MySQL主从复制
一、主从复制概念
主从复制是指将主数据库的DDL和DML操作通过二进制日志传到从服务器中,然后在从服务器上对这些日志重新执行也叫重做,从而使得从数据库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行赋值,从库同时也可以作为其他从服务器的主库,实现链式复制。
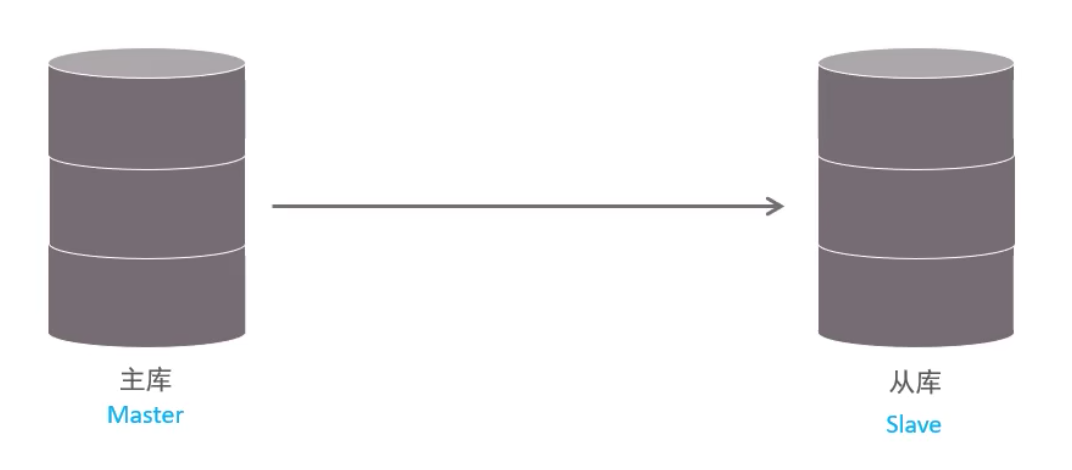
一般主服务器我们叫Master, 从服务器叫Slave
二、主从复制优点
- 主库出现问题,可以快速切换到从库提供服务。
- 实现读写分离,降低主库的访问压力。
- 可以在从库备份,以避免备份期间影响主库服务。
三、主从复制原理
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件binlog中。
- 从库读取主库的二进制文件binlog,写入到从库的中继日志relay.log
- slave重做中继日志中的事件,将改变从库自己的数据

四、主从复制搭建
4.1 MySQL服务器准备
首先准备两台已经安装了MySQL的主机,这里我分为准备了两台10.0.3.93(Master) 和 10.0.3.94(Slave)
4.2 主服务器配置
1、在MySQL的配置文件中,增加如下两行的配置,第三和第四的配置,可以根据需要配置
#MySQL服务ID,保证整个集群中唯一,默认是1
server-id=1
#是否只读,1代表只读,0代表读写
read-only=0
#忽略的数据,指不需要同步的数据库,和下面的一条配置默认如果不配置的话,即复制所有数据库
#binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db012、配置好了之后,要重启MySQL服务。
3、登录mysql,创建远程连接的账号,并授予主从复制权限,这个账号是用来在从服务器上登录主服务用的。
# 创建一个mysql用户为houlei,并设置密码为:Se7eN521,该用户可以在任意主机连接该MySQL服务
mysql> create user 'houlei'@'%' identified with mysql_native_password by 'Se7eN521';
Query OK, 0 rows affected (0.03 sec)
# 为'houlei'@'%' 用户分配主从复制权限
mysql> grant replication slave on *.* to 'houlei'@'%';
Query OK, 0 rows affected (0.01 sec)4、通过指令,查看二进制日志坐标,这里的数据也是需要在从服务上配置需要的
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000005 | 156 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)4.3 从服务器配置
1、从服务器上在MySQL的配置文件中增加下面的配置
#MySQL服务ID,保证整个集群中唯一
server-id=2
#是否只读 1代表只读 0代表读写
read-only=12、配置好了之后,要重启MySQL服务。
3、登录mysql,设置主库配置
mysql-8.0.23以后的版本,执行以下SQL
change replication source to host='xxx.xxx.xxx.xxx', source_user='xxx',soucre_password='xxx',source_log_file='xxx',source_log_pos=xxx;mysql-8.0.23以前的版本,执行以下SQL,但是mysql-8.0.23以后的版本也是兼容mysql-8.0.23以前的这个SQL的,所以怕麻烦去查版本的,可以直接使用这个mysql-8.0.23以前的
change master to master_host='xxx.xxx.xxx.xxx',master_user='xxx',master_password='xxx',master_log_file='xxx',master_log_pos='xxx'参数解释
- source_host/master_host: 主库IP地址。
- source_user/master_user:连接主库的用户名。
- source_password/master_password:连接主库的密码。
- source_log_file/master_log_file:binlog日志文件名。
- source_log_pos/master_log_pos:binlog日志文件位置,这个参数是不用加引号或单引号的。
示例:注意该语句一定要在从库上执行
change master to master_host='10.0.3.93',master_user='houlei',master_password='Se7eN521',master_log_file='binlog.000005',master_log_pos=1564、启动主从复制
mysql-8.0.23之后:start replica;
mysql-8.0.23之前:start slave;
5、查看主从同步状态
mysql-8.0.23之后:show replica status\G;
mysql-8.0.23之前:show slave status\G;

说明1:这里主要看Slave_IO_Running和Slave_SQL_Running这两个是否为YES,全部为YES说明配置成功
五、主从复制测试

说明1:主从原始的都是只有四张系统表

说明2:主服务器上创建了一个数据库db01,在从服务器上查询,就马上显示了刚创建的db01

说明3:在主服务器上创建了一张表,马上就主从复制到了从服务器上

说明4:主表中插入数据,也会马上复制到从表中,同样的修改和删除数据也会同步复制过去。
MySQL Mycat配置
一、schema.xml
1.1 简介
schema.xml作为Mycat中最重要的配置文件之一,涵盖了Mycat的逻辑库、逻辑表、分片规则、分片节点即数据源的配置。主要包括一下三组标签
- schema标签
- datanode标签
- datahost标签
1.2 schema标签
用于定于Mycat实例中的逻辑库,一个Mycat实例中,可以有多个数据库,可以通过schema标签来划分不同的逻辑库。Mycat中的逻辑库的概念,等同于MySQL中的database概念没需要操作某个逻辑库下的表时,就需要切换逻辑库,同MySQL一样,使用use xxxx语句。

核心属性:
name: 自定自定义的逻辑库苦命
checkSQLschema: 在SQL语句操作时指定了数据库名称,执行时是否自动去除,true:自动去除,false不自动去除,即如果有true时,我们可以不进入数据库查询.
sqlMaxLimit: 如果未指定limit进行查询,列表查询模式默认查询的条数。checkSQLschema参数演示:

说明1:当checkSQLschema为true时,我们可以不进入数据库查询,即使用DB01.TB_ORDER的方式,但是如果checkSQLschema为false的时候,就不能这样写了,就必须要要先usr DB01;今日数据库里面在查找,所以这里大家就直接给true就行了。
1.3 schema标签中的table标签
table标签定义Mycat中逻辑库schema下的逻辑表,所有需要查分的表都需要在table标签中定义。
核心属性:
name:定义逻辑表表名,在该逻辑库下唯一
DataNode:定义逻辑表所属的dataNode,该属性需要与dataNode标签中的name对应,多个dataNode用逗号隔开
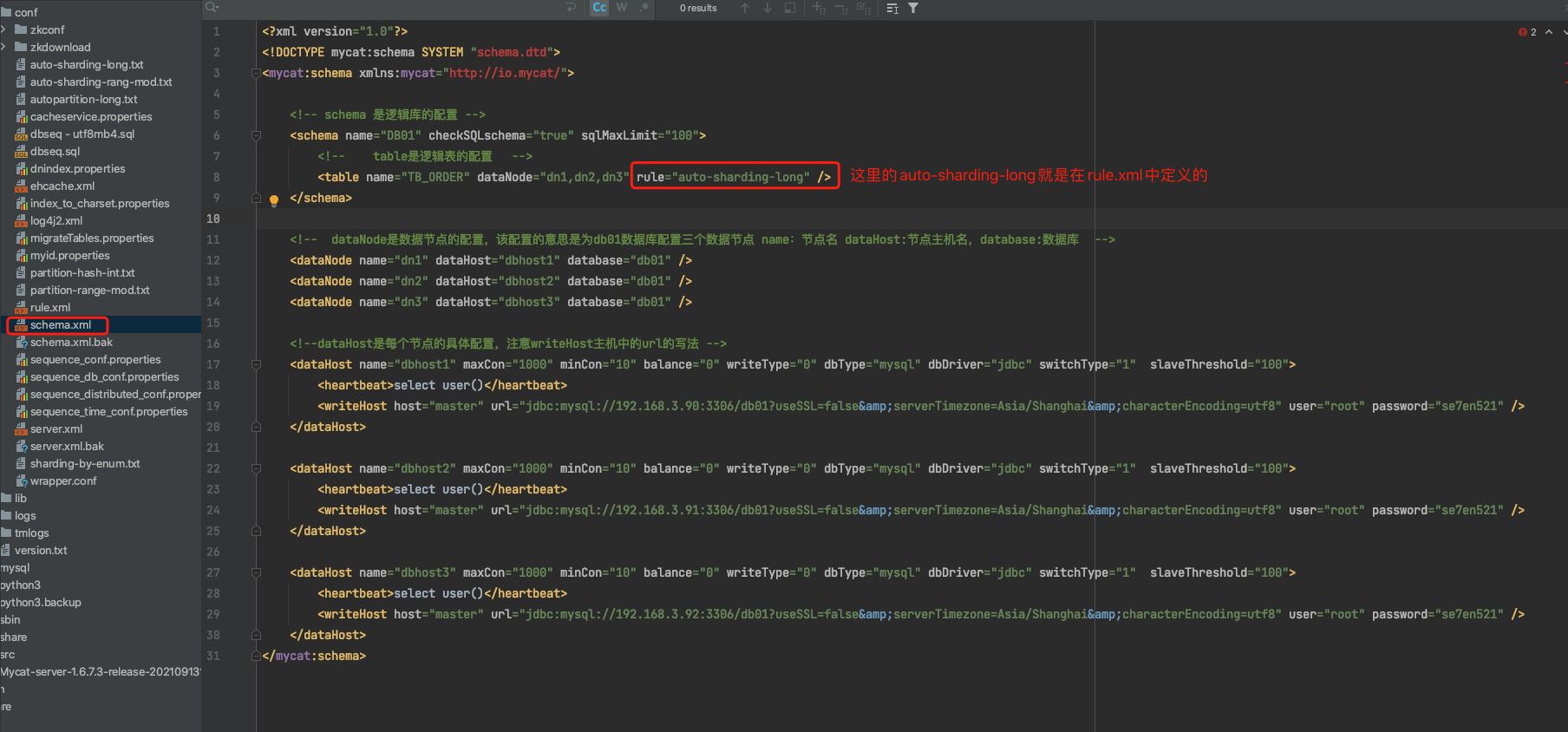
rule: 分片规则的名称,分片规则名字是在rule.xml中定义的
primaryKey: 逻辑表对应的真是表的主键
type: 逻辑表的类型,目前逻辑表只有全局表和普通表,如果未配置,默认是普通表,全局表配置为global1.4 dataNode标签

