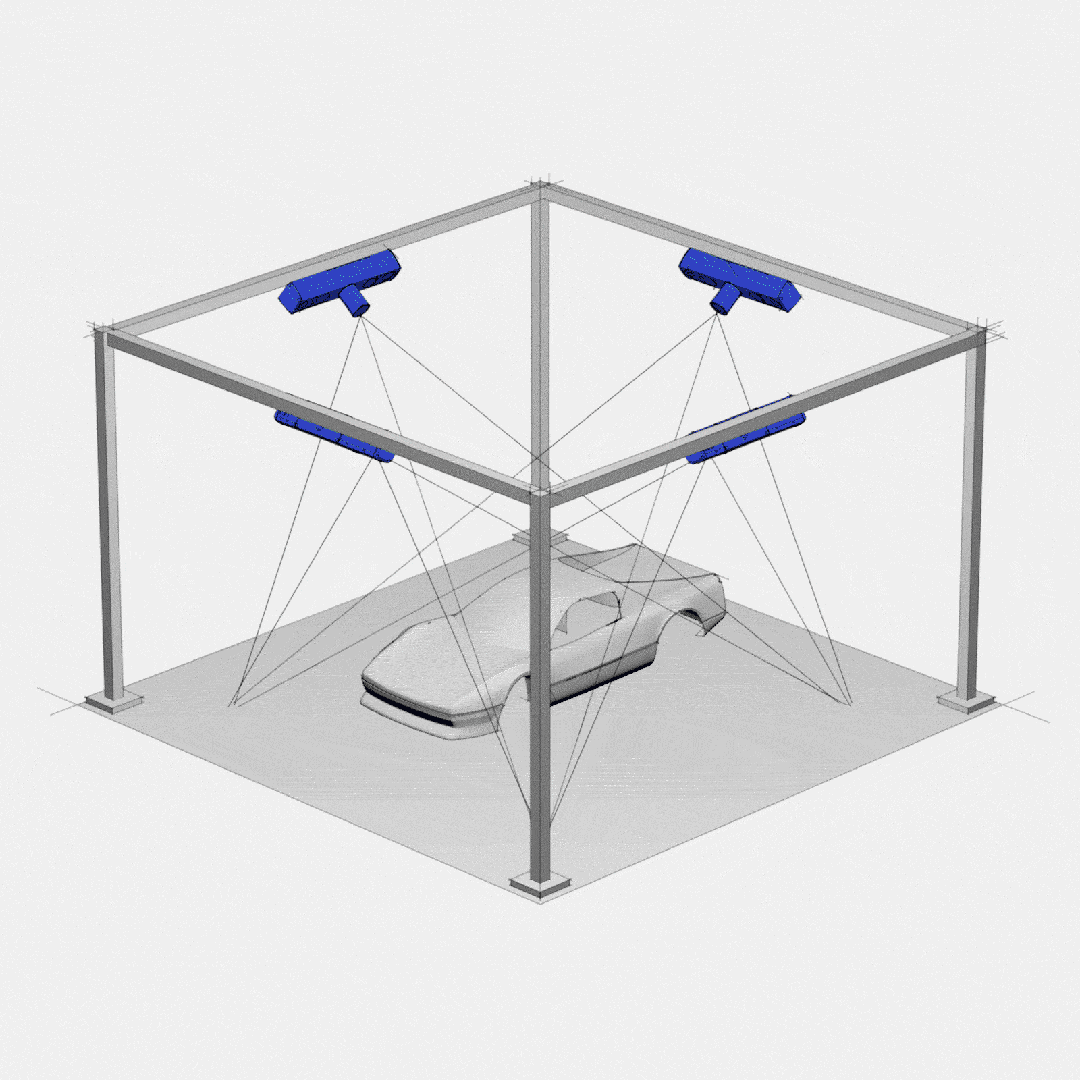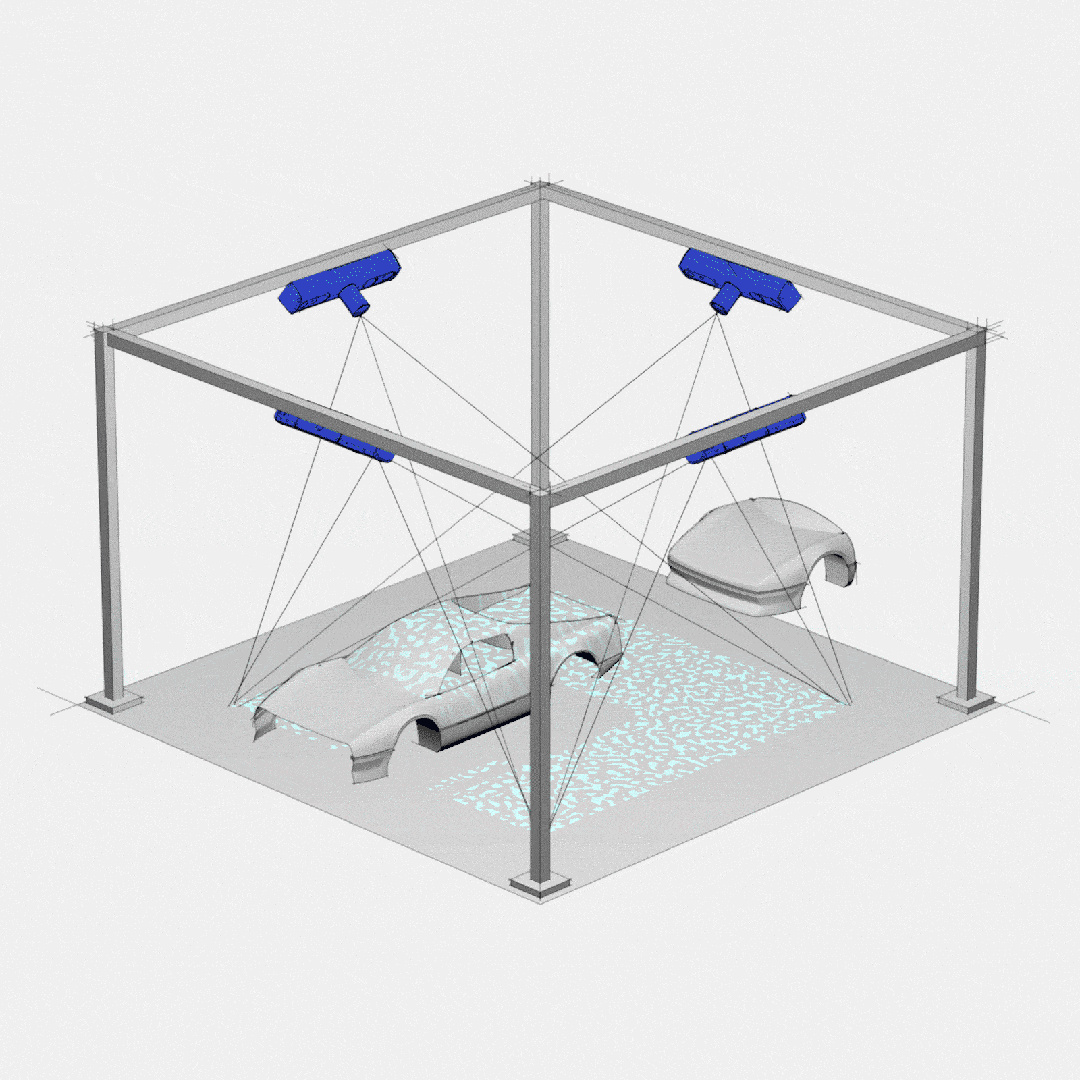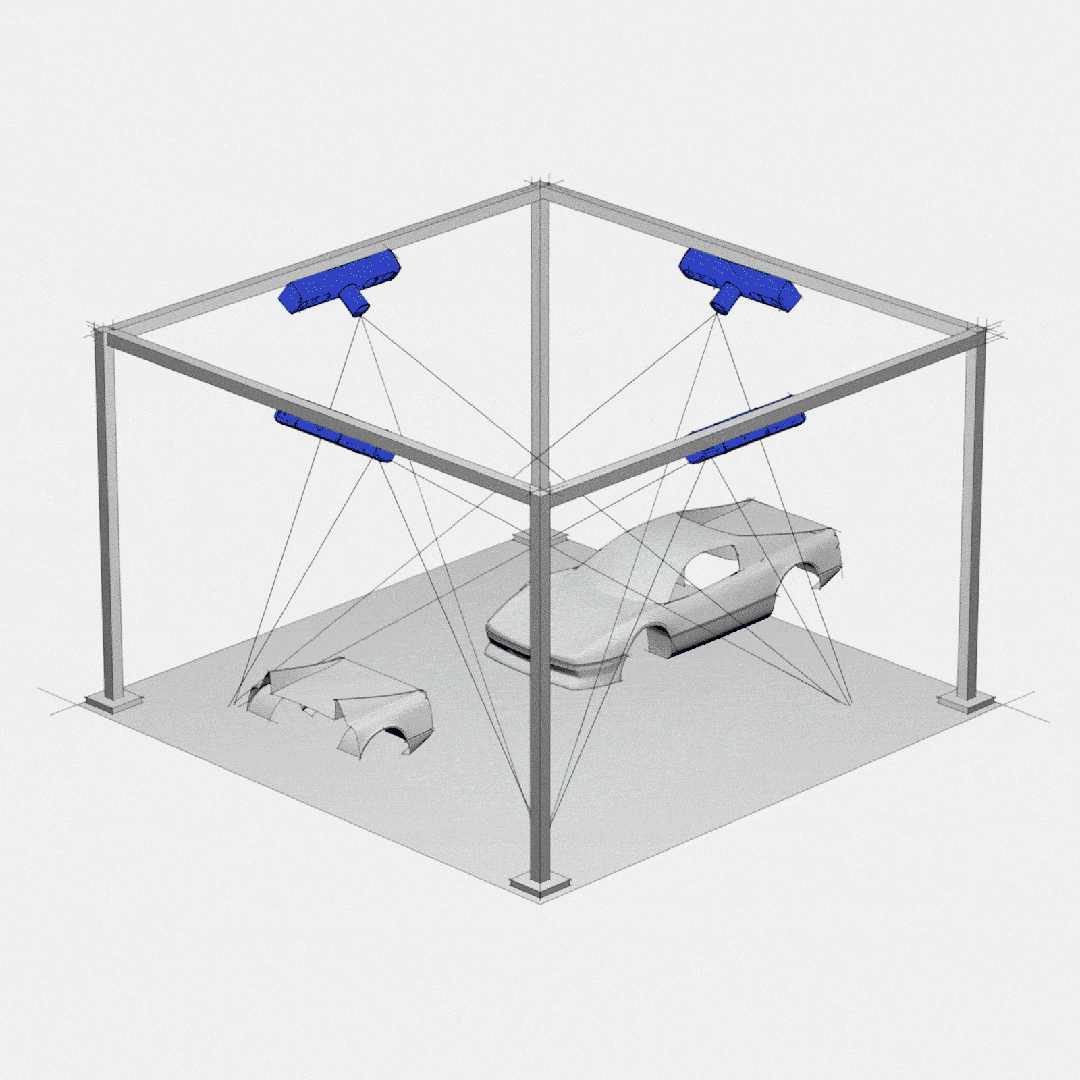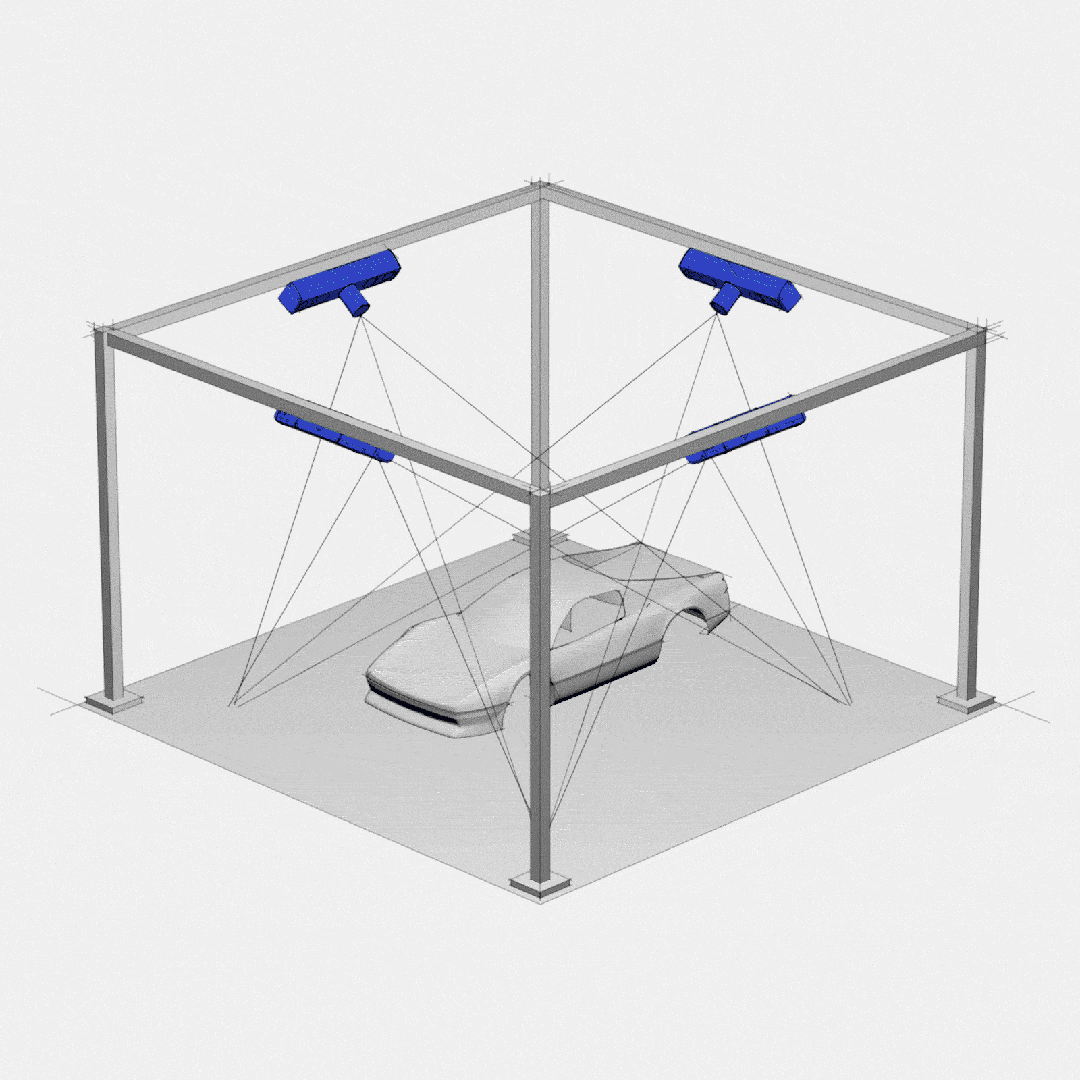
Topic的分区和副本机制
分区有什么用呢?
作用:
1- 避免单台服务器容量的限制: 每台服务器的磁盘存储空间是有上限。Topic分成多个Partition分区,可以避免单个Partition的数据大小过大,导致服务器无法存储。利用多台服务器的存储能力,提升Topic的数据存储条数。
2- 提升Topic的吞吐量(数据读写速度): 利用多台服务器的数据读写能力、网络等资源
分区的数量有没有限制?
没有限制,分区数量和Kafka集群中的broker节点个数没有任何关系。
推荐Topic的分区数量不要超过Kafka集群中的broker节点个数的3倍,这只是一个推荐/经验值。
