系列文章目录
第一章 TensorRT优化部署(一)–TensorRT和ONNX基础
第二章 TensorRT优化部署(二)–剖析ONNX架构
第三章 TensorRT优化部署(三)–ONNX注册算子
第四章 TensorRT模型优化部署(四)–Roofline model
第五章 TensorRT模型优化部署(五)–模型优化部署重点注意
第六章 TensorRT模型优化部署(六)–Quantization量化基础(一)
第七章 TensorRT模型优化模型部署(七)–Quantization量化(PTQ and QAT)(二)
文章目录
- 系列文章目录
- 前言
- 一、(PTQ and quantization-analysis)
- 1.1 PTQ 优缺点
- 1.2 量化中的sensitive analysis
- 1.2 Polygraphy
- 1.3 FP16/INT8对计算资源的利用
- 二、Quantization(QAT and kernel-fusion)
- 1.Q/DQ是什么
- 2.量化流程
- 总结
前言
理解PTQ和QAT的区别,以及PTQ的优缺点和layer-wise sensitive analysis
一、(PTQ and quantization-analysis)
根据量化的时机,一般我们会把量化分为
• PTQ(Post-Training Quantization),训练后量化
• QAT(Quantization-Aware Training),训练时量化
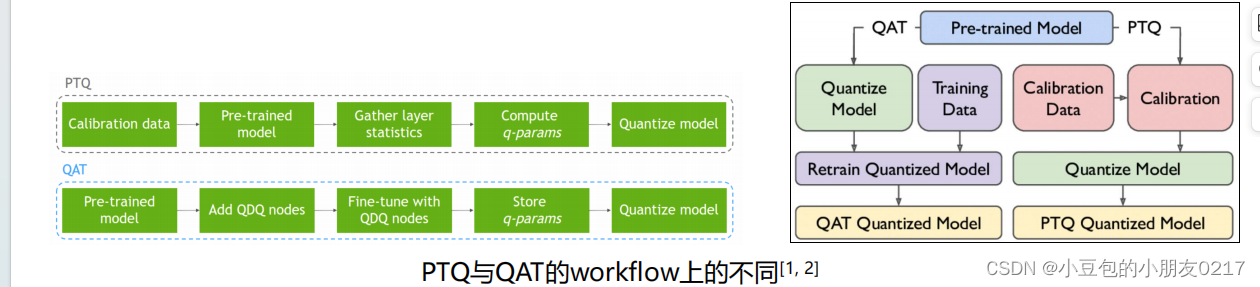
PTQ一般是指对于训练好的模型,通过calibration算法等来获取dynamic range来进行量化。
但量化普遍上会产生精度下降。所以QAT为了弥补精度下降,在学习过程中通过Fine-tuning权
重来适应这种误差,实现精度下降的最小化。所以一般来讲,QAT的精度会高于PTQ。但并不
绝对。
1.1 PTQ 优缺点
PTQ(Post-training quantization)也被称作隐式量化(implicit quantization)。我们并不显式的
对算子添加量化节点(Q/DQ),calibration之后TensorRT根据情况进行量化。
优点
• 方便使用,不需要训练。可以在部署设备上直接跑
缺点
- 精度下降
• 量化过程会导致精度下降。但PTQ没有类似于QAT这种fine-tuning的过程。所以权重不会更
新来吸收这种误差。 - 量化不可控