dataNode标签中定义了Mycat中的数据节点,也就是我们通常说的数据分片,一个dataNode标签就是一个独立的数据分片
核心属性:
name:定义了数据节点名称
dataHost:数据库实例主机名称,引用自dataHost标签中name属性
database:定义分片所属数据库1.5 dataHost标签
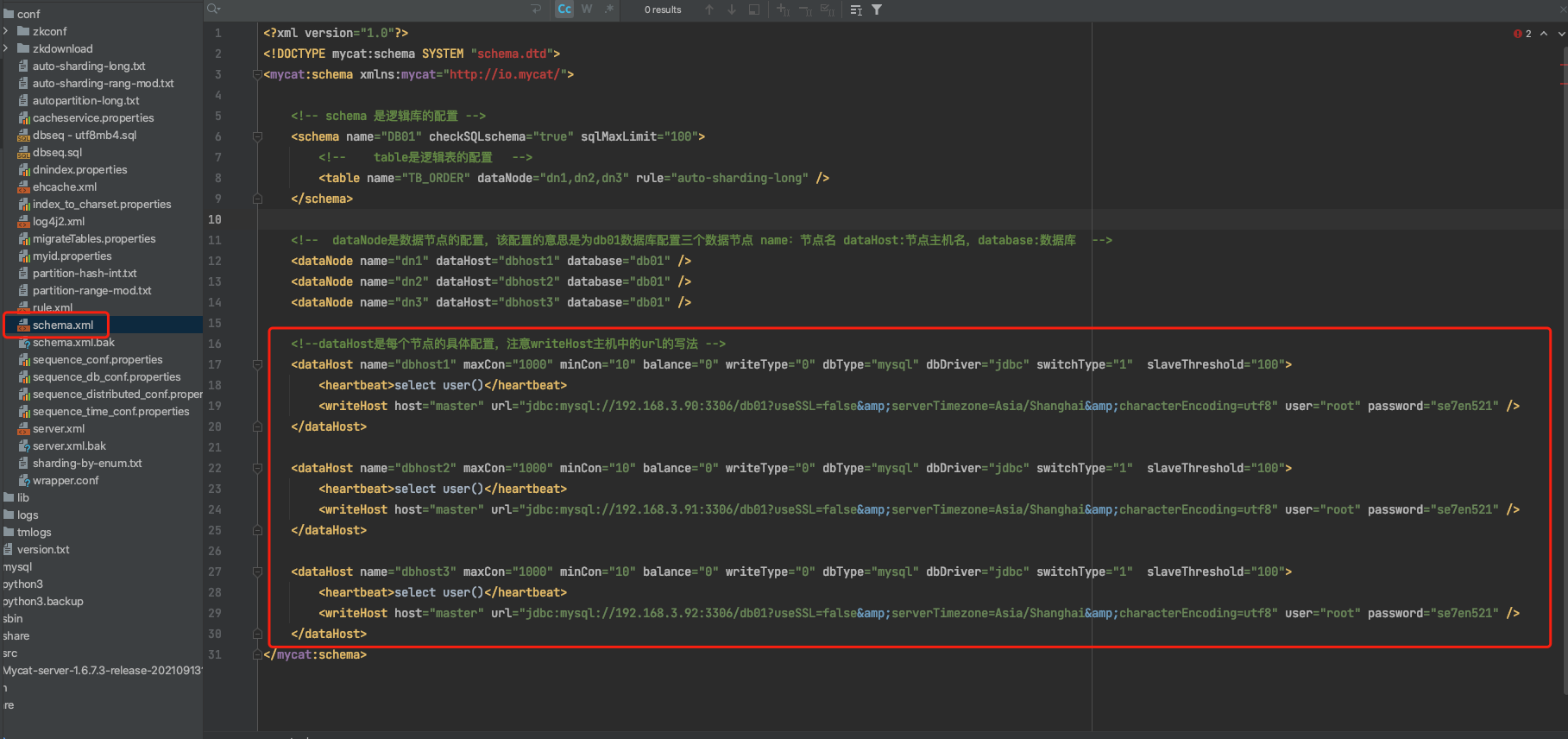
该标签在Mycat逻辑库中作为底层标签,直接定义了具体的数据库实例、读写分离,心跳语句。
核心属性:
name:唯一标识符,供上层标签使用
maxCon/minCon:最大连接数/最小连接数
balance:负载均衡策略,取值0,1,2,3 ,读写分离的时候,在详细说明这四个取值的意义。
writeType:写操作分发方式(0:写操作转发到第一个writeHost,第一个挂了,切换到第二个;1:写操作随机发配到配置的writeHost)
dbDriver:数据库驱动,支持native和jdbc,native主要支持MySQL5+,jdbc主要支持MySQL8+1.6 schema.xml逻辑库映射
逻辑库的名字和mysql数据库中的名字可以不一致的,例如我们这里配置的逻辑库的名字是大写的DB01,而MySQL中的数据库名则是小写的db01,这取决于逻辑库和MySQL真实数据库的映射关系。
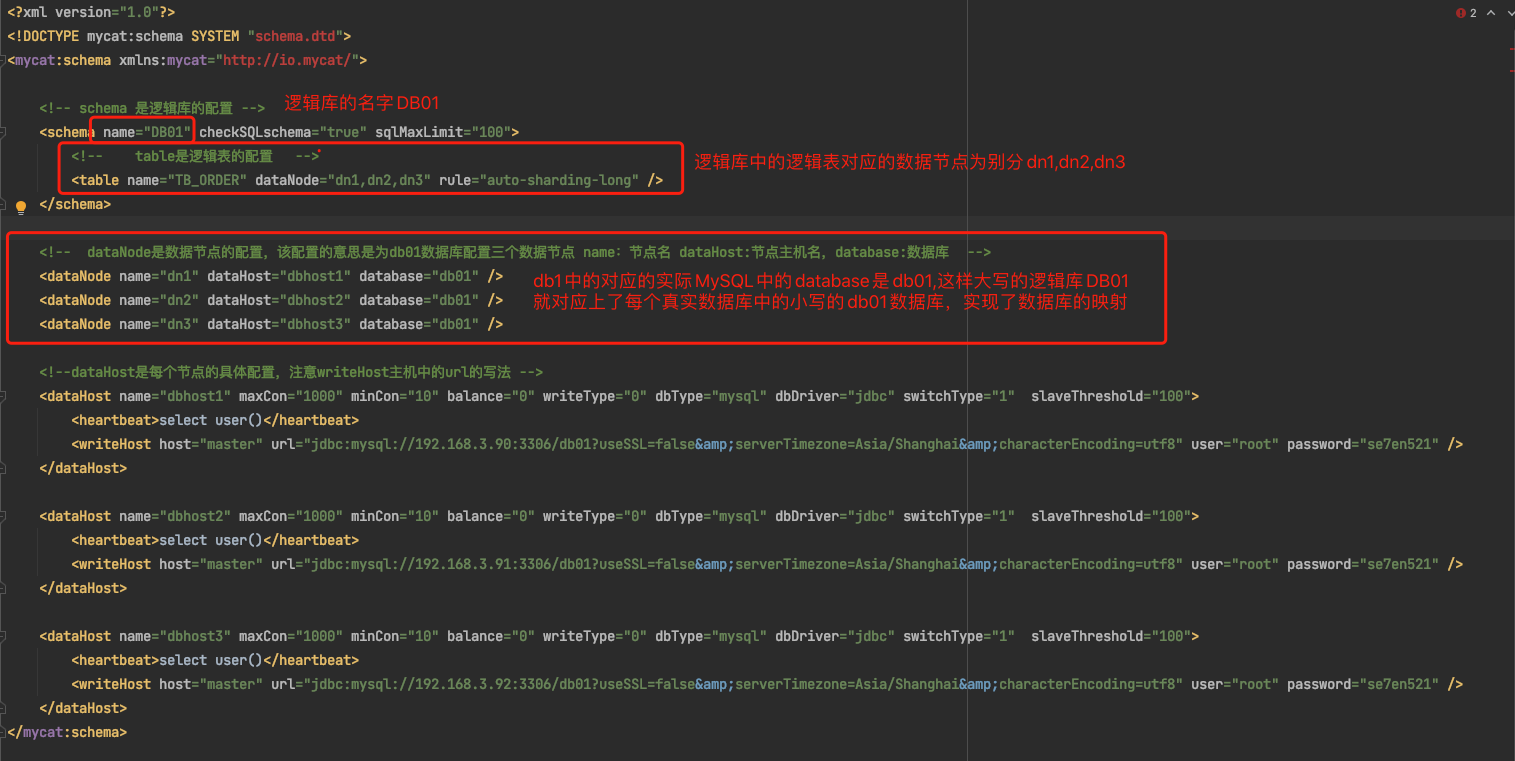
schema.xml整体配置流程即关系隐射示意

