Apache Spark是一个强大的开源分布式计算系统,专为大规模数据处理而设计。而DataBricks则提供了一个基于云的环境,使得在Spark上处理数据变得更加高效和便捷。本文将介绍如何在DataBricks平台上使用Spark轻松处理大数据。DataBricks是一个基于云的大数据处理平台,它提供了一个完整的环境,用于运行和管理Spark应用程序。DataBricks的界面用户友好,支持多种数据源,并提供了丰富的数据可视化工具。此外,DataBricks还提供了协作功能,使团队成员可以共享和协作处理数据。
如何用免费资源启动Azure DataBricks 工作区,请参照之前的一个教程:
利用 Azure Data Bricks的免费资源学习云上大数据-CSDN博客
一、使用以下 PySpark 代码将数据加载到数据帧
CSV 文件的第一行包含列名,Spark 能够根据每一列所包含的数据推断出其数据类型。 还可以指定数据的显式架构,这在数据文件中不包含列名时很有用,例如此 CSV 示例:

1、下载示例文件:
样本数据下载地址:【免费】AzureDataBricks-sample-Data资源-CSDN文库
Notebook试验文件下载地址:【免费】DataBricks-Python-Sample.ipynb资源-CSDN文库
2、上传同样本数据文件到DataBricks DBFS系统中
在Azure DataBricks新建笔记本,然后选择上传数据

将样本数据Products.csv 拖动上传到这里

3、上传notebook示例试验文件(此步骤可不做跳过)

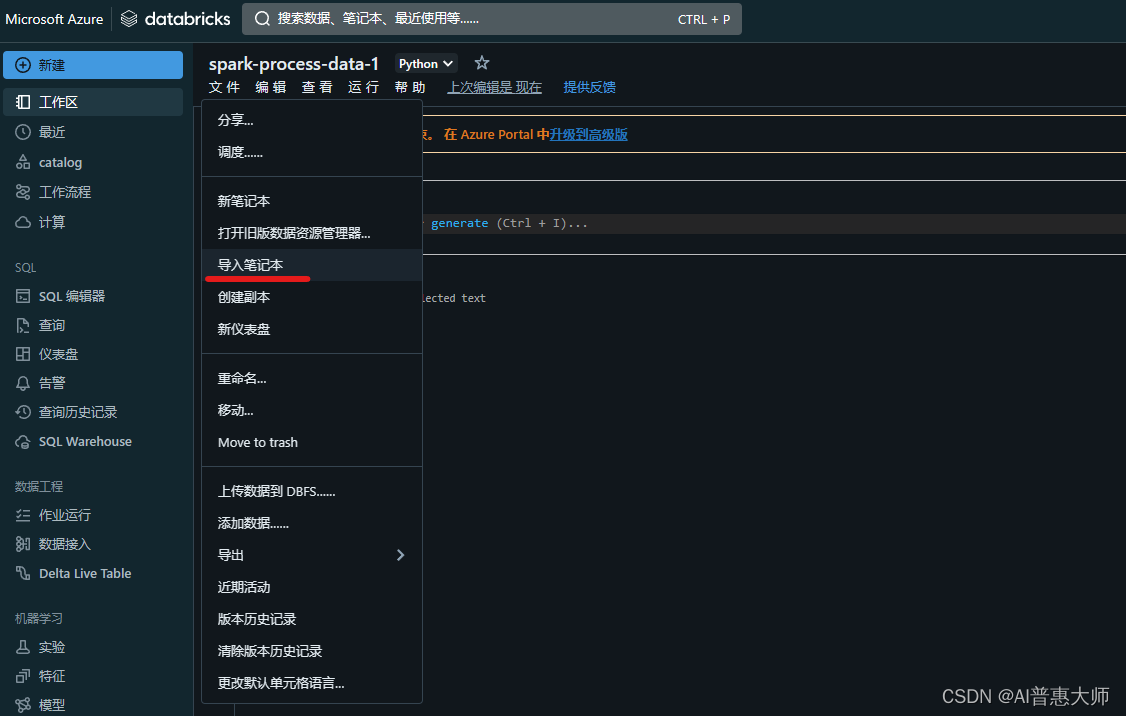
如下图:将刚刚下载的DataBricks-Python-Sample.ipynb拖动上传

4、加载数据到数据帧
加载数据后,可以直接在笔记本粘贴下面命令,逐步复制来执行看结果
# 请用你的azure portal 登录的邮箱替换掉 azure-user@outlook.com
df = spark.read.format("csv").option("header", "true").load("dbfs:/FileStore/shared_uploads/azure-user@outlook.com/products.csv")
执行结果:

二、浏览原始表中的数据
display(df1)执行结果:

可以使用以下 PySpark 代码将数据加载到数据帧中并显示前 10 行:
# 请用你的azure portal 登录的邮箱替换掉 azure-user@outlook.com
df = spark.read.load('dbfs:/FileStore/shared_uploads/azure-user@outlook.com/products.csv',
format='csv',
header=True
)
display(df.limit(10))执行结果:

三、指定Spark数据帧架构
以下 PySpark 示例演示了如何指定要从名为 product-data.csv 的文件加载的数据帧的架构
# 请用你的Azure 登录用户邮箱替换 azure-user@outlook.com
from pyspark.sql.types import *
from pyspark.sql.functions import *
productSchema = StructType([
StructField("ProductID", IntegerType()),
StructField("ProductName", StringType()),
StructField("Category", StringType()),
StructField("ListPrice", FloatType())
])
df = spark.read.load('dbfs:/FileStore/shared_uploads/azure-user@outlook.com/products.csv',
format='csv',
schema=productSchema,
header=False)
display(df.limit(10))执行结果:

四、调用sparkAPI 对数据帧进行筛选和分组
pricelist_df = df.select("ProductID", "ListPrice")
将多个方法“链接”在一起来执行一系列操作,从而生成转换后的数据帧。 例如,此示例代码将 select 和 where 方法链接在一起来创建新的数据帧,其中包含用于“山地自行车”或“公路自行车”类别的产品的 ProductName 和 ListPrice 列:
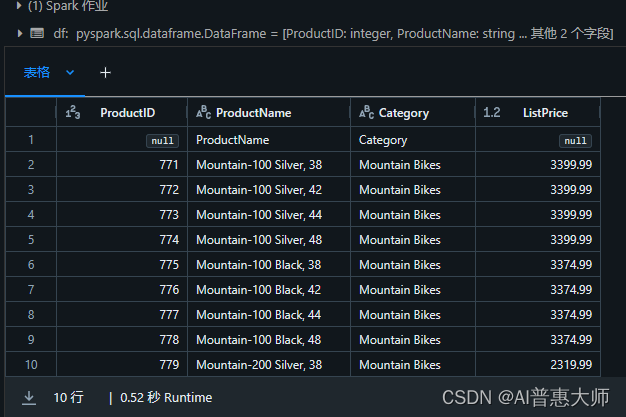
bikes_df = df.select("ProductName", "ListPrice").where((df["Category"]=="Mountain Bikes") | (df["Category"]=="Road Bikes"))
display(bikes_df)执行结果:
要对数据进行分组和聚合,可以使用 groupBy 方法和聚合函数。 例如,以下 PySpark 代码计算每个类别的产品数量:
counts_df = df.select("ProductID", "Category").groupBy("Category").count()
display(counts_df)执行结果:

五、在 Spark 目录中创建数据库对象
1、可以使用数据帧的 saveAsTable 方法将其保存为表。
2、可以使用 spark.catalog.createTable 方法创建空表。 表是元数据结构,该结构会将其基础数据存储在与目录关联的存储位置。 删除表也会删除其基础数据。
3、 可以使用 spark.catalog.createExternalTable 方法创建外部表。 外部表定义目录中的元数据,但从外部存储位置获取其基础数据;通常是数据湖中的文件夹。 删除外部表不会删除基础数据。
#1
df.write.saveAsTable("products1")
#2
df.createOrReplaceTempView("products2")六、用sql语句进行查询
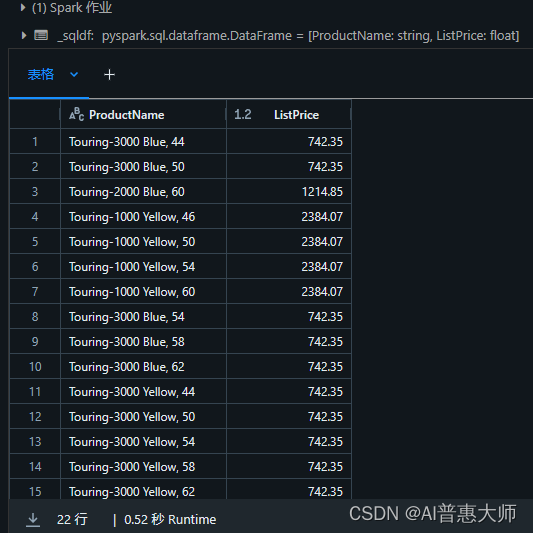
1、直接用SQL语句进行查询
%sql
SELECT ProductName, ListPrice
FROM products1
WHERE Category = 'Touring Bikes';执行结果:
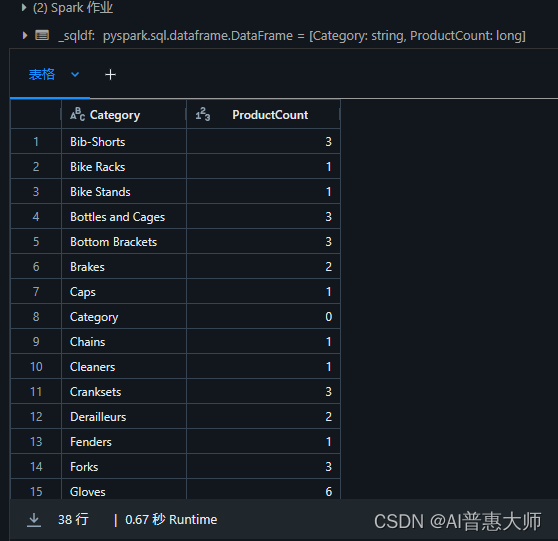
2、用sql 语句汇总查询
%sql
SELECT Category, COUNT(ProductID) AS ProductCount
FROM products1
GROUP BY Category
ORDER BY Category执行结果:
3、调用spark.sql 查询
bikes_df = spark.sql("SELECT ProductID, ProductName, ListPrice \
FROM products \
WHERE Category IN ('Mountain Bikes', 'Road Bikes')")
display(bikes_df)执行结果: