PyFlink1.16.0 使用说明:建表及连接Mysql数据库
- 引言
- 安装运行环境
- PyFlink创建作业环境
- 一、创建一个 Table API 批处理表环境
- 二、创建一个 Table API 流处理表环境
- 三、创建一个 DataStream API 数据流处理环境
- PyFlink建表
- 一、从Python List对象创建一个 Table
- 二、创建具有显式架构的 Table
- 三、从pandas DataFrame创建一个table
- 四、从DDL语句创建 Table
- 五、从 TableDescriptor 创建数据源表
- 六、从 DataStream 创建 数据源表
- 七、从Catalog 创建数据源表
- PyFlink连接Mysql数据库
- PyFlink同步Mysql表数据到另一张表
- 一、创建表环境并添加数据库连接依赖
- 二、创建数据源表
- 三、创建接收数据表
- 三、执行数据同步
引言
Flink已经成为 大数据开发 领域举足轻重的存在
直到 PyFlink1.16.0 版本,python已经支持95%以上的Fink功能
最好的学习办法是通过官方文档进行学习
但是官方文档中使用的例子,往往跑不通
需要有一定的经验积累,再进行不断调试,才能摸索到一定的门道
安装运行环境
环境根据最新的版本安装即可,需要注意最新的PyFlink支持的最大Python版本
如:PyFlink1.16.0 支持Python 3.6, 3.7, 3.8 or 3.9,大于3.9的版本就不支持了
PyFlink创建作业环境
PyFlink分为 DataStream API 和 Table API & SQL
在创建环境的方式上大概分为三种:
一、创建一个 Table API 批处理表环境
from pyflink.table import EnvironmentSettings, TableEnvironment
batch_env_settings = EnvironmentSettings.in_batch_mode()
batch_table_env = TableEnvironment.create(batch_env_settings)
二、创建一个 Table API 流处理表环境
from pyflink.table import EnvironmentSettings, TableEnvironment
stream_env_settings = EnvironmentSettings.in_streaming_mode()
stream_table_env = TableEnvironment.create(stream_env_settings)
三、创建一个 DataStream API 数据流处理环境
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
data_stream_env = StreamExecutionEnvironment.get_execution_environment()
data_stream_table_env = StreamTableEnvironment.create(data_stream_env)
PyFlink建表
Table 是 python table api的核心组件
对象描述数据转换的通道
它不以任何方式包含数据本身
相反,它描述了如何从表源读取数据
如何对数据添加一些计算以及如何最终将数据写入表接收器
声明管道可以 打印、优化并最终在集群中执行
管道可以使用有界或无界流
一、从Python List对象创建一个 Table
def create_table_from_list():
"""
根据list数据,创建数据源表
流模式、批模式 均可以创建成功
:return:
"""
table = batch_table_env.from_elements([(1, 'Hi'), (2, "Hello")])
# table = stream_table_env.from_elements([(1,'Hi'),(2,"Hello")])
print(table.get_schema())
table.execute().print()
二、创建具有显式架构的 Table
def create_table_from_type():
"""
在创建数据源表的时候,设置好字段类型和字段名称
流模式、批模式 均可以创建成功
:return:
"""
# table = batch_table_env.from_elements([
# (1,"hi"),(2,"Hello")
# ],
# DataTypes.ROW([
# DataTypes.FIELD("id",DataTypes.TINYINT()),
# DataTypes.FIELD('data',DataTypes.STRING())
# ]))
table = stream_table_env.from_elements([
(1, "hi"), (2, "Hello")
],
DataTypes.ROW([
DataTypes.FIELD("id", DataTypes.TINYINT()),
DataTypes.FIELD('data', DataTypes.STRING())
]))
print(table.get_schema())
table.execute().print()
三、从pandas DataFrame创建一个table
def create_tabel_from_pandas():
"""
pandas设置表数据
流模式、批模式 均可以创建成功
:return:
"""
df = pd.DataFrame({
'id': [1, 2],
'data': ['Hi', 'Hello']
})
# table = batch_table_env.from_pandas(df)
table = stream_table_env.from_pandas(df)
print(table.get_schema())
table.execute().print()
四、从DDL语句创建 Table
注意点:使用 批处理环境的时候,无法执行成功 ,必须使用 流处理环境
使用批处理环境报错信息:
Querying an unbounded table 'default_catalog.default_database.random_source' in batch mode is not allowed. The table source is unbounded.
