背景需求:
制作一个EXCEL模板,每个班级的班主任统计 班级图书量(一个孩子10本,最多35个孩子350本)
EXCEL模板



1.0版本:
将这个模板制作N份——每班一份
'
项目:班级图书统计表
核心:一个EXCEL模板批量生成N个班级的表格,然后合在一个EXCEL内变成N个工作簿(便于了解各班情况)+合并为1个工作簿(便于对数目名称分类统计)
作者:阿夏
时间:2024年1月8日19:03'''
#导入模块xlrd
import xlrd
import openpyxl
import pandas as pd
import os
import time
# 先在桌面上建立一个“图书”的文件夹,里面做一个EXCEL基础模板
# 在图书文件夹里新建一个“整理”的文件夹
imagePath=r'C:\Users\jg2yXRZ\OneDrive\桌面\图书'
imagePath2=imagePath+'/整理'
# 反斜杠
if not os.path.exists(imagePath2): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath2) # 若图片文件夹不存在就创建
# 班级名称(用遍历,就不用每次都写长串的列表了
classroom=[]
for a in ['托']:
for b in range(1,3): # 托班两个
classroom.append('{}{}班'.format(a,b))
for c in ['小','中','大']:
for d in range(1,8): # 小中大都是7个班
# 如果要用“一、二、三班”汉字表示,就是for d in ['一 ','二','三'】但是这种情况下 小一班前面要加0101,否则汉字拼音会让排序混乱
bj='{}{}班'.format(c,d)
# 如果某个年级没有6班,就跳过,本学期班级号都是连贯的
# if bj=='中6班':
# pass
# else:
# classroom.append(bj)
classroom.append(bj)
print(classroom)
print(len(classroom))
# 打开EXCEL文件,修改标题,并保存
for x in range(len(classroom)):
#打开工作表模板
wb = openpyxl.load_workbook(imagePath+r'/(模板)大1班班级图书汇总表.xlsx')
# EXCEL模板里面只有一个工作簿
sheet = wb['Sheet1']
# 在第一行里写入新的标题(模板里面的字体字号已居中经确定,所以不用再考虑这些,直接写入文字即可)
sheet['A1']='XX幼儿园 {} 班级图书汇总表'.format(classroom[x])
# 另存为
wb.save(imagePath2+r'/{}班级图书汇总表.xlsx'.format(classroom[x]))
wb.close()
# EXCEL模板不能有页眉页脚



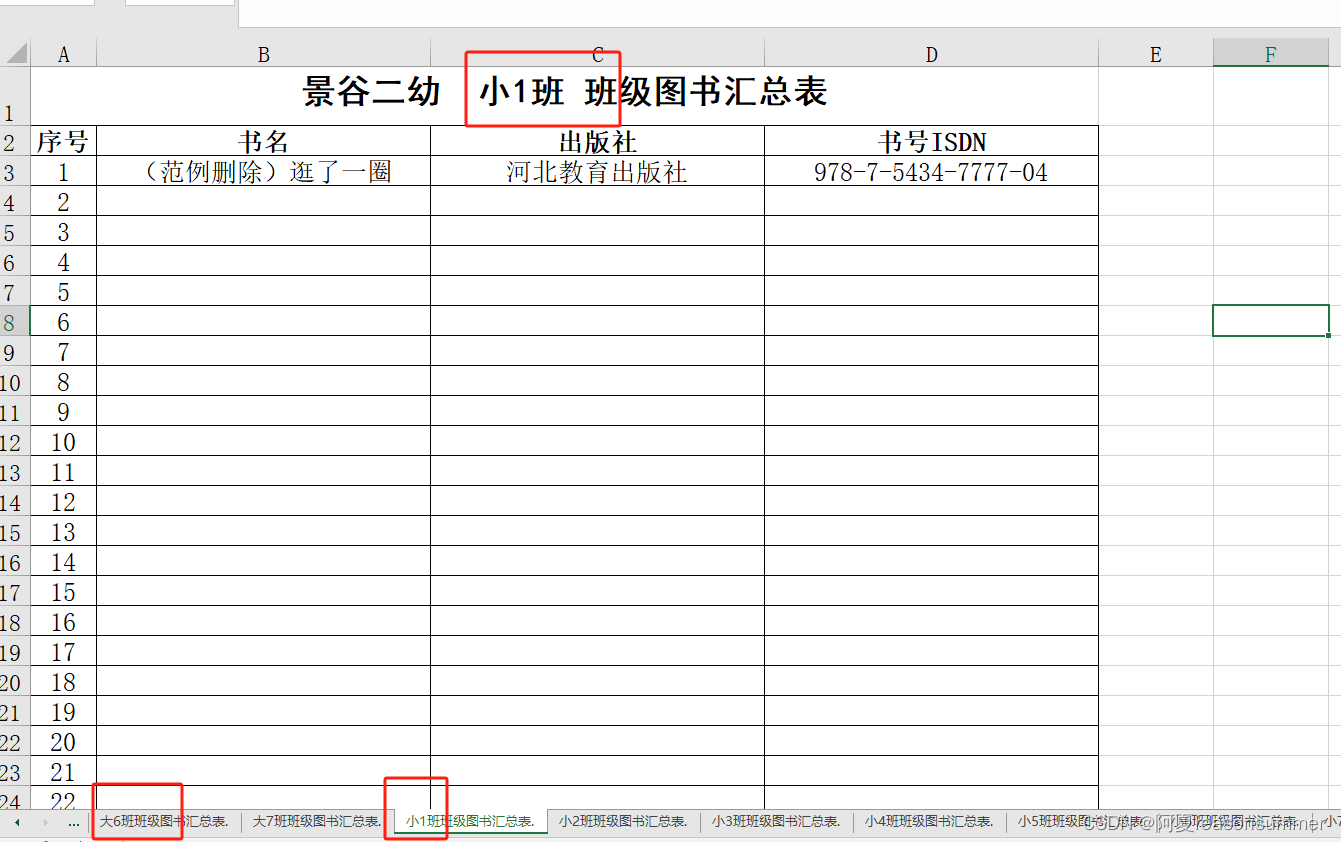
2.0版本:
后来我了解班主任已经用Word将书名进行统计(确保一页A4)打印,所以,我将23份汇总表合并在一起,做成共享编辑,班主任们用电脑打开共享文档,把Word里面的内容批量复制进去即可
(复制后格式边框可能会消失,但是由于在一个Excel,可以批量全选标签,批量统一制作每页的格式)
'''
项目:班级图书统计表
核心:一个EXCEL模板批量生成N个班级的表格,然后合在一个EXCEL内变成N个工作簿(便于了解各班情况)+合并为1个工作簿(便于对数目名称分类统计)
作者:阿夏
时间:2024年1月8日19:03'''
#导入模块xlrd
import xlrd
import openpyxl
import pandas as pd
import os
import time
# 先在桌面上建立一个“图书”的文件夹,里面做一个EXCEL基础模板
# 在图书文件夹里新建一个“整理”的文件夹
imagePath=r'C:\Users\jg2yXRZ\OneDrive\桌面\图书'
imagePath2=imagePath+'/整理'
# 反斜杠
if not os.path.exists(imagePath2): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath2) # 若图片文件夹不存在就创建
# 班级名称(用遍历,就不用每次都写长串的列表了
classroom=[]
for a in ['托']:
for b in range(1,3): # 托班两个
classroom.append('{}{}班'.format(a,b))
for c in ['小','中','大']:
for d in range(1,8): # 小中大都是7个班
# 如果要用“一、二、三班”汉字表示,就是for d in ['一 ','二','三'】但是这种情况下 小一班前面要加0101,否则汉字拼音会让排序混乱
bj='{}{}班'.format(c,d)
# 如果某个年级没有6班,就跳过,本学期班级号都是连贯的
# if bj=='中6班':
# pass
# else:
# classroom.append(bj)
classroom.append(bj)
print(classroom)
print(len(classroom))
# 打开EXCEL文件,修改标题,并保存
for x in range(len(classroom)):
#打开工作表模板
wb = openpyxl.load_workbook(imagePath+r'/(模板)大1班班级图书汇总表.xlsx')
# EXCEL模板里面只有一个工作簿
sheet = wb['Sheet1']
# 在第一行里写入新的标题(模板里面的字体字号已居中经确定,所以不用再考虑这些,直接写入文字即可)
sheet['A1']='XX幼儿园 {} 班级图书汇总表'.format(classroom[x])
# 另存为
wb.save(imagePath2+r'/{}班级图书汇总表.xlsx'.format(classroom[x]))
wb.close()
# EXCEL模板不能有页眉页脚
time.sleep(2)
# # 把整理里面的多个EXCEL工作表合并在一个工作表内N个工作簿、
# 获取"整理"目录下所有的表
gzb = os.listdir(imagePath2)
print(gzb)
with pd.ExcelWriter(imagePath+r'/XX幼儿园{}个班级 班级图书汇总表合.xlsx'.format(len(classroom))) as writer:
# # 循环遍历表格
for i in gzb:
# 拼接每个文件的路径
file_path = imagePath2+ '/' + i
