1.端上接入协议
如何自行开发代码访问阿里语音服务_智能语音交互(ISI)-阿里云帮助中心
2.接口修改结果逻辑及端上调用步骤
阿里client server交互流程图:

阿里语音接收识别结果:
begin_time time 含义
客户端循环发送语音数据,持续接收识别结果:
- SentenceBegin 事件表示检测到一句话的开始
- TranscriptionResultChanged 事件表示识别结果发生了变化。仅当请求消息中设置参数 enable_intermediate_result 为 ture 才会返回,默认为 false。
{
"header": {
"namespace": "SpeechTranscriber",
"name": "TranscriptionResultChanged",
"status": 20000000,
"message_id": "dc21193fada84380a3b6137875ab****",
"task_id": "5ec521b5aa104e3abccf3d361822****",
"status_text": "Gateway:SUCCESS:Success."
},
"payload": {
"index": 1,
"time": 1835,
"result": "北京的天",
"confidence": 1.0,
"words": [{
"text": "北京",
"startTime": 630,
"endTime": 930
}, {
"text": "的",
"startTime": 930,
"endTime": 1110
}, {
"text": "天",
"startTime": 1110,
"endTime": 1140
}]
}
}
payload 参数说明:
| 参数 | 类型 | 说明 |
| index | integer | 句子编号,1 开始递增 |
| time | integer | 已处理音频时长,ms |
| result | string | 当前句子识别结果 |
| words | list<> | 句子的词信息,enable_words 需要设置为 true |
| confidence | double | 当前句子识别结果的置信度,取值范围:[0.0, 1.0]。值越大置信度越高 |
- SentenceEnd 事件表示服务端检测到一句话的结束并将这句话最终结果发给用户,所谓最终结果,就是后面即使接收到音频,也不会对这个数据进行修正,也就是说目前阿里的设计是只支持句内修正,因为一般情况下句内相关性比较大,用来做参考纠正效果比较好。
{
"header": {
"namespace": "SpeechTranscriber",
"name": "SentenceEnd",
"status": 20000000,
"message_id": "c3a9ae4b231649d5ae05d4af36fd****",
"task_id": "5ec521b5aa104e3abccf3d361822****",
"status_text": "Gateway:SUCCESS:Success."
},
"payload": {
"index": 1,
"time": 1820,
"begin_time": 0,
"result": "北京的天气。",
"confidence": 1.0,
"words": [{
"text": "北京",
"startTime": 630,
"endTime": 930
}, {
"text": "的",
"startTime": 930,
"endTime": 1110
}, {
"text": "天气",
"startTime": 1110,
"endTime": 1380
}]
}
}
payload对象参数说明:
| 参数 | 类型 | 说明 |
| index | Integer | 句子编号,从1开始递增。 |
| time | Integer | 当前已处理的音频时长,单位是毫秒。 |
| begin_time | Integer | 当前句子对应的SentenceBegin事件的时间,单位是毫秒。 |
| result | String | 当前的识别结果。 |
| words | List< Word > | 当前句子的词信息,需要将enable_words设置为true。 |
| confidence | Double | 当前句子识别结果的置信度,取值范围:[0.0,1.0]。值越大表示置信度越高。 |
Words对象参数说明:
| 参数 | 类型 | 说明 |
| text | String | 文本。 |
| startTime | Integer | 词开始时间,单位为毫秒。 |
| endTime | Integer | 词结束时间,单位为毫秒。 |
腾讯实时语音接收识别结果:
语音识别 实时语音识别(websocket)-API 文档-文档中心-腾讯云
无相应字段配置

-
3.两个重要的功能字段
在上面描述端上调用步骤的时候提到了句内修正,那么怎么知道什么样的音频是一句话,下面有两个协议参数,对应了断句的两种策略。
| max_sentence_silence | int | 语音断句检测阈值,静音时长超过该阈值会被认为断句,参数范围200ms~6000ms,默认值800ms。 开启语义断句enable_semantic_sentence_detection后,此参数无效。 | 默认是200,单位毫秒 |
| enable_semantic_sentence_detection | bool | 是否开启语义断句,默认是False。语义断句参数需要和开启中间结果配合使用,即开启该语义断句参数需将中间结果参数同时打开:enable_intermediate_result=true。 | 默认是False,目前不支持 |