副本有什么用呢?
作用: 通过多副本的机制,提升数据安全性。但是副本过多,会导致冗余(重复)的数据过多
副本的数量有没有限制?
有限制,副本数量最大不能够超过Kafka集群中的broker节点个数。
推荐的分区的副本数量是1-3个。具体设置多少个,根据企业的数据重要程度进行选择。如果数据重要,可以将副本数设置大一些;如果数据不太重要,可以将副本数设置小一些。
消息存储机制和查询机制
消息存储机制:生产的消息在Kafka集群中,是如何存储。
查询机制:消费者在消费消息的时候,是如何找到对应offset(偏移量)的消息。
消息存储机制

1-Topic的数据存放路径是:/export/server/kafka/data。在该目录下,还有其他的目录。而且是以Topic进行划分,具体目录的命名规则是:Topic名称-分区编号
2- Topic目录下,存放的是消息的数据文件。并且是成对出现,也就是xx.log和xx.index文件
1-xx.log和xx.index它们的作用是什么?
答:
xx.log: 称之为segment片段文件,也就是一个Partition分区的数据,会被分成多个segment(log)片段文件进行存储。
xx.index: 称之为索引文件,该文件的作用是用来加快对xx.log文件内容检索的速度
2-xx.log和xx.index文件名称的意义?
答: 这个数字是xx.log文件中第一条消息的offset(偏移量)。offset偏移量从0开始编号。
3-为什么一个Partition分区的数据要分成多个xx.log(segment片段文件)文件进行存储?
答:
1- 如果一个文件的数据量过大,打开和关闭文件都非常消耗资源
2- 在一个大的文件中,检索内容也会非常消耗资源
3- Kafka只是用来临时存储消息数据。会定时将过期数据删除。如果数据放在一个文件中,删除的效率低;如果数据分成了多个segment片段文件进行存储,删除的时候只需要判断segment文件最后修改时间,如果超过了保留时间,就直接将整个segment文件删除。该保留时间是通过server.properties文件中的log.retention.hours=168进行设置,默认保留168小时(7天)
index文件内容基本结构:

查询机制

查询步骤:
1- 首先先确定要读取哪个xx.log(segment片段)文件。368776该offset的消息在368769.log文件中
2- 查询xx.log对应的xx.index,查询该条消息的物理偏移量范围
3- 根据消息的物理偏移量范围去读取xx.log文件(底层是基于磁盘的顺序读取)
4- 最终就获取到了具体的消息内容
扩展内容: 磁盘的读写中,有两种方案:随机读写 和 顺序读写。顺序读写的速度会更快
参考连接: https://www.cnblogs.com/yangqing/archive/2012/11/13/2767453.html
Kafka为什么有非常高的吞吐能力/读写性能
Kafka中生产者数据分发策略
何为生产者的数据分发策略呢?
指的就是生产者生产的消息,是如何保存到具体分区上
分发策略如下这些:
- 1- 随机分发策略:将消息发到到随机的某个分区上,还是发送到Leader主副本上。Python支持,Java不支持
- 2- 指定分区策略:将消息发到指定的分区上面。Python支持,Java支持
- 3- Hash取模策略:对消息的key先取Hash值,再和分区数取模。Python支持,Java支持
- 4- 轮询策略:在Kafka的2.4及以上版本,已经更名成粘性分发策略。Python不支持,Java支持
- 5- 自定义分发策略:Python支持,Java支持
- 0- 分发源码查看方式
1- 导入DefaultPartitioner
from kafka.partitioner import DefaultPartitioner
2- 进入到DefaultPartitioner,查看__call__源码
- 1- 随机分发策略
def send(self, topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None):
当在发送数据的时候, 如果只传递了topic 和 value,没有指定key的时候, 那么此时就采用随机策略
在kafka中, 专门提供了一个默认的分发数据的类: DefaultPartitioner
def __call__(cls, key, all_partitions, available):
"""
如果 key为 null, 那么随机返回一个分区的编号
"""
if key is None:
if available:
return random.choice(available)
return random.choice(all_partitions)
# 后续的代码 当没有key的时候,压根就执行不到
idx = murmur2(key)
idx &= 0x7fffffff
idx %= len(all_partitions)
return all_partitions[idx]
- 2- 指定分区策略
def send(self, topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None):
当在发送数据的时候, 如果指定了partition参数, 表示的采用指定分区的方案, 分区的编号从0开始
当指定了partition的参数后, 与DefaultPartitioner没有任何的关系
- 3- Hash取模策略
def send(self, topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None):
当在发送数据的时候, 如果传递了topic 和 value 以及key的时候, 那么此时就是采用hash取模策略
注意: 相同key的返回的hash值是一致的, 同样对应分区也是同一个。也就是要注意数据倾斜的问题。
在kafka中, 专门提供了一个默认的分发数据的类: DefaultPartitioner
def __call__(cls, key, all_partitions, available):
"""
如果 key为 null, 那么随机返回一个分片的编号
"""
if key is None:
if available:
return random.choice(available)
return random.choice(all_partitions)
# 当有key的时候 , 执行下列代码. 此处的代码其实就是hash取模的方案
idx = murmur2(key)
idx &= 0x7fffffff
idx %= len(all_partitions)
return all_partitions[idx]
- 4- 自定义分区策略: 参考DefaultPartitioner
# 第一步:创建自己的分区类
class MyPartitioner(object):
# 第二步:实现__call__。key:消息中的key;all_partitions:所有的分区列表;available:所有可用分区的列表
@classmethod
def __call__(cls, key, all_partitions, available):
# 第三步:分发逻辑根据自己要求进行实现
return 0
# 第四步:导入自己的分区类
import MyPartitioner
# 第五步:调用
producer = KafkaProducer(
bootstrap_servers=['node1.itcast.cn:9092','node2.itcast.cn:9092'],
partitioner=MyPartitioner()
)
Java中的 轮询分发策略 和 粘性分发策略介绍:
轮询分发策略: 在Kafka的老版本中存在的一种分发策略,当生产数据的时候,只有value但是没有key的时候,采用轮询。
优点: 可以保证每个分区拿到的数据基本是一样,因为是一个一个的轮询的分发
缺点: 如果采用异步发送方式,意味着一批数据发送到broker端,由于是轮询策略,会将这一批数据拆分为多个小的批次,分别再写入到不同的分区里面去,写入进去以后,每个分区都会给予响应,会影响写入效率。
粘性分发策略: 在Kafka新版本中存在的一种分发策略。当生产数据的时候,只有value但是没有key的时候,采用粘性分发策略
优点: 在发送数据的时候,首先会随机的选取一个分区,然后尽可能将数据分发到这个分区上面去,也就是尽可能粘着这个分区。该分发方式,在异步发送的操作中,效率比较高。
缺点: 在数据发送特别快的时候,可能会导致某个分区的数据比其他分区数据多很多,造成大量的数据集中在一个分区上面
Kafka消费者的负载均衡机制

Kafka集群中每分钟新产生400条数据,下游的一个消费者每分钟能够处理400条数据。
随着业务发展,Kafka集群中每分钟新产生1200条数据,下游的一个消费者每分钟能够处理400条数据。
答:会导致broker中积压的消息条数越来越多,造成消息处理不及时。可以增加消费者数量,并且将这些消费者放到同一个消费组当中
随着业务发展,Kafka集群中每分钟新产生1600条数据,下游的一个消费者每分钟能够处理400条数据。
答:会导致broker中积压的消息条数越来越多,造成消息处理不及时。再增加消费组中消费者的个数已经无法解决问题。
如何解决:
1- 增加消费组中消费者的个数
2- 提高下游消费者对消息的处理效率
Kafka消费者的负载均衡机制
1- 在同一个消费组中,消费者的个数最多不能超过Topic的分区数。如果超过了,就会有一些消费者处于闲置状态,消费不到任何数据。
2- 在同一个消费组中,一个Topic中一个分区的数据,只能被同个消费组中的一个消费者所消费,不能被同个消费组中多个消费者所消费。但是一个消费组内的一个消费者可以消费多个分区的数据。也就是分区和消费者的对应关系,多对一
3- 不同的消费组中的消费者,可以对一个Topic的数据同时消费,也就是不同消费组间没有任何关系。也就是Topic的数据能够被多个消费组中的消费者重复消费。
补充:
查看消费组中有多少个消费者,用来避免消费者个数超过分区个数。
./kafka-consumer-groups.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --group g_1 --members --describe
数据不丢失机制
生产端保证消息不丢失
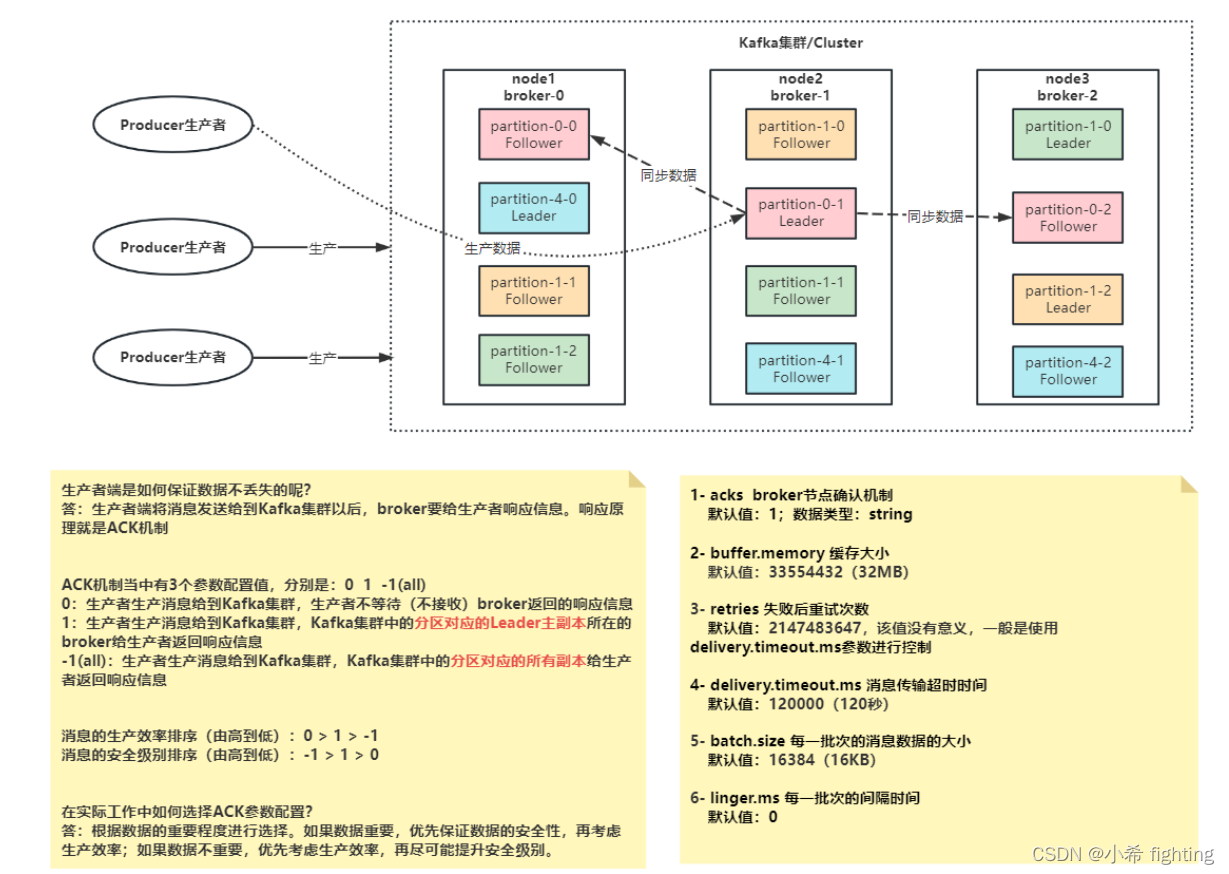
生产者端是如何保证数据不丢失的呢?
