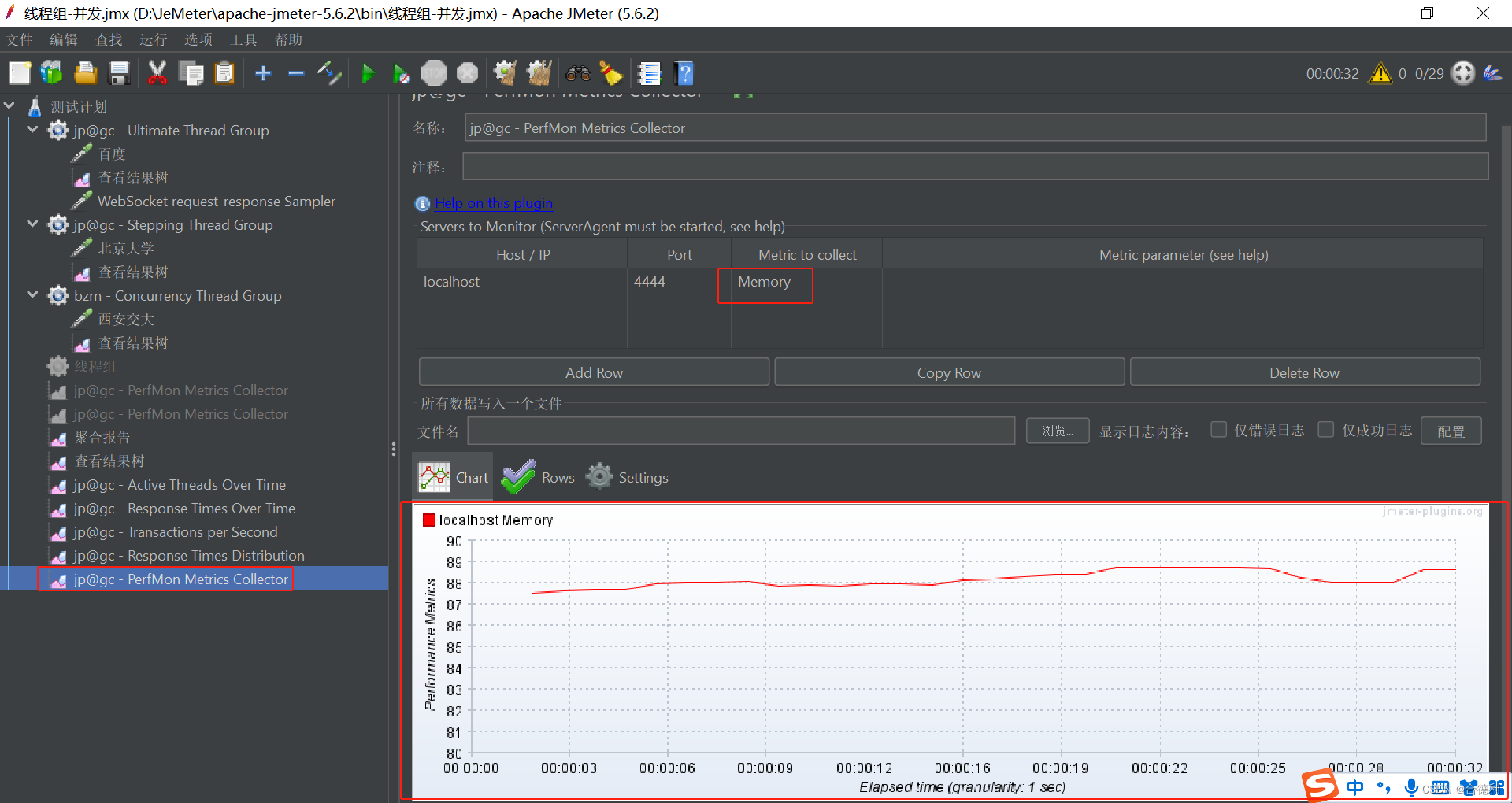
Python办公自动化 – 数据预处理和数据校验
以下是往期的文章目录,需要可以查看哦。
Python办公自动化 – Excel和Word的操作运用
Python办公自动化 – Python发送电子邮件和Outlook的集成
Python办公自动化 – 对PDF文档和PPT文档的处理
Python办公自动化 – 对Excel文档和数据库的操作运用、设置计划任务
Python办公自动化 – 对CSV文件运用和管理文件 / 文件夹
Python办公自动化 – 对数据进行分析和制作图表数据
Python办公自动化 – 对图片处理和文件的加密解密
Python办公自动化 – 语音识别和文本到语音的转换
Python办公自动化 – 日志分析和自动化FTP操作
Python办公自动化 – 进行网络监控和处理压缩文件
Python办公自动化 – 文件的比较合并和操作xml文件
Python办公自动化 – 定时邮件提醒和音视频文件处理
Python办公自动化 – 处理JSOM数据和操作SQL Server数据库
Python办公自动化 – 人脸识别和自动化测试
Python办公自动化 – 操控远程桌面和文件版本控制
Python办公自动化 – 自动化清理数据和自动化系统命令
Python办公自动化 – 对数据进行正则表达式匹配
Python办公自动化 – 操作SQLite数据库和数据迁移
Python办公自动化 – 操作NoSQL数据库和自动化图像识别
文章目录
- Python办公自动化 – 数据预处理和数据校验
- 前言
- 一、使用Python对数据进行预处理
- 1. 导入所需库
- 2. 数据加载
- 3. 数据清洗
- 4. 特征选择
- 5. 数据转换
- 6. 数据分割
- 7. 数据可视化(可选)
- 8. 最终数据集准备
- 二、使用Python进行自动化数据校验
- 1. 导入所需库
- 2. 数据加载
- 3. 数据校验
- 4. 错误处理和日志记录
- 5. 自动化校验脚本
- 6. 定期执行校验
- 总结
前言

Python办公自动化是利用Python编程语⾔来创建脚本和程序,以简化、加速和自动化日常办公任务和工作流程的过程。它基于Python的强大功能和丰富的第三方库,使得能够处理各种办公任务,如⽂档处理、数据分析、电子邮件管理、网络通信等等。
一、使用Python对数据进行预处理
数据预处理是数据分析和机器学习流程中的关键步骤之⼀,它旨在清理、转换和准备原始数据,以便更好地适应分析或机器学习模型。Python提供了多种库和工具来进行数据预处理。
下面是进行数据预处理的⼀般步骤和示例:
1. 导入所需库
⾸先,导入可能需要的数据处理库,例如 pandas 用于数据框操作, numpy 用于数值计算,sklearn 用于机器学习等。
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
2. 数据加载
加载的原始数据,通常可以从⽂件(如CSV、Excel)或数据库中读取。
data = pd.read_csv('data.csv')
3. 数据清洗
数据清洗包括处理缺失值、异常值和重复值等。以下是⼀些示例操作:
• 处理缺失值:
# 删除包含缺失值的⾏
data.dropna(inplace=True)
# 使⽤均值或中位数填充缺失值
data['column_name'].fillna(data['column_name'].mean(), inplace=True)
• 处理异常值:
# 根据阈值或统计信息过滤异常值
lower_threshold = 10.0
upper_threshold = 20.0
data = data[(data['column_name'] >= lower_threshold) & (data['column_name'] <= upper_threshold)]
• 处理重复值:
# 删除重复⾏
data.drop_duplicates(inplace=True)
4. 特征选择
选择最相关的特征来构建模型,以减少维度并提⾼模型性能。
# 选择特定的列作为特征
features = data[['feature1', 'feature2', 'feature3']]
5. 数据转换
对数据进⾏转换,以适应模型或改进性能。⽰例包括标签编码、独热编码、标准化等。
• 标签编码:
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])