二、rule.xml
rule.xml中定义了所有拆分表的规则,在使用过程中可以灵活的使用分片算法,或者对同一个分片算法使用不同的参数,它让分片过程可配置化,主要包含两类标签:tableRule,Function
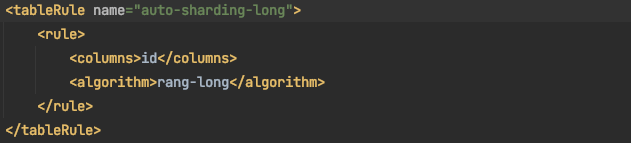

而在schema.xml中配置的分片规则就是在这里定义的
说明1:在tableRule标签里面主要有columns和algorithm两个标签。
说明2:columns标签主要是分表的依据
说明3:algorithm标签主要是,分库分表的算法引用,这里algorithm里面的值就是Function标签的实现。

例如:auto-sharding-long 分表规则的,依据是rang-long这个算法。

而 rang-long这个算法就在function标签中有定义,而function标签中的class就是对应这个算法的实现类。
说明4:至于这里面的分库分表的规则具体的使用,我们会在后面分库分表实战章节,用到的时候在详细说。
三、server.xml
server.xml配置文件包含了Mycat的系统配置,主要有两个重要的标签:system, user.
3.1 system标签

