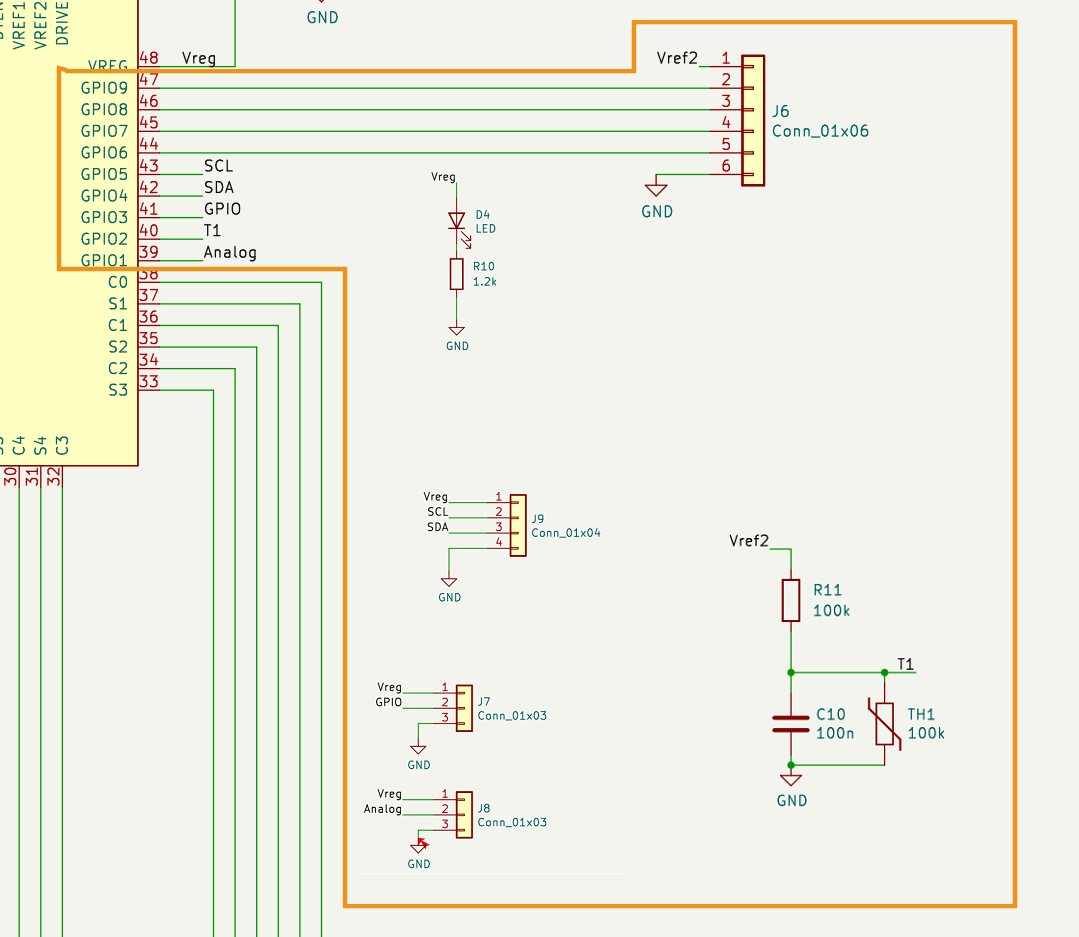
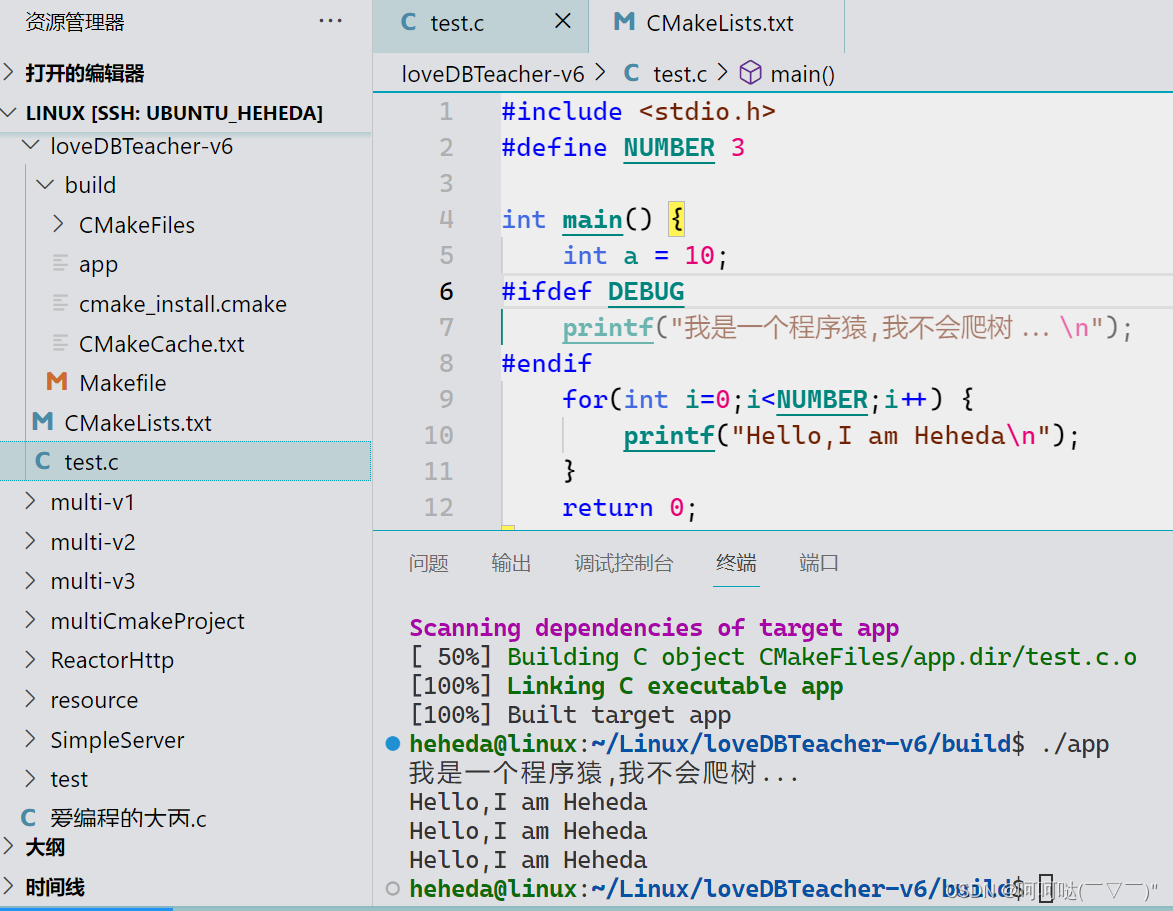
schedule调度的整体流程
- React Fiber Scheduler 是 react16 最核心的一部分,这块在
react-reconciler这个包中 - 这个包的核心是 fiber reconciler,也即是 fiber 结构
- fiber 的结构帮助我们把react整个树的应用,更新的流程,能够拆成每一个 fiber 对象为单元的一个更新的流程
- 这种单元的形式把更新拆分出来之后,给每个不同的任务提供一个优先级,以及我们在更新的过程当中,可以中断
- 因为我们记录更新到了哪一个单元,中断了之后,可以过一会儿再回过头来,继续从这个单元开始,继续之前没有做完的更新
- 在 react 16之前 setState 产生的更新,必须从头到尾更新完成,然后再执行之后的代码
- 如果我们的整个应用树,它的节点非常多,整个更新会导致它占用的js的运行时间会非常的多
- 让页面的其他的一些操作进入一个停滞的状态
- 比如说,动画的刷新或者是我们在 input 里面输入内容的时候,可能产生卡顿的感觉
- 所以,react 16之后,它的整体的更新流程是完全不一样的
- 因为加入了中断,挂起,这样的功能,导致它的整个更新流程的调度变得非常的复杂
- 整个源码体系,它每一个细节,每一个变量的具体作用,都是值得琢磨的
- 理解它出于什么目的这么去设计,这时候才能深入整个react的更新体系中,这样才能慢慢理解
全局变量一览
- 调度过程中的全局变量,基本上都在 react-reconciler/src/ReactFiberScheduler.js 这个js里面
- https://github.com/facebook/react/blob/v16.6.3/packages/react-reconciler/src/ReactFiberScheduler.js
- 这个js的代码是非常多的,它总共有两千五百行代码,而且注释不算多
- 在这个文件里面,会存在着非常多的公共变量,就是说我们定义在这个文件的顶层的变量名
- 就是说我们定义在这个文件顶层作用域上面的很多的变量,在很多方法里面,它们是被共享的
- 这些公共变量对于去理解整个 schedule,它是非常重要的,因为它在很多方法里面都会有调用
- 它什么时候调用,什么时候被修改成什么值,用来记录什么内容
- 对于这些公共变量的理解,一方面来说比较的困难
- 另外一方面来说,它非常的重要
- 如果不能理解这些公共变量的作用,会导致看源码的时候,看到一些地方会变得毫无头绪
几个重点需要关注的变量
// Used to ensure computeUniqueAsyncExpiration is monotonically decreasing.
let lastUniqueAsyncExpiration: number = Sync - 1;
let isWorking: boolean = false;
// The next work in progress fiber that we're currently working on.
let nextUnitOfWork: Fiber | null = null;
let nextRoot: FiberRoot | null = null;
// The time at which we're currently rendering work.
