ICM B 题:光伏发电 完整资料在文末获取
该题目出题的难度与方向都与美赛 ICM 的题型高度相似,将本次竞赛当做美赛的 练手赛,个人认为是非常合适的一种选择。同时 28 号就可以出成绩,也可以在美赛前 实现查漏补缺,提前预祝大家比赛顺利,美赛都可以取得好成绩。下面,我们开始详细 的解读一下本次竞赛的 B 题。
B 题本次的难度远低于 A 题,这势必会导致 B 题的选题认识会比 A 题多很多,但 是比赛的最终成绩是获奖率。无论都是每个赛题选择人数多少,每个赛题获奖的人数都 是 50%,因此不存在选择人少的赛题好获奖这种情况,都是比例获奖。我可以保证跟着 本人的思路,获奖是没有任何问题的,至于能获得什么奖项,主要还是看对于每一问选 择的模型复杂度的高低以及队伍可视化的能力。基本每一问都会给两三种实现方式,上 中下三种实现方式,即使最简单的方式,也是可以保证获奖的。但是很难保证获得很好 的奖项。
数据收集
在正式开始题目之前必须明白,对于美赛这种 ICM 题目,很大程度的上的难点并不在 于题目本身而是,需要我们自行收集数据,由于大家之前没有自己找过数据,所以这一关会 难倒很多很多的人群。本团队会为大家收集一套完整的数据,供大家选择。至于选择这套数 据集中的何种数据,就因队伍而已,因此一千个队伍可能有一千种选择方式。所以,从一开 始的选择数据开始,大家就会各不相同。因此,无需担心查重率过高的问题。
本文目前,已经为大家收集了问题一和问题四的数据,如下所示。稍后也将为大家专门 收集关于光伏发电相关的数据,完成对于问题三四的数据收集。
(注释:大家如果需要其他,数据集中没有的数据,欢迎大家留言,我们会尽力帮大家 收集)
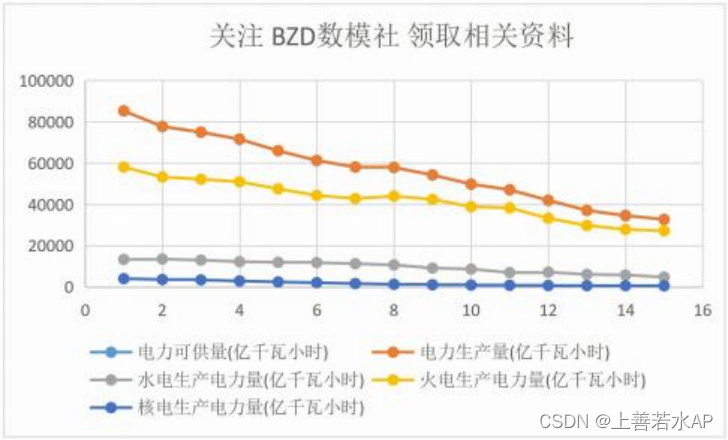
问题一、中国的电力供应与许多因素相互作用。请研究它们之间的关系,并预测中国从 2024 年到 2060 年电力供应的发展趋势。
问题一本质是一个问题,两个步骤,一进行相关性分析,二进行预测。需要注意的是本 题的主体是电力供应,不是本文的主旨光伏发电。因此,我们只需要研究电力供应就可以。 首先,我们需要选择合适的指标,对于电力供应有很多相关的指标,这里每个人选择的都不 会一模一样,因此这也是大家论文不用的地方。我下面给大家一个大致的方向,首先就是历 史的电力供应数据(该数据在国家统计局收集到,在 1.5 更新中,文件名为‘水电、火电、 核电、风电生产量 ’),其次就是一些与电力供应相关的数据经济数据(GDP、人口增长等)、 工业化进程数据、 电力结构(煤炭、天然气、可再生能 源等)、经济增长率、城市化率、家庭 消费水平等(以上大部分数据都可以在 1.5 更新中,文件名为“1269 个中国宏观指标”找到) 后续也会补充一些这方面的宏观数据。
确定收集到的数据指标后,就是整理数据。建议大家可以绘制几张折线图(图一这种的) 等,完成对收集到数据的描述,对于数据预处理,包括缺失值处理、异常值处理、数据降维 等。异常值处理,首先判定数据分布方式,对于正态分布的数据利用 3 西格玛原则判定异常 值;非正态分布的数据利用箱型图判定异常值。对于判定的异常值进行剔除处理,变为缺失 值。
对缺失值,两部分既有数据收集本身所有的,还有就是异常值处理带来的异常值。这里 比较建议大家选择线性插值(平均值插值、克里斯插值等都是可以的)。对于较高维度的数 据,还可以选择就降维处理。
处理完数据后,需要对进行第一小问的回答,即判定关系。这属于关联分析模型,根据 变量的个数不用刻意直接选择不用的方式。这里,个人比较建议直接使用 person进行相关 性分析即可。
第二小问,预测模型可以根据自行收集的数据的需求进行选择,数模常见的预测模型见 下表。个人比较推荐的三种预测模型,分别为
方案一:y 与多个 x 建立多元回归模型
使用该方法的原因,是之前已经完成了多个 x 之间的分析,可以直接顺理成章的建 立多元回归模型。这种方式比较顺滑,比较容易懂,但是预测精度会比较低。
方案二:单一预测模型 例如 LSTM 、BP 、随机森林可能会比较合适
使用该模型,复杂度比方案一要好一些,精度也很好。模型整体度没有方案一好
方案三:建立加权平均预测( arima 、lstm 、多元回归模型) ,个人最喜欢的模型,模型复 杂度很高,但是主要问题就是篇幅很长,可能 25 页的篇幅限制会超出限制。有点自卖自夸 的嫌疑,但是这个就是我们保奖模版的预测模版。该模型也是本次我论文写作的模型,下面 是其原理图,会在更新的视频里面进行说明,看不懂的,只能使用方案一、二。点击链接加入群聊【2024华数杯数学建模资料总群】: