redis的数据类型有哪些
string,list,set,sorted_set,hash
操作
sting:
set name maliao
get name
exists name
expire name 5
ttl name
del name
setex name 10 maliao 设置key和过期时间
setnx name maliao 当key不存在时才添加
list:
lpush letter a
lpush letter b
lrange letter 0 -1:0表示从第0个元素开始获取,-1 表示获取到最后一个元素
rpush letter c
rpush letter d
rpush letter e f
lpop letter
rpop letter
lpop letter 2
llen letter
区间操作:
lpush score 100,99,60,50
ltrim score 1,3:修建,只保留[1:3]的元素
set:
sadd hero luna
sadd hero pa sa
sismember hero luna
srem hero luna
sorted_set:
由name -score 组成
zadd result 669 sjtu 680 pku 650 zju
zrange result 0 -1
zrange result 0 -1 withscores:输出name和分数
zrank result zju:得到从小到大zju的排名
zrevrank result zju:得到从大到小zju的排名
zrank result
zrevrank result
hash:
hset person name laoyang
hset person age 50
hget person name
hgetall person
hdel person age
hexists person name
hkeys person
hlen person
flushall:慎用!删除redis所有key
几个数据结构的特点
string
- string是动态字符串,可修改,最大长度为512M。
- 通常采用加倍扩容预分配原则,减少内存的频繁分配:<1MB时每次扩容1MB,>1MB时翻倍扩容
- string设置了过期时间后调用set修改,过期时间会失效。
list
- list是连续的内存存储+双向链表,链表不是数组,增删的时间复杂度为O(1),索引定位时间复杂度为O(n)
- 这样的结构满足快速增删,减少空间冗余。
- list 常用来用作异步队列,实现队列、栈等结构。
hash
- hash是无需字典,底层结构为
数组+链表 - hash字典的值只能是字符串
- has字典采用渐进式rehash保证高性能,创建新表进行rehash,此时旧表可读,rehash完成后删除旧表。
- hash字典可对用户结构中的每个字段单独存储,方便部分读取,避免全量获取造成的资源浪费。
- 存储消耗hash>string,使用时要考虑成本
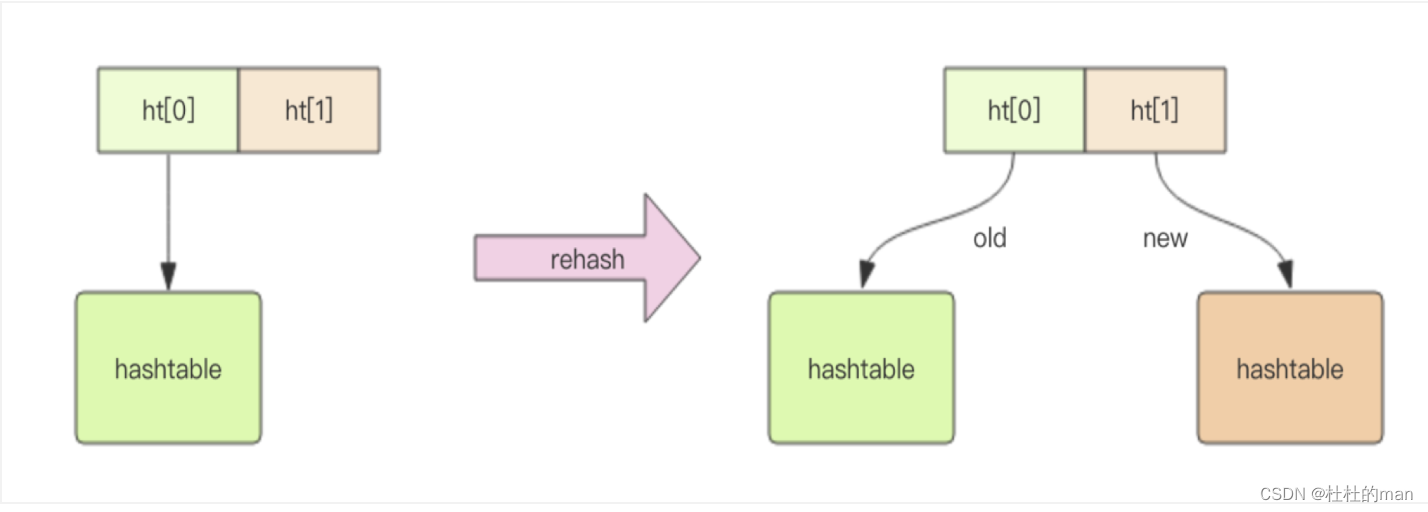
zset 有序集合
- zset为有序列表,可对value指定权重值score后进行排序
- zset内部的结构为
跳跃列表,为支持随机的增删,使用类似金字塔结构:底层元素串联,抽取代表值使用一级指针串联,抽取代表值使用二级指针串联······以此类推,最多32层。单个节点可能身兼多级职能。 - 跳跃列表采取随机策略决定新元素的层级位置,层级概率主机减半:L0 100%,L1层50%,L2层25%······

容器型数据结构的通用规则
- list、set、hash、zset是容器型数据结构
- 自动创建规则:如果容器不存在,redis会自动创建容器,再rpush进去新元素。
- 自动释放规则: 如果容器内无元素,则立即删除容器,释放内存。
- 过期策略:redis的过期时间是以对象为单位的,不是元素或属性,hash结构过期是整个hash对象过期,并非子key过期。








![给定n个字符串s[1...n], 求有多少个数对(i, j), 满足i < j 且 s[i] + s[j] == s[j] + s[i]?](https://img-blog.csdnimg.cn/direct/85d295adffbd4ef8897e17df713e7440.jpeg)