目录
一、概述
1.1、分片算法
精确分片算法
范围分片算法
复合分片算法
Hint分片算法
1.2、分片策略
标准分片策略
复合分片策略
行表达式分片策略
Hint分片策略
不分片策略
二、自定义分片算法 - 复合分片算法
(1)、创建数据库和表
(2)、自定义分库算法
(3)、自定义分片算法
(4)、配置分库分表规则
(5)、测试插入操作
三、自定义分片算法 - 精确分片算法
四、自定义分片算法 - 范围分片算法
五、自定义分片算法 - Hint算法
一、概述
1.1、分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。

精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
1.2、分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm(精准分片)和RangeShardingAlgorithm(范围分片)两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
不分片策略
对应NoneShardingStrategy。不分片的策略。
在前面 Sharding-JDBC的案例中,我们都是使用的系统内置的分表分库算法,配置起来非常简单, 直接使用行表达式配置即可,如t_order$->{order_id % 2}等。但是它的功能比较简单,只能进行简单的取模,哈希运算,对于需要根据业务逻辑进行复杂的分片规则,内置的一些算法就无法实现了,这个时候就需要我们自己自定义满足业务规则的分片算法,下面演示一下如何自定义分片算法。
二、自定义分片算法 - 复合分片算法
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片键操作。
下面我们实现同时以 order_id、user_id两个字段作为分片键,自定义复合分片策略。
(1)、创建数据库和表
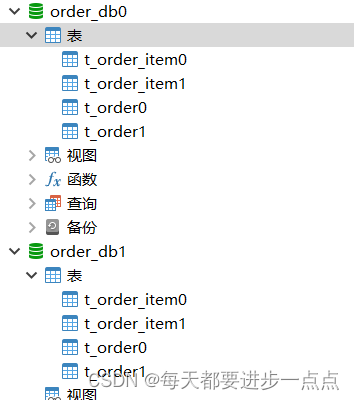
CREATE TABLE `t_order0` (
`order_id` bigint(20) NOT NULL COMMENT '订单ID',
`order_name` varchar(255) DEFAULT NULL COMMENT '订单名称',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_order1` (
`order_id` bigint(20) NOT NULL COMMENT '订单ID',
`order_name` varchar(255) DEFAULT NULL COMMENT '订单名称',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;(2)、自定义分库算法
重点是演示如何自定义分库算法,所以我们只是实现了一个很简单的多个分片键共同决定分库选择的策略:
(order_id.hashCode() + user_id.hashCode()) % databases.size()。
/**
* 自定义一个简单的复合分库算法: 使用到两个分片键(order_id、user_id)共同决定数据应该落到哪个真实数据库。
* (order_id.hashCode() + user_id.hashCode()) % databases.size()
*
* 泛型是Long的原因是order_id、user_id这两个分表列类型就是Long,就是说这个算法你要应用到数据表的哪一个字段,那么这个泛型的类型就是这个字段的类型。
*/
public class MyDataBaseShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
private static final Logger logger = LoggerFactory.getLogger(MyDataBaseShardingAlgorithm.class);
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
logger.info("【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...");
logger.info("【MyDataBaseShardingAlgorithm】availableTargetNames: {}, shardingValue: {}", availableTargetNames, JSON.toJSONString(shardingValue));
// dataSourceIndex = (order_id.hashCode() + user_id.hashCode()) % databases.size()
int dataSourceIndex = getDataSourceIndex(availableTargetNames, shardingValue);
logger.info("【MyDataBaseShardingAlgorithm】dataSourceIndex:{}", dataSourceIndex);
List<String> shardingResults = new ArrayList<>();
// availableTargetNames: [ds0, ds1]
for (String dataSourceName : availableTargetNames) {
// 截取数据源名称ds后面的部分
String dataSourceNameSuffix = dataSourceName.substring(2);
// 匹配到第一个合适的数据源,直接返回
if (dataSourceNameSuffix.equals(String.valueOf(dataSourceIndex))) {
shardingResults.add(dataSourceName);
break;
}
}
return shardingResults;
}
private static int getDataSourceIndex(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
// availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[13847],"user_id":[28]},"logicTableName":"t_order"}
// 分片键的h值
int columnShardingValueHashCode = shardingValue.getColumnNameAndShardingValuesMap().values()
.stream().map(longs -> (List<Long>) longs)
.mapToInt(columnShardingValues -> columnShardingValues.get(0).hashCode())
.sum();
// (order_id.hashCode() + user_id.hashCode()) % databases.size()
logger.info("【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:{}", columnShardingValueHashCode);
return columnShardingValueHashCode % availableTargetNames.size();
}
}(3)、自定义分片算法
重点是演示如何自定义分库算法,所以我们只是实现了一个很简单的多个分片键共同决定分库选择的策略:
(order_id * user_id) % databases.size()。
/**
* 自定义一个简单的复合分表算法: 使用到两个分片键(order_id、user_id)共同决定数据应该落到哪个真实数据库。
* (order_id * user_id) % databases.size()
*/
public class MyTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
private static final Logger logger = LoggerFactory.getLogger(MyTableShardingAlgorithm.class);
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
logger.info("【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...");
logger.info("【MyTableShardingAlgorithm】availableTargetNames: {}, shardingValue: {}", availableTargetNames, JSON.toJSONString(shardingValue));
// dataSourceIndex = (order_id * user_id) % databases.size()
int tableIndex = getTableIndex(availableTargetNames, shardingValue);
logger.info("【MyTableShardingAlgorithm】tableIndex:{}", tableIndex);
List<String> shardingResults = new ArrayList<>();
// availableTargetNames: [t_order0, t_order1]
for (String dataSourceName : availableTargetNames) {
// 截取数据源名称t_order后面的部分
String dataSourceNameSuffix = dataSourceName.substring(7);
// 匹配到第一个合适的数据表,直接返回
if (dataSourceNameSuffix.equals(String.valueOf(tableIndex))) {
shardingResults.add(dataSourceName);
break;
}
}
return shardingResults;
}
private static int getTableIndex(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
// availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[58201],"user_id":[95]},"logicTableName":"t_order"}
int columnShardingValue = shardingValue.getColumnNameAndShardingValuesMap().values()
.stream().map(longs -> (List<Long>) longs)
.mapToInt(columnShardingValues -> Math.toIntExact(columnShardingValues.get(0)))
.reduce(1, (a, b) -> a * b);
// (order_id * user_id) % databases.size()
logger.info("【MyTableShardingAlgorithm】columnShardingValue:{}", columnShardingValue);
return columnShardingValue % availableTargetNames.size();
}
}(4)、配置分库分表规则
application.properties 配置文件中只需修改分库策略名 database-strategy 为复合模式complex,分片算法 complex.algorithm-class-name为自定义的分库算法类路径。
spring:
shardingsphere:
props:
sql:
show: true # 打印具体的插入SQL
datasource:
names: ds0,ds1
ds0: # 数据源的名称
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order_db0?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: "0905"
ds1: # 数据源的名称
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order_db1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: "0905"
sharding:
tables:
t_order: # 逻辑表的名称
actual-data-nodes: ds$->{0..1}.t_order$->{0..1} # 真实的数据节点: ds0数据源下的t_order0、t_order1两个表
table-strategy:
complex:
sharding-columns: order_id,user_id # 表分片字段
algorithm-class-name: org.example.shardingjdbcdemo.algorithm.MyTableShardingAlgorithm # 自定义数据表分片算法
database-strategy:
complex:
sharding-columns: order_id,user_id # 分库字段
algorithm-class-name: org.example.shardingjdbcdemo.algorithm.MyDataBaseShardingAlgorithm # 自定义分库算法
key-generator:
column: order_id # 主键字段名称
type: SNOWFLAKE # 主键生成策略:雪花算法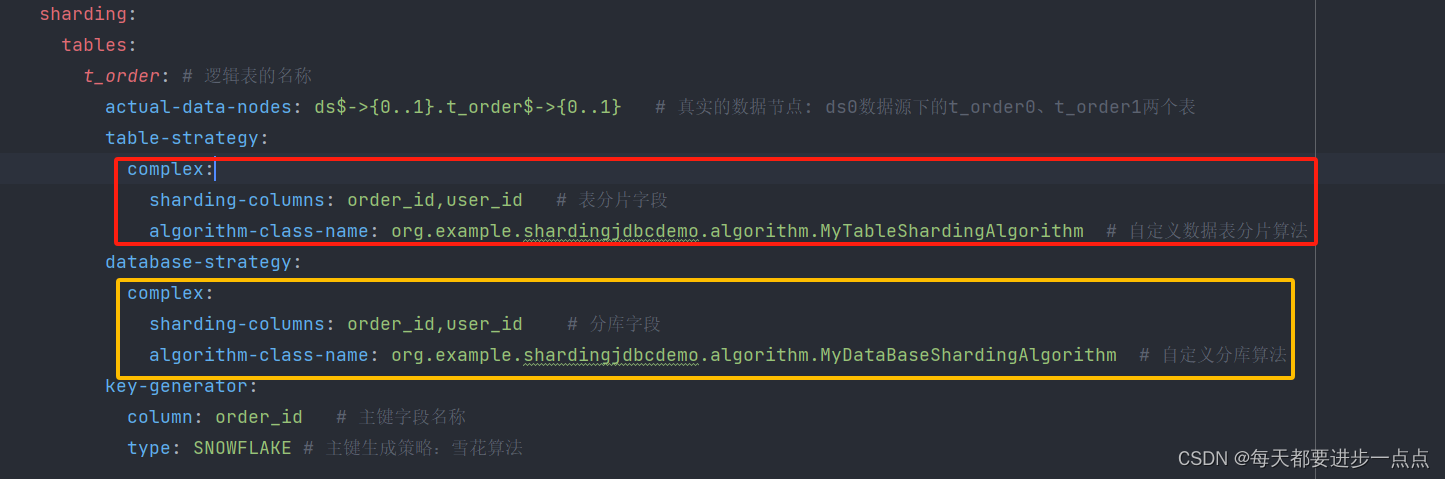
(5)、测试插入操作
从控制台的路由信息可以看到,分库、分表的选择策略都如上面我们定义的根据order_id、user_id共同决定的,在工作中如有需要根据多个分片键共同决定分片策略的场景,就可以通过实现ComplexKeysShardingAlgorithm接口实现。
2023-12-21 17:46:44.356 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...
2023-12-21 17:46:44.890 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[29687],"user_id":[75]},"logicTableName":"t_order"}
2023-12-21 17:46:44.894 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:29762
2023-12-21 17:46:44.894 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】dataSourceIndex:0
2023-12-21 17:46:44.895 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...
2023-12-21 17:46:44.896 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[29687],"user_id":[75]},"logicTableName":"t_order"}
2023-12-21 17:46:44.898 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】columnShardingValue:2226525
2023-12-21 17:46:44.898 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】tableIndex:1
2023-12-21 17:46:44.955 INFO 3652 --- [ main] ShardingSphere-SQL : Logic SQL: insert into t_order(`order_id`, `order_name`, `user_id`) values (?, ?, ?)
2023-12-21 17:46:44.956 INFO 3652 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@261de205, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@7f3fc42f), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@7f3fc42f, columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=66, stopIndex=66, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=69, stopIndex=69, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=72, stopIndex=72, parameterMarkerIndex=2)], parameters=[29687, 订单[0], 75])], generatedKeyContext=Optional[GeneratedKeyContext(columnName=order_id, generated=false, generatedValues=[29687])])
2023-12-21 17:46:44.956 INFO 3652 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: insert into t_order1(`order_id`, `order_name`, `user_id`) values (?, ?, ?) ::: [29687, 订单[0], 75]
2023-12-21 17:46:45.051 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[83190],"user_id":[8]},"logicTableName":"t_order"}
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:83198
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】dataSourceIndex:0
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.053 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[83190],"user_id":[8]},"logicTableName":"t_order"}
2023-12-21 17:46:45.053 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】columnShardingValue:665520
2023-12-21 17:46:45.053 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】tableIndex:0
2023-12-21 17:46:45.054 INFO 3652 --- [ main] ShardingSphere-SQL : Logic SQL: insert into t_order(`order_id`, `order_name`, `user_id`) values (?, ?, ?)
2023-12-21 17:46:45.054 INFO 3652 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@261de205, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@324b6a56), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@324b6a56, columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=66, stopIndex=66, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=69, stopIndex=69, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=72, stopIndex=72, parameterMarkerIndex=2)], parameters=[83190, 订单[1], 8])], generatedKeyContext=Optional[GeneratedKeyContext(columnName=order_id, generated=false, generatedValues=[83190])])
2023-12-21 17:46:45.055 INFO 3652 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: insert into t_order0(`order_id`, `order_name`, `user_id`) values (?, ?, ?) ::: [83190, 订单[1], 8]
2023-12-21 17:46:45.067 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.067 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[13400],"user_id":[3]},"logicTableName":"t_order"}
2023-12-21 17:46:45.067 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:13403
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】dataSourceIndex:1
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[13400],"user_id":[3]},"logicTableName":"t_order"}
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】columnShardingValue:40200
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】tableIndex:0
2023-12-21 17:46:45.069 INFO 3652 --- [ main] ShardingSphere-SQL : Logic SQL: insert into t_order(`order_id`, `order_name`, `user_id`) values (?, ?, ?)
2023-12-21 17:46:45.070 INFO 3652 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@261de205, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@36359723), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@36359723, columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=66, stopIndex=66, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=69, stopIndex=69, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=72, stopIndex=72, parameterMarkerIndex=2)], parameters=[13400, 订单[2], 3])], generatedKeyContext=Optional[GeneratedKeyContext(columnName=order_id, generated=false, generatedValues=[13400])])
2023-12-21 17:46:45.070 INFO 3652 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: insert into t_order0(`order_id`, `order_name`, `user_id`) values (?, ?, ?) ::: [13400, 订单[2], 3]三、自定义分片算法 - 精确分片算法
实现自定义精准分库、分表算法的方式大致相同,都要实现 PreciseShardingAlgorithm 接口,并重写 doSharding() 方法,只是配置稍有不同,而且它只是个空方法,得我们自行处理分库、分表逻辑。
/**
* 自定义精确分片算法
*/
public class MyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
private static final Logger logger = LoggerFactory.getLogger(MyPreciseShardingAlgorithm.class);
/**
* 精确分片的返回只有一个
*
* @param availableTargetNames 可用的数据源或表的名称
* @param shardingValue PreciseShardingValue: 其中logicTableName为逻辑表,columnName分片键(字段),value为分片键的值
* @return
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
logger.info("execute MyPreciseShardingAlgorithm.doSharding....");
logger.info("【MyPreciseShardingAlgorithm】availableTargetNames:{}, shardingValue:{}", availableTargetNames, shardingValue);
for (String availableTargetName : availableTargetNames) {
// 分片键的值 % 表数量
String shardingIndex = String.valueOf(shardingValue.getValue() % availableTargetNames.size());
// 找到一个合适的分片后直接返回
if (availableTargetName.endsWith(shardingIndex)) {
return availableTargetName;
}
}
throw new IllegalArgumentException();
}
}分库分表规则配置如下:
# 分库策略
# 分库分片键
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 自定义分库算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=自定义分库算法的全限定类名
# 分表策略
# 分表分片键
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
# 自定义分表算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=自定义分表算法的全限定类名四、自定义分片算法 - 范围分片算法
使用场景:当我们 SQL中的分片键字段用到 BETWEEN AND操作符会使用到此算法,会根据 SQL中给出的分片键值范围值处理分库、分表逻辑。
/**
* 自定义范围分片算法
*/
public class MyRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
// 满足分片规则的DataSourceName或者TableNames
Set<String> result = new LinkedHashSet<>();
// between and的起始值
long lower = shardingValue.getValueRange().lowerEndpoint();
// between and的截止值
long upper = shardingValue.getValueRange().upperEndpoint();
long i = lower;
while (i <= upper) {
for (String targetName : availableTargetNames) {
if (targetName.endsWith(String.valueOf(i % availableTargetNames.size()))) {
result.add(targetName);
}
}
i++;
}
return result;
}
}分库分表规则配置如下:
# 分库策略
# 分库分片键
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 自定义分库算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=自定义分库算法的全限定类名
# 分表策略
# 分表分片键
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
# 自定义分表算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=自定义分表算法的全限定类名五、自定义分片算法 - Hint算法
Hint分片策略(HintShardingStrategy)相比于上面几种分片策略稍有不同,这种分片策略无需配置分片键,分片键值也不再从 SQL中解析,而是由外部指定分片信息,让 SQL在指定的分库、分表中执行。ShardingSphere 通过 Hint API实现指定操作,实际上就是把分片规则tablerule 、databaserule由集中配置变成了个性化配置。
举个例子,如果我们希望订单表t_order用 user_id 做分片键进行分库分表,但是 t_order 表中却没有 user_id 这个字段,这时可以通过 Hint API 在外部手动指定分片键或分片库。
/**
* 自定义Hint分片算法
*/
public class MyHintShardingAlgorithm implements HintShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<String> shardingValue) {
Collection<String> result = new ArrayList<>();
for (String targetName : availableTargetNames) {
for (String value : shardingValue.getValues()) {
if (targetName.endsWith(String.valueOf(Long.parseLong(value) % availableTargetNames.size()))) {
result.add(targetName);
}
}
}
return result;
}
}这种方式自定义完分片算法时,需要在业务代码中手动设置分库或者分片的值,对业务代码侵入太大,在实际工作中用的不多,这里只是做个了解,不再阐述,感兴趣的同学可自行google下。