引言
上篇文章加速推理的KV缓存技术,本文介绍让我们可以得到更好的BLEU分数的解码技术——束搜索。
束搜索
我们之前生成翻译结果的时候,使用的是最简单的贪心搜索,即每次选择概率最大的,但是每次生成都选择概率最大的并不一定代表最终的结果是最好的。
我们来看个简单的例子,假设词表中共4个单词:["你","好","<bos>","<eos>"],每个时间步预测的搜索树如下:
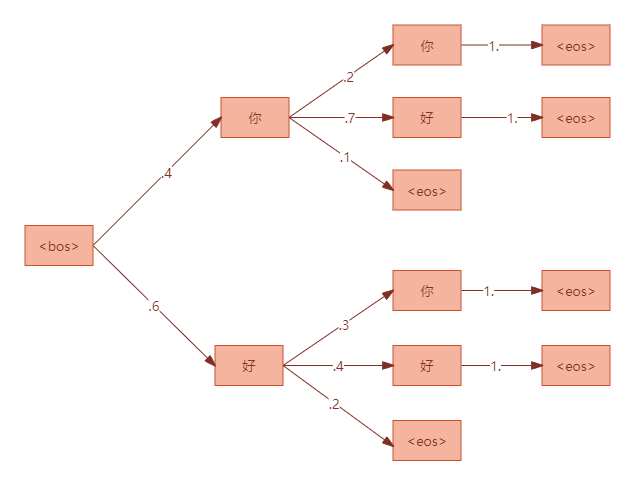
上面是一个极端的例子,假设我们想要生成的是"你好"(生成后去掉开始和结束标记),而如果用贪心搜索它的选择是:
- 第1步,概率最大的是
p(好|<bos>)=0.6; - 第2步,概率最大的是
p(好|<bos>好)=0.4; - 第3步,直接到达结束标记;
因此得到的整体概率是0.6*0.4=0.24,实际上我们想要的输出"你好"它的概率更高:0.4*0.7=0.28。
而束搜索的话,它维护K条概率最大的搜索路径,这里的K就是束搜索的宽度,假设K=2。
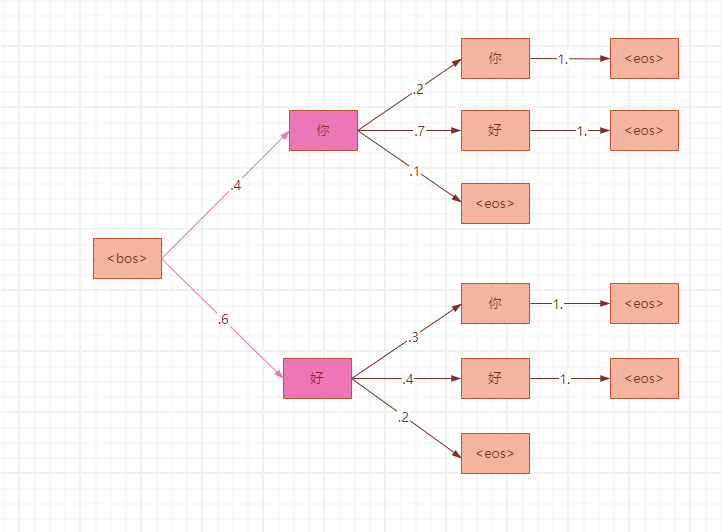
第1步,概率最大的2条路径是:p(你|<bos>)=0.4和p(好|<bos>)=0.6;
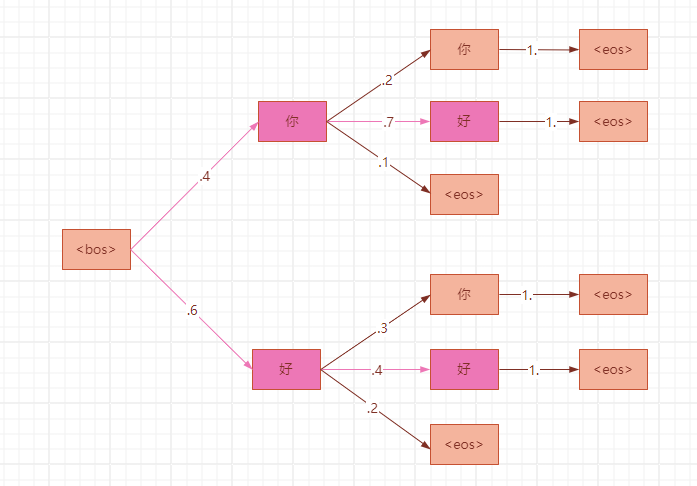
第2步,概率最大的2条路径是:p(好|<bos>你)=0.28和p(好|<bos>好)=0.24;
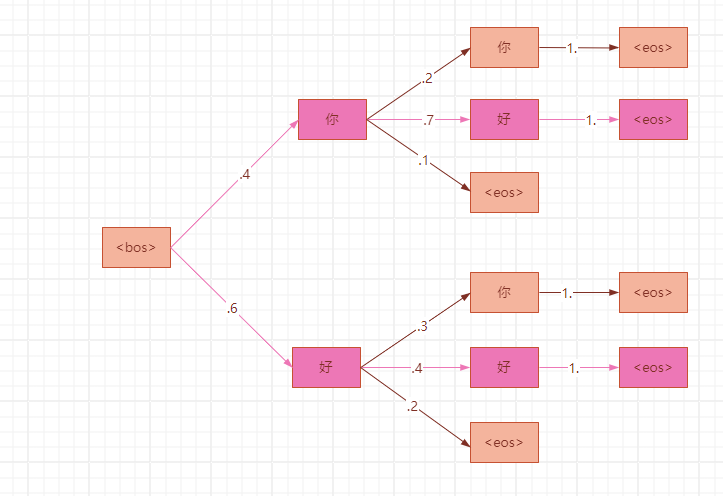
第3步,概率最大的2条路径是:p(<eos>|<bos>你好)=0.28和p(<eos>|<bos>好好)=0.24;
此时都达到了结束标记,最后束搜索比较这两条路径,选择概率最大的:“你好”。
这个例子有点简单,不过能看出来束搜索思想和缺点。
显然束的宽度越大,生成效率越低。以宽度2为例,相当于要输入模型两次才能得到我们想要的结果。因此如何能在批次内进行束搜索是非常重要的。
下面我们参考HuggingFace的源码来实现批次束搜索。
首先定义一个管理BeamSearch假设的类,假设可以理解为候选序列。
class BeamHypotheses:
def __init__(
self,
num_beams: int,
max_length: int,
length_penalty: float,
early_stopping: bool,
):
self.max_length = max_length - 1 # 忽略BOS标记
self.length_penalty = length_penalty # 长度惩罚
self.early_stopping = early_stopping
self.num_beams = num_beams # 宽度
self.beams = []
self.worst_score = 1e9 # 初始化一个非常大的值,用于比较和更新最差的分数,新加入的假设得分必然比它小。
def __len__(self):
return len(self.beams)
def add(self, hyp: torch.LongTensor, sum_logprobs: float) -> None:
"""
新增一个假设到列表中,并维护得分(概率)最高的num_beams个假设
"""
# 计算假设的分数,根据长度惩罚因子对分数进行调整。
# hyp.shape[-1]就是当前假设的长度,length_penalty是幂系数。
score = sum_logprobs / (hyp.shape[-1] ** self.length_penalty)
# 如果当前的假设不够或者当前假设计算的得分比假设列表中最差的要好
if len(self) < self.num_beams or score > self.worst_score:
# 将当前加上加入假设列表,通过得分和假设的元组形式
self.beams.append((score, hyp))
# 如果加入列表后导致超过最大要维护的假设数量
if len(self) > self.num_beams:
# 那么根据得分进行排序,按照升序,这里返回的是得分和索引
sorted_next_scores = sorted(
[(s, idx) for idx, (s, _) in enumerate(self.beams)]
)
# 移除排序第一即得分最小的假设,根据上面计算的索引
del self.beams[sorted_next_scores[0][1]]
# 更新最差的得分为排名第二的得分,排名第一的已经被干掉了
self.worst_score = sorted_next_scores[1][0]
else:
# 否则列表中的假设数量不够,则插入后只需要更新最差得分
self.worst_score = min(score, self.worst_score)
def is_done(self, best_sum_logprobs: float, cur_len: int) -> bool:
"""
If there are enough hypotheses and that none of the hypotheses being generated can become better than the worst
