朋友们,ICLR 2024这周放榜了!据统计,本届会议共收到了7262篇论文,整体接收率约为31%,与去年(31.8%)基本持平。其中Spotlight论文比例为5%,Oral论文比例为1.2%。
不知道各位看完有什么感想,我只觉卷上加卷,仿佛误入神仙打架现场...听说还有热度非常高的论文被拒稿,这下对31%接收率下的神文都讲的啥更好奇了。
于是为了满足各(自)位(已)的好奇心,我火速浏览了部分录用论文,整理出了25篇已录用的高分论文来和同学们分享,这些论文主要涉及时间序列、图大模型、agent等热门投稿主题。
由于个人时间和精力有限,论文都只做了简单介绍,但原文以及开源代码都已经帮同学们打包好了,感兴趣的同学可以看文末直接获取。
时间序列
1.Inherently Interpretable Time Series Classification via Multiple Instance Learning
通过多实例学习实现固有可解释的时间序列分类
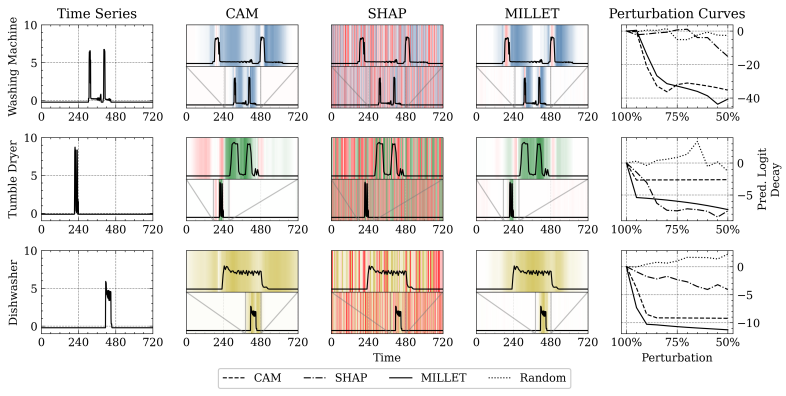
「简述:」论文提出了一种名为MILLET的新方法,通过多实例学习来解决传统时间序列分类方法难以解释的问题。作者将MILLET应用于现有的深度学习TSC模型,并展示了它们如何在不牺牲预测性能的情况下变得更容易理解。作者在多个数据集上评估了MILLET,结果表明它比其他可解释性方法更好。
2.ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis
用于通用时间序列分析的现代纯卷积结构
「简述:」论文提出了一种名为ModernTCN的新型纯卷积结构,用于更好地进行时间序列分析。作者对传统的TCN进行了修改,使其更适合时间序列任务。ModernTCN在五个主流时间序列分析任务上表现出色,同时保持了卷积模型的效率优势,比现有的最先进Transformer-based和MLP-based模型具有更好的效率和性能平衡。研究表明,ModernTCN具有更大的有效感受野,可以更好地发挥卷积在时间序列分析中的潜力。

3.Interpretable Sparse System Identification: Beyond Recent Deep Learning Techniques on Time-Series Prediction
超越时间序列预测的最新深度学习技术
「简述:」论文提出了一种可解释的稀疏系统识别方法,用于时间序列预测。该方法利用傅里叶基函数构建字典函数,同时考虑了数据背后的长期趋势和短期波动。通过使用L1范数进行稀疏优化,可以获得具有极高准确性的预测结果。作者在多个基准数据集上对该方法进行了评估,结果表明比最新的深度学习方法总体提高了超过20%。

4.iTransformer: Inverted Transformers Are Effective for Time Series Forecasting(热度高到爆炸)
倒置的Transformer对时间序列预测有效
「简述:」论文提出了新型时间序列预测模型iTransformer,重新定义了Transformer中的注意力机制和前馈网络的职责。该模型将每个时间点的多个变量嵌入到不同的变体令牌中,并利用注意力机制来捕捉多变量之间的相关性;同时,对每个变体令牌应用前馈网络以学习非线性表示。iTransformer模型在多个真实数据集上表现出色,具有更好的性能、泛化能力和回溯窗口利用率,可作为时间序列预测的基本骨干网络的替代品。

-
ClimODE: Climate Forecasting With Physics-informed Neural ODEs
-
Leveraging Generative Models for Unsupervised Alignment of Neural Time Series Data
-
FITS: Modeling Time Series with Parameters
-
TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
图大模型
1.LMExplainer: A Knowledge-Enhanced Explainer for Language Models
一种增强知识的语言模型解释器
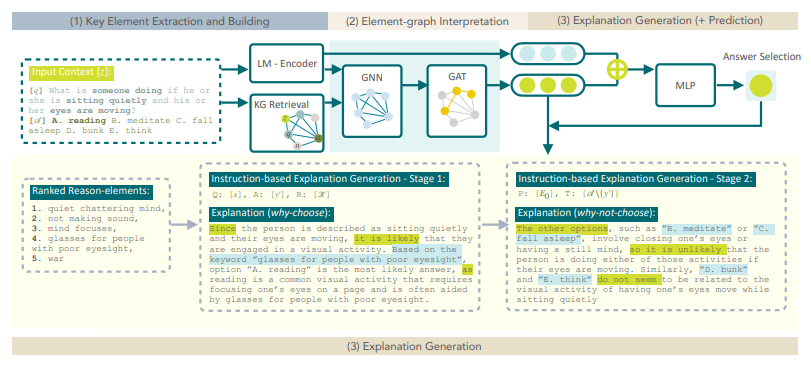
「简述:」论文提出了一种名为LMExplainer的知识增强型语言模型解释器,用于为大型语言模型提供易于理解的解释。该解释器利用图注意力神经网络在大规模知识图谱中高效地定位最相关的知识,以提取反映给定语言模型工作方式的关键决策信号。实验表明,LMExplainer比其他基线方法表现更好,生成更全面、更清晰的结论。
2.GraphGPT: Graph Learning with Generative Pre-trained Transformers
基于生成式预训练 Transformer 的图学习
「简述:」论文提出了一种新型图学习模型GraphGPT,利用生成式预训练Transformer进行自监督学习。该模型将每个图或采样子图转换为表示节点、边和属性的可逆令牌序列,并使用标准Transformer解码器进行预训练和微调。该模型在大规模数据集上表现出色,并能够训练最多包含4亿个参数的模型。

3.LLM4GCL: Can Large Language Model Em-Power Graph Contrastive Learning?
大型语言模型能否赋能图对比学习?
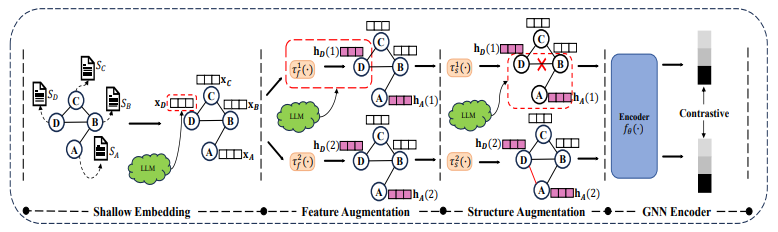
「简述:」在本文中,作者探讨了如何利用大型语言模型(LLMs)改进图对比学习(GCL)在文本归因图(TAGs)上的性能。作者提出了两种方法:LLM-as-GraphAugmentor和LLM-as-TextEncoder。前者利用LLMs对图进行增强,后者则将文本属性转换为嵌入向量。作者在六个基准数据集上进行了实验,结果表明LLM4GCL有望提高现有GCL方法的性能。
4.TKG-LM: Temporal Knowledge Graph Extrapolation Enhanced by Language Models
由语言模型增强的时间知识图谱外推
「简述:」论文提出了一种名为TKG-LM的方法,用于填补时间知识图谱和语言模型之间有效集成的空白。该方法包括历史事件剪枝、采样提示构建和层状模态融合等模块。具体来说,作者采用剪枝策略从大量历史事实中提取有价值的事件,并减少答案的搜索空间。然后,使用LMs和时间加权函数对每个邻居元组的语义相似性进行评分,并建立历史采样提示作为LMs的输入。作者将LMs和图神经网络的编码表示整合到一个多层框架中,以实现模态之间的双向信息流。这有助于将结构化拓扑知识纳入语言上下文表示,同时利用语言细微差别增强知识的图形表示。

-
GraphAgent: Exploiting Large Language Models for Interpretable Learning on Text-attributed Graphs
-
XplainLLM: A QA Explanation Dataset for Understanding LLM Decision-Making
-
One For All: Towards Training One Graph Model For All Classification Tasks
-
Spatio-Temporal Graph Learning with Large Language Model
AI Agent
1.Welfare Diplomacy Benchmarking Language Model Cooperation
福利外交基准语言模型合作
「简述:」论文提出了一种多代理基准测试,用于评估人工智能系统的合作能力。该测试结合了军事征服和国内福利两个因素,能够更全面地测量合作能力。作者使用开源引擎实现了该测试,并使用零样本提示语言模型构建了基线代理进行实验。实验结果表明,最先进的模型可以获得高社会福祉,但也存在被利用的风险。
2.WebArena A Realistic Web Environment for Building Autonomous Agents
用于构建自主代理的现实网络环境
「简述:」本文介绍了一种逼真、可重复的语言引导代理环境WebArena,用于评估自主代理在真实世界任务中的表现。作者创建了一个具有完全功能的网站环境,包括电子商务、社交论坛讨论、协作软件开发和内容管理等四个常见领域。该环境还配备了工具和外部知识库,以鼓励人类类似的任务解决方式。基于这个环境,作者发布了一组基准任务,重点评估任务完成的功能性正确性。实验结果表明,解决复杂任务具有挑战性,当前的先进大型语言模型在这些真实生活任务中的表现还不够完美。

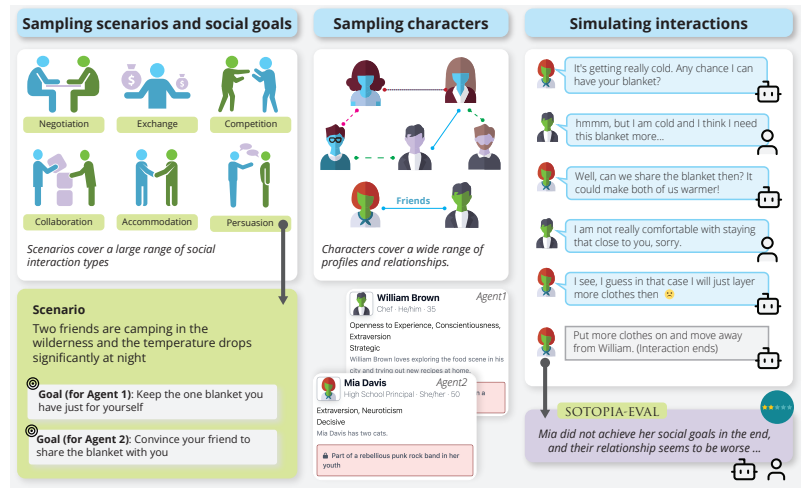
3.SOTOPIA Interactive Evaluation for Social Intelligence in Language Agents
语言代理中社会智能的交互式评估
「简述:」论文介绍了一个开放性环境SOTOPIA,用于模拟人工代理之间的复杂社交互动并评估其社会智能。作者使用该环境在各种情景下对基于LLM的代理和人类进行了角色扮演互动,并使用综合评估框架SOTOPIA-Eval对其表现进行评估。通过SOTOPIA,作者发现这些模型在社会智能方面存在显著差异,并且确定了一组通常对所有模型都具有挑战性的SOTOPIA场景。作者还发现在这些子集中,GPT-4在完成目标方面的成功率比人类低得多,并且很难表现出社交常识推理和战略沟通技巧。这些发现表明SOTOPIA作为评估和提高人工代理的社会智能的通用平台具有潜力。
4.SmartPlay A Benchmark for LLMs as Intelligent Agents
LLMs作为智能代理的基准测试
「简述:」本文介绍了一种名为SmartPlay的基准测试,用于评估大型语言模型(LLMs)作为智能代理的能力。该基准测试包括6个不同的游戏,每个游戏都有独特的设置和环境变化。每个游戏都挑战了智能LLM代理的不同能力,如推理、计划、空间推理、学习历史和理解随机性等。SmartPlay不仅是一种测试平台,还是识别当前方法学差距的路线图。
-
Playing repeated games with Large Language Models
-
MindAgent Emergent Gaming Interaction
-
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
-
Exploring Collaboration Mechanisms for LLM Agents A Social Psychology View
-
Evaluating Multi-Agent Coordination Abilities in Large Language Models
-
AgentBench Evaluating LLMs as Agents
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ICLR24”获取全部论文+录用清单
码字不易,欢迎大家点赞评论收藏