• 独热编码:
data = pd.get_dummies(data, columns=['categorical_column'], drop_first=True)
• 数据标准化(可选)
scaler = StandardScaler() # 创建StandardScaler对象
X_train = scaler.fit_transform(X_train) # 对训练集进行标准化处理
X_test = scaler.transform(X_test) # 对测试集进行标准化处理
6. 数据分割
将数据分成训练集、验证集和测试集,以进⾏模型训练和评估。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 将数据分为训练集和测试集
X_val, X_test, y_val, y_test = train_test_split(X_test, y_test, test_size=0.5, random_state=42) # 将测试集进一步分为验证集和测试集
7. 数据可视化(可选)
使⽤数据可视化库(如 matplotlib 或 seaborn )来探索数据分布、关系和趋势,以更好地理解数据。
8. 最终数据集准备
根据的应用场景,将数据整理成最终用于建模或分析的形式。
以上是⼀般的数据预处理步骤,具体的操作和流程可能因数据类型、问题类型和⽬标⽽异。数据预处理是⼀个迭代的过程,通常需要多次试验和调整,以确保数据准备得当,以⽀持后续的分析或建模任务。确保根据实际情况选择适当的数据处理技术和方法。
二、使用Python进行自动化数据校验
自动化数据校验是确保数据的质量、完整性和⼀致性的关键步骤之⼀。Python提供了多种库和工具来进行自动化数据校验。
以下是进行数据校验的⼀般步骤和示例:
1. 导入所需库
⾸先,导入可能需要的数据处理和校验库。
import pandas as pd
import numpy as np
2. 数据加载
加载要校验的原始数据,通常可以从文件(如CSV、Excel)或数据库中读取。
data = pd.read_csv('data.csv')
3. 数据校验
进行数据校验的步骤可能包括:
• 检查缺失值:
# 检查每列是否有缺失值
missing_values = data.isnull().sum()
# 或者检查特定列是否有缺失值
if data['column_name'].isnull().any():
print("列 'column_name' 存在缺失值")
• 检查重复值:
# 检查是否存在重复⾏
if data.duplicated().any():
print("数据中存在重复⾏")
• 数据类型验证:
# 检查列的数据类型
if not data['column_name'].dtype == np.int64:
print("列 'column_name' 的数据类型不正确")
• 数据范围验证:
# 检查列的数值范围
if data['numeric_column'].min() < 0 or data['numeric_column'].max() > 100:
print("列 'numeric_column' 的值超出了允许范围")
• ⾃定义规则验证:
可以编写⾃定义函数来根据的业务规则检查数据。
def custom_data_validation(data):
# ⾃定义规则验证
if data['column1'] > data['column2']:
return False
return True
if not data.apply(custom_data_validation, axis=1).all():
print("数据未通过⾃定义验证规则")
4. 错误处理和日志记录
如果发现任何数据问题,可以编写适当的错误处理代码,例如记录问题或引发异常。
5. 自动化校验脚本
将上述校验步骤组合成一个自动化校验脚本,以便将其应用于多个数据集或定期执行校验。
6. 定期执行校验
使用Python的计划任务工具(如 cron 、 schedule 库等)或其他自动化工具来定期执行数据校验脚本,以确保数据的质量和⼀致性。
自动化数据校验是确保数据质量和可靠性的关键步骤之⼀,特别是在数据驱动的业务环境中。根据的数据和业务需求,可以根据需要添加更多的校验规则和逻辑。确保数据校验脚本能够及时发现数据问题,并采取适当的措施来解决这些问题。
总结
以上就是今天分享的内容,希望对看到的小伙伴有帮助,后续会持续更新完python办公自动化的文章分享,可以持续关注哦。