one in the heap, then we are done with this sentence.
"""
# 若当前生成的假设少于num_beams个则未完成
if len(self) < self.num_beams:
return False
# 如果大于等于num_beams个且开启了早停,则返回完成
elif self.early_stopping:
return True
else:
cur_score = best_sum_logprobs / cur_len**self.length_penalty
# 返回当前得分是否比最差的要好
ret = self.worst_score >= cur_score
return ret
注意这个logprob是概率的对数,因为概率的取值范围在0~1,概率取值越接近0,负的就越大;越接近1,负的就越小。概率等于1,则logprob=0。总体来说值越大表示概率越高,得分越好。
明白这一点,才好理解长度惩罚系数。首先默认情况下,惩罚系数等于1,即不惩罚,但是sum_logprobs会除以长度,用于对长度进行归一化。如果没有长度归一化,那么生成的序列越短就负的越少,就会造成束搜索倾向于生成短序列。
length_penalty作为长度惩罚幂系数,如果length_penalty<1,表示长度越长,分母越小,score负的就越多,从而倾向于生成更短的序列;反之倾向于生成更长的序列。
显然,批次内的一个样本就对应这样一个BeamHypotheses实例。
然后我们先来看生成时_beam_search的实现:
def _beam_search(
self,
src: Tensor,
src_mask: Tensor,
max_gen_len: int,
num_beams: int,
use_cache: bool,
keep_attentions: bool,
):
# memory (batch_size, seq_len, d_model) 首先还是计算出编码器的输出
memory = self.transformer.encode(src, src_mask)
# 获取批大小
batch_size = memory.size(0)
# 在维度0上复制num_beams次,变成 (batch_size * num_beams, seq_len, d_model)
memory = memory.repeat_interleave(num_beams, dim=0)
# 同理
src_mask = src_mask.repeat_interleave(num_beams, dim=0)
device = src.device
# batch_size * num_beams 批次内总共的束大小
batch_beam_size = memory.size(0)
# 初始化一个计算得分类实例
beam_scorer = BeamSearchScorer(
batch_size=batch_size,
max_length=max_gen_len,
num_beams=num_beams,
device=device,
)
# 初始化beam_scores为全零,记录过程中每个束的得分
beam_scores = torch.zeros(
(batch_size, num_beams), dtype=torch.float, device=device
)
# 将第一个束设成0,后面的设成-1e9。 这样可以确保只有第一个束的token被考虑,防止所有的束产生的结果是一样的。
beam_scores[:, 1:] = -1e9
# 拉平
beam_scores = beam_scores.view((batch_beam_size,))
# 初始化解码器输入为bos
decoder_inputs = (
torch.LongTensor(batch_beam_size, 1).fill_(self.bos_idx).to(device)
)
input_ids = decoder_inputs
# 用于kv缓存
past_key_values = None
tgt_mask = None
while True:
if not use_cache:
tgt_mask = self.generate_subsequent_mask(decoder_inputs.size(1), device)
outputs = self.transformer.decode(
input_ids,
memory,
tgt_mask=tgt_mask,
memory_mask=src_mask,
past_key_values=past_key_values,
use_cache=use_cache,
keep_attentions=keep_attentions,
)
# logits (batch_beam_size, seq_len, vocab_size)
logits = self.lm_head(outputs[0])
past_key_values = outputs[1]
# next_token_logits (batch_beam_size, vocab_size)
next_token_logits = logits[:, -1, :]