let nextRenderExpirationTime: ExpirationTime = NoWork;
let nextLatestAbsoluteTimeoutMs: number = -1;
let nextRenderDidError: boolean = false;
// The next fiber with an effect that we're currently committing.
let nextEffect: Fiber | null = null;
let isCommitting: boolean = false;
let rootWithPendingPassiveEffects: FiberRoot | null = null;
let passiveEffectCallbackHandle: * = null;
let passiveEffectCallback: * = null;
let legacyErrorBoundariesThatAlreadyFailed: Set<mixed> | null = null;
// Used for performance tracking.
let interruptedBy: Fiber | null = null;
let stashedWorkInProgressProperties;
let replayUnitOfWork;
let mayReplayFailedUnitOfWork;
let isReplayingFailedUnitOfWork;
let originalReplayError;
let rethrowOriginalError;
-
isWorking
- commitRoot和renderRoot开始都会设置为true,然后在他们各自阶段结束的时候都重置为false
- 用来标志是否当前有更新正在进行,不区分阶段
-
isCommitting
- commitRoot开头设置为true,结束之后设置为false
- 用来标志是否处于commit阶段
-
nextUnitOfWork
- 用于记录render阶段Fiber树遍历过程中下一个需要执行的节点。
- 在resetStack中分别被重置
- 它只会指向workInProgress
-
nextRoot & nextRenderExpirationTime
- 用于记录下一个将要渲染的root节点和下一个要渲染的任务的
-
nextEffect
- 用于commit阶段记录firstEffect -> lastEffect链遍历过程中的每一个Fiber
下面是其他的一些全局变量
// Linked-list of roots
let firstScheduledRoot: FiberRoot | null = null;
let lastScheduledRoot: FiberRoot | null = null;
let callbackExpirationTime: ExpirationTime = NoWork;
let callbackID: *;
let isRendering: boolean = false;
let nextFlushedRoot: FiberRoot | null = null;
let nextFlushedExpirationTime: ExpirationTime = NoWork;
let lowestPriorityPendingInteractiveExpirationTime: ExpirationTime = NoWork;
let hasUnhandledError: boolean = false;
let unhandledError: mixed | null = null;
let isBatchingUpdates: boolean = false;
let isUnbatchingUpdates: boolean = false;
let completedBatches: Array<Batch> | null = null;
