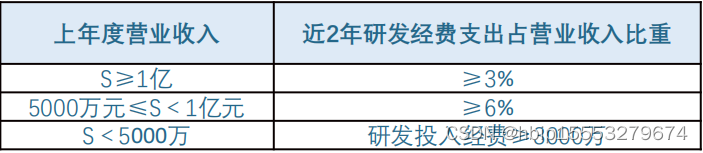
前置内容
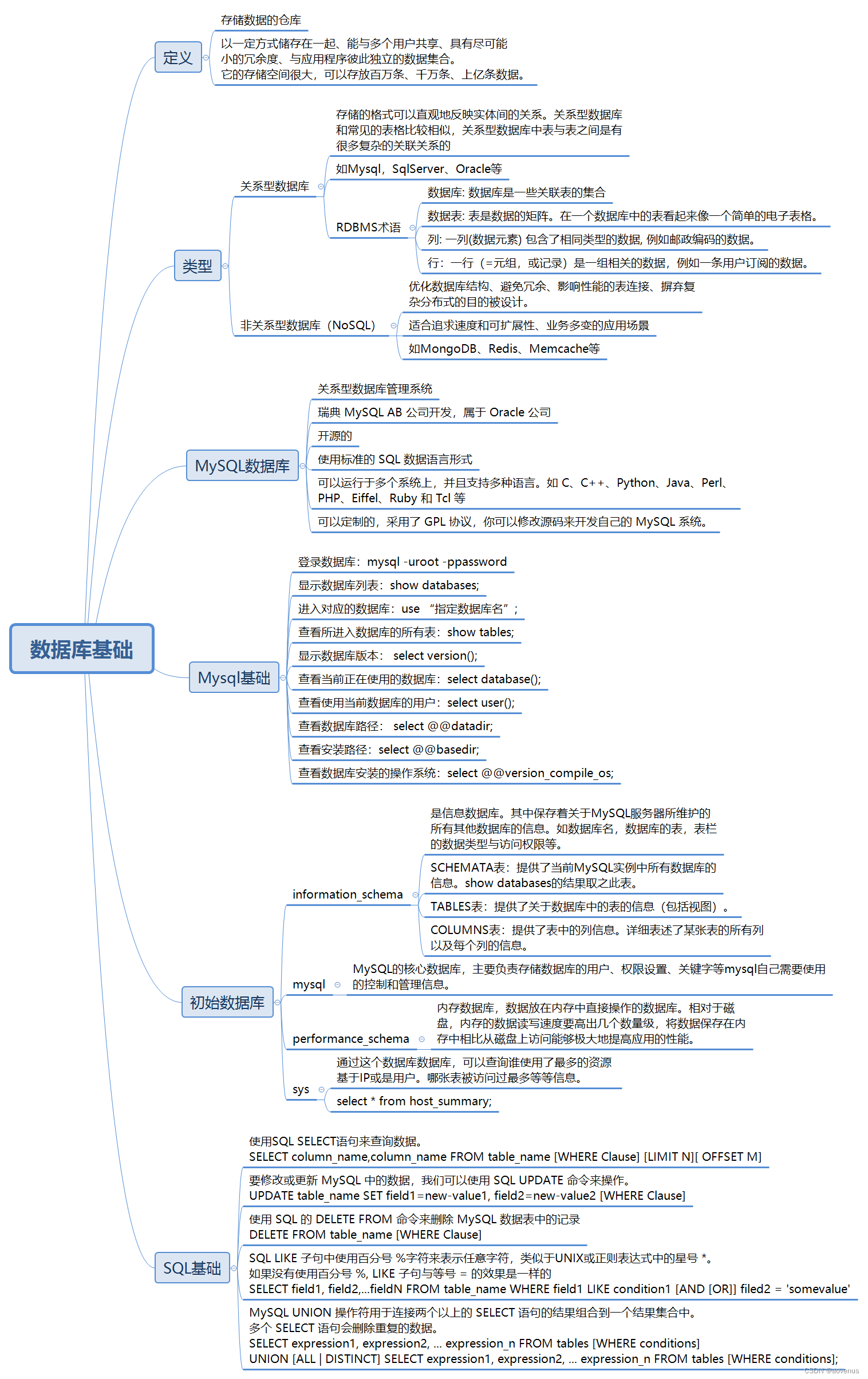
Jensen不等式
高斯混合模型
多元高斯模型
拉格朗日乘子法
主要内容

EM算法(Expectation-Maximization),期望-最大化。 用于保证收敛到MLE(最大似然估计)。主要用于求解包含隐变量的混合模型,主要思想是把一个难于处理的似然函数最大化问题用一个易于最大化的序列取代,而其极限是原始问题的解。
高斯混合模型
高斯混合模型 (GMM) 是一种机器学习算法。它们用于根据概率分布将数据分类为不同的类别。
高斯混合模型 (GMM) 是一个概率概念,用于对真实世界的数据集进行建模。GMM是高斯分布的泛化,可用于表示可聚类为多个高斯分布的任何数据集。
GMM 有许多应用,例如密度估计、聚类和图像分割。对于密度估计,GMM 可用于估计一组数据点的概率密度函数。对于聚类,GMM 可用于将来自相同高斯分布的数据点组合在一起。对于图像分割,GMM 可用于将图像划分为不同的区域。
高斯混合模型可用于各种用例,包括识别客户群、检测欺诈活动和聚类图像。在这些示例中的每一个中,高斯混合模型都能够识别数据中可能不会立即明显的聚类。因此,高斯混合模型是一种强大的数据分析工具,应该考虑用于任何聚类任务。
GMM API
# 高斯混合的变分贝叶斯估计。
mixture.BayesianGaussianMixture(*[, ...]) Variational Bayesian estimation of a Gaussian mixture.