# next_token_scores (batch_beam_size, vocab_size)
# 计算当前预测的token的得分,先计算概率(softmax)再取对数变成得分。
next_token_scores = F.log_softmax(next_token_logits, dim=-1)
# next_token_scores (batch_beam_size, vocab_size)
# 与之前的得分相加,因为取了对数,原来相乘的变成了相加
next_token_scores = next_token_scores + beam_scores[:, None].expand_as(
next_token_scores
)
vocab_size = next_token_scores.shape[-1]
# 转换成 (batch_size, num_beams * vocab_size)的形状,将num_beams在vocab的维度上拉平(拼接),即batch内的每个样本包含的所有束进行一起对比
# vocab_size 乘上了num_beams,后续选择出来的索引很有可能超过vocab_size
next_token_scores = next_token_scores.view(
batch_size, num_beams * vocab_size
)
# next_token_scores (batch_size, 2 * num_beams)
# next_tokens (batch_size, 2 * num_beams)
# 每个样本选择topk个束得分(k=2*num_beams防止生成了eos过早地停止)
# 得到topk个束的得分以及对应的索引
next_token_scores, next_tokens = torch.topk(
next_token_scores,
2 * num_beams, # 防止生成了eos过早地停止
dim=1, # 在批次内所有束对应的维度
largest=True, # 最大的得分排在最前
sorted=True, # 进行排序
)
# next_indices next_tokens (batch_size, 2 * num_beams)
# 得到束的索引,即哪个束,也有可能topk都来自同一个束,然后由这些token继续延伸束的路径
next_indices = next_tokens // vocab_size
# 得到束中的索引,即来自哪个token
next_tokens = next_tokens % vocab_size
# 更新每个束的状态
beam_outputs = beam_scorer.process(
decoder_inputs,
next_token_scores,
next_tokens,
next_indices,
pad_token_id=self.pad_idx,
eos_token_id=self.eos_idx,
)
...
我们由此进入process方法,它是BeamSearchScorer的实例,从上面可以看到我们只有一个这样的实例。
class BeamSearchScorer:
def __init__(
self,
batch_size: int,
max_length: int,
num_beams: int,
device: torch.device,
length_penalty: float = 1.0,
do_early_stopping: bool = True,
num_beam_hyps_to_keep: int = 1,
):
"""
Args:
batch_size (int): Batch Size of `input_ids` for which beam search decoding is run in parallel.
max_length (int): The maximum length of the sequence to be generated.
num_beams (int): Number of beams for beam search.
device (torch.device): the device.
length_penalty (float, optional): Exponential penalty to the length. 1.0 means no penalty. Set to values < 1.0 in order to encourage the
model to generate shorter sequences, to a value > 1.0 in order to encourage the model to produce longer sequences. Defaults to 1.0.
do_early_stopping (bool, optional): Whether to stop the beam search when at least ``num_beams`` sentences are finished per batch or not. Defaults to True.
num_beam_hyps_to_keep (int, optional): The number of beam hypotheses that shall be returned upon calling. Defaults to 1.