let originalStartTimeMs: number = now();
let currentRendererTime: ExpirationTime = msToExpirationTime(
originalStartTimeMs,
);
let currentSchedulerTime: ExpirationTime = currentRendererTime;
// Use these to prevent an infinite loop of nested updates
const NESTED_UPDATE_LIMIT = 50;
let nestedUpdateCount: number = 0;
let lastCommittedRootDuringThisBatch: FiberRoot | null = null;
-
firstScheduledRoot & lastScheduledRoot
- 用于存放有任务的所有root的单链表结构
- 在findHighestPriorityRoot用来检索优先级最高的root
- 在addRootToSchedule中会修改
-
callbackExpirationTime & callbackID
- 记录请求ReactScheduler的时候用的过期时间,如果在一次调度期间有新的调度请求进来了
- 而且优先级更高,那么需要取消上一次请求,如果更低则无需再次请求调度。
- callbackID是ReactScheduler返回的用于取消调度的 ID
-
isRendering
- performWorkOnRoot开始设置为true,结束的时候设置为false
- 表示进入渲染阶段,这是包含render和commit阶段的
-
nextFlushedRoot & nextFlushedExpirationTime
- 用来标志下一个需要渲染的root和对应的expirtaionTime
-
deadline & deadlineDidExpire
- deadline是ReactScheduler中返回的时间片调度信息对象
- 用于记录是否时间片调度是否过期,在shouldYield根据deadline是否过期来设置
-
isBatchingUpdates & isUnbatchingUpdates & isBatchingInteractiveUpdates
- batchedUpdates、unBatchedUpdates,deferredUpdates、interactiveUpdates等这些方法用来存储更新产生的上下文的变量
-
originalStartTimeMs
- 固定值,js 加载完一开始计算的时间戳
-
currentRendererTime & currentSchedulerTime
- 计算从页面加载到现在为止的毫秒数,后者会在isRendering === true的时候
- 用作固定值返回,不然每次requestCurrentTime都会重新计算新的时间。
-
以上,每一个全局变量给它拿出来,单独解释它是在什么地方被用到
-
以及它是用来记录哪些东西,是在什么情况下,才会发挥了哪些作用
调度流程
1 )第一阶段
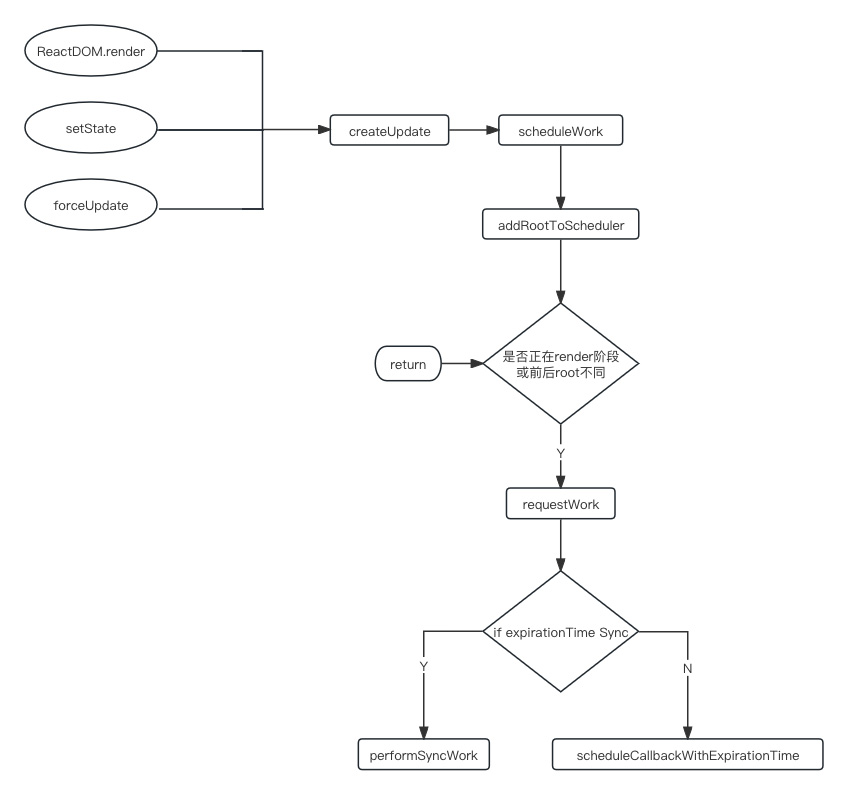
- 在调用
ReactDOM.render,setState,forceUpdate,都会产生一个update - 产生update之后,进入 scheduleWork 进行调度
- scheduleWork 第一步操作是
addRootToScheduler - 在一个rect应用当中,它不仅仅可能只存在一个 root 节点
- 因为我们通过
ReactDOM.render调用的时候,就会创建一个 root 节点 - 如果调用多次
ReactDOM.render,就可以创建多个 root 节点 - 这个时候, 整个应用中就会存在着多个react的节点
- 在这些节点,可以单独在内部进行 setState,进行调度
- 它们都会有独立的 updateQueen,有独立的一个 fiber tree 来进行应用的更新
- 一个应用当中可能会存在多个root, 所以这个时候就要去维护一下
- 因为,在同一时间可能有多个root会有更新存在, 所以有这么一个地方去维护它
- 这就是
addRootToScheduler的一个作用
- scheduleWork 第一步操作是
addRootToScheduler加入之后, 要先判断一下是否正在 render 阶段 或者 前后的root不同- 如果是,则调用
requestWork,就要开始进行工作了,如果不是,我们就要return - 因为之前的任务可能正在做,或者处于目前这个阶段,不需要主动的再去调用一个
requestWork来更新了
- 如果是,则调用
- 关于
requestWork它里面做了什么?- 它判断
expirationTime,它是否是Sync - 计算
expirationTime调用的是computeExpirationForFiber - 这时候会根据 fiber 是否有
ConcurrentMode的特性来计算 Sync 的 expirationTime 或者是异步的 expirationTime - 这个时候它最终会导致整体的一个更新模式的不同
- 因为如果是 Sync 的模式代表着我们这个更新要立马进行执行,要立马更新到最终的 dom tree 上面
- 所以我们调用的是
performSyncWork - 而如果它是一个 Async 模式的,那么说明它的优先级不是特别高,那么他会进入一个调度的流程,因为它可以不立即更新
- 它本身的期望是在 expirationTime 结束之前,能够被更新完成就可以了, 所以它的优先级非常低,会进入到一整个调度的流程,即
scheduleCallbackWithExpirationTime
- 它判断
2 )下一阶段
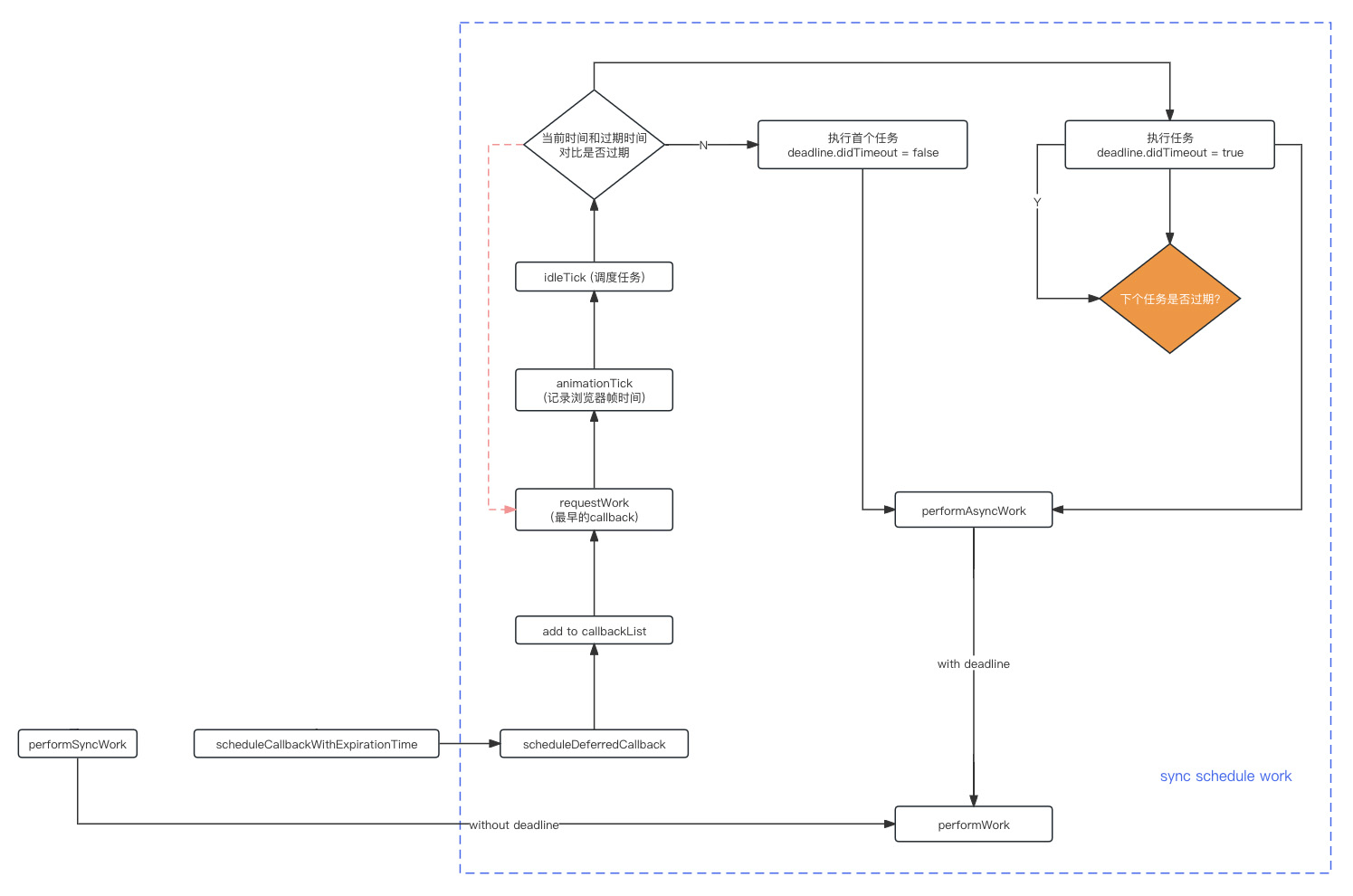
- 整个调度的流程 react 给它单独区分了一个包
packages/scheduler- 用蓝色的框给它圈起来,叫做 async schedule work
- 这一部分就涉及到整个异步的调度的过程
- 它利用的是浏览器当中一个较新的API叫做
requestIdleCallback, 能够让浏览器优先进行他自己的任务 - 比如说更新动画,在每一帧有多余的时间的时候,它调用react给他设置了一个callback
- 然后就可以去执行react一个更新,然后react会自己去记一个时
- 在这个时间内,我可以执行我自己的工作
- 如果这个时间内我的工作没有执行完,我要把javascript的运行的主动权交还给浏览器
- 让浏览器去执行它新的一些动画的更新之类的,来让浏览器保证高优先级的任务能够被立即执行
- 所以,这就是这个蓝色这一片区域的一个作用
- 它利用的是浏览器当中一个较新的API叫做
- 在这里面调用的一个方法叫做
scheduleDeferredCallback, 然后会有一个 callbackList - 因为可能多次调用这个方法去把 callback 设置进去
- 然后在这里面,我们虽然想要使用
requestIdleCallback这个API - 但是, 大部分浏览器还不支持, 浏览器的兼容性也不是特别好
- 所以在react里面,它实现了自己的一个模拟 requestIdleCallback 的一个方式
- 它通过
requestAnimationFrame和js的任务队列的原理来进行了一个模拟
- 它通过
- 在调用
requestIdleCallback之后,说明浏览器有空了,可以去执行react的更新了- 这就是我们加入到这里面的异步的更新任务,它的优先级比较低,浏览器有空的时候,再来执行
- 因为 react 的任务它是有一个 expirationTime 的
- 所以它这里要判断一下我的任务有没有超时
- 如果已经超时了,要把所有加入callbackList队列的超时任务都执行掉
- 因为任务已经超时了,所以必须要立刻完成
- 执行到第一个非超时的任务之后,若还有时间,可以继续执行
- 如果没有时间了,要把主动权交还给浏览器,让浏览器来做其他一些任务
- 最终要执行这个任务,执行的是什么?
- 调用一个
performAsyncWork这个方法 - 它会执行react的schedule里面的回调函数
- 在调用这个方法的时候,schedule 会传给这个方法一个叫做deadline的一个对象,这个对象是用来判断。
- 在进入
performAsyncWork的时候,就进入到react的一个更新流程 - react的更新流程中,它去遍历整一棵树,会遍历每棵树的每个单元,然后对它进行一个更新的操作
- 每个单元更新完了之后,回过头来通过这个deadline对象判断一下,现在是否还有 js 运行的一个时间片
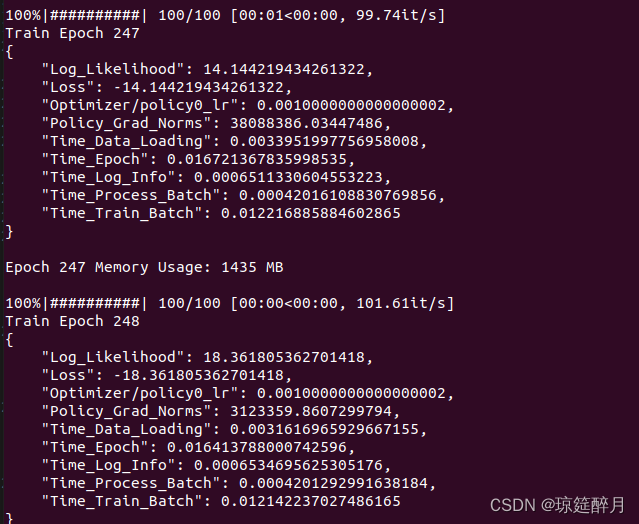
- 因为调度器每一次调用
performAsyncWork的任务,它是有一个时间限制的 - 比如说默认的情况下是22毫秒,在这个时间片内你可以去执行的操作
- 这就是这个 deadline 对象它的一个作用
- 调用一个
- 最终调用
performWork这个方法 performWork它调用的是没有deadline的performAsyncWork它调用的是有deadline的- 最终在 if deadline 这里汇集在一起
- 根据是否有 deadline 进入下个阶段的循环
3 )第三个阶段
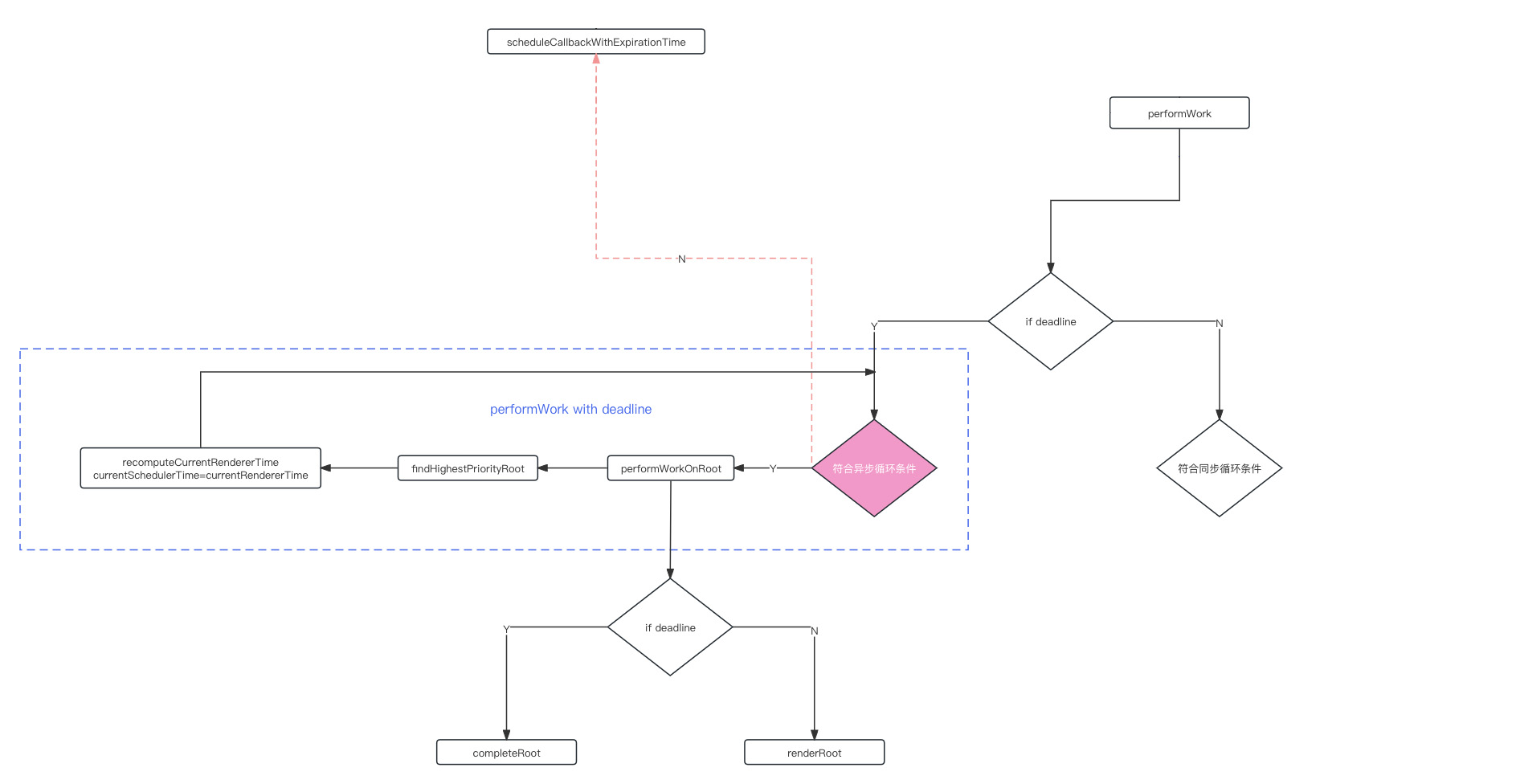
- 根据是否有 deadline 进入循环
- 这个循环是什么呢?
- 这个循环就是要遍历整棵树每一个 fiber 节点进行的更新操作
- 对于同步任务,它会遍历完整棵树,然后把整个应用更新就完了
- 因为它是同步的,跟以前的react用法是一样的
- 对于异步的来讲,如果符合条件
- 进入
performWorkOnRoot, 它做的其实是一个更新的过程 - 然后
findHighestPriorityRoot找到一个最高优先级的节点之后 - 对这个节点进行一个更新
recomputeCurrentRendererTime - 对于有 deadline 的情况,调用
performWorkOnRoot进行更新任务之后 - 在
renderRoot里面,它还会有一个循环去判断 deadline - 最终要等这个
performWorkOnRoot返回之后,才会继续下面的操作 - 对于有 deadline 的情况,会重新请求一个时间,然后去判断一下deadline是否已经过期
- 如果已经过期的话,会回过头来到红色区域再进行一个判断
- 如果发现 deadline 已经过期的话,又会去继续调用这个
scheduleCallbackWithExpirationTime - 再次进行异步的回调, 它这是一个递归的过程
- 因为之前第一阶段加入了一个
addRootToScheduler - 它就有一个队列,在维护着所有的更新的情况
- 对于每一次更新,只能更新一个优先级的任务,以及一个root上的任务
- 上述红色这块区域,它就是一个循环的条件判断
- 它每次更新一个节点上的一个优先级任务
- 具体的操作在
performWorkOnRoot里面 - 更新完之后, 它会去调用相对应的方法
- 在这个root上对应的优先级任务更新完之后
- 它要找到下一个root上面的对应优先级的任务,然后再次进入这个循环
- 所以这个就是deadline它的一个用处,它帮助我们去判断是否应该跳出循环了
- 如果我们一直处于这个循环,要把所有任务都更新完,那么可能占用的js运行时间会非常的长
- 导致可能的动画停滞或用户输入卡顿。
- 在这个 deadline 超过了之后,这个循环直接跳出
- 然后再继续跳回到这个
scheduleCallbackWithExpirationTime - 再次进入一个调度,然后把js的执行权交给浏览器,让它先执行动画或者用户输入的响应
- 等有空了,再回过头来再去执行这个任务,然后又回到 红色区域判断这里
- 之前没完成的任务,再继续这么一个循环
- 最终达到的目的是要把 root 里面的所有的节点上面的所有更新都执行完为止
- 这就是整的一个循环的一个过程
- 进入
整体流程图
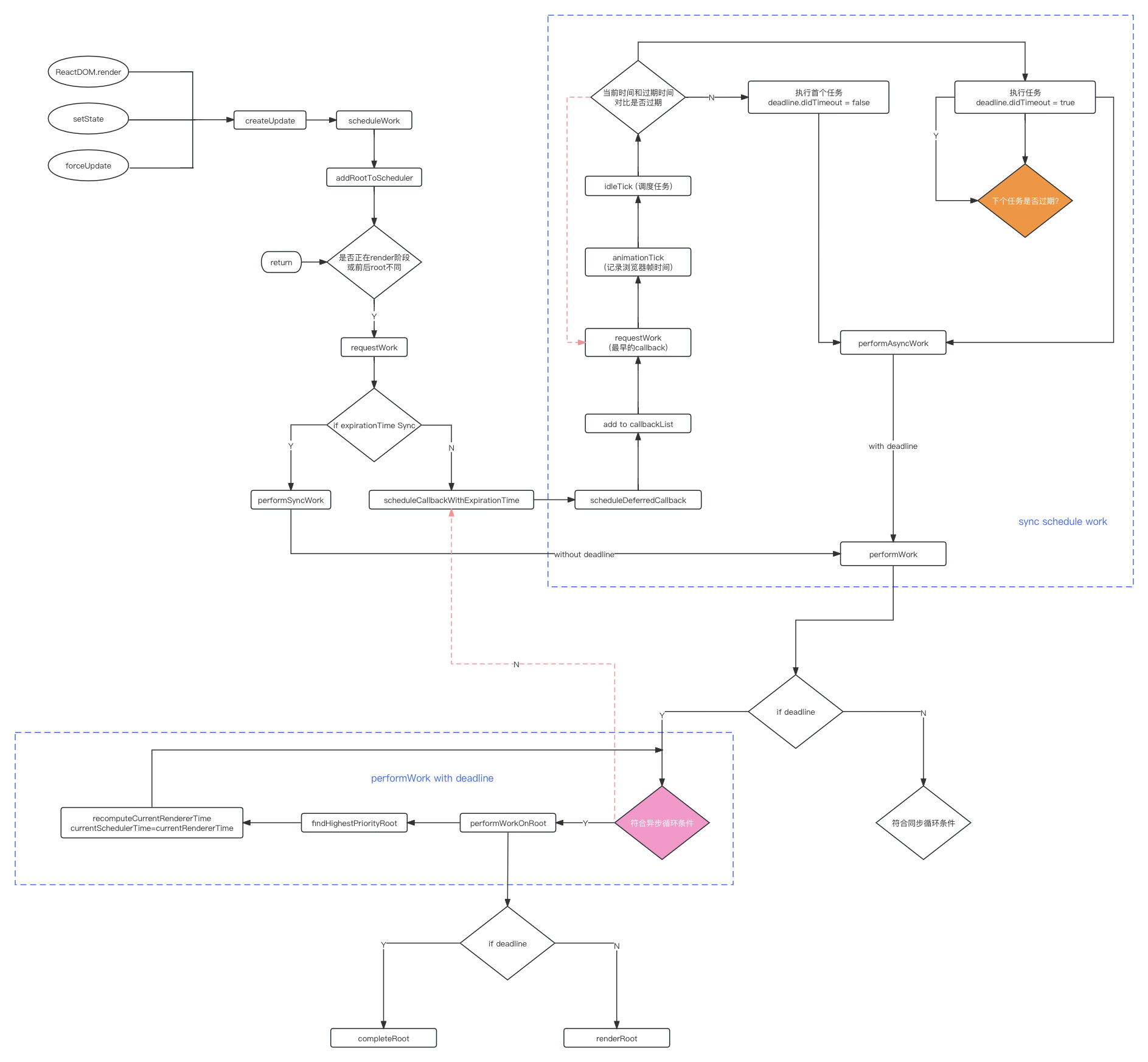
总结
- 通过
ReactDOM.render,setState,forceUpdate这几个方法产生了更新 - 产生了更新之后,维护一个队列去保存这些更新以及对应的root节点
- 然后,根据它任务的优先级来进行判断,判断是同步的更新还是异步的更新
- 对于异步的更新,如果有多个任务,它会一直处于先执行浏览器优先级最高的更新
- 有空的时候回过头来更新 react 树
- 如果 root 上对应的某一个优先级的任务更新完了
- 那么先输出到dom上,然后执行下一个更新
- 在这个循环的过程当中,根据这个调度器传入的 deadline 对象
- 判断是否有超时,如果超时,再回过头去进行一个调度
- 先把执行权给浏览器,让它保证动画的流畅运行
- 等它有空,再回过头来继续执行的任务
- 这就是整个调度的核心原理
- 目的是
- 保证我们低优先级的react更新,不会阻止浏览器的一些高要求的动画更新
- 能够保证浏览器的一些动画能够达到30帧以上这么一个情况
- 以上就是react整个的调度过程