mixture.GaussianMixture([n_components, ...]) Gaussian Mixture.
详解
class sklearn.mixture.BayesianGaussianMixture(*, n_components=1, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weight_concentration_prior_type='dirichlet_process', weight_concentration_prior=None, mean_precision_prior=None, mean_prior=None, degrees_of_freedom_prior=None, covariance_prior=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)
class sklearn.mixture.GaussianMixture(n_components=1, *, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)[source]
参数:
- n_components:int, default=1
混合物组分的数量。 - covariance_type:{‘full’, ‘tied’, ‘diag’, ‘spherical’}, default=’full’
描述要使用的协方差参数类型的字符串。必须是以下之一:
“full”:每个组件都有自己的通用协方差矩阵。
“tied”:所有组件共享相同的通用协方差矩阵。
“diag”:每个组件都有自己的对角协方差矩阵。
“spherical”:每个分量都有自己的单一方差。 - tol:float, default=1e-3
收敛阈值。当下限平均增益低于此阈值时,EM迭代将停止。 - reg_covar:float, default=1e-6
非负正则化添加到协方差的对角线上。允许确保协方差矩阵均为正。 - max_iter:int, default=100
要执行的EM迭代次数。 - n_init:int, default=1
要执行的初始化次数。保持最佳结果。
init_params:{‘kmeans’,‘k-means++’,‘random_from_data’},default =‘kmeans’
用于初始化权重、平均值和精度的方法。字符串必须是以下之一:
“kmean”:使用kmean初始化职责。
“k-means++”:使用k-means+方法进行初始化。
“随机”:职责随机初始化。
“random_from_data”:初始均值是随机选择的数据点。 - weights_init:array-like of shape (n_components, ), default=None
用户提供了初始权重。如果为None,则使用init_params方法初始化权重。 - means_init:array-like of shape (n_components, n_features), default=None
用户提供的初始方法,如果为None,则使用init_params方法初始化方法。 - precisions_init:array-like, default=None
用户提供了初始精度(协方差矩阵的倒数)。如果为None,则使用“init_params”方法初始化精度。形状取决于“协变类型”:
(n_components,) if ‘spherical’,
(n_features, n_features) if ‘tied’,
(n_components, n_features) if ‘diag’,
(n_components, n_features, n_features) if ‘full’ - random_state:int, RandomState instance or None, default=None
控制为所选方法提供的随机种子,以初始化参数(请参见init_params)。此外,它还控制从拟合分布生成随机样本(见方法样本)。在多个函数调用之间传递一个int以获得可复制的输出。请参阅词汇表。 - warm_start:bool, default=False
如果“warm_start”为True,则最后一次拟合的解决方案将用作下次调用fit()的初始化。当在类似问题上多次调用fit时,这可以加快收敛速度。在这种情况下,将忽略“n_init”,并且在第一次调用时只进行一次初始化。请参阅术语表。 - verbose:int, default=0
启用详细输出。如果为1,则打印当前初始化和每个迭代步骤。如果大于1,则还会打印日志概率和每个步骤所需的时间。 - verbose_interval:int, default=10
下一次打印前完成的迭代次数。
参考
1.EM算法视频:https://www.bilibili.com/video/BV1Ca411M7KA/?p=10&spm_id_from=333.880.my_history.page.click&vd_source=c35b16b24807a6dbe33f5473659062ac
2.机器学习笔记 - 什么是高斯混合模型(GMM)?:https://blog.csdn.net/bashendixie5/article/details/124891359