max_sentence_silence和enable_semantic_sentence_detection参数是互斥的两个参数,两个参数不能同时生效。第一个参数生效时候是根据静音来进行断句的并且只支持识别结果句内修正,第二种参数生效的时候是根据语义(标点符号),进行断句的。
两种参数分别对应了两种buffer的处理方式,下面在单路设计中会体现出来。
4.单路设计音频数据核心处理流程
单路流程图:

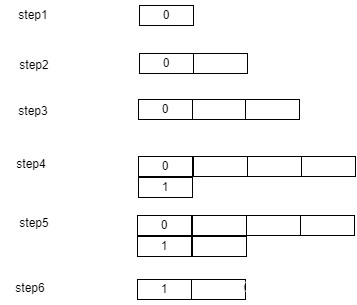
- 当max_sentence_silence参数生效时候数据buffer的生产消费处理流程
- 第一步是初始化状态,初始化数据为空(下图第一个框代表数组下标,不存储数据)。
- 第二步和第三步是每当收到用户发送的一块固定长度数据之后,将数据填入数组中最后的一个元素buffer之中。
- 第四步客户端发送的数据是静音数据,将该数据丢弃,并创建大小为0的buffer数据放入数组。
- 第五步将客户端发送的非静音数据拼接在数组尾部元素的buffer里面。
- 第六步数据处理线程,将数组头部数据拿走,发现数组大小大于1,将该元素删除出数组。
- 循环这个过程。
- enable_semantic_sentence_detection参数生效时候的buffer处理
前面不需要静音进行处理,通过句号来处理。
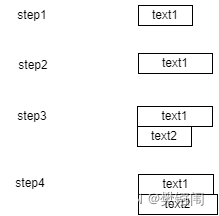
- 当max_sentence_silence参数生效时候数据文本的生产消费处理流程
第一步将识别文本放入下标为x的数据元素。
第二步由于没有收到静音或者未到达30s,将数据覆盖之前的数据元素。
第三步数据处理线程发现断句,将识别出来的文本数据,存入下标为x+1的数组元素中。
第四步使用数据处理线程识别出来的数据覆盖数组最后元素的文本。
第五步数据发送线程从文本数组中按照数组下标递增的顺序取数据并发送给客户端,如果当发送线程当前的句子index和文本数组index相等,发送最后一句。
- 当enable_semantic_sentence_detection参数生效时候数据文本的生产消费处理流程
该参数断句逻辑是根据识别文本中的句号或者逗号进行断句,所以将识别的数据连续存入string,根据标点符号断句发送给客户端就可以了。
5.多路设计整体流程架构
6.session上下文数据结构
| 字段名称 | 字段类型 | 字段含义 | 说明 |
| websocket | websocket | websocket句柄 | 用于该路数据的收发 |
| sessionId | string | 每一路数据唯一标识sessionId | 32位uuid,用于标识某一路数据。 |
| bytes | bytes of array | 二进制数据数组 | 用来存储二进制数据,每一个bytes都是一段buffer。 |
| textArray | string[] | 文本结果数组 | 用来存储结果文本数据,如果enable_intermediate_result能力为true,数组的最后一个元素是可变的,以便支持该能力。 |
| format | string | 音频数据的类型 | 默认是“PCM”,v1只支持处理pcm格式数据 |
| sample_rate | int | 音频数据采样率 | 默认是16000 |
| channels | int | 通道数 | 默认是1,目前只支持单通道 |
| enable_intermediate_result | bool | 是否返回中间识别结果 | 默认是true |
| enable_punctuation_prediction | bool | 是否在后处理中加标点 | 默认是false,目前不支持 |
| enable_inverse_text_normalization | bool | ITN(逆文本inverse text normalization)中文数字转换阿拉伯数字。设置为True时,中文数字将转为阿拉伯数字输出,默认值:False | 目前不支持 |
| customization_id | string | 自学习模型id | 目前不支持 |
| vocabulary_id | string | 定制泛热词ID | 目前不支持 |
| max_sentence_silence | int | 语音断句检测阈值,静音时长超过该阈值会被认为断句,参数范围200ms~6000ms,默认值800ms。 开启语义断句enable_semantic_sentence_detection后,此参数无效。 | 默认是200,单位毫秒 |
| enable_words | bool | 是否开启返回词信息 | 默认是false |
| enable_ignore_sentence_timeout | bool | 是否忽略实时识别中的单句识别超时 | 默认是false |
| disfluency | bool | 过滤语气词,即声音顺 | 默认值false,目前不支持 |
| speech_noise_threshold | float | 噪音参数阈值,参数范围:[-1,1]。取值说明如下:
| 默认是0.0 |
| enable_semantic_sentence_detection | bool | 是否开启语义断句,默认是False。语义断句参数需要和开启中间结果配合使用,即开启该语义断句参数需将中间结果参数同时打开:enable_intermediate_result=true。 | 默认是False,目前不支持 |
