我们来做一个节点分类的任务,选择的数据集是Karate Club,Karate是空手道的意思,所以这就是一个空手道俱乐部的数据。
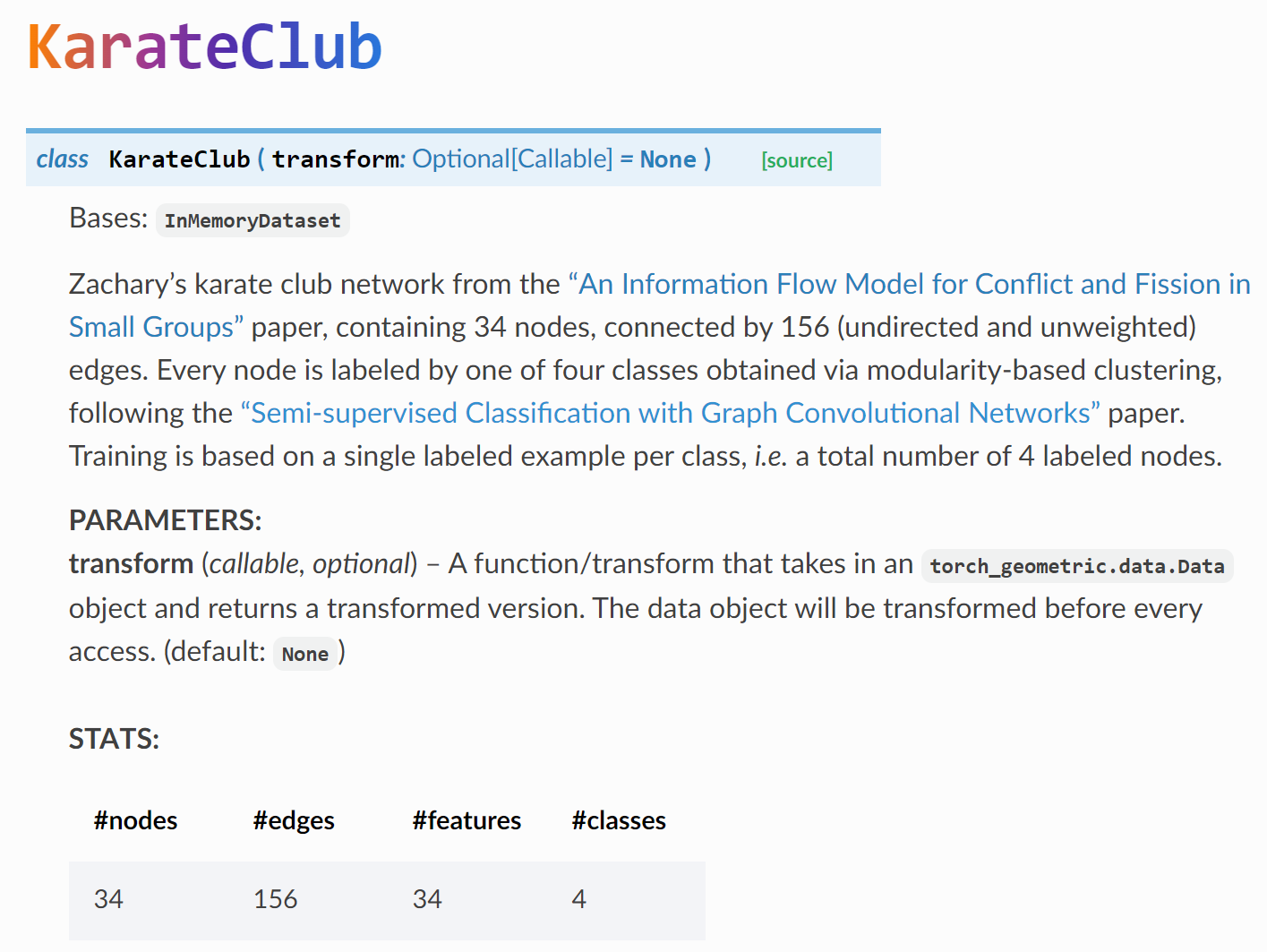
简而言之,这个数据集,包含34个节点,156条无向无权边,结点总共分为4类,此外,每个节点还有34个特征,也就是说还有34个指标来描述空手道俱乐部的每个成员。欸?特征数怎么和节点数一样,没错,就是one-hot编码。
下图是论文原图,颜色表示了类别。
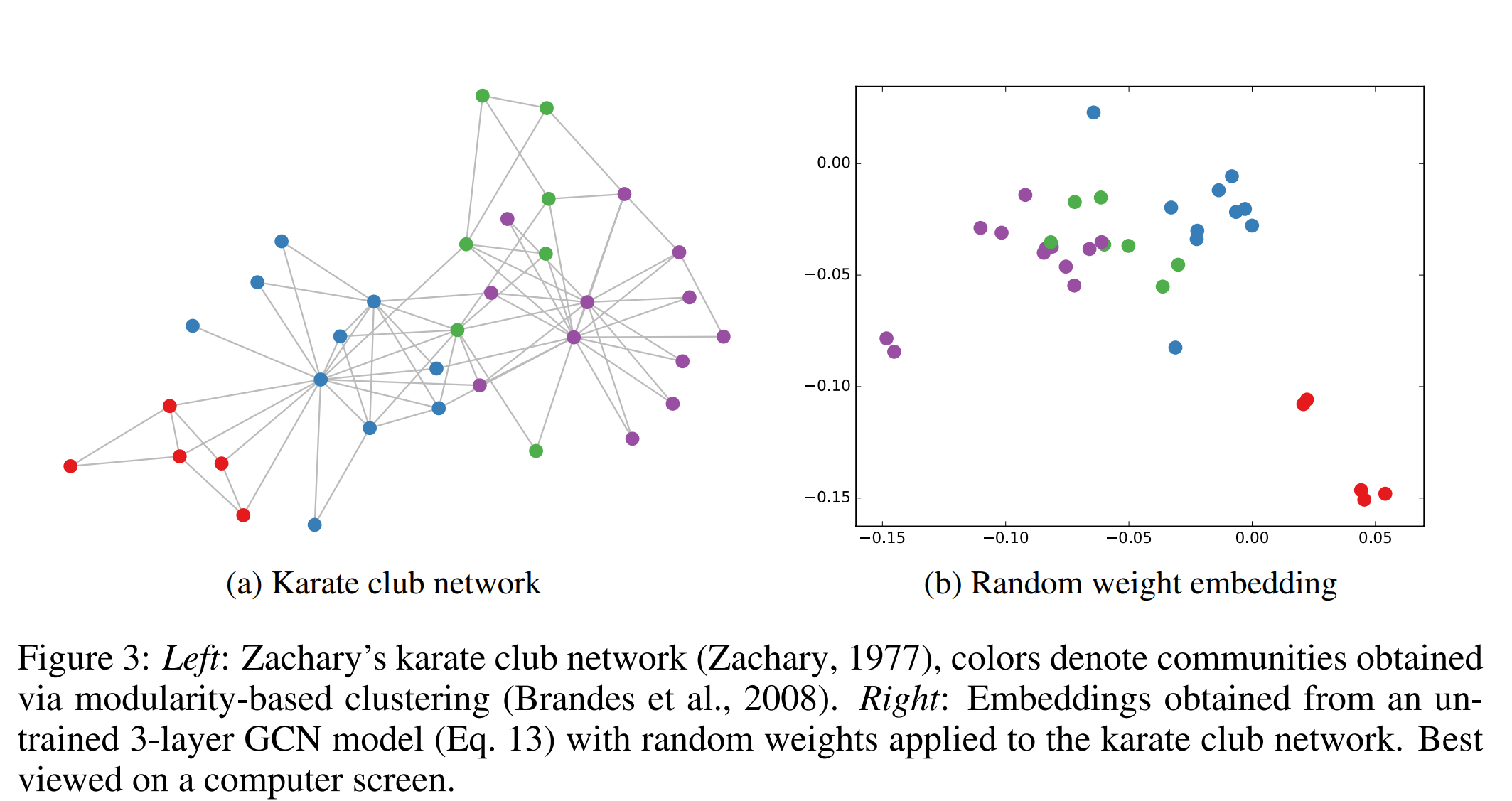
数据集的详细说明
这个数据集是由社会学家Wayne W. Zachary在1977年的论文An Information Flow Model for Conflict and Fission in Small Groups中提出的,基于他对一个美国大学空手道俱乐部的观察和记录。这个数据集包含34个节点和78条边,每个节点代表一个空手道俱乐部的成员,每条边代表两个成员之间的社交关系。
在收集数据的过程中,俱乐部的管理员和教练之间发生了冲突,导致俱乐部分裂为两个社区,一半成员跟随教练,另一半成员跟随管理员或离开俱乐部。Zachary利用图的结构信息,成功地预测了除了一个成员之外的所有成员的类别。
Zaharu’s karateclub数据集还根据2017年的论文Semi-supervised Classification with Graph Convolutional Networks,给每个节点赋予了一个四分类的标签,表示它们属于哪个社区,这些标签是通过基于模块度的聚类方法得到的。
再说一遍数据集的本质:这个数据集,包含34个节点,156条无向无权边,结点总共分为4类,此外,每个节点还有34个特征,也就是说还有34个指标来描述空手道俱乐部的每个成员。欸?特征数怎么和节点数一样,没错,就是one-hot编码。
加载并探索数据集
torch_geometric.datasets里已经有了这个数据集,我们可以查看一下这个数据的一些信息。包括有几个图(有的数据集有很多张图,比如有好几个俱乐部,每个俱乐部是一张图,这里是只有一张图),结点/边特征个数,结点类别个数。
from torch_geometric.datasets import KarateClub
dataset = KarateClub()
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of node features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