• TensorRT会权衡量化后所产生的新添的计算或者访存, 是否用INT8还是FP16。
• TensorRT中的kernel autotuning会选择核函数来做FP16/INT8的计算。来查看是否在CUDA
core上跑还是在Tensor core上跑
• 有可能FP16是在Tensor core上,但转为INT8之后就在CUDA core上了 - 层融合问题
• 量化后有可能出现之前可以融合的层,不能融合了
• 量化会添加reformatter这种更改tensor的格式的算子,如果本来融合的两个算子间添加了这
个就不能被融合了
• 比如有些算子支持int8,但某些不支持。之前可以融合的,但因为精度不同不能融合了
如果INT8量化后速度反而会比FP16/FP32要慢,我们可以从以上的2和3去分析并排查原因
1.2 量化中的sensitive analysis
从精度分析的角度去弥补PTQ的精度下降,我们可以进行layer-wise的量化分析。这种方法被称
作layer-wise sensitive analysis。每层对模型的重要度比例是不一样的,普遍来讲,模型框架中会有一些层的量化对精度的影响比较大。我们管它们叫做敏感层(sensitive layer)。对于这些敏感层的量化我们需要非常小心。尽量用FP16。敏感层一般靠近模型的输入输出
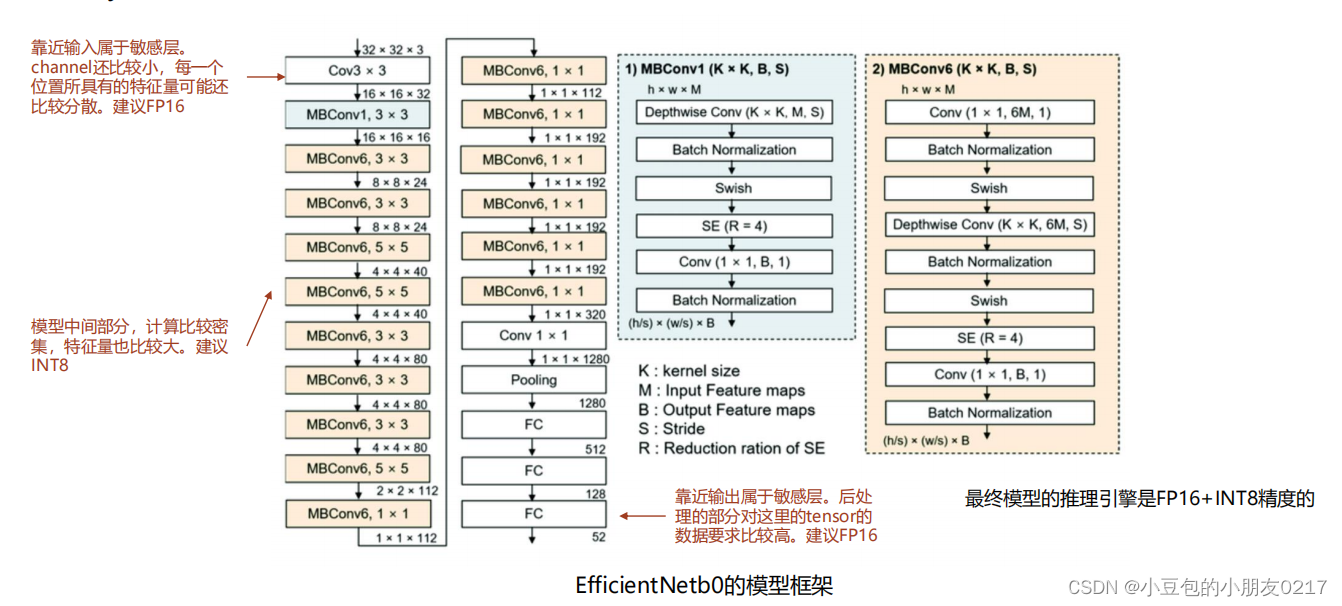
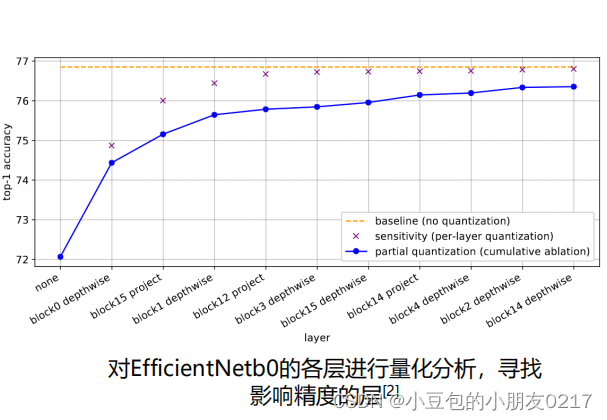
1.2 Polygraphy
Polygraphy 是英伟达推出的一款工具,用于可视化和分析深度学习模型的性能和效果。可以分析并查找模型精度下降并且影响比较大的地方
• onnxruntime与TensorRT engine的layer-wise的精度分析
• 输出每一层layer的权重histogram
• 截取影响整个网络中对精度影响最大的子网,并使用onnx-surgeon单独拿出来

(跑一下Onnx模型再跑一下trt模型,两个模型对比,看激活值差别大概有多大,如果有一个层某个层精度下降比较大就会报错,然后把它取出来。)
具体查看官方文档:https://github.com/NVIDIA/TensorRT/tree/main/tools/Polygraphy#examples
1.3 FP16/INT8对计算资源的利用
在做量化后,我们无法指定将量化后的conv或者gemm放在Tensor core还是在CUDA core上计算。这些是TensorRT在帮我们选择核函数的时候自动完成的。查看是否在用Tensor core可以通过下面三个办法