| special_word_filter | json string | 敏感词过滤功能,可根据实际需求开启或关闭自定义词或默认词表。该参数支持以下选项:
| 默认不处理,目前不支持 |
7.线程安全相关调研
python中的队列(queue.Queue)是线程安全的,不需要加锁(如果在多线程环境中进行通信,应该使用queue.Queue。如果在多进程环境中进行通信,你应该使用multiprocessing.Queue。如果在协程之间进行通信,你应该使用asyncio.Queue)。
相关资料:
8.10. Queue — A synchronized queue class — Python 2.7.18 documentation
队列源码实现:
class Queue:
"""Create a queue object with a given maximum size.
If maxsize is <= 0, the queue size is infinite.
"""
def __init__(self, maxsize=0):
self.maxsize = maxsize
self._init(maxsize)
# mutex must be held whenever the queue is mutating. All methods
# that acquire mutex must release it before returning. mutex
# is shared between the three conditions, so acquiring and
# releasing the conditions also acquires and releases mutex.
self.mutex = _threading.Lock()
# Notify not_empty whenever an item is added to the queue; a
# thread waiting to get is notified then.
self.not_empty = _threading.Condition(self.mutex)
# Notify not_full whenever an item is removed from the queue;
# a thread waiting to put is notified then.
self.not_full = _threading.Condition(self.mutex)
# Notify all_tasks_done whenever the number of unfinished tasks
# drops to zero; thread waiting to join() is notified to resume
self.all_tasks_done = _threading.Condition(self.mutex)
self.unfinished_tasks = 0
def task_done(self):
"""Indicate that a formerly enqueued task is complete.
Used by Queue consumer threads. For each get() used to fetch a task,
a subsequent call to task_done() tells the queue that the processing
on the task is complete.
If a join() is currently blocking, it will resume when all items
have been processed (meaning that a task_done() call was received
for every item that had been put() into the queue).
Raises a ValueError if called more times than there were items
placed in the queue.
"""
self.all_tasks_done.acquire()
try:
unfinished = self.unfinished_tasks - 1
if unfinished <= 0:
if unfinished < 0:
raise ValueError('task_done() called too many times')
self.all_tasks_done.notify_all()
self.unfinished_tasks = unfinished
finally:
self.all_tasks_done.release()
def join(self):
"""Blocks until all items in the Queue have been gotten and processed.
The count of unfinished tasks goes up whenever an item is added to the
queue. The count goes down whenever a consumer thread calls task_done()
to indicate the item was retrieved and all work on it is complete.
When the count of unfinished tasks drops to zero, join() unblocks.