def create_table_from_ddl():
"""
使用sql语句创建数据源表
注意点:使用 批处理环境的时候,无法执行成功
必须使用 流处理环境
:return:
"""
create_sql = """
CREATE TABLE random_source (
id TINYINT,
data STRING
) WITH (
'connector' = 'datagen',
'fields.id.kind' = 'sequence',
'fields.id.start' = '1',
'fields.id.end' = '2',
'fields.data.kind' = 'random'
)
"""
# batch_table_env.execute_sql(create_sql )
# table = batch_table_env.from_path("random_source")
# table.get_schema()
# table.execute().print()
# 以上失败
# 以下成功
# stream_table_env.execute_sql(create_sql )
# table = stream_table_env.from_path("random_source")
# table.execute().print()
data_stream_table_env.execute_sql(create_sql)
table = data_stream_table_env.from_path("random_source")
table.execute().print()
五、从 TableDescriptor 创建数据源表
注意点:使用 批处理环境的时候,无法执行成功 ,必须使用 流处理环境
def create_table_from_descriptor():
"""
使用TableDescriptor,创建数据源表
注意点:使用 批处理环境的时候,无法执行成功
必须使用 流处理环境
:return:
"""
schema = (Schema.new_builder()
.column('id', DataTypes.TINYINT())
.column('data', DataTypes.STRING())
.build())
# table = batch_table_env.from_descriptor(
# 以上失败
# 以下成功
table = stream_table_env.from_descriptor(
TableDescriptor
.for_connector('datagen')
.option('fields.id.kind', 'sequence')
.option('fields.id.start', '1')
.option('fields.id.end', '2')
.option('fields.data.kind', 'random')
.schema(schema)
.build()
)
table.get_schema()
table.execute().print()
六、从 DataStream 创建 数据源表
def create_table_from_data_stream():
"""
使用DataStream 创建数据源表
创建方式与以上都不相同。
环境设置数据和数据类型及字段名
表环境设置数据源表
:return:
"""
data_stream_env = StreamExecutionEnvironment.get_execution_environment()
data_stream_table_env = StreamTableEnvironment.create(data_stream_env)
ds = data_stream_env.from_collection(
[(1, 'Hi'), (2, 'Hello')],
type_info=Types.ROW_NAMED(
['id', 'data'],
[Types.BYTE(), Types.STRING()]
)
)
table = data_stream_table_env.from_data_stream(
ds,
Schema.new_builder()
.column('id', DataTypes.TINYINT())
.column('data', DataTypes.STRING())
.build()
)
table.get_schema()
table.execute().print()
七、从Catalog 创建数据源表
def create_table_from_catalog():
"""
流模式、批模式 均可以创建成功
:return:
"""
# old_table = batch_table_env.from_elements(
old_table = stream_table_env.from_elements(
[(1, "Hi"), (2, "Hello")],
["id", "data"]
)
# 创建临时 视图表
# batch_table_env.create_temporary_view("source_table",old_table)
stream_table_env.create_temporary_view("source_table", old_table)
