关于Pandas版本: 本文基于 pandas2.1.2 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
Pandas稳定版更新及变动内容整合专题: Pandas稳定版更新及变动迭持续更新。
Pandas API参考所有内容目录
本节目录
- Pandas.DataFrame.loc[]
- 语法:
- 返回值:
- 语法说明:
- 1、筛选1行,筛选1列,筛选单元格
- 2、筛选多行,筛选多列
- 3、范围筛选
- 4、布尔筛选
- 5、Callable 筛选
- 相关方法:
- 示例:
Pandas.DataFrame.loc[]
Pandas.DataFrame.loc[] 方法用于通过索引、列名 筛选 DataFrame 数据。
- 注意!在此方法中,你传递的数字,不会被理解为
自然索引,只作为字符串传递给DataFrame.loc视为行索引的值,或列名的值。 -
⚠️ 注意 :
- 在此方法中,你传递的数字,不会被理解为
自然索引,只作为字符串传递给DataFrame.loc视为行索引的值,或列名的值。 - 如果对具有
多层索引的DataFrame进行范围筛选,必须先对其进行排序 推荐使用df.sort_index(inplace=True)排序后再进行范围筛选。 - 支持筛选后对原数据进行赋值 例10
- 在此方法中,你传递的数字,不会被理解为
语法:
DataFrame.loc [‘行索引’,‘列名’]
返回值:
- Series or DataFrame or Scalar
- 筛选范围、
DataFrame是否具有多层索引等都会影响具体的返回形式。 - 如果筛选结果是
Series或Scalar时,筛选条件套上 [ ] 方括号,可以强制以DataFrame样式返回。例1
- 筛选范围、
语法说明:
1、筛选1行,筛选1列,筛选单元格
-
DataFrame.loc[索引,列名] 例1
索引筛选条件、列名筛选条件,用英文逗号分隔。
-
筛选1行: DataFrame.loc[‘索引’,: ] 只传递索引条件时,红色逗号、冒号可以省略。红色的冒号表示所有列。
-
筛选1列: DataFrame.loc[:, ‘列名’] 红色冒号必须有,表示所有行。
-
筛选单元格: DataFrame.loc[‘索引’, ‘列名’]
如果
DataFrame有多层索引、列名,当你想筛选非顶层数据时,需要用元组传递索引、列名的层级。例2
-
2、筛选多行,筛选多列
-
DataFrame.loc[[‘索引1’,‘索引2’, …],[‘列名1’,‘列名2’, …]]例3
多个索引筛选条件用方括号包裹、多个列名筛选条件用方括号包裹。两种条件用英文逗号分隔。
- 筛选多行: DataFrame.loc[[‘索引1’,‘索引2’, …], ] 只传递索引条件时,红色逗号可以省略。
- 筛选多列: DataFrame.loc[, [‘列名1’,‘列名2’, …]]
- 同时筛选多行多列: DataFrame.loc[[‘索引1’,‘索引2’, …], [‘列名1’,‘列名2’, …]]
-
⚠️ 注意 :
-
多个条件,必须用 [ ] 方括号包裹!
-
与
Python切片不同,被 [ ] 包裹的开始和结束位置的元素,都会包含在筛选条件内。 -
如果
DataFrame有多层索引、列名,当你想筛选非顶层数据时,需要用元组传递索引、列名的层级。例4
-
3、范围筛选
-
DataFrame.loc[[‘索引1’:‘索引2’] 例5
支持行的范围筛选,开始和结束的范围用英文冒号分隔。不支持列的范围筛选。
-
只筛选行范围: DataFrame.loc[[‘索引1’:‘索引2’], ] 只传递索引条件时,红色逗号可以省略。
-
筛选行范围 + 筛选1列: DataFrame.loc[[‘索引1’:‘索引2’], ‘列名1’]
-
筛选行范围 + 筛选多列: DataFrame.loc[[‘索引1’:‘索引2’], [‘列名1’,‘列名2’, …]]
-
⚠️ 注意 :
-
开始和结束的范围,必须用 : 英文冒号分隔!
-
范围,必须用 [ ] 方括号包裹!
-
与
Python切片不同,被 [ ] 包裹的范围,开始和结束位置,都会包含在筛选条件内。
-
如果
DataFrame有多层索引、列名,起始范围,必须精确到最底层的索引或列名。因为顶层索引、列名,可能代表着多行或多列,这是不能作为开始条件使用的。例6如果对具有
多层索引的DataFrame进行范围筛选,必须先对其进行排序 推荐使用df.sort_index(inplace=True)排序后再进行范围筛选。 -
4、布尔筛选
-
DataFrame.loc[行条件,列条件]
- 行筛选: 可以传递一个与行索引长度相同的
布尔列表表示那些行留下,哪些行舍弃。例7 - 行筛选: 可以使用布尔运算对行进行筛选。如果布尔运算的数量超过3个,建议使用 advanced indexing
-
⚠️ 注意 :
行的布尔运算,是通过列名完成的。以
df[列名]的方式表达。 例8多个条件,可以用
&,|表示并或,不能使用and,or。例8
- 列筛选: 不支持布尔运算。
- 行筛选: 可以传递一个与行索引长度相同的
5、Callable 筛选
-
DataFrame.loc[Callable]
可以使用
Callable进行筛选,原理上这也是一种布尔筛选。 例9
相关方法:
➡️ 相关方法
DataFrame.at
Access a single value for a row/column label pair.
