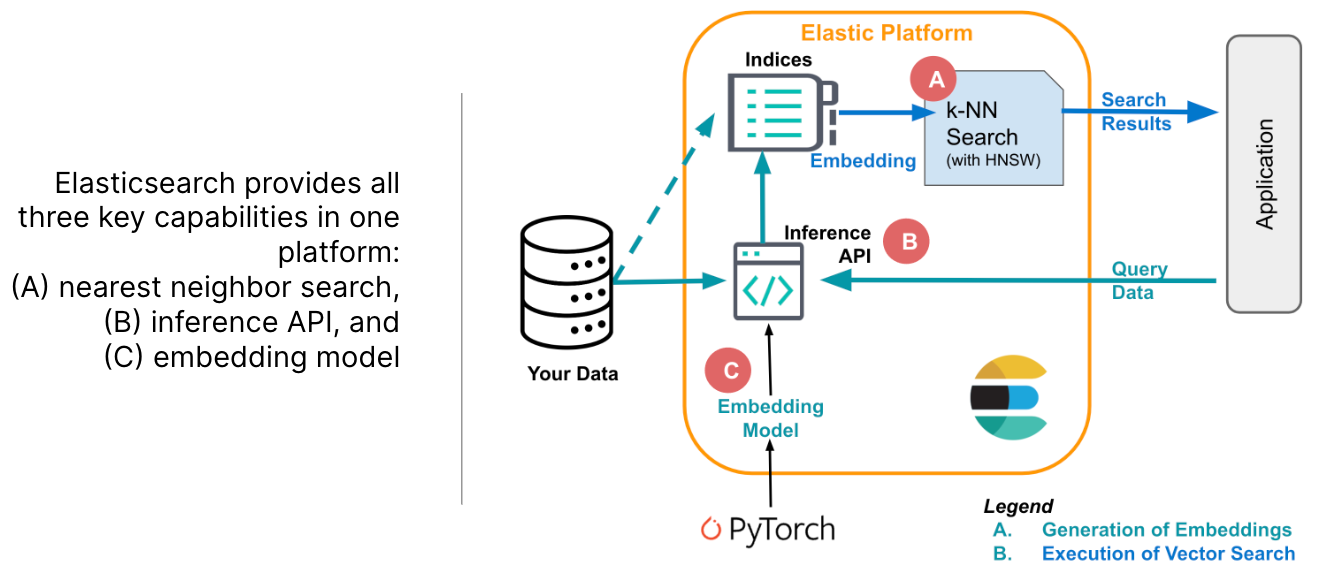
作为 Golang 开发人员,您可能遇到过导入周期。Golang 不允许导入循环。如果 Go 检测到代码中的导入循环,则会抛出编译时错误。在这篇文章中,让我们了解导入周期是如何发生的以及如何处理它们。
导入周期
假设我们有两个包,p1并且p2。当 packagep1依赖于 packagep2且 package 又p2依赖于 packagep1时,就会形成依赖循环。或者它可能比这更复杂,例如。packagep2并不直接依赖于 package p1,而是p2依赖于 package ,而 packagep3又依赖于p1,这又是一个循环。

让我们通过一些示例代码来理解它。
包 p1 :
package p1
import (
"fmt"
"import-cycle-example/p2"
)
type PP1 struct{}
func New() *PP1 {
return &PP1{}
}
func (p *PP1) HelloFromP1() {
fmt.Println("Hello from package p1")
}包p2:
package p2
import (
"fmt"
"import-cycle-example/p1"
)
type PP2 struct{}
func New() *PP2 {
return &PP2{}
}
func (p *PP2) HelloFromP2() {
fmt.Println("Hello from package p2")
}
func (p *PP2) HelloFromP1Side() {
pp1 := p1.New()
pp1.HelloFromP1()
}构建时,编译器返回错误:
imports import-cycle-example/p1
imports import-cycle-example/p2
imports import-cycle-example/p1: import cycle not allowed导入周期是糟糕的设计
Go 高度关注更快的编译时间而不是执行速度(甚至愿意牺牲一些运行时性能来加快构建速度)。Go 编译器不会花费大量时间尝试生成最高效的机器代码,它更关心快速编译大量代码。
允许循环/循环依赖关系将显着增加编译时间,因为每次依赖关系之一发生更改时,整个依赖关系循环都需要重新编译。它还增加了链接时间成本,并使独立测试/重用事物变得困难(单元测试更困难,因为它们不能彼此隔离地进行测试)。循环依赖有时会导致无限递归。
循环依赖还可能导致内存泄漏,因为每个对象都保留另一个对象,它们的引用计数永远不会达到零,因此永远不会成为收集和清理的候选者。
Robe Pike 在回复 Golang 中允许导入周期的提案时表示,这是一个值得预先简单化的领域。进口周期可能很方便,但其成本可能是灾难性的。他们应该继续被禁止。