# 工作簿表名=文件名称的前3个元素“大X班”
sheet_name = i[:3]
df = pd.read_excel(file_path)
#变相解决表格中第一行第一列为空的缺陷
string = "".join(list(str(i) for i in df.index))
# 判断如果索引都为数字,则不保留索引(根据自己代码调整)
if string.isdigit():
df.to_excel(writer, sheet_name,index=False)
else:
df.to_excel(writer, sheet_name)
存在问题:
把所有工作表放在一个工作表的不同工作簿里,原来的格式不见了
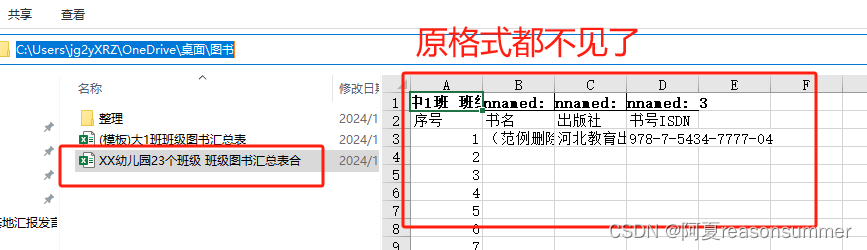

暂时处理方式:
全选标签。统一修改格式
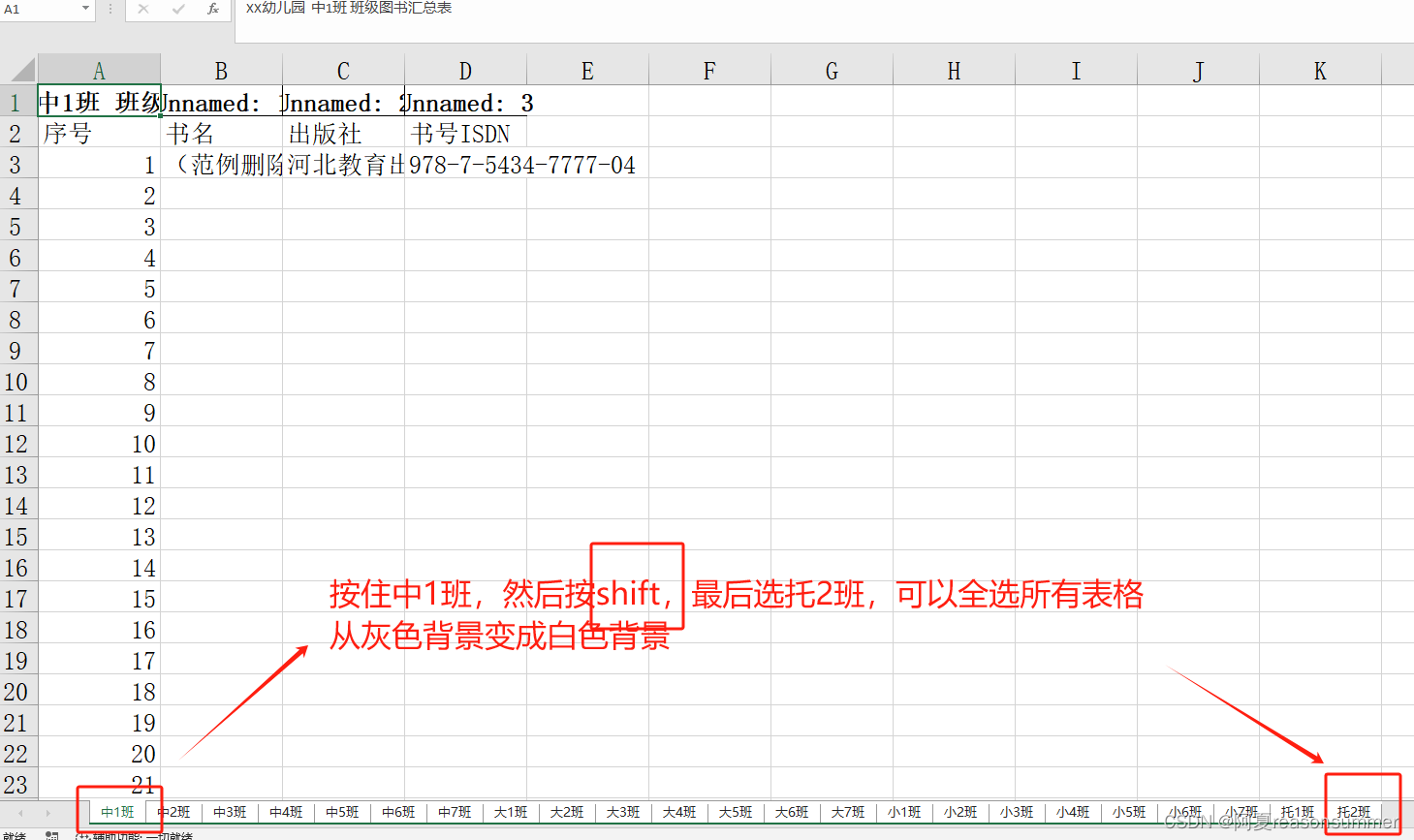




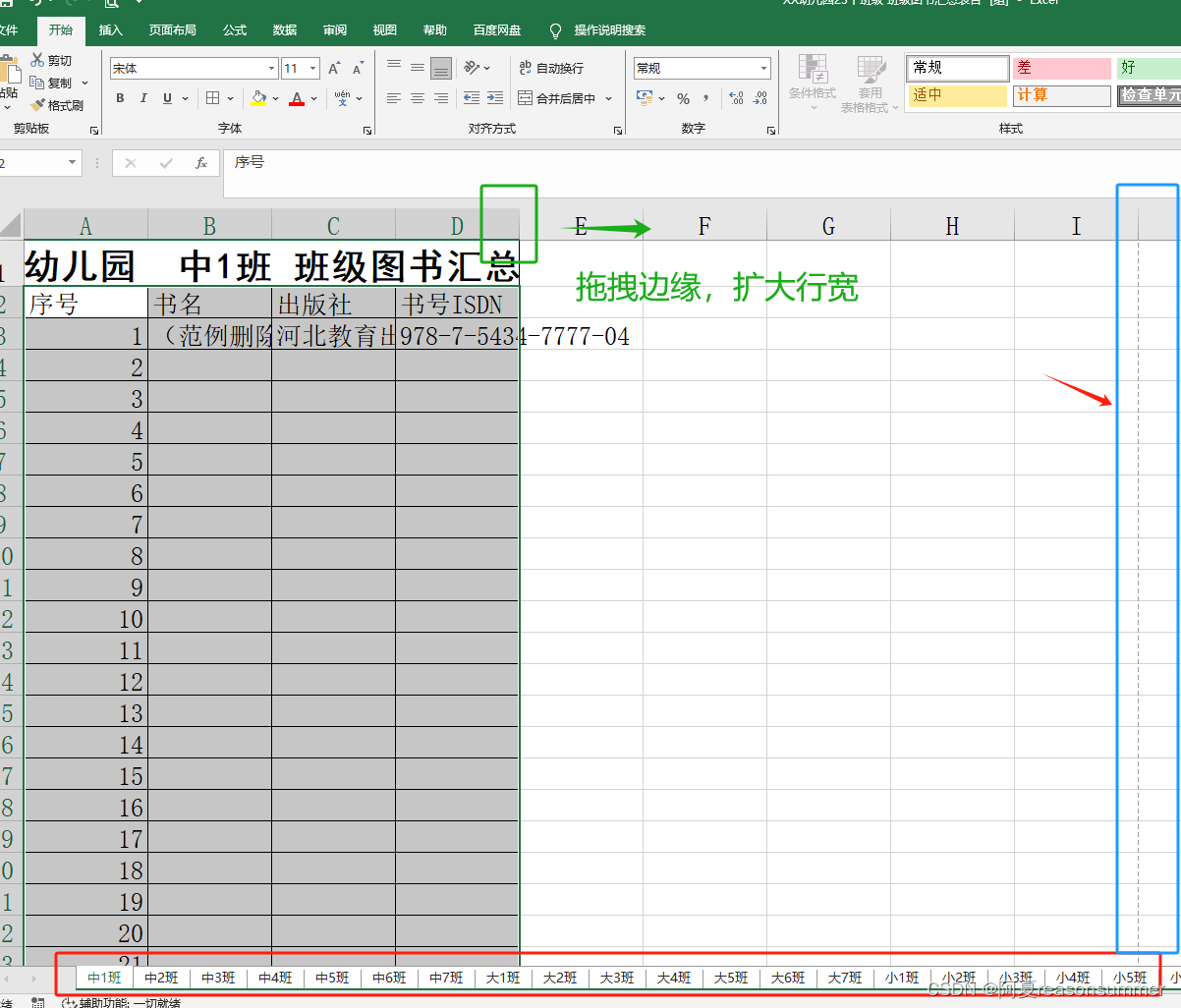
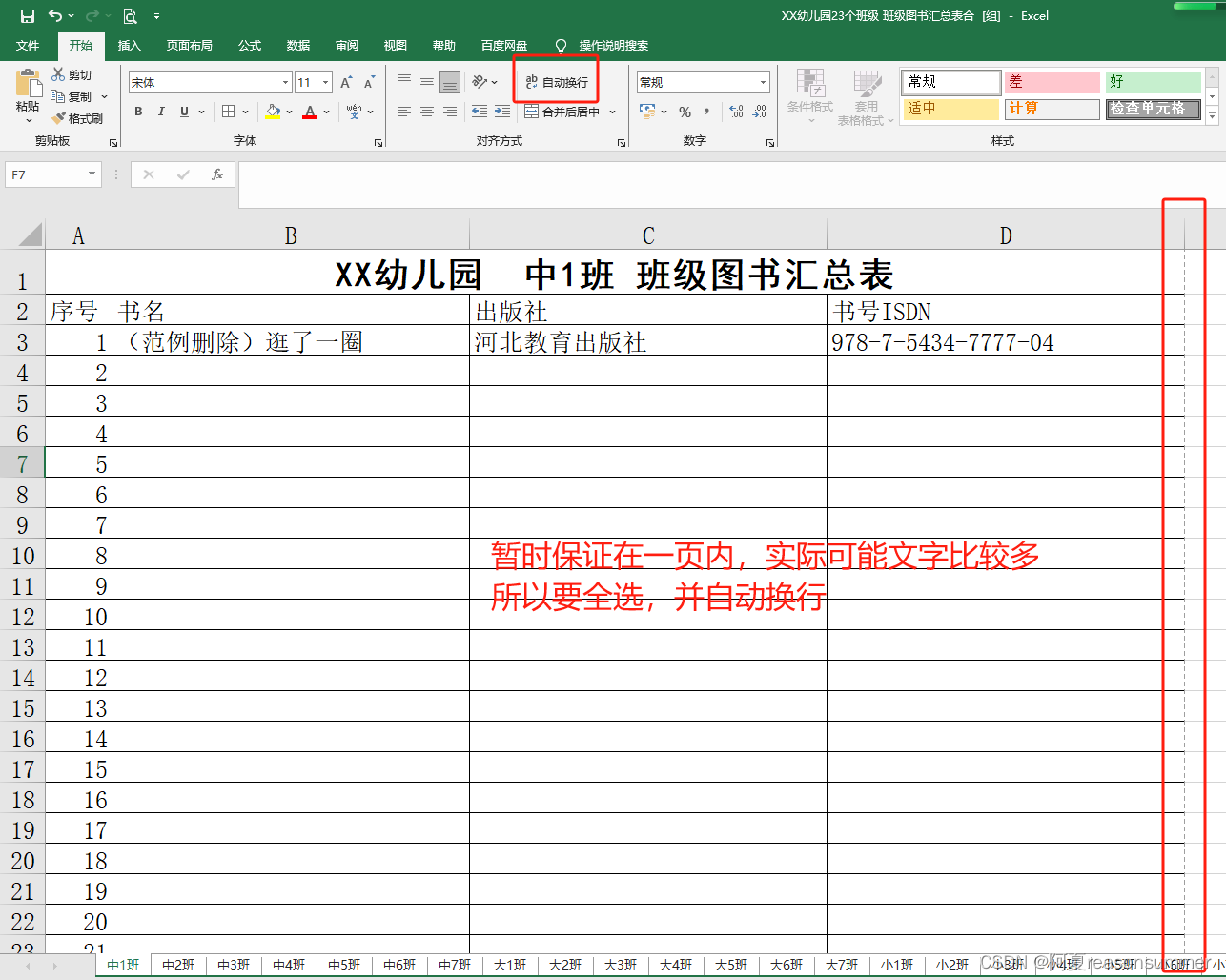
发到手机里,转成编辑模式共享。

使用情况:
给领导发了两个版本:


最后领导觉得还是打包发送方便,所以就是每个班级填一份,组长收齐。

思考:
我更喜欢第二款共享编辑模式制作汇总表格,但是格式消失,人工批量改格式还是比较繁琐的,但是目前测试的几个代码都不能复制格式,后续一定能找到直接复制表格样式的代码。






![[Docker] Mac M1系列芯片上完美运行Docker](https://img-blog.csdnimg.cn/direct/4f4d4a4d953040ddbee1bcbe02c0203a.png)