DataFrame.iloc
筛选数据-自然索引法
DataFrame.xs
Returns a cross-section (row(s) or column(s)) from the Series/DataFrame.
Series.loc
Access group of values using labels.
示例:
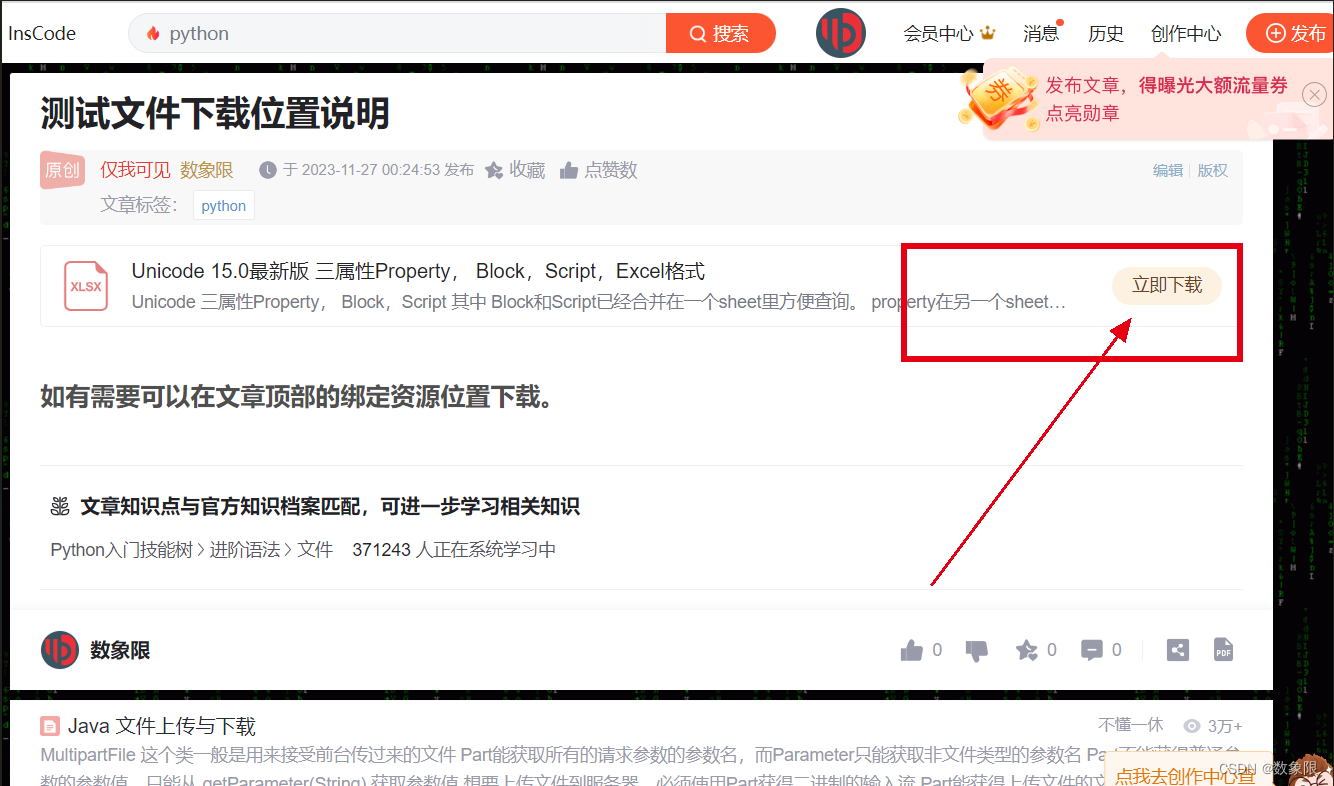
测试文件下载:
本文所涉及的测试文件,如有需要,可在文章顶部的绑定资源处下载。
若发现文件无法下载,应该是资源包有内容更新,正在审核,请稍后再试。或站内私信作者索要。
read_excel_na_values
- 1、筛选1行,默认返回
Series,把筛选条件套上 [ ],可以强制返回DataFrame。
import pandas as pd
# 构建DF
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
# 常规单行筛选,返回Series
df.loc['cobra']
# ... max_speed 1
# ... shield 2
# ... Name: cobra, dtype: int64
# 单行筛选,条件套上[ ],强制返回 DataFrame
df.loc[['cobra']]
# ... max_speed shield
# ... cobra 1 2
- 2、筛选1列,默认返回
Series,把筛选条件套上 [ ],可以强制返回DataFrame。
# 常规单列筛选'max_speed',返回Series
df.loc[:,'max_speed']
# ... cobra 1
# ... viper 4
# ... sidewinder 7
# ... Name: max_speed, dtype: int64
# 单列筛选,条件套上[ ],强制返回 DataFrame
df.loc[:,['max_speed']]
# ... max_speed
# ... cobra 1
# ... viper 4
# ... sidewinder 7
- 3、筛选单元格,默认返回标量值
Scalar,把筛选条件套上 [ ],可以强制返回DataFrame。
# 常规单元格筛选,返回标量值
df.loc['cobra', 'max_speed']
# ... 1
# 把筛选条件套上 [ ],可以强制返回 DataFrame
df.loc[['cobra'], ['max_speed']]
# ... max_speed
# ... cobra 1
- 1、构建演示数据并观察数据内容
import pandas as pd
# 构建演示数据
tuples = [
('射手', '巨魔族'), ('射手', '死灵族'),
('法师', '巨魔族'), ('法师', '死灵族'),
('战士', '巨魔族'), ('战士', '死灵族')
]
index = pd.MultiIndex.from_tuples(tuples)
values = [[9, 20], [10, 18], [7, 23],
[6, 25], [4, 30], [3, 35]]
df = pd.DataFrame(values, columns=[['属性1','属性2'], ['攻速','攻击力']], index=index)
# 观察数据内容
df
- 2、筛选1行或1列顶层索引,正常传递条件即可
# 筛选顶层行索引
df.loc['射手']
# ... 属性1 属性2
# ... 攻速 攻击力
# ... 巨魔族 9 20
# ... 死灵族 10 18
# 筛选顶层列索引
df.loc[:,'属性1']
# ... 攻速
# ... 射手 巨魔族 9
# ... 死灵族 10
# ... 法师 巨魔族 7
# ... 死灵族 6
# ... 战士 巨魔族 4
# ... 死灵族 3
- 2、筛选非顶层索引、列名,需要用元组把条件套起来
# 筛选最底层的某行
df.loc[('射手','巨魔族')]
# ... 属性1 攻速 9
# ... 属性2 攻击力 20
# ... Name: (射手, 巨魔族), dtype: int64
# 筛选底层索引,顶层列名
df.loc[('射手','巨魔族'),'属性1']
# ... 攻速 9
# ... Name: (射手, 巨魔族), dtype: int64
# 筛选底层索引,底层列名
df.loc[('射手','巨魔族'),('属性1','攻速')]
# ... 9
9
- 3、多层索引筛选,条件用 [] 套起来,也可以强制返回
DataFrame
df.loc[[('射手','巨魔族')],['属性1']]
# ... 属性1
# ... 攻速
# ... 射手 巨魔族 9
import pandas as pd
# 构建DF
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
# 筛选多行
df.loc[['cobra', 'viper']]
# ... max_speed shield
# ... cobra 1 2
# ... viper 4 5
# 筛选多行、单列
df.loc[['cobra', 'viper'],'max_speed']
# ... cobra 1
# ... viper 4
# ... Name: max_speed, dtype: int64
# 筛选多行、多列
df.loc[['cobra', 'viper'],['max_speed', 'shield']]
# ... max_speed shield
# ... cobra 1 2
# ... viper 4 5
import pandas as pd
# 构建演示数据
tuples = [
('射手', '巨魔族'), ('射手', '死灵族'),
('法师', '巨魔族'), ('法师', '死灵族'),
('战士', '巨魔族'), ('战士', '死灵族')
]
index = pd.MultiIndex.from_tuples(tuples)
values = [[9, 20], [10, 18], [7, 23],
[6, 25], [4, 30], [3, 35]]
df = pd.DataFrame(values, columns=[['属性1','属性2'], ['攻速','攻击力']], index=index)
# 筛选多个顶层行索引
df.loc[['射手','法师']]
# ... 属性1 属性2
# ... 攻速 攻击力
# ... 射手 巨魔族 9 20
# ... 死灵族 10 18
# ... 法师 巨魔族 7 23
# ... 死灵族 6 25
# 筛选多个底层航索引
df.loc[[('射手','巨魔族'),('法师','死灵族')]]
# ... 属性1 属性2
# ... 攻速 攻击力
# ... 射手 巨魔族 9 20
# ... 法师 死灵族 6 25
# 行、列组合条件
df.loc[('射手','巨魔族'),('属性2','攻击力')]
# ... 20
# 同时筛选多行、多列
df.loc[[('射手','巨魔族'),('法师','死灵族')],[('属性1','攻速'),('属性2','攻击力')]]
# ... 属性1 属性2
# ... 攻速 攻击力
# ... 射手 巨魔族 9 20
# ... 法师 死灵族 6 25
import pandas as pd
# 构建DF
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
# 只筛选行的范围
df.loc['viper':'sidewinder']
# ... max_speed shield
# ... viper 4 5
# ... sidewinder 7 8
# 行范围 + 1列
df.loc['viper':'sidewinder','shield']
# ... viper 5
# ... sidewinder 8
# ... Name: shield, dtype: int64
# 行范围 + 多列
df.loc['viper':'sidewinder',['max_speed','shield']]
# ... max_speed shield
# ... viper 4 5
# ... sidewinder 7 8
例6:多层索引的DataFrame,筛选行范围 起始范围,必须精确到最底层的索引或列名。
import pandas as pd
# 构建演示数据
tuples = [
('射手', '巨魔族'), ('射手', '死灵族'),
('战士', '巨魔族'), ('战士', '死灵族'),
('法师', '巨魔族'), ('法师', '死灵族')
]
index = pd.MultiIndex.from_tuples(tuples)
values = [[9, 20], [10, 18], [7, 23],
[6, 25], [4, 30], [3, 35]]
