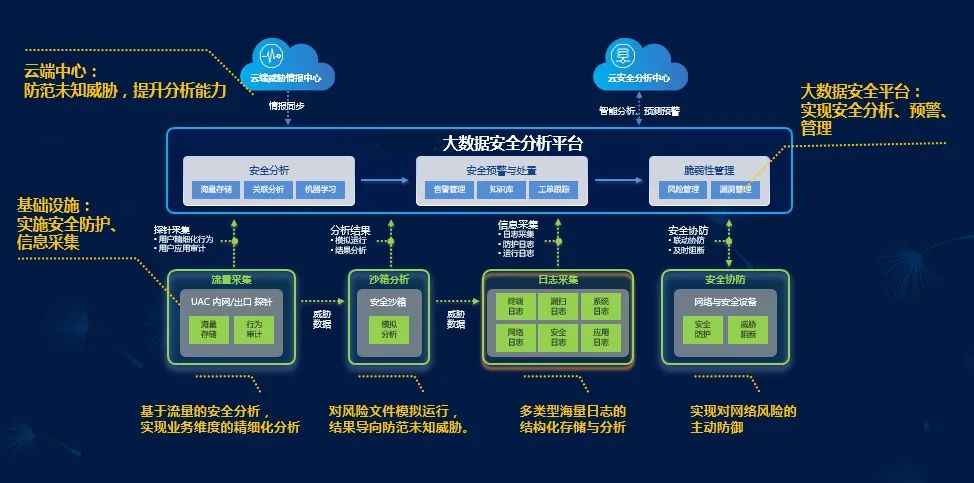
目录
- 前言
- 1 使用基础模型训练手段的传统训练策略
- 1.1 随机初始化为模型提供初始点
- 1.2 目标函数设定是优化性能的关键
- 2 BERT微调策略: 适应具体任务的精妙调整
- 2.1 利用不同的representation和分类器进行微调
- 2.2 通过fine-tuning适应具体任务
- 3 T5预训练策略: 统一任务形式以提高通用性
- 3.1 利用11B参数的T5模型
- 3.2 将任务转换为Seq2Seq形式
- 4 GPT3微调策略: 实现零样本和少样本学习的创新方法
- 4.1 利用transformer decoder进行微调
- 4.2 通过prompt处理实现zero-shot和few-shot学习
- 结论
前言
微调是在NLP领域中应用预训练模型的关键步骤之一。本文将深入研究微调过程中的训练策略,从传统训练到预训练和微调的策略演进,为实现微调成功提供清晰的指导。
1 使用基础模型训练手段的传统训练策略
传统训练策略是深度学习领域的基础,但在微调大规模预训练模型时,需要更加灵活的方法。

1.1 随机初始化为模型提供初始点
随机初始化是通过随机设定模型权重和偏置,为模型提供一个初始状态的过程。初始状态的多样性。 随机初始化引入了一定的多样性,使得模型不会陷入固定的状态,有助于避免陷入局部最优解。
随机初始化为整个训练过程提供了一个出发点,模型从这一点开始通过梯度下降等优化方法逐步调整参数。这一步骤奠定了整个训练过程的基础,为后续的迭代优化提供了起点。
1.2 目标函数设定是优化性能的关键
在深度学习中,通过巧妙设计目标函数进行训练是确保模型性能优越的关键步骤。
通过分类器和定义的目标函数进行训练。 目标函数通常涉及分类器,它负责将模型的输出映射到预期的标签空间。 设计一个明确的目标函数,能够量化模型在任务上的性能。
目标函数的设计需要平衡不同性能度量之间的关系,确保模型在关键任务上取得优异的表现。针对不同任务,可能需要调整目标函数的设计,以适应多样性的问题场景。
在训练过程中,通过梯度下降等优化算法,不断迭代优化模型参数以最小化目标函数。利用验证集监控模型的性能,确保模型在未见过的数据上具有较好的泛化能力。在验证效果良好后,进行最终的测试,评估模型在真实场景中的表现。
目标函数的巧妙设计是深度学习任务成功的基石,通过对模型学习目标的明确定义和调整,能够推动模型在各种任务上取得更好的性能。这一过程也需要根据任务的具体特点进行精心的设计和调整,以确保模型在实际应用中能够发挥最佳的效果。
随着大规模预训练模型的兴起,微调策略也相应演化,以更好地适应各种任务。
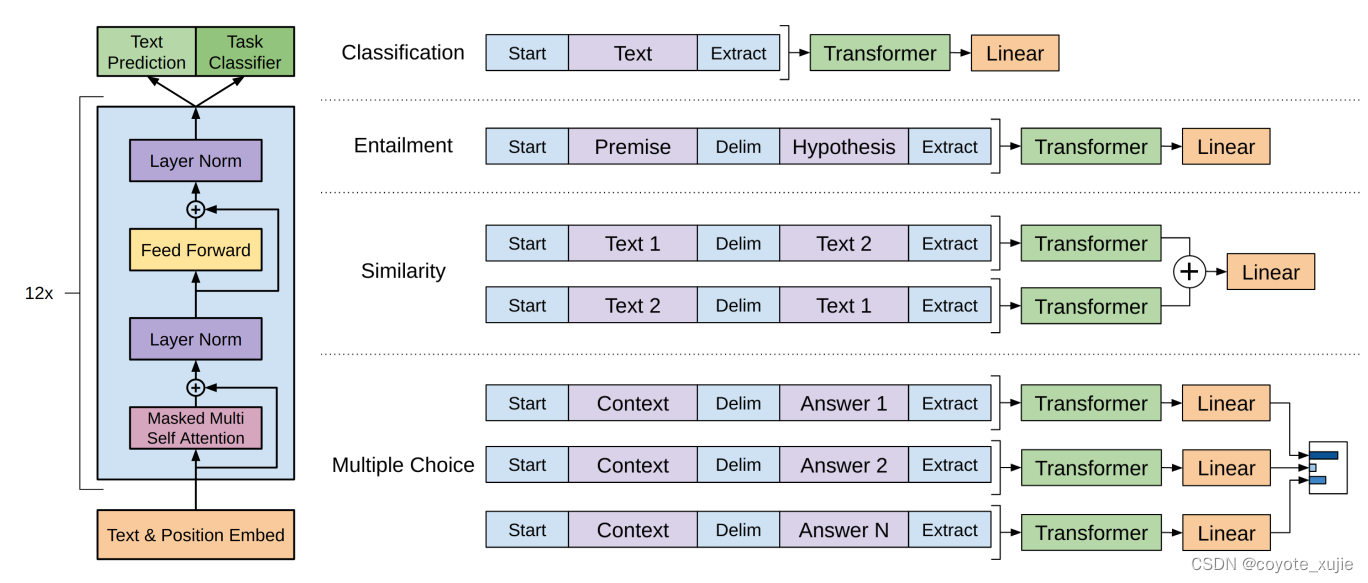
2 BERT微调策略: 适应具体任务的精妙调整
BERT微调策略是为了使该模型更好地适应具体任务的一种巧妙调整。

2.1 利用不同的representation和分类器进行微调
BERT模型产生了多层不同抽象级别的representation,微调过程中可以选择合适的层级,根据任务需求进行使用。
分类器被引入,将任务相关的representation输入其中,通过fine-tuning的方式调整模型参数,以更好地适应具体任务。
2.2 通过fine-tuning适应具体任务
BERT模型在预训练中学到了丰富的上下文信息,但为了适应特定任务,需要微调模型以调整参数,使得模型能够更好地理解和利用任务相关的特征。
微调的目标是优化模型在任务上的性能,通过梯度下降等优化算法进行参数的调整。
3 T5预训练策略: 统一任务形式以提高通用性
T5预训练策略旨在通过将各种任务转化为通用的Seq2Seq问题,提高模型的通用性。

3.1 利用11B参数的T5模型
T5模型的大规模参数使其能够捕捉更丰富的语言表示,适应更广泛的任务。
大规模参数的使用提高了模型的表达能力,使得其能够更好地处理多样性任务。
3.2 将任务转换为Seq2Seq形式
通过将任务表达为Seq2Seq问题,使得T5模型能够以同一方式处理各种任务。
编码器-译码器结构的设计使得模型能够将输入序列编码为中间表示,再将其解码为与任务相关的输出。
4 GPT3微调策略: 实现零样本和少样本学习的创新方法
GPT3微调策略通过transformer decoder和prompt处理实现了零样本和少样本学习的创新方法。

4.1 利用transformer decoder进行微调
GPT3使用transformer decoder进行微调,这是为了在模型的生成阶段引入任务相关的信息。
Transformer decoder的结构允许模型生成更符合特定任务的输出。
4.2 通过prompt处理实现zero-shot和few-shot学习
引入prompt处理的方式,使得GPT3能够在未经过专门微调的情况下,通过提示理解和执行特定任务。
这种创新方法使得GPT3具备了在零样本和少样本情况下学习任务的能力,大大提高了模型的泛化性。
这些微调策略对应于各自模型的特性,通过巧妙的设计使得模型能够在各种任务上取得更好的性能,展现了不同模型在应对复杂任务时的灵活性和通用性。
结论
从传统训练到预训练和微调的策略演进,为微调成功提供了多样的选择。随着大规模预训练模型的崛起,微调策略的不断创新成为应对多样任务的关键。选择适当的策略,结合模型特性和任务需求,是确保微调过程高效、成功的关键步骤。这一演进不仅推动了NLP领域的发展,也为其他领域的深度学习任务提供了有益的经验。