重要属性说明:
charset: 取值utf8: 设置Mycat的字符集,字符集需要与MySQL的字符集保持一致
nonePasswordLogin: 取值 [0, 1], 0:需要登录密码登录,1:不需要登录密码登录,默认为0,设置为1,则需要指定默认账户
useHandshakeV10: 取值 [0,1],使用该选项主要是为了能够兼容高低版本的jdbc驱动,是否采用handshakeV10来与client进行通讯,1:是,0:否
useSqlStat: 取值[0,1],开启SQL实时统计 1:开启,0:关闭,开启之后Mycat会自动统计SQL语句的执行情况:mysql -h xxx.xxx.xxx.xxx -P 9066 -u root -p之后就可以查看,使用show @@sql; show @@sql.low; show @@sql.sum等,分别是查看Myact执行的sql, 执行效率比较低的SQL,SQL的整体执行情况,读写比例等等。
useGlobelTableCheak: 取值[0,1],是否开启全局表一致性检查,1:开启,0关闭
sqlExecuteTimeout: 取值1000等整数:SQL执行的超时时间单位为秒
sequnceHandleType:取值[0,1,2],用来指定Mycat全局序列类型,0:本地文件,1:数据库方式,2:为时间戳方式,默认使用本地文件方式,文件方式主要用于测试
sequnceHandlePattern: 正则表达式:必须带有MYCATSEQ或者mycatseq进入序列匹配流程
subqueryRelationshipCheck: 取值[true,false],子查询存在关联查询的情况下,检查关联字段中是否有分片字段,默认false
useCompression: 取值[0,1],开启mysql压缩协议,0:关闭,1:开始
fakeMySQLVersion: 5.5,5.6,8.0.27等,设置模拟MySQL版本号
defaultSqlParser: 由于Mycat的最初版本使用了FoundationDB的SQL解析器,在Mycat1.3后增加了Druid解析器,所以要设置defaultSqlParser属性来指定默认的解析器,解析器有两个:druidparser和fdbparser,在Mycat1.4之后默认是fruidparser,fdbparser已经废弃
processors: 取值[1,2....] 指定系统可用的线程数量,默认值为CPU核心 乘以 每个核心运行的线程数,processors会影响processorBufferPool,processorBufferLocalPercent,processorExecutor属性,所以在性能调优时可以适当的修改processors的值
processorBufferChunk: 指定每次分配Socker Direct Buffer默认值为4096字节,也会影响BufferPool长度,如果一次性获取字节过多而导致buffer不都用,则会出现警告,可以调大该值
processorExecutor: 指定NIOProcessor上共享businessExecutor固定线程池的大小,Mycat把异步任务交给businessExecutor线程池,在新版本的Mycat中这个连接池使用频率不高,可以适当的把该值调小
packetHeaderSize: 指定MySQL协议中的报文头长度,默认4个字节。
maxPacketSize: 指定MySQL协议可以携带的数据最大大小,默认值为16M
idleTimeout: 取值30等,指定连接的空闲时间的超时长度,如果超时将关闭资源并回收,默认30分钟
txlsolation:取值[1,2,3,4], 初始化前端连接的事务隔离级别,默认为REPEATED_READ,对应数字3,READ_UNCOMMITED=1, READ_COMMITED=2,REPEATED_READ=3,SERIALIZABLE=4
sqlExecuteTimeout: 取值 300 等, 执行SQL的超时时间,如果SQL语句执行超时,将关闭连接,默认300秒
serverPort: 8066 ,定义Mycat的使用端口,默认8066
managerPort: 9066, 定义Mycat的管理端口,默认90663.2 user标签
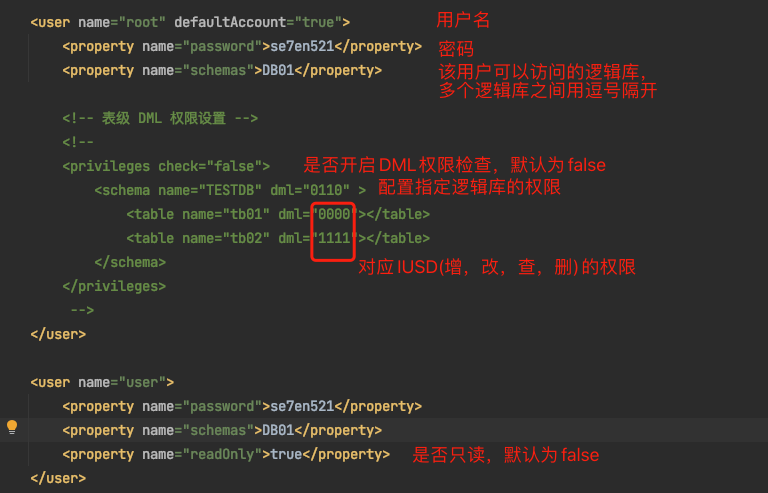
说明1:server.xml中允许有多个user,即同时配置多个用户的权限
说明2:如果一个账户可以访问多个逻辑库,多个逻辑库之间用逗号隔开
说明3:dml中的四个二进制数分别代表增,改,查,删的权限
说明4:如果逻辑表和逻辑库的权限冲突,则就近原则,即优先使用逻辑表的权限
MySQL一主一从读写分离
一、读写分离介绍
读写分离,是把数据库的读和写分开操作,以应对不同的数据库服务器。主数据库提供写操作,从数据库提供读操作,这样能有效的减轻单台数据库的压力。

二、一主一从原理
MySQL的主从复制是基于二进制(binlog)实现的

说明1:当主服务器的MySQL执行了DML,DDL语句之后,会将数据的变更写入到binlog日志中
说明2:在从服务器上有一个IOThread线程会读取主服务器上的binlog日志,然后写入到自己的中继日志(relay log)中
说明3:在从服务器上还有一个SQLThread线程会从自己的中继日志(relaylog)中读取数据变更,然后反映到自身的数据库上
三、主从复制准备
两台MySQL主机
192.168.3.91:角色master
192.168.3.90:角色slave
具体主从复制的配置如果不会的请参考《MySQL运维2-主从复制》
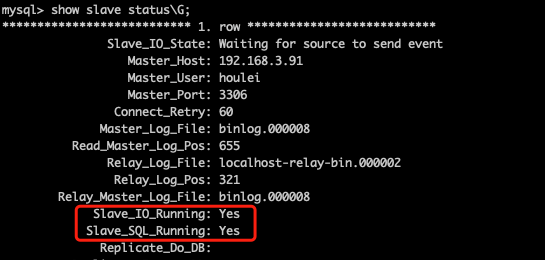
在从服务器上查看主从配置。
然后在主服务器上创建rw数据库,这时在从库上就会自动创建rw数据库
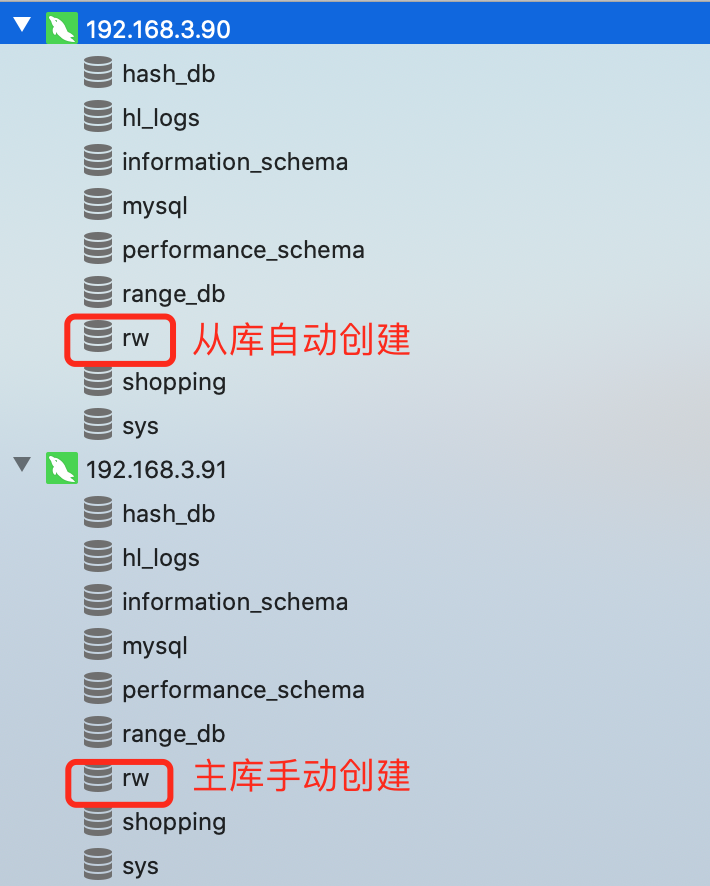
然后再在主服务器上的rw库中创建一个tb_test用于测试的表
create table tb_test(id int auto_increment primary key, name varchar(20)); 
四、配置schema.xml
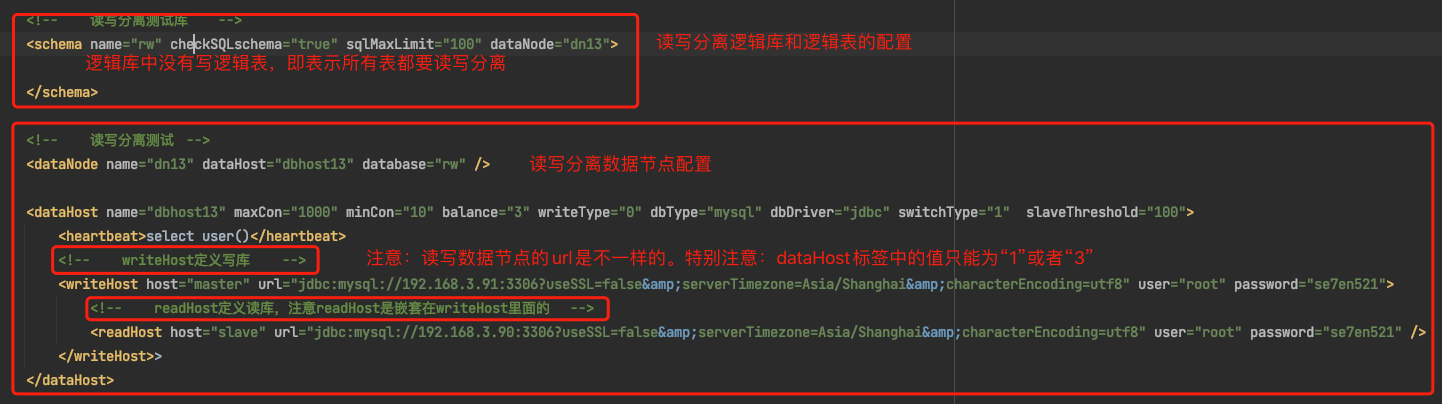
说明1:在业务中如果逻辑库中的所有表都要做读写分离,则可以在schema标签中省略所有的表
说明2:在dataHost数据节点中的配置中注意balance的值只能是“1”或者“3”,balance值的释义
0:不开启读写分离机制,所有读操作都发送当前可用的writeHost上
1:全部的readHost与备用的writeHost都参与select语句的负载均衡(主要针对于双主双从模式)
2:所有的读写操作都随机在writeHost,readHost上分发
3:所有的读请求随机分发到writeHost对应的readHost上执行,writeHost不负担读压力说明3:一组读写分离的库,其中readHost标签是嵌在writeHost标签中的
说明4:因为要读写分离,所以读写节点上的url是不同的
五、配置server.xml
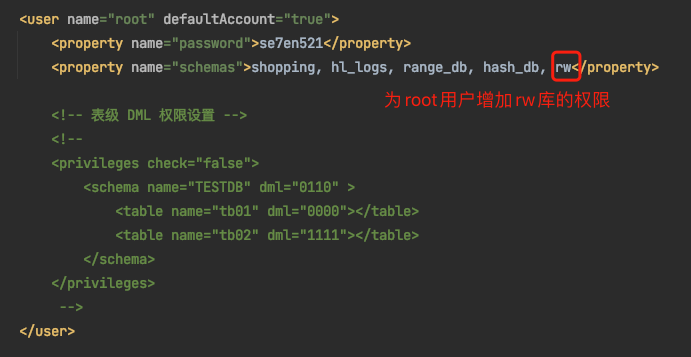
说明1:为root用户增加rw库的权限
六、读写分离测试
首先重启Mycat
登录Mycat
查看逻辑库和逻辑表
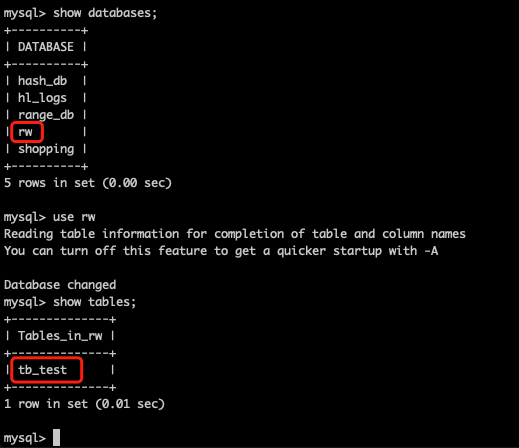
说明1:我们在schema.xml没有配置逻辑表,所以会把rw数据库中的表,全部当做逻辑表,即我们之前创建的tb_test表会查询出来。
插入数据进行测试
insert into tb_test(name) values ("张三");
insert into tb_test(name) values ("李四");
insert into tb_test(name) values ("王五");