答:生产者端将消息发送给到Kafka集群以后,broker要给生产者响应信息。响应原理就是ACK机制
ACK机制当中有3个参数配置值,分别是:0 1 -1(all)
0:生产者生产消息给到Kafka集群,生产者不等待(不接收)broker返回的响应信息
1:生产者生产消息给到Kafka集群,Kafka集群中的分区对应的Leader主副本所在的broker给生产者返回响应信息
-1(all):生产者生产消息给到Kafka集群,Kafka集群中的分区对应的所有副本给生产者返回响应信息
消息的生产效率排序(由高到低):0 > 1 > -1
消息的安全级别排序(由高到低):-1 > 1 > 0
如何选择ACK参数配置?
答:根据数据的重要程度进行选择。如果数据重要,优先保证数据的安全性,再考虑生产效率;如果数据不重要,优先考虑生产效率,再尽可能提升安全级别。
相关的参数:
1- acks broker节点确认机制
默认值:1;数据类型:string
2- buffer.memory 缓存大小
默认值:33554432(32MB)
3- retries 失败后重试次数
默认值:2147483647,该值没有意义,一般是使用delivery.timeout.ms参数进行控制
4- delivery.timeout.ms 消息传输超时时间
默认值:120000(120秒)
5- batch.size 每一批次的消息数据的大小
默认值:16384(16KB)
6- linger.ms 每一批次的间隔时间
默认值:0
Broker端如何保证数据不丢失
Broker端通过多副本机制确保数据不丢失。同时需要生产者端将acks设置为-1
消费者如何保证数据不丢失
流程:
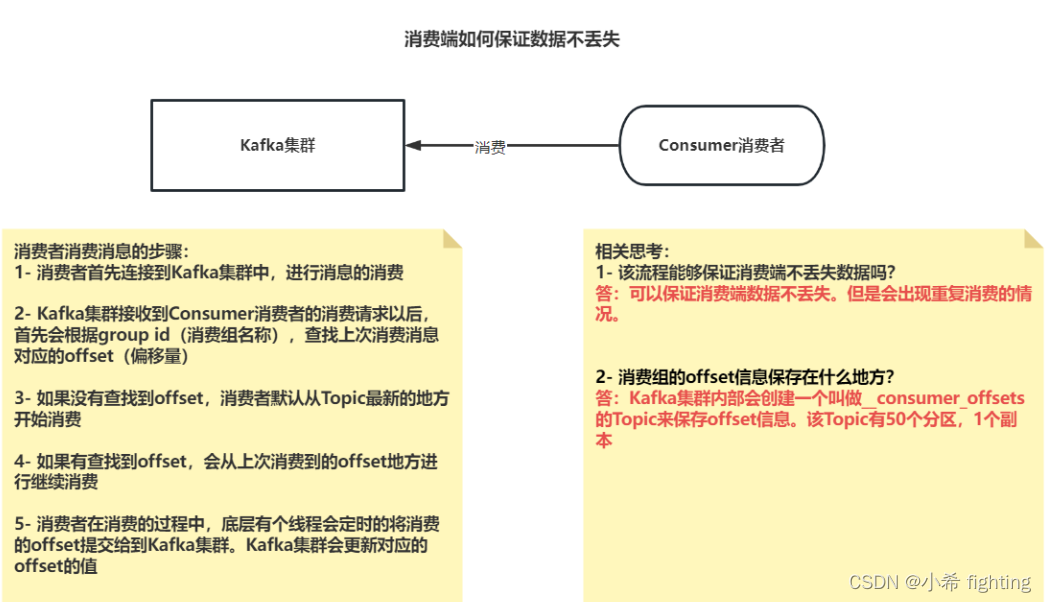
消费者消费消息的步骤:
1- 消费者首先连接到Kafka集群中,进行消息的消费
2- Kafka集群接收到Consumer消费者的消费请求以后,首先会根据group id(消费组名称),查找上次消费消息对应的offset(偏移量)
3- 如果没有查找到offset,消费者默认从Topic最新的地方开始消费
4- 如果有查找到offset,会从上次消费到的offset地方进行继续消费
4.1- 首先先确定要读取的这个offset偏移量在哪个segment文件当中
4.2- 查询这个segment文件对应的index文件,根据offset确定这个消息在log文件的什么位置,也就是确定消息的物理偏移量
4.3- 读取log文件,查询对应范围内的数据即可
4.4- 获取最终的消息数据
5- 消费者在消费的过程中,底层有个线程会定时的将消费的offset提交给到Kafka集群。Kafka集群会更新对应的offset的值
1- 该流程能够保证消费端不丢失数据吗?
