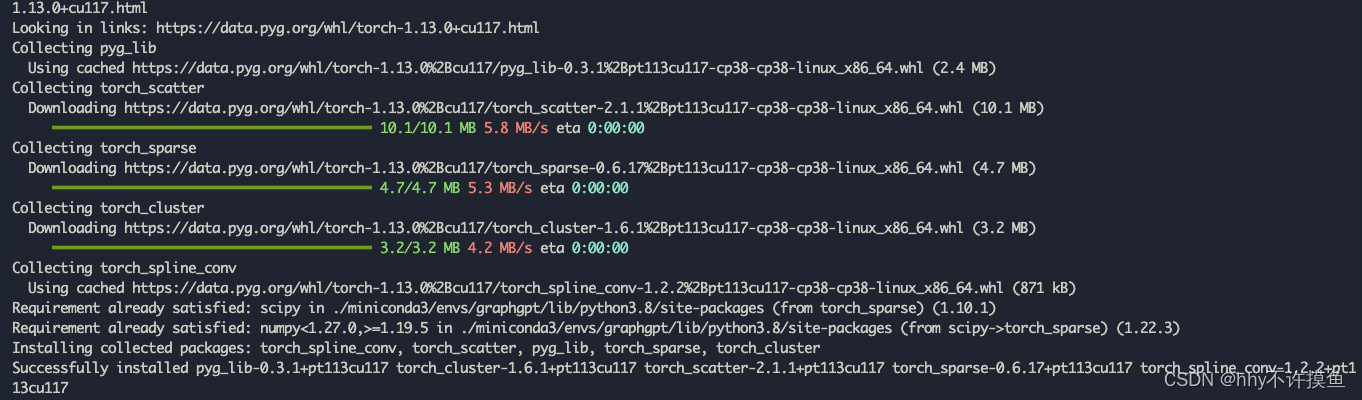
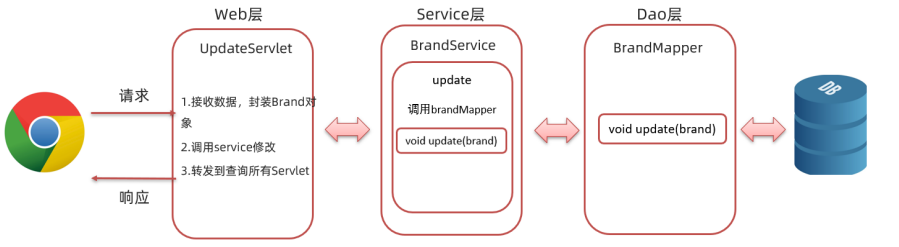
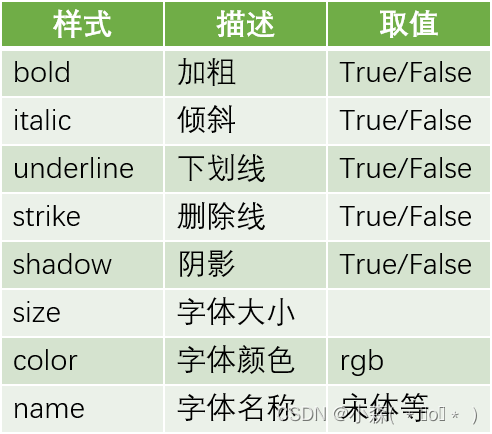
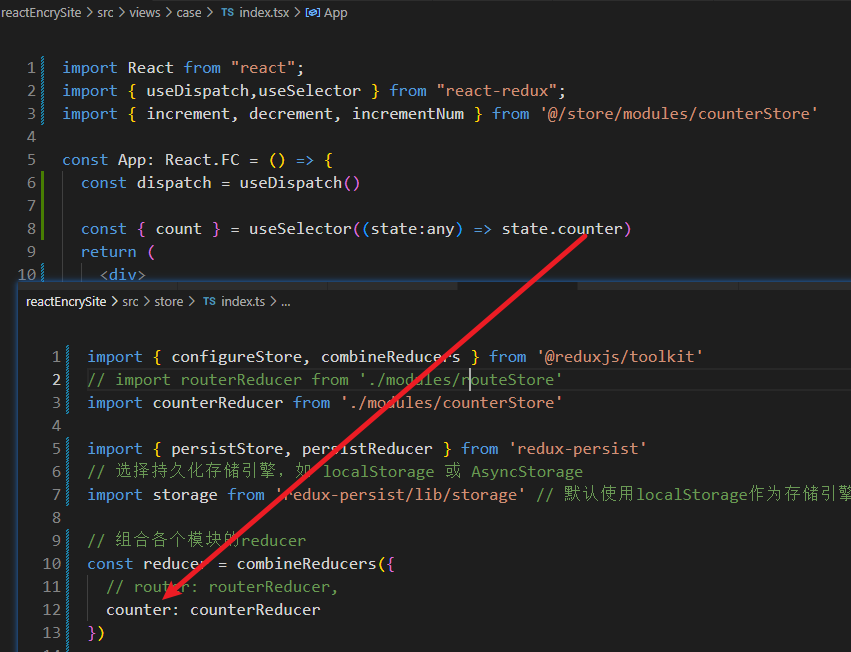
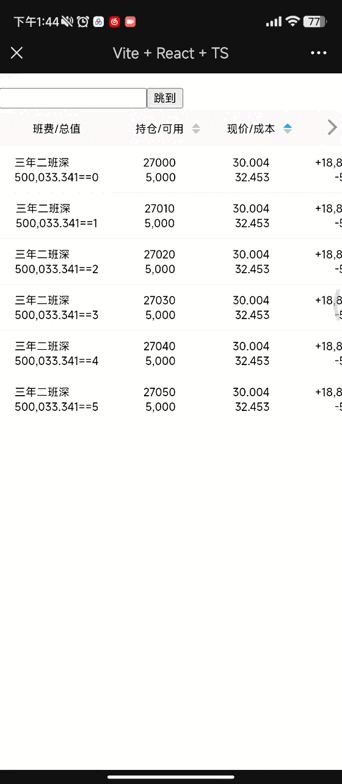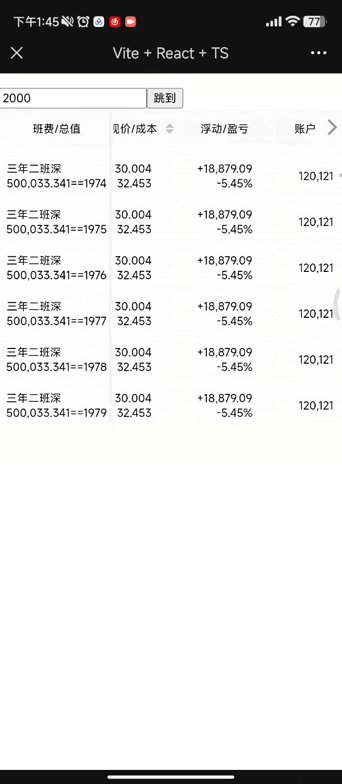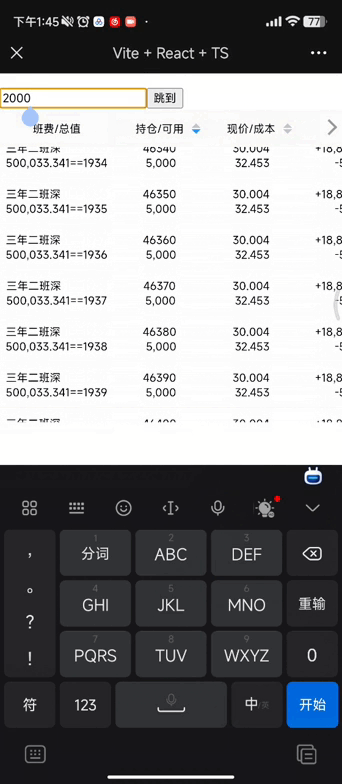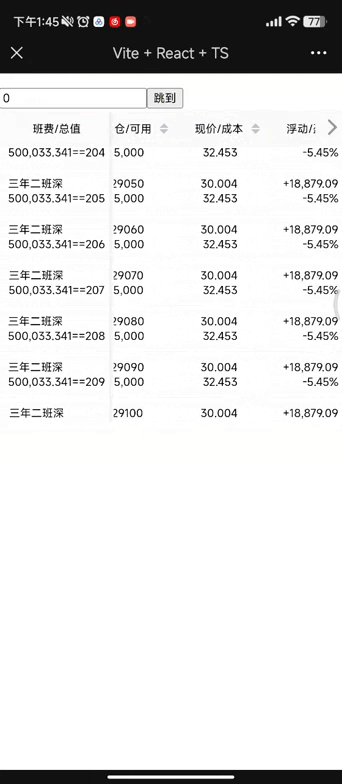
模型的 F1 分数是一个综合评估模型性能的指标,同时考虑了模型的精确率(Precision)和召回率(Recall)。F1 分数的计算公式为:
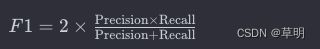
其中:
Precision是模型正确识别为正例的样本数量与所有被模型识别为正例的样本数量的比例。Recall是模型正确识别为正例的样本数量与所有实际正例的样本数量的比例。
F1 分数的取值范围在 0 到 1 之间,越接近 1 表示模型在精确率和召回率之间取得了更好的平衡。
在实际应用中,F1 分数通常用于那些需要在模型的精确性和召回率之间取得平衡的场景。例如,在某些医学诊断任务中,既希望模型能够尽可能准确地识别正例,又希望不漏报任何实际正例,这时 F1 分数就成为一个重要的评估指标。
要计算模型的 F1 分数,首先需要计算模型的精确率和召回率,然后使用上述公式计算 F1 分数。在一些机器学习框架和库中,计算 F1 分数的函数通常已经包含在性能评估工具中。例如,使用 scikit-learn 库可以通过 sklearn.metrics.f1_score 函数来计算 F1 分数。