这时主库和从库的tb_test表中都有了数据,进行查询测试。
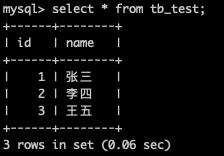
但是这个时候,我们并分不清这个查询出来的数据是主表的还是从表的,这时我们将从表中的“张三”改为“张三1”,因为主从复制,只是单向的从主到从复制,即主表改了,从表会跟着一起改,但是从表改了,主表的数据是不会改的。

再次查询验证
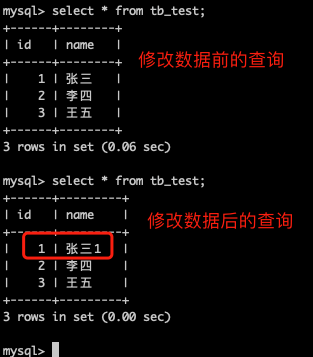
说明1:通过查询的数据得知,我们读取的数据是来自我们配置的从库的数据,即实现了读的数据是从库中的数据。
说明2:因为主从复制是从到主到从单向的复制,所以说明我们写数据一定是写入到主库的,不然从库是不会有数据的。
说明3:所以我们已经实现了简单的数据读写分离。





![[BJDCTF2020]ZJCTF,不过如此](https://img-blog.csdnimg.cn/direct/7eaede2b9a63415a92047e8456963cab.png)