"""
self.batch_size = batch_size
self.max_length = max_length
self.num_beams = num_beams
self.device = device
self.length_penalty = length_penalty
self.do_early_stopping = do_early_stopping
self.num_beam_hyps_to_keep = num_beam_hyps_to_keep
self._beam_hyps = [
BeamHypotheses(num_beams, max_length, length_penalty, do_early_stopping)
for _ in range(batch_size)
]
self._done = torch.tensor(
[False for _ in range(batch_size)], dtype=torch.bool, device=self.device
)
首先是初始化方法,传入的参数有批大小、最长长度、束个数、设备、长度惩罚系数、是否早停、每个样本返回的假设个数。
然后,定义了批大小个BeamHypotheses实例,用_beam_hyps保存。
最后初始化每个实例的完成为False。
接下就是我们关心的process方法:
def process(
self,
input_ids: torch.LongTensor, # 输入的ID
next_scores: torch.FloatTensor, # 当前每个束的得分
next_tokens: torch.LongTensor, # 当前束中对应的token
next_indices: torch.LongTensor, # 来自哪个束
pad_token_id: int,
eos_token_id: int,
) -> Tuple[torch.Tensor]:
# 获取输入序列的长度
cur_len = input_ids.shape[-1]
# 批大小
batch_size = len(self._beam_hyps)
assert batch_size == (input_ids.shape[0] // self.num_beams)
device = input_ids.device
# next_beam_scores预测token对应束的得分
next_beam_scores = torch.zeros(
(batch_size, self.num_beams), dtype=next_scores.dtype, device=device
)
# next_beam_tokens 当前步预测的token
next_beam_tokens = torch.zeros(
(batch_size, self.num_beams), dtype=next_tokens.dtype, device=device
)
# next_beam_indices 预测token所在束的下标
next_beam_indices = torch.zeros(
(batch_size, self.num_beams), dtype=next_indices.dtype, device=device
)
# 遍历批次内每个样本
for batch_idx, beam_hyp in enumerate(self._beam_hyps):
# 如果当前样本已经完成
if self._done[batch_idx]:
# 对应束路径得分设为0
next_beam_scores[batch_idx, :] = 0
# 对于已经完成的句子,它的下一个token是pad
next_beam_tokens[batch_idx, :] = pad_token_id
# 所在束路径的下标设为0
next_beam_indices[batch_idx, :] = 0
# 跳过剩下的代码,处理下一个样本
continue
# 当前样本的束索引
beam_idx = 0
for beam_token_rank, (next_token, next_score, next_index) in enumerate(
# 遍历批次内batch_idx对应的样本
zip(
next_tokens[batch_idx],
next_scores[batch_idx],
next_indices[batch_idx],
)
):
# 批次内束ID
batch_beam_idx = batch_idx * self.num_beams + next_index
# 如果当前预测的token为eos
if next_token.item() == eos_token_id:
is_beam_token_worse_than_top_num_beams = (
beam_token_rank >= self.num_beams
)
# 如果beam_token_rank大于等于num_beams,即不属于topk个束的token
if is_beam_token_worse_than_top_num_beams:
continue
# 增加到当前样本的假设中
beam_hyp.add(input_ids[batch_beam_idx].clone(), next_score.item())
else:
# 不为eos
# 更新当前束(beam_idx)的得分、标记id以及束ID
next_beam_scores[batch_idx, beam_idx] = next_score
next_beam_tokens[batch_idx, beam_idx] = next_token
next_beam_indices[batch_idx, beam_idx] = batch_beam_idx
# 处理下一个束
beam_idx += 1
# 一旦处理完所有的束,则退出当前样本的循环
if beam_idx == self.num_beams:
break
# 更新当前样本是否生成结束,如果新的结果没有改善或已经记录为结束
self._done[batch_idx] = self._done[batch_idx] or beam_hyp.is_done(
next_scores[batch_idx].max().item(), cur_len
)
# 返回更新后的结果
return UserDict(
{
"next_beam_scores": next_beam_scores.view(-1),
"next_beam_tokens": next_beam_tokens.view(-1),
"next_beam_indices": next_beam_indices.view(-1),
}
)
我们再次回到生成时_beam_search的方法:
while True:
...
next_token_scores, next_tokens = torch.topk(
next_token_scores,
2 * num_beams, # prevent finishing beam search with eos
dim=1,
largest=True,
sorted=True,
)
# next_tokens (batch_size, 2 * num_beams)
next_indices = next_tokens // vocab_size
next_tokens = next_tokens % vocab_size
beam_outputs = beam_scorer.process(
decoder_inputs,
next_token_scores,
next_tokens,
next_indices,
pad_token_id=self.pad_idx,
eos_token_id=self.eos_idx,
)
# beam_scores (2 * num_beams)
beam_scores = beam_outputs["next_beam_scores"]
# beam_next_tokens (2 * num_beams)
beam_next_tokens = beam_outputs["next_beam_tokens"]
# beam_idx (2 * num_beams)
beam_idx = beam_outputs["next_beam_indices"]
# decoder_inputs (2 * num_beams, cur_seq_len)
decoder_inputs = torch.cat(