答:可以保证消费端数据不丢失。但是会出现重复消费的情况。
2- 消费组的offset信息保存在什么地方?
答:Kafka集群内部会创建一个叫做__consumer_offsets的Topic来保存offset信息。该Topic有50个分区,1个副本
Kafka中消费者如何对数据仅且只消费一次?
1- 将消费者的 enable.auto.commit 属性设置为 false,并手动管理消费者的偏移量。这样可以确保消费者在处理完所有消息后才更新偏移量,避免重复消费数据。也就是将消息的消费、消息业务处理代码、offset提交代码放在同一个事务当中。
2- 使用幂等生产者或事务性生产者来确保消息只被发送一次。这样可以避免重复发送消息,从而避免消费者重复消费数据。
3- 在消息中加入唯一的ID
在提交偏移量的时候,有二种提交方式: 自动提交偏移量 和 手动提交偏移量,手动提交又分了同步和异步
- 自动提交偏移量
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from kafka import KafkaConsumer
# 指定远端的环境地址
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# pyspark程序需要有入口函数main
# main函数快捷键:main+回车
if __name__ == '__main__':
print("自动提交offset偏移量")
# 创建Kafka消费者
# enable_auto_commit=True:自动提交offset偏移量
consumer = KafkaConsumer(
'test01',
bootstrap_servers=['node1.itcast.cn:9092','node2.itcast.cn:9092'],
group_id='g_01',
enable_auto_commit=True
)
for message in consumer:
topic = message.topic
partition = message.partition
value = message.value.decode('UTF-8')
# key = message.key.decode('UTF-8')
key = message.key
offset = message.offset
print(f'消费到的消息信息:topic={topic},partition={partition},value={value},key={key},offset={offset}')
- 手动提交偏移量
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from kafka import KafkaConsumer
# 指定远端的环境地址
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# pyspark程序需要有入口函数main
# main函数快捷键:main+回车
if __name__ == '__main__':
print("手动提交offset偏移量")
# 创建Kafka消费者
# enable_auto_commit=False:关闭自动提交offset偏移量
consumer = KafkaConsumer(
'test01',
bootstrap_servers=['node1.itcast.cn:9092','node2.itcast.cn:9092'],
group_id='g_01',
enable_auto_commit=False
)
for message in consumer:
topic = message.topic
partition = message.partition
value = message.value.decode('UTF-8')
# key = message.key.decode('UTF-8')
key = message.key
offset = message.offset
print(f'消费到的消息信息:topic={topic},partition={partition},value={value},key={key},offset={offset}')
# 手动提交偏移量
# 同步提交
# consumer.commit()
# 异步提交
consumer.commit_async()
Kafka的数据积压
前期准备:安装kafka-eagle工具,并搭建环境
数据积压介绍
什么是数据积压?
数据持续的在Kafka集群中积压。也就是Lag的值,一直在增大没有减小。正常情况下,lag的值是来回波动的。
通过命令的方式查看数据积压
- 1- 查看Kafka集群有哪些消费组
./kafka-consumer-groups.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --list

- 2- 查看指定消费组数据积压情况
./kafka-consumer-groups.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --describe --group g_2

数据积压问题处理
出现积压的原因:
- 因为数据写入目的容器失败,从而导致消费失败
- 因为网络延迟消息消费失败
- 消费逻辑过于复杂, 导致消费过慢,出现积压问题
解决方案:
- 对于第一种, 我们常规解决方案, 处理目的容器,保证目的容器是一直可用状态
- 对于第二种, 如果之前一直没问题, 只是某一天出现, 可以调整消费的超时时间。并且同时解决网络延迟问题
- 对于第三种, 一般解决方案,调整消费代码, 消费更快即可, 利于消费者的负载均衡策略,提升消费者数量