【一】粘包问题介绍
【1】粘包和半包
-
粘包:
- 定义: 粘包指的是发送方发送的若干个小数据包被接收方一次性接收,形成一个大的数据包。
- 原因: 通常是因为网络底层对数据传输的优化,将多个小数据包组合成一个大的数据块一次性传输,以提高传输效率。
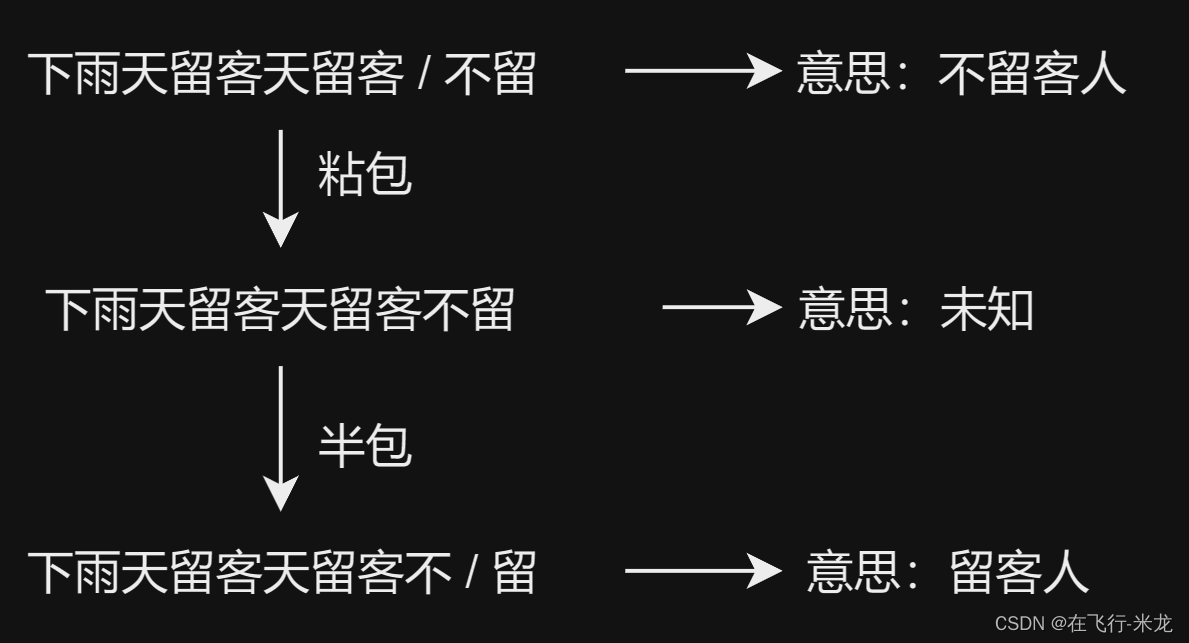
- **举例:**A给B发送了两条信息,分别是”下雨天留客天留人“和”不留“,然而B一次性全部收到了”下雨天留客天留人不留“,这就可能会让B理解成留人的意思
-
半包:
- 定义: 半包是指接收方在一次接收中没有完全接收到一个完整的数据包,导致数据包被切割成了两部分。
- 原因: 可能是网络传输过程中发生了拆包,或者接收缓冲区不够大,无法容纳完整的数据包。
- **举例:**还是同样的,A给B发的一条信息”下雨天留客天留人不留“,B却收到分开的两条信息”下雨天留客天留人“和”不留“,让B理解成不留
【2】为什么会有粘包
-
注:只有TCP协议才有粘包现象, UDP协议永远不会粘包
-
TCP协议是面向连接的,面向流的,提供高可靠性服务。
- 客户端和服务器端都要有一个成对的socket
- 因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。
- 这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
-
UDP协议是无连接的,面向消息的,提供高效率服务。
- 不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息)
- 这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
-
两种情况会发生粘包
- 发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据量小会合到一起,产生粘包)
- 接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)。
【二】解决粘包问题
-
思路:
- 接收端不知道发送端要发送的数据大小,那么就提前告知接收端数据的大小,这样接收端就可以完整的取出所有数据
-
还存在的问题:
- 需要提前发送数据的大小,这个大小也是我们需要发送的数据,那么还需要这个大小的大小,这不是陷入死循环了
-
解决办法:
- 通过struct模块将数据的大小进行打包
- 因为struct模块可以输出固定字节大小的字节流数据
- 比如:所有的int的型变量,无论大小都可以转换成4个字节的数据
- 这个大小固定,那么每次接收端只要先判断数据的大小就可以完整接收数据
-
代码演示:接收大数据文件
# 服务端
# 导入模块
import socket
import struct
# 1320KB的数据内容
big_data = ("重要信息" * 110).encode("utf8")
# 计算大小
data_size = len(big_data)
# struct生成四字节流的信息
data_size_struct = struct.pack("i", data_size)
# 创建socket对象
server = socket.socket()
server.bind(("localhost", 5656))
server.listen()
conn, addr = server.accept()
# 先发送数据的大小
conn.send(data_size_struct)
# 发送大数据包
conn.send(big_data)
# 关闭
conn.close()
server.close()
# 客户端
# 导入模块
import socket
import struct
# 创建socket对象
client = socket.socket()
client.connect(("localhost", 5656))
# 读取文件大小
head = client.recv(4)
total = struct.unpack("i", head)[0]
# 根据大小接收数据
have = 0
data = bytes()
while have < total:
data += client.recv(1024)
have += 1024
print(data.decode("utf8"))
# 关闭
client.close()
【三】练习
- 使用所学内容完成以下要求:
- 创建客户端和服务端
- 服务端给客户端提供信息列表(视频资源)
- 客户端选择对应资源
- 服务端传输对应资源给客户端
- 可以尝试:
- 分别在两台电脑上创建客户端和服务端
- 提示:关闭防火墙,查询服务端IP地址
参考代码:
- 运行要求:需要在服务端路径视频资源文件夹server_movie下放入一些视频文件
# 服务端
# 导入模块
import os
import pickle
import socket
import struct
# 创建电影资源路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
MOVIE_DIR = os.path.join(BASE_DIR, "server_movie")
os.makedirs(MOVIE_DIR, exist_ok=True)
movie_list = os.listdir(MOVIE_DIR)
# 生成电影资源字典
movie_dict = {index: data for index, data in enumerate(movie_list, start=1)}
# 将字典转换为字节流数据
movie_pickle = pickle.dumps(movie_dict)
# 开启服务端
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0)
server.bind(("0.0.0.0", 9696))
server.listen(5)
# 长时间没有客户端连接
server.settimeout(5)
while True:
# 进行时间尝试捕获
try:
conn, addr = server.accept()
print(f"{addr}发送链接请求")
# 发送定影资源信息
conn.send(movie_pickle)
except socket.timeout:
print("长时间没有客户端连接,服务端自动关闭")
break
while True:
# 接收选择信息
res = conn.recv(1024).decode("utf8")
# 退出或断开连接
if res == "q" or not res:
print(f"客户端{addr}断开连接")
conn.close()
break
# 获取资源路径
choice_index = int(res)
movie_dir = os.path.join(MOVIE_DIR, f"{movie_dict.get(choice_index)}")
# 读取电影资源
with open(movie_dir, "rb") as fp:
movie_data = fp.read()
# 计算大小并发送
head = struct.pack("i", len(movie_data))
conn.send(head)
conn.send(movie_data)
print(f"向{addr}发送{movie_dict.get(choice_index)}完成")
# 一个客户端完成
conn.close()
# 关闭服务端
server.close()
# 客户端
# 导入模块
import os.path
import pickle
import socket
import struct
# 创建保存资源路径
DB_DIR = os.path.dirname(os.path.abspath(__file__))
MOVIE_DIR = os.path.join(DB_DIR, "client_movie")
os.makedirs(MOVIE_DIR, exist_ok=True)
# 开始客户端
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0)
client.connect(("localhost", 9696))
# 接收资源信息字典
movie_pickle = client.recv(1024)
movie_dict = pickle.loads(movie_pickle)
while True:
# 打印可获取的资源
print("可以从服务端拿到的资源信息如下:")
for key, value in movie_dict.items():
print(f"编号【{key}】 资源信息:{value}")
# 选择判断
choice = input("根据编号进行资源选择(Q/q:退出):>>>").strip()
if choice.lower() == "q":
client.send(choice.encode("utf8"))
break
elif choice not in [str(i) for i in range(1, len(movie_dict) + 1)]:
print("输入有误,请重新检查")
continue
# 发送选择编号
client.send(choice.encode("utf8"))
# 获取资源名字
movie_name = movie_dict.get(int(choice))
# 获取资源大小
head_pack = client.recv(4)
total = struct.unpack("i", head_pack)[0]
# 下载接收文件
have = 0
movie_data = bytes()
print(f"正在下载{movie_name}")
while have < total:
movie_data += client.recv(1024)
have += 1024
# 进度条显示
progress = have / total
bar_length = 30
bar = '=' * int(progress * bar_length) + '-' * (bar_length - int(progress * bar_length))
percentage = progress * 100
print(f'\r[{bar}] {percentage:.2f}% Complete', end='', flush=True)
# 保存下载的资源
movie_dir = os.path.join(MOVIE_DIR, movie_name)
with open(movie_dir, "wb") as fp:
fp.write(movie_data)
print(f"\n{movie_name} 保存成功")
# 关闭
client.close()







![[笔记]深度学习入门 基于Python的理论与实现(三)](https://img-blog.csdnimg.cn/direct/73b6140f048c4f258a9a28a651e54b37.png)