# table = batch_table_env.from_path("source_table")
table = stream_table_env.from_path("source_table")
table.get_schema()
# table.execute().print()
PyFlink连接Mysql数据库
如果使用第三方 JAR,则可以在 Python 表 API 中指定 JAR
环境:
PyFlink版本是1.16.0,所以需要下载 :flink-connector-jdbc-1.16.0.jar
flink-connector-jdbc-1.16.0.jar下载地址
Mysql版本是8.0.30,所以需要下载:mysql-connector-java-8.0.30.jar
mysql-connector-java-8.0.30.jar下载地址
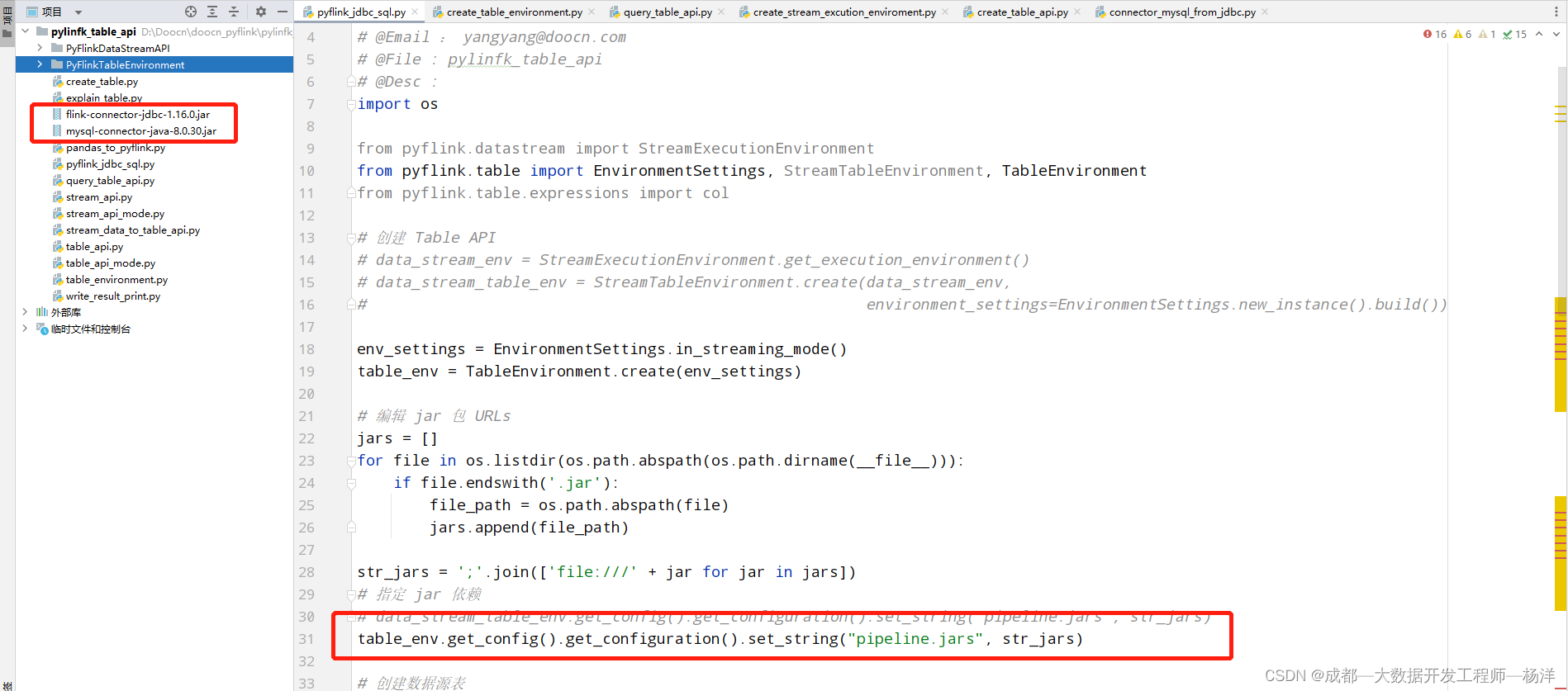
在创建表环境时,将 JAR 依赖添加到表环境
from pyflink.table import EnvironmentSettings, TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
jars = []
for file in os.listdir(os.path.abspath(os.path.dirname(__file__))):
if file.endswith('.jar'):
file_path = os.path.abspath(file)
jars.append(file_path)
str_jars = ';'.join(['file:///' + jar for jar in jars])
table_env.get_config().get_configuration().set_string("pipeline.jars", str_jars)
不报错就是正确
PyFlink同步Mysql表数据到另一张表
思路:
1、需要创建一张数据源表,数据源表需要连接到数据库中的表
2、需要创建一张接收数据表,用于接收同步过来的数据
3、执行数据同步的sql语句或者table sql
注意点:
需要提前在数据库中建立好这两张表
一、创建表环境并添加数据库连接依赖
from pyflink.table import EnvironmentSettings, TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
jars = []
for file in os.listdir(os.path.abspath(os.path.dirname(__file__))):
if file.endswith('.jar'):
file_path = os.path.abspath(file)
jars.append(file_path)
str_jars = ';'.join(['file:///' + jar for jar in jars])
table_env.get_config().get_configuration().set_string("pipeline.jars", str_jars)
二、创建数据源表
# 创建数据源表
create_source_table_sql = """
CREATE TABLE source (
user_id STRING,
name STRING,
telephone STRING,
is_del STRING,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://******:33066/dim',
'table-name' = 'source',
'username' = '******',
'password' = '******',
'driver' = 'com.mysql.cj.jdbc.Driver'
)
"""
table_env.execute_sql(create_source_table_sql)
三、创建接收数据表
# 创建接收结果表
create_sink_table_sql = """
CREATE TABLE sink (
user_id STRING,
name STRING,
telephone STRING,
is_del STRING,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://******:3306/tmp',
'table-name' = 'sink',
'username' = '******',
'password' = '******',
'driver' = 'com.mysql.cj.jdbc.Driver'
)
"""
table_env.execute_sql(create_sink_table_sql)
三、执行数据同步
table_env.execute_sql("INSERT INTO sink SELECT * FROM source").wait()
如有提示:
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
只需要在 WITH 中 添加 ‘driver’ = ‘com.mysql.cj.jdbc.Driver’ 即可
完整代码,将以上代码,按照顺序copy到编译器即可
不报错则表示运行成功