• 使用dlprof
• 使用nsight system
• 使用trtexec
DLProf
DLProf (Deep learning Profiler)工具可以把模型在GPU上的执行情况以TensorBoard的形式打印出来,分析TensorCore的使用情况。DLProf不支持Jetson系列的Profile。对于Jetson,我们可以使用Nsight system或者trtexec。具体查看官方文档:https://developer.nvidia.com/blog/profiling-and-optimizing-deep-neural-networks-with-dlprof-and-pyprof/
Nsight System/trtexec
如果是利用Nsight system的话,我们可以查看到哪一个kernel的时间占用率最高,之后从kernel的名字取推测这个kernel是否在用Tensor Core。
eg:
• h884 = HMMA = FP16 TensorCore
• i8816 = IMMA = INT8 TensorCore
• hcudnn = FP16 normal CUDA kernel (without TensorCore)
• icudnn = INT8 normal CUDA kernel (without TensorCore)
• scudnn = FP32 normal CUDA kernel (without TensorCore)
HMMA: Half-precision matrix multiply and accumulate
Nsight System/trtexec IMMA: Int-precision matrix multiply and accumulate
二、Quantization(QAT and kernel-fusion)
QAT(Quantization Aware Training)也被称作显式量化。我们明确的在模型中添加Q/DQ节点
(量化/反量化),来控制某一个算子的精度。并且通过fine-tuning来更新模型权重,让权重学习
并适应量化带来的精度误差。QAT的核心就是通过添加fake quantization,也就是Q/DQ节点,来模拟量化过程
1.Q/DQ是什么
Q/DQ node也被称作fake quantization node,是用来模拟fp32->int8的量化的scale和
shift(zero-point),以及int8->fp32的反量化的scale和shift(zero-point)。QAT通过Q和DQ
node里面存储的信息对fp32或者int8进行线性变换。
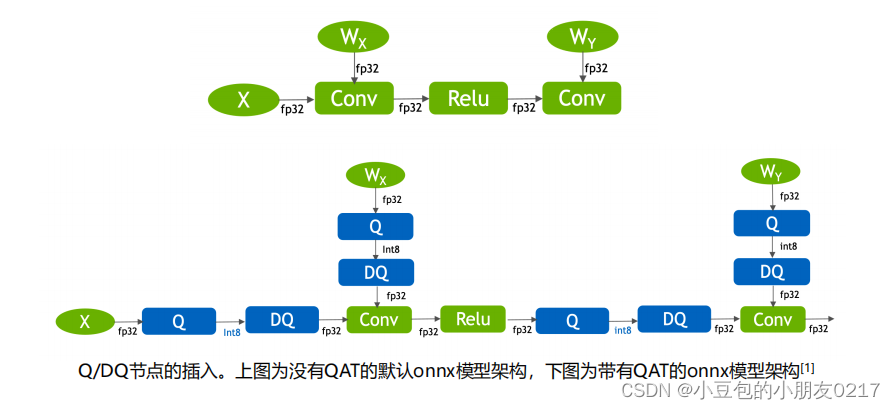
TensorRT对包含Q/DQ节点的onnx模型使用很多图优化,从而提高计算效率。主要分为
• Q/DQ fusion
通过层融合,将Q/DQ中的线性计算与conv或者linear这种线性计算融合在一起,实现int8计算
• Q/DQ Propagation
将Q节点尽量往前挪,将DQ节点尽量往后挪,让网络中int8计算的部分变得更长
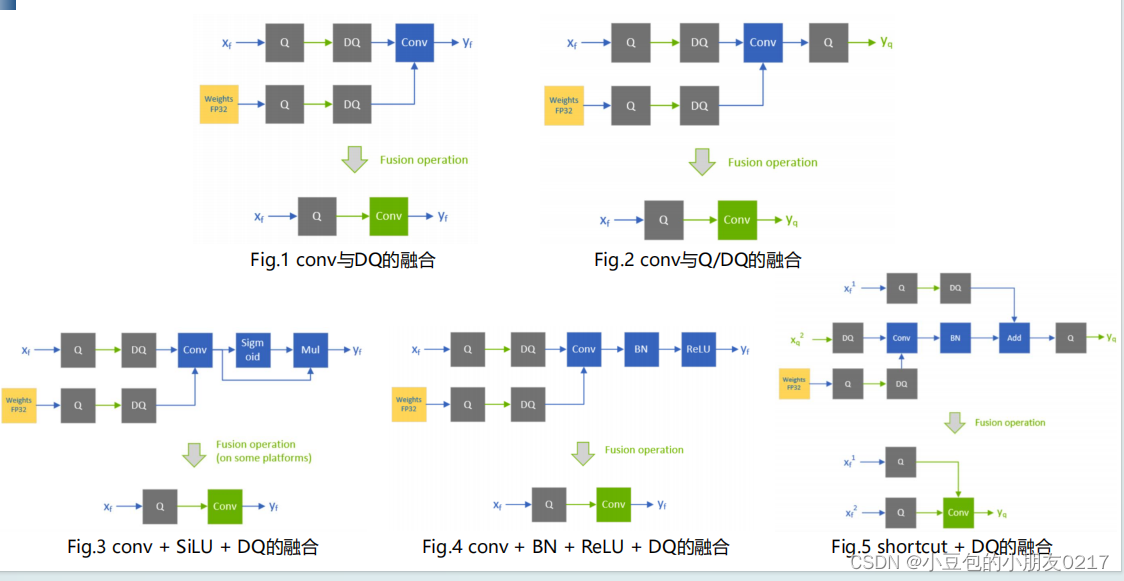

QAT的学习过程
• 主要是训练weight来学习误差
Q/DQ中的scale和zero-point也是可以训练的。通过训练来学习最好的scale来表示dynamic range
• 没有PTQ中那样人为的指定calibration过程
不是因为没有calibration这个过程来做histogram的统计,而是因为QAT会利用fine-tuning的数
据集在训练的过程中同时进行calibration,这个过程是我们看不见的。这就是为什么我们在
pytorch创建QAT模型的时候需要选定calibration algorithm。
pytorch支持对已经训练好的模型自动添加Q/DQ节点。详细可以参考https://github.com/NVIDIA/TensorRT/tree/main/tools/pytorch-quantization
2.量化流程
- 先进行PTQ
从多种calibration策略中选取最佳的算法,查看是否精度满足,如果不行再下一步。 - 进行partial-quantization
通过layer-wise的sensitve analysis分析每一层的精度损失,尝试fp16 + int8的组合;fp16用在敏感层(网络入口和出口),int8用在计算密集处(网络的中间),查看是否精度满足,如果不行再下一步。(注意,这里同时也需要查看计算效率是否得到满足) - 进行QAT来通过学习权重来适应误差
选取PTQ实验中得到的最佳的calibration算法,通过fine-tuning来训练权重(大概是原本训练的10%个epoch),查看是否精度满足,如果不行查看模型设计是否有问题。(注意,这里同时也需要查看层融合是否被适用,以及Tensor core是否被用)
总结
下节介绍channel-level pruning的算法,以及如何使用L1-Norm来让权重稀疏