df = pd.DataFrame(values, columns=[['属性1','属性2'], ['攻速','攻击力']], index=index)
# 观察数据
# df
# 属性1 属性2
# 攻速 攻击力
# 射手 巨魔族 9 20
# 死灵族 10 18
# 战士 巨魔族 4 30
# 死灵族 3 35
# 法师 巨魔族 7 23
# 死灵族 6 25
# 筛选从射手到法师,即使都是顶层索引,范围条件的开始位置,也必须精确到巨魔族,意为指定这一行。因为顶层索引、列名,可能代表着多行或多列,这是不能作为开始条件使用的。
df.loc[('射手','巨魔族'):'战士']
# 属性1 属性2
# 攻速 攻击力
# 射手 巨魔族 9 20
# 死灵族 10 18
# 战士 巨魔族 4 30
# 死灵族 3 35
# 筛选行范围 + 列范围
df.loc[('射手','巨魔族'):('战士', '巨魔族'),('属性1','攻速'):('属性2', '攻击力')]
# 属性1 属性2
# 攻速 攻击力
# 射手 巨魔族 9 20
# 死灵族 10 18
# 战士 巨魔族 4 30
import pandas as pd
# 构建演示数据
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
# 布尔列表
list_bool = [False, False, True]
# 传入布尔列表,只保留第3行'sidewinder'
df.loc[list_bool]
# ... max_speed shield
# ... sidewinder 7 8
import pandas as pd
# 构建演示数据
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['移速', '护甲'])
# 筛选 '移速列' > 6 的行
df.loc[df['移速'] > 6]
# ... 移速 护甲
# ... sidewinder 7 8
# 筛选 '移速列' > 6 的行,同时,只保留护甲列
df.loc[df['移速'] > 6,['护甲']] # 护甲加了方括号,是为了以DataFrame显示。
# ... 护甲
# ... sidewinder 8
# 用 & 表示 并
df.loc[(df['移速'] > 1) & (df['护甲'] < 8)]
# ... 移速 护甲
# ... viper 4 5
# 用 | 表示 或
df.loc[(df['移速'] > 4) | (df['护甲'] < 5)]
# ... 移速 护甲
# ... cobra 1 2
# ... sidewinder 7 8
- 1、lambda
import pandas as pd
# 构建演示数据
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['移速', '护甲'])
# 使用lambda 筛选 护甲列 ==8 的行
df.loc[lambda df: df['护甲'] == 8]
# ... 移速 护甲
# ... sidewinder 7 8
- 2、自定义函数
import pandas as pd
# 构建演示数据
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['移速', '护甲'])
# 定义筛选函数
def slect_df(df):
return df['护甲'] == 8
# 调用函数
df.loc[slect_df]
import pandas as pd
# 构建演示数据
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['移速', '护甲'])
# 筛选后,批量修改数据
df.loc[df['移速']>2] = 50
df
# ... 移速 护甲
# ... cobra 1 2
# ... viper 50 50
# ... sidewinder 50 50
# 筛选后,批量 + 30
df.loc[df['移速'] == 50] += 5
df
# ... 移速 护甲
# ... cobra 1 2
# ... viper 55 55
# ... sidewinder 55 55







![[渗透测试学习] Hospital - HackTheBox](https://img-blog.csdnimg.cn/direct/65d696d108614b75942e2b82ff34a348.png)