[decoder_inputs[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1
)
# 如果所有的束都结束了,或者达到了生成长度限制
if beam_scorer.is_done or decoder_inputs.shape[-1] >= max_gen_len:
break
if use_cache:
input_ids = beam_next_tokens.unsqueeze(-1)
past_key_values = self._reorder_cache(past_key_values, beam_idx)
else:
input_ids = decoder_inputs
return beam_scorer.finalize(
decoder_inputs,
beam_scores,
pad_token_id=self.pad_idx,
eos_token_id=self.eos_idx,
)
经过process方法后得到更新后的三元组,然后拼接最新生成的token到decoder_inputs中。重复这个过程,直到生成的长度达到最大长度或者所有的束已经生成完毕。
最后进入finalize方法:
def finalize(
self,
input_ids: torch.LongTensor,
final_beam_scores: torch.FloatTensor,
pad_token_id: int,
eos_token_id: int,
) -> torch.LongTensor:
batch_size = len(self._beam_hyps)
# 可能有些束还未生成结束,但由于已经达到了最大长度,而提前终止,这些标记和得分未被加入到假设列表中,这里进行对它们进行处理
for batch_idx, beam_hyp in enumerate(self._beam_hyps):
# 如果该样本已经结束了就没必要处理
if self._done[batch_idx]:
continue
# 遍历样本内的每个束
for beam_id in range(self.num_beams):
# 获取束ID
batch_beam_idx = batch_idx * self.num_beams + beam_id
# 得到最终得分
final_score = final_beam_scores[batch_beam_idx].item()
# 以及对应的标记ID
final_tokens = input_ids[batch_beam_idx]
# 最后的标记和最后的得分加入到束中
beam_hyp.add(final_tokens, final_score)
# 选择最好的假设
sent_lengths = input_ids.new(batch_size * self.num_beam_hyps_to_keep)
best = []
# 假设出最佳假设
for i, beam_hyp in enumerate(self._beam_hyps):
# 根据得分进行排序,排序的是beams属性,它的score索引0位置
sorted_hyps = sorted(beam_hyp.beams, key=lambda x: x[0])
# num_beam_hyps_to_keep要返回的假设个数
for j in range(self.num_beam_hyps_to_keep):
best_hyp = sorted_hyps.pop()[1]
# 更新最佳假设的长度
sent_lengths[self.num_beam_hyps_to_keep * i + j] = len(best_hyp)
best.append(best_hyp)
# 准备增加eos标记
sent_max_len = min(sent_lengths.max().item() + 1, self.max_length)
decoded = input_ids.new(batch_size * self.num_beam_hyps_to_keep, sent_max_len)
# 先全部填充PAD
if sent_lengths.min().item() != sent_lengths.max().item():
decoded.fill_(pad_token_id)
for i, hypo in enumerate(best):
# 将假设覆盖前sent_lengths[i]个元素,后续的元素就是PAD
decoded[i, : sent_lengths[i]] = hypo
if sent_lengths[i] < self.max_length:
# 如果假设的长度未达到最大长度,在适当位置插入eos
decoded[i, sent_lengths[i]] = eos_token_id
return decoded
可以看到该方法主要进行后处理,以及每个样本返回num_beam_hyps_to_keep个束路径。
最后我们看在训练时应用(宽度=5)束搜索+KV cache来计算bleu分数,训练过程以及最后在测试集上的表现如何。
Number of GPUs used: 3
Running DDP on rank 0.
source tokenizer size: 32000
target tokenizer size: 32000
Loads cached train dataframe.
Loads cached dev dataframe.
The model has 93255680 trainable parameters
begin train with arguments: {'d_model': 512, 'n_heads': 8, 'num_encoder_layers': 6, 'num_decoder_layers': 6, 'd_ff': 2048, 'dropout': 0.1, 'max_positions': 5000, 'source_vocab_size': 32000, 'target_vocab_size': 32000, 'attention_bias': False, 'pad_idx': 0, 'dataset_path': 'nlp-in-action/transformers/transformer/data/wmt', 'src_tokenizer_file': 'nlp-in-action/transformers/transformer/model_storage/source.model', 'tgt_tokenizer_path': 'nlp-in-action/transformers/transformer/model_storage/target.model', 'model_save_path': 'nlp-in-action/transformers/transformer/model_storage/best_transformer.pt', 'dataframe_file': 'dataframe.{}.pkl', 'use_dataframe_cache': True, 'cuda': True, 'num_epochs': 40, 'train_batch_size': 32, 'eval_batch_size': 32, 'gradient_accumulation_steps': 1, 'grad_clipping': 0, 'betas': (0.9, 0.98), 'eps': 1e-09, 'label_smoothing': 0, 'warmup_steps': 4000, 'warmup_factor': 0.5, 'only_test': True, 'max_gen_len': 60, 'generation_mode': 'beam_search', 'num_beams': 5, 'use_wandb': True, 'patient': 5, 'calc_bleu_during_train': True, 'use_kv_cache': True}
total train steps: 73760
0%| | 0/1844 [00:00<?, ?it/s]Running DDP on rank 1.
0%| | 0/1844 [00:00<?, ?it/s]Running DDP on rank 2.
[GPU2] TRAIN loss=6.537506, learning rate=0.0001612: 100%|██████████| 1844/1844 [03:57<00:00, 7.77it/s]
[GPU1] TRAIN loss=7.091136, learning rate=0.0001612: 100%|██████████| 1844/1844 [03:57<00:00, 7.77it/s]
[GPU0] TRAIN loss=7.040263, learning rate=0.0001612: 100%|██████████| 1844/1844 [03:57<00:00, 7.77it/s]
0%| | 0/264 [00:00<?, ?it/s]
| ID | GPU | MEM |
------------------
| 0 | 0% | 22% |
| 1 | 82% | 80% |
| 2 | 82% | 73% |
| 3 | 68% | 71% |
begin evaluate
100%|██████████| 264/264 [00:07<00:00, 35.79it/s]
100%|██████████| 264/264 [00:07<00:00, 35.77it/s]
89%|████████▊ | 234/264 [00:07<00:00, 36.40it/s]calculate bleu score for dev dataset
100%|██████████| 264/264 [00:08<00:00, 31.98it/s]
100%|██████████| 264/264 [05:08<00:00, 1.17s/it]
100%|██████████| 264/264 [05:19<00:00, 1.21s/it]
100%|██████████| 264/264 [05:22<00:00, 1.22s/it]
[GPU2] end of epoch 1 [ 580s]| train loss: 8.0693 | valid loss: 7.1201 | valid bleu_score 0.44
[GPU1] end of epoch 1 [ 567s]| train loss: 8.0779 | valid loss: 7.1337 | valid bleu_score 0.41
[GPU0] end of epoch 1 [ 568s]| train loss: 8.0677 | valid loss: 7.1127 | valid bleu_score 0.40
Save model with best bleu score :0.40
[GPU0] end of epoch 2 [ 520s]| train loss: 6.5043 | valid loss: 5.8464 | valid bleu_score 6.92
Save model with best bleu score :6.92
[GPU0] end of epoch 3 [ 503s]| train loss: 5.2821 | valid loss: 4.6888 | valid bleu_score 17.73
Save model with best bleu score :17.73
[GPU0] end of epoch 4 [ 498s]| train loss: 4.3038 | valid loss: 4.1166 | valid bleu_score 22.75
Save model with best bleu score :22.75
[GPU0] end of epoch 5 [ 491s]| train loss: 3.7260 | valid loss: 3.8295 | valid bleu_score 24.64
Save model with best bleu score :24.64
[GPU0] end of epoch 6 [ 487s]| train loss: 3.3333 | valid loss: 3.6786 | valid bleu_score 26.01
Save model with best bleu score :26.01
[GPU0] end of epoch 7 [ 484s]| train loss: 3.0398 | valid loss: 3.6040 | valid bleu_score 26.65
Save model with best bleu score :26.65
[GPU0] end of epoch 8 [ 479s]| train loss: 2.8061 | valid loss: 3.5674 | valid bleu_score 27.27
Save model with best bleu score :27.27
[GPU0] end of epoch 9 [ 471s]| train loss: 2.6083 | valid loss: 3.5461 | valid bleu_score 27.63
Save model with best bleu score :27.63
[GPU0] end of epoch 10 [ 469s]| train loss: 2.4357 | valid loss: 3.5609 | valid bleu_score 27.68
Save model with best bleu score :27.68
[GPU0] end of epoch 11 [ 471s]| train loss: 2.2854 | valid loss: 3.5788 | valid bleu_score 27.89
Save model with best bleu score :27.89
[GPU0] end of epoch 12 [ 474s]| train loss: 2.1497 | valid loss: 3.6098 | valid bleu_score 27.81
[GPU0] end of epoch 13 [ 476s]| train loss: 2.0273 | valid loss: 3.6379 | valid bleu_score 27.86
[GPU0] end of epoch 14 [ 479s]| train loss: 1.9142 | valid loss: 3.6808 | valid bleu_score 27.72
[GPU0] end of epoch 15 [ 476s]| train loss: 1.8119 | valid loss: 3.7120 | valid bleu_score 27.64
[GPU0] end of epoch 16 [ 477s]| train loss: 1.7181 | valid loss: 3.7535 | valid bleu_score 27.64
stop from early stopping.
wandb: Run history:
wandb: train_loss █▆▅▄▃▃▂▂▂▂▂▁▁▁▁▁
wandb: valid_bleu_score ▁▃▅▇▇███████████
wandb: valid_loss █▆▃▂▂▁▁▁▁▁▁▁▁▁▁▁
wandb:
wandb: Run summary:
wandb: train_loss 1.71805
wandb: valid_bleu_score 27.64178
wandb: valid_loss 3.75346
wandb:
这次最佳的验证集得分为27.89,继续在测试集上测试:
total train steps: 221200
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1580/1580 [22:55<00:00, 1.15it/s]
Test bleu score: 27.75
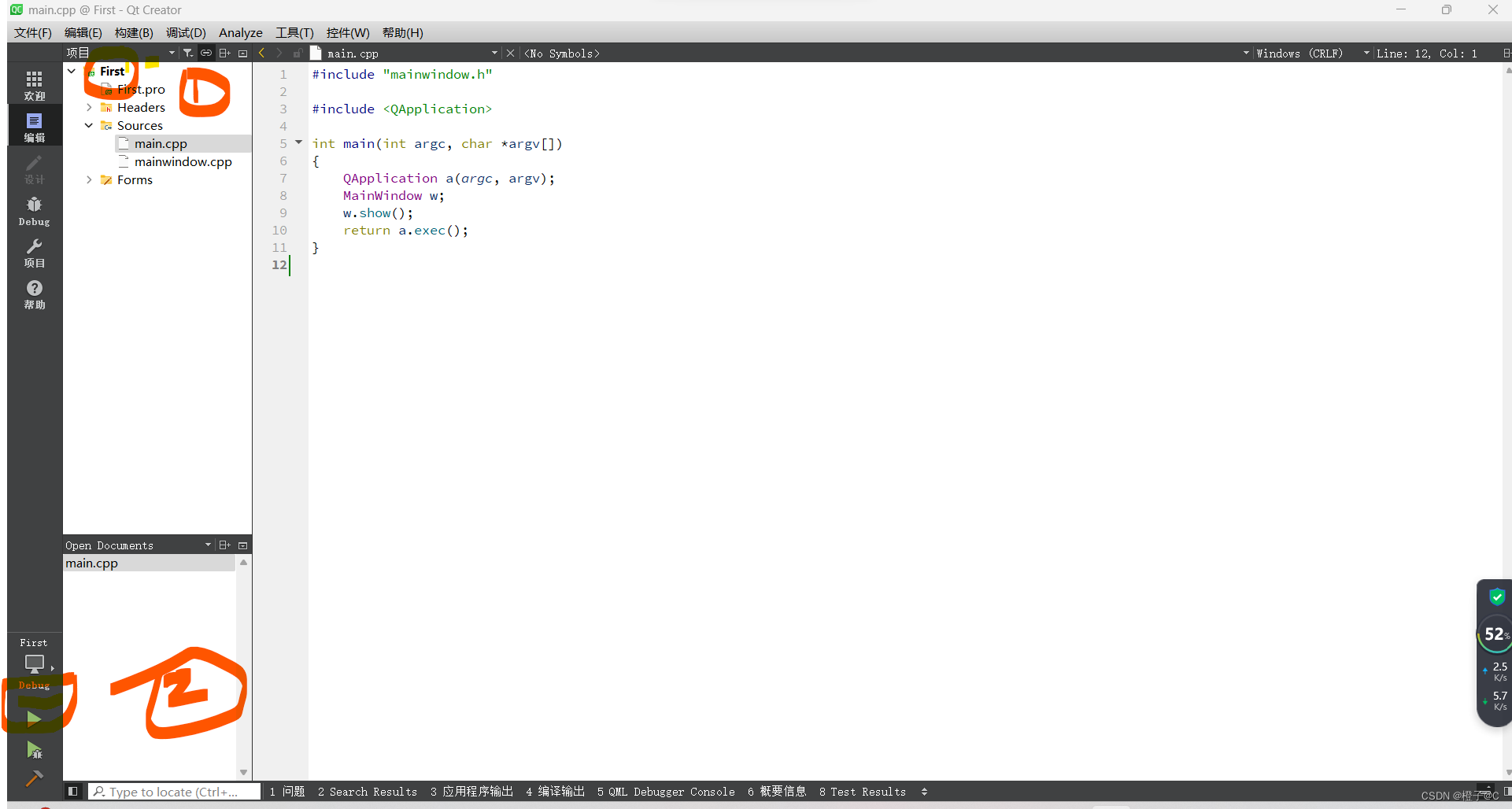
得到当前最佳得分为27.75,最佳模型权重链接:https://pan.baidu.com/s/1Zk20SozUIndC2XFELACd5g 提取码:l6oz
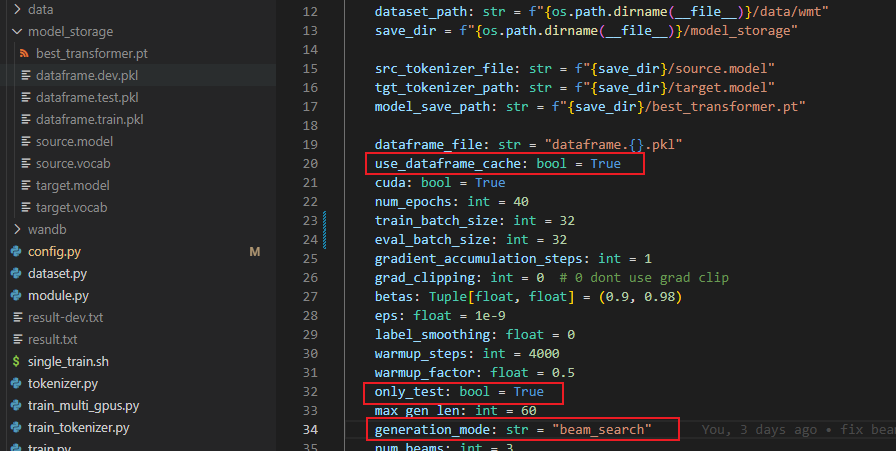
下载下来只要解压到当前目录即可,确保上图的三个红框内的配置,可以直接运行验证。
一些问题
Mask的作用
PAD mask & Subsequent mask => Target mask
[[1, 1, 1, 0, 0, 0]] & [[1, 0, 0, 0, 0, 0]] => [[1, 0, 0, 0, 0, 0]]
[[1, 1, 1, 0, 0, 0]] & [[1, 1, 0, 0, 0, 0]] => [[1, 1, 0, 0, 0, 0]]
[[1, 1, 1, 0, 0, 0]] & [[1, 1, 1, 0, 0, 0]] => [[1, 1, 1, 0, 0, 0]]
[[1, 1, 1, 0, 0, 0]] & [[1, 1, 1, 1, 0, 0]] => [[1, 1, 1, 0, 0, 0]]
[[1, 1, 1, 0, 0, 0]] & [[1, 1, 1, 1, 1, 0]] => [[1, 1, 1, 0, 0, 0]]
[[1, 1, 1, 1, 1, 1]] & [[1, 1, 1, 1, 1, 1]] => [[1, 1, 1, 1, 1, 1]]
这里说的是Transformer中的掩码矩阵,不要和BERT中的<mask>混淆起来,如上所示。Mask有两个作用:
- 防止注意到填充Token;
- 防止信息泄露;
对应有填充Mask和子序列Mask。
训练阶段采用Teacher force的思想,输入序列和目标序列已知,输入和目标序列中样本的长度不一,因此需要填充到某一个统一长度,我们本文采用的是填充到批次内最大长度。
- Encoder Attention Mask:指作用于编码器多头注意力的Mask,编码器的Mask唯一的作用就是防止计算(注意到)填充Token,会影响性能;
- Decoder Self-attention Mask:指作用于解码器自注意力的Mask,也就是解码器Block中的第一个多头注意力,它其实就是一个下三角矩阵的子序列Mask和填充Mask的结合,防止计算当前步Token时偷窥到未来的Token以及填充Token,解码器输入也会进行填充对齐。所以是填充Mask和子序列Mask的结合。
- Decoder Cross-attention Mask:交叉注意力的Key和Value来自编码器的输出,Query来自下层的输出,Query可以与整个Key进行交互计算注意力分数,但是不能与Key中填充位置的Token进行交互,所以实际上和编码器的Mask一致。
推理时需不需要Mask?
对于编码器来说,推理时是否需要Mask取决于输入中是否包含填充Token;
对于解码器来说,要分两种情况讨论:
- 解码器的交叉注意力,根据上面的讨论和编码器的Mask一致;
- 解码器的自注意力,这里就值得玩味了。因为在推理时每次只能预测一个Token,理论上不再需要一个Mask区防止信息泄露,因为未来的Token也不存在。但是经过实验对比,不加子序列Mask会有性能上的损失,BLEU分数会差几个点。一种可能的解释是如果不加这个子序列Mask,会导致训练和推理存在不一致性,比如可能影响了输入的分布,因此需要加上这个Mask。
注意力的时间和空间复杂度
缩放点积注意力的公式为:
Attention
=
Softmax
(
Q
K
T
d
)
V
\text{Attention} = \text{Softmax} \left(\frac{QK^T}{\sqrt{d}}\right) V
Attention=Softmax(dQKT)V
假设
Q
,
K
,
V
∈
R
N
×
d
Q,K,V \in \R ^{N \times d}
Q,K,V∈RN×d;
N
N
N是序列长度;
d
d
d是模型的隐藏层维度大小;
改公式其实包含了多个操作,我们分别来看。
第一个是 Q K T QK^T QKT,即 ( N × d ) (N \times d) (N×d)的矩阵乘 ( d × N ) (d \times N) (d×N)的矩阵,它的时间复杂度是 O ( N ⋅ d ⋅ N ) = O ( N 2 ⋅ d ) O(N\cdot d \cdot N) = O(N^2\cdot d) O(N⋅d⋅N)=O(N2⋅d)。
因为 Q K T QK^T QKT的维度是 ( N × N ) (N\times N) (N×N),所以它的空间复杂度是 O ( N 2 ) O(N^2) O(N2)。
A = np.random.rand(m, n) # (m,n)
B = np.random.rand(n, p) # (n,p)
C = np.zeros((m, p))
for i in range(m):
for j in range(p):
for k in range(n):
# m*p*n
C[i][j] += A[i][k] * B[k][j]
这里矩阵乘法可以理解为三个for循环,虽然实际上Pytorch会进行优化,但我们可以见到当成这样实现,这里的时间复杂度就是m*p*n。
对应上面的 Q K T QK^T QKT矩阵就是 O ( N ⋅ d ⋅ N ) = O ( N 2 ⋅ d ) O(N\cdot d \cdot N)=O(N^2\cdot d) O(N⋅d⋅N)=O(N2⋅d);
上式括号中除以一个常数不会影响时间复杂度。对每行做 Softmax \text{Softmax} Softmax与除法的复杂度为 O ( N ) O(N) O(N), N N N行的复杂度为 O ( N 2 ) O(N^2) O(N2);
这里整个Softmax得到了一个 N × N N \times N N×N的矩阵,然后与 V ∈ R N × d V \in \R^{N \times d} V∈RN×d的矩阵相乘,时间复杂度为 O ( N 2 d ) O(N^2 d) O(N2d)。
因此整个公式的时间复杂度为 O ( N 2 d ) + O ( N 2 ) + O ( N 2 ) + O ( N 2 d ) = O ( N 2 d ) O(N^2d) + O(N^2) +O(N^2) + O(N^2d) = O(N^2d) O(N2d)+O(N2)+O(N2)+O(N2d)=O(N2d);
其中这两个 O ( N 2 ) O(N^2) O(N2)分别对应除法和Softmax。
再看空间复杂度,只与矩阵维度有关,Softmax包含的三个操作都是 O ( N 2 ) O(N^2) O(N2),最后计算出来的结果矩阵维度是 N × d N \times d N×d,所以它的空间复杂度是 O ( N d ) O(Nd) O(Nd)。整体空间复杂度就是 O ( N 2 + N d ) O(N^2 + Nd) O(N2+Nd)。
完整代码
https://github.com/nlp-greyfoss/nlp-in-action-public/tree/master/transformers/transformer
参考
- 十分钟弄懂字节对编码
- HuggingFace官网课程
- 从零实现Transformer
- Transformer Architecture: The Positional Encoding
- Making Sense of Positional Encoding in Transformer Architectures with Illustrations
- Transformer’s Positional Encoding
- How does Layer Normalization work?
- Rethinking the Inception Architecture for Computer Vision