本篇笔记部分内容来源于这位老师的知识分享【公众号:秃顶的码农】,我从他的资料里学到了很多,期间还私信询问了一些困惑,都得到了老师详细的答复,相当nice!
(六)横向联邦学习 — 梯度更新聚合
云端数据中心的分布式机器学习可以有成百上千的节点,对比横向联邦学习有一定的借鉴意义,都存在着节点更新的同步与异步的问题,节点梯度更新之后的问题、节点掉线的问题、数据的 Non IID 问题,但是横向联邦学习的场景更加复杂,基础设施相对云端的统一高速基建存在非常大的差异,同时加上隐私保护机制,这就造成了横向联邦学习的系统设计会更加的复杂,以支撑各种异构的底层基建。
1. 模型更新方法
横向联邦学习的两种模型更新机制:
-
FedSGD
类似于云端数据中心里面的分布式机器学习的同步模式,通过梯度的传输进行模型的全局更新。最近大量的深度学习的成功应用几乎完全依赖于随机梯度下降(SGD)的变体作为优化算法,因此,我们很自然地从 SGD 开始构建联邦优化的算法。我们可以通过使用所选设备上的所有数据来选择批处理,所以我们将这个简单的基线算法称为 FedSGD。

-
FedAvg
上面描述算法可以理解为一个端点的简单的一次平均,其中每个客户求解最小化其局部数据损失的模型,并对这些模型进行聚合以产生最终的全局模型。这种方法在带有 IID 数据的凸情况下得到了广泛的研究,众所周知,在最坏情况下,产生的全局模型并不比在单个客户端上训练模型更好,所以我们需要针对联邦学习研究一种新的模型更新方法,也就是 FedAvg。
笔记分享 | 联邦学习新手必看!手把手教你读懂FedAvg代码并实现运行

FedSGD 与 FedAvg 的不同点在于:
- 传递数据的不同:FedSGD 传递的是梯度 g,FedAvg 传递的是模型参数 w;
- 传输效率不同:FedAvg 会在本地经过多轮的训练,先对本地模型经过 Loss 的多轮优化,在同步最后的优化参数 w 到服务端。
- 模型聚合的方式不同:服务端针对客户端返回的参数 w 进行平均聚合,期望通过这种方式解决数据的 Non IID 问题。
- 安全性:FedAvg 在本地经过多轮训练,对于模型的保护性更好。
2. 梯度安全聚合
顺着前文的思路,在 FedSGD 与 FedAvg 这两个算法中,所有的梯度、参数等都是通过明文的形式传递的,所以存在隐私泄露问题。早在2017年,谷歌的Bonawitz 等发表了《Practical Secure Aggregation for Privacy-Preserving Machine Learning》这篇文章,详细阐述了针对梯度泄露攻击设计的 Secure Aggregation 协议,我们简称为 SMPC。
— — 那么如何实现梯度的安全聚合?
— — 借助 “秘密分享” 和 “DH密钥交换”!
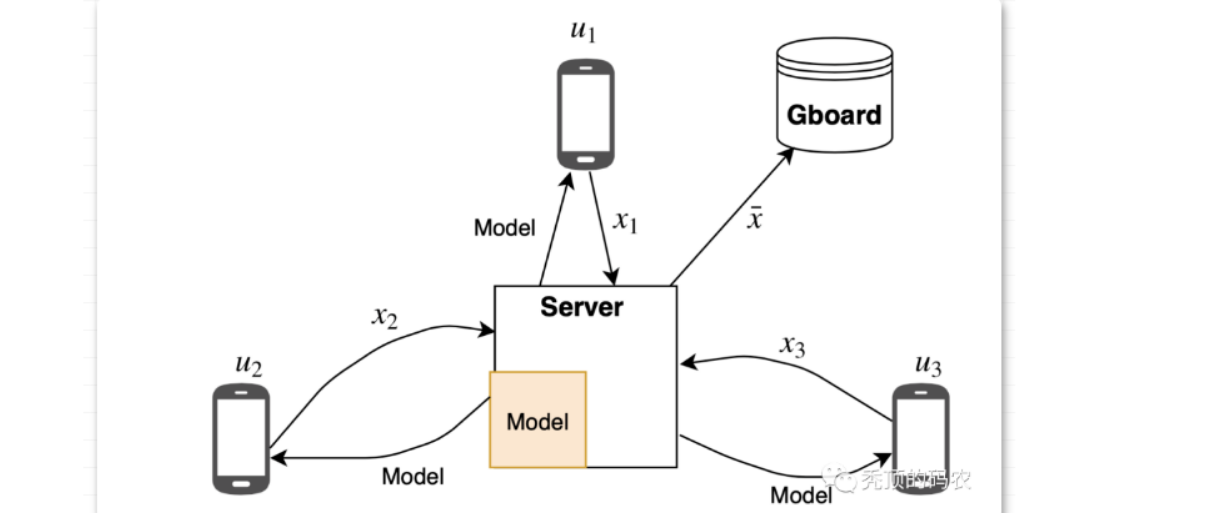
以下是安全聚合协议的初步过程:
首先,安全地聚合用户数据向量的第一次尝试涉及到每对用户 u, v,用户 u < v 同意一个秘密的总顺序,这个秘密被记为 su,v。每个用户用他们与所有其他用户构建的秘密蒙蔽了他们的输入值 xu。如果 u 将 su,v 加到 xu 上,v 从 xv 中减去它,那么当它们的向量相加时,掩码就会被取消,但它们的实际输入不会显示出来。形式上,每个用户的盲值是:
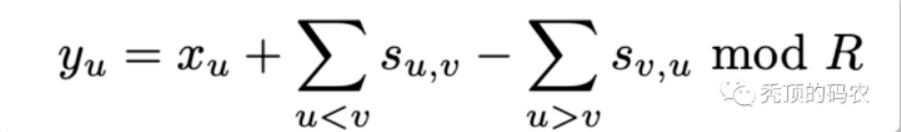
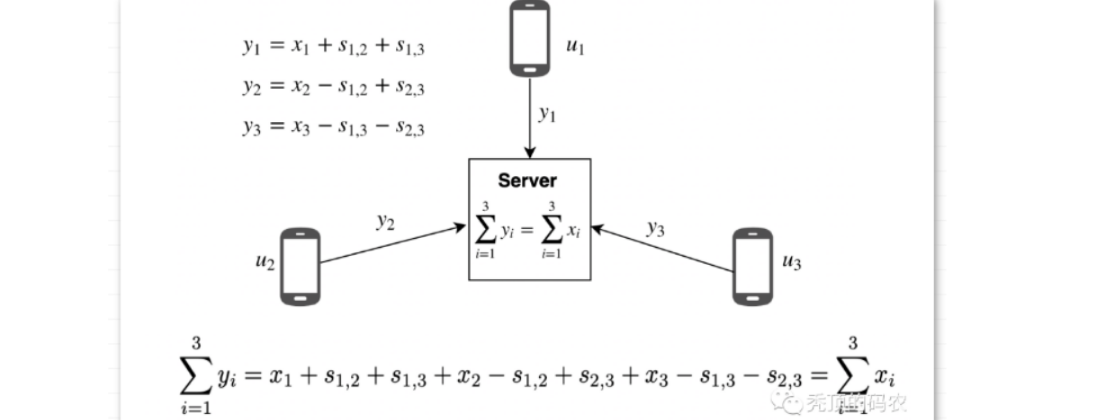
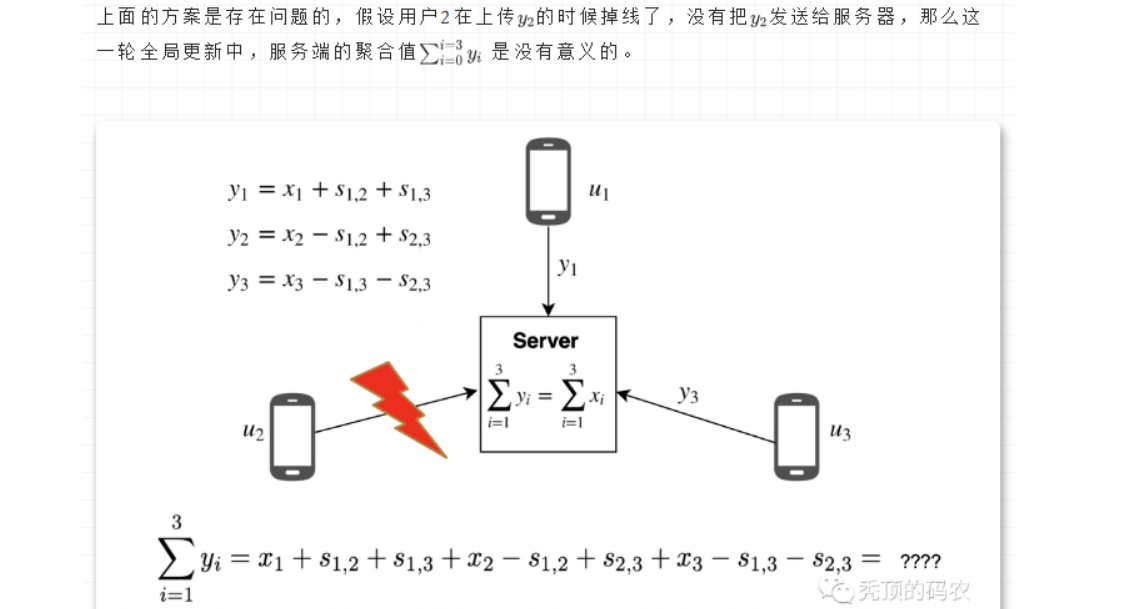
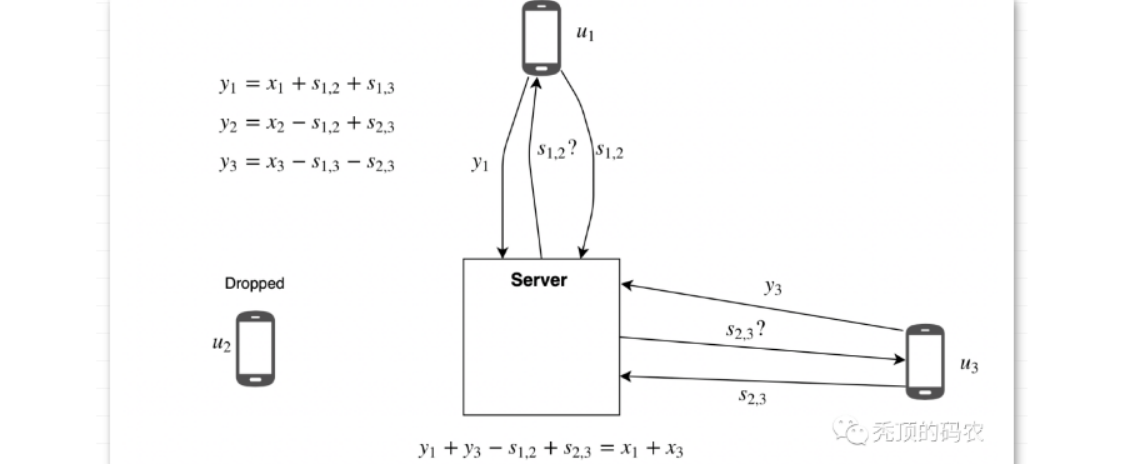
所以,在有用户掉线的时候,存在聚合时效的情况。所以考虑恢复方案,比如用户2掉线的时候,进行恢复阶段的处理,对于用户2的添加的扰动值 s1,2 ,s2,3 来说,用户1和用户3是知道的,所以服务器只要询问用户1和用户3,获取相应的扰动值,就可以剔除影响,完成聚合。
然而,延迟的通信可能会导致服务器认为某个用户被删除了,从而可以从所有其他用户那里恢复他们的机密。但是如果是网络延迟,将导致服务器能够在收到用户的秘密后解密他们的个人信息。针对这个问题,可以再做改进,采用双掩码机制,即使用两个随机数,并且加入秘密分享的机制。
- 为用户 u 引入另外一个随机数 bu。所有的 bu 和 sx,x 均使用秘密分享的方式分享给其他用户,在恢复阶段,至少 t 个用户才能恢复一个秘密。
- 在聚合阶段
- 如果用户 u 掉线,只聚合第一个分享的随机数 sx,x ;
- 如果用户 u 不掉线,则聚合两个随机数 bu 和 sx,x ;
— — 更完整的安全聚合协议?
— — 除了 “秘密分享” 和 “DH密钥交换”,还需要借助 “认证加密” 、“伪随机数生成器” 和 “数字签名”!





还有其他更多的安全聚合协议,详情可参考: 联邦学习安全聚合:基于安全多方计算的经典方案
2023年10月份新开了一个GitHub账号,里面已放了一些密码学,隐私计算电子书资料了,之后会整理一些我做过的、或是我觉得不错的论文复现、代码项目也放上去,欢迎一起交流!Ataraxia-github