"""
self.all_tasks_done.acquire()
try:
while self.unfinished_tasks:
self.all_tasks_done.wait()
finally:
self.all_tasks_done.release()
def qsize(self):
"""Return the approximate size of the queue (not reliable!)."""
self.mutex.acquire()
n = self._qsize()
self.mutex.release()
return n
def empty(self):
"""Return True if the queue is empty, False otherwise (not reliable!)."""
self.mutex.acquire()
n = not self._qsize()
self.mutex.release()
return n
def full(self):
"""Return True if the queue is full, False otherwise (not reliable!)."""
self.mutex.acquire()
n = 0 < self.maxsize == self._qsize()
self.mutex.release()
return n
def put(self, item, block=True, timeout=None):
"""Put an item into the queue.
If optional args 'block' is true and 'timeout' is None (the default),
block if necessary until a free slot is available. If 'timeout' is
a non-negative number, it blocks at most 'timeout' seconds and raises
the Full exception if no free slot was available within that time.
Otherwise ('block' is false), put an item on the queue if a free slot
is immediately available, else raise the Full exception ('timeout'
is ignored in that case).
"""
self.not_full.acquire()
try:
if self.maxsize > 0:
if not block:
if self._qsize() == self.maxsize:
raise Full
elif timeout is None:
while self._qsize() == self.maxsize:
self.not_full.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
endtime = _time() + timeout
while self._qsize() == self.maxsize:
remaining = endtime - _time()
if remaining <= 0.0:
raise Full
self.not_full.wait(remaining)
self._put(item)
self.unfinished_tasks += 1
self.not_empty.notify()
finally:
self.not_full.release()
def put_nowait(self, item):
"""Put an item into the queue without blocking.
Only enqueue the item if a free slot is immediately available.
Otherwise raise the Full exception.
"""
return self.put(item, False)
def get(self, block=True, timeout=None):
"""Remove and return an item from the queue.
If optional args 'block' is true and 'timeout' is None (the default),
block if necessary until an item is available. If 'timeout' is
a non-negative number, it blocks at most 'timeout' seconds and raises
the Empty exception if no item was available within that time.
Otherwise ('block' is false), return an item if one is immediately
available, else raise the Empty exception ('timeout' is ignored
in that case).
"""
self.not_empty.acquire()
try:
if not block:
if not self._qsize():
raise Empty
elif timeout is None:
while not self._qsize():
self.not_empty.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
endtime = _time() + timeout
while not self._qsize():
remaining = endtime - _time()
if remaining <= 0.0:
raise Empty
self.not_empty.wait(remaining)
item = self._get()
self.not_full.notify()
return item
finally:
self.not_empty.release()
进程间数据安全调用示例
from multiprocessing import Process, Queue
def producer(q):
for i in range(5):
q.put('Message {}'.format(i))
print('Message {} put in queue by producer'.format(i))
def consumer(q):
while True:
message = q.get()
print('Message received by consumer: {}'.format(message))
if message == 'Message 4':
break
if __name__ == '__main__':
q = Queue()
p1 = Process(target=producer, args=(q,))
p2 = Process(target=consumer, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
线程间数据安全调用示例
import queue
import threading
def producer(q):
for i in range(5):
q.put('Message {}'.format(i))
print('Message {} put in queue by producer'.format(i))
def consumer(q):
while True:
message = q.get()
print('Message received by consumer: {}'.format(message))
if message == 'Message 4':
break
if __name__ == '__main__':
q = queue.Queue()
t1 = threading.Thread(target=producer, args=(q,))
t2 = threading.Thread(target=consumer, args=(q,))
t1.start()
t2.start()
t1.join()
t2.join()
协程间线程安全调用示例
import asyncio
async def producer(q):
for i in range(5):
await q.put('Message {}'.format(i))
print('Message {} put in queue by producer'.format(i))
async def consumer(q):
while True:
message = await q.get()
print('Message received by consumer: {}'.format(message))
if message == 'Message 4':
break
if __name__ == '__main__':
q = asyncio.Queue()
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(producer(q), consumer(q)))
loop.close()
- 方案设计进度表格