调试导入周期
关于导入循环错误最糟糕的是,Golang 不会告诉您导致错误的源文件或部分代码。因此,很难弄清楚代码库何时很大。您可能会想知道不同的文件/包来检查问题到底出在哪里。为什么golang不显示导致错误的原因?因为循环中不只有一个罪魁祸首源文件。
但它确实显示了导致问题的软件包。因此,您可以查看这些软件包并解决问题。
要可视化项目中的依赖关系,您可以使用godepgraph,一个 Go 依赖关系图可视化工具。可以通过运行以下命令来安装:
go get github.com/kisielk/godepgraph它以Graphviz点格式显示图形。如果您安装了 graphviz 工具(您可以从此处下载),您可以通过将输出管道传输到 dot 来渲染它:
godepgraph -s import-cycle-example | dot -Tpng -o godepgraph.png您可以在输出 png 文件中看到导入周期:

除此之外,您还可以使用它go list来获得一些见解(运行go help list以获取更多信息)。
go list -f '{\{join .DepsErrors "\n"\}}' <import-path>您可以提供导入路径,也可以将当前目录留空。
处理进口周期
当你遇到导入周期错误时,退后一步,思考一下项目组织。处理导入周期的最明显且最常见的方法是通过接口实现。但有时你并不需要它。有时您可能不小心将包裹分成了几个。检查创建导入周期的包是否紧密耦合并且它们需要彼此才能工作,它们可能应该合并到一个包中。在Golang中,包是一个编译单元。如果两个文件必须始终一起编译,则它们必须位于同一个包中。
接口方式:
- 包通过导入 package
p1来使用包中的函数/变量。p2p2 - 包
p2可以从包中调用函数/变量,p1而无需导入包p1。所有需要传递的包p1实例都实现了 中定义的接口p2,这些实例将被视为包p2对象。
这就是 packagep2忽略 package 的存在p1并且导入周期被破坏的方式。
应用上述步骤后,打包p2代码:
package p2
import (
"fmt"
)
type pp1 interface {
HelloFromP1()
}
type PP2 struct {
PP1 pp1
}
func New(pp1 pp1) *PP2 {
return &PP2{
PP1: pp1,
}
}
func (p *PP2) HelloFromP2() {
fmt.Println("Hello from package p2")
}
func (p *PP2) HelloFromP1Side() {
p.PP1.HelloFromP1()
}包p1代码如下所示:
package p1
import (
"fmt"
"import-cycle-example/p2"
)
type PP1 struct{}
func New() *PP1 {
return &PP1{}
}
func (p *PP1) HelloFromP1() {
fmt.Println("Hello from package p1")
}
func (p *PP1) HelloFromP2Side() {
pp2 := p2.New(p)
pp2.HelloFromP2()
}您可以使用main包中的此代码进行测试。
package main
import (
"import-cycle-example/p1"
)
func main() {
pp1 := p1.PP1{}
pp1.HelloFromP2Side() // Prints: "Hello from package p2"
}您可以在 GitHub 上的jogendra/import-cycle-example-go上找到完整的源代码
使用接口打破循环的其他方法可以是将代码提取到单独的第三个包中,该包充当两个包之间的桥梁。但很多时候它会增加代码重复。您可以采用这种方法,同时牢记您的代码结构。
“三通”进口链:包 p1 -> 包 m1 & 包 p2 -> 包 m1
丑陋的方式:
有趣的是,您可以通过使用go:linkname. go:linkname是编译器指令(用作//go:linkname localname [importpath.name])。此特殊指令不适用于其后面的 Go 代码。相反,//go:linkname指令指示编译器使用“importpath.name”作为源代码中声明为“localname”的变量或函数的目标文件符号名称。(定义来自golang.org,乍一看很难理解,看下面的源代码链接,我尝试用它解决导入循环。)
有许多 Go 标准包依赖于使用go:linkname. 有时您还可以使用它解决代码中的导入周期问题,但您应该避免使用它,因为它仍然是一种 hack,并且 Golang 团队不推荐。
这里需要注意的是,Golang 标准包不是用来go:linkname避免导入周期的,而是用它来避免导出不应该公开的 API。
这是我使用以下方法实现的解决方案的源代码go:linkname:
-> jogendra/import-cycle-example-go -> golinkname
底线
当代码库很大时,导入周期绝对是一件痛苦的事情。尝试分层构建应用程序。较高层应该导入较低层,但较低层不应该导入较高层(它会产生循环)。记住这一点,有时将紧密耦合的包合并到一个包中是比通过接口解决问题更好的解决方案。但对于更一般的情况,接口实现是打破导入周期的好方法。