print(f'Number of edge features: {dataset.num_edge_features}')
Dataset: KarateClub():
======================
Number of graphs: 1
Number of node features: 34
Number of classes: 4
Number of edge features: 0
可以看到只有一张图,34个结点特征和4个类别。
这里需要明确的是,数据集是数据集,图是图,图是包含在数据集中的,接下来,我们拿出这个数据集的第一张图(也是唯一一张图),来看看这个图中的一些信息。包括图的节点个数、边的个数、结点的平均度、是否有孤立点、有没有自己连接自己等等。
data = dataset[0] # Get the first graph object.
print(data)
print('==============================================================')
# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {(data.num_edges) / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')
print(f'Contains isolated nodes: {data.has_isolated_nodes()}')
print(f'Contains self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')
Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])
==============================================================
Number of nodes: 34
Number of edges: 156
Average node degree: 4.59
Number of training nodes: 4
Training node label rate: 0.12
Contains isolated nodes: False
Contains self-loops: False
Is undirected: True
Data这个数据类型
我们来详细看看Data这个数据类型。
PyTorch Geometric是一个用于图神经网络的PyTorch库,它可以处理各种类型的图数据。在PyTorch Geometric中,每个图都由一个Data对象表示,它包含了描述图结构的所有信息。Data对象可以像一个普通的Python字典一样使用,也可以提供一些分析图结构的有用功能。
Data对象可以有多个属性,每个属性都是一个PyTorch张量。例如,上面的代码中,Data对象有四个属性:
- edge_index:一个2 x 156的张量,表示图中的边的连接关系。每一列是一个边的起点和终点的索引,例如第一列[0, 1]表示从节点0到节点1的一条边。
- x:一个34 x 34的张量,表示图中的节点的特征。每一行是一个节点的34维特征向量,例如第一行[-1]表示节点0的特征。
- y:一个34维的张量,表示图中的节点的标签。每个元素是一个节点的类别,例如第一个元素0表示节点0属于类别0。
- train_mask:一个34维的布尔张量,表示哪些节点的标签是已知的。每个元素是True或False,例如第一个元素True表示节点0的标签是已知的。
注意了,Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])这里面的数字,都是表示维度。
这个Data对象表示了一个有34个节点,156条边的图,其中只有4个节点的标签是已知的,其余的节点的标签需要通过图神经网络来推断。
Data对象还提供了一些实用函数,用于推断图的一些基本属性。例如,我们可以通过以下方式来判断图是否有孤立的节点(没有任何边相连的节点),是否有自环(从一个节点到自己的边),或者是否是无向图(每条边都是双向的):
- data.isolated_nodes():返回一个布尔张量,表示哪些节点是孤立的。
- data.contains_self_loops():返回一个布尔值,表示图是否有自环。
- data.is_undirected():返回一个布尔值,表示图是否是无向的。
coo format
在这里我还想补充要给知识点,也就是coo format,这是用来表示图的一种方式,本质上是表示稀疏矩阵的一种方式,也就是用三个向量分别表示,行、列、值,请看下面详细介绍:
coo format是一种稀疏矩阵的存储格式,它只记录矩阵中非零元素的位置和值。coo format的全称是coordinate format,意思是坐标格式,因为它用两个坐标来表示每个非零元素的行和列索引。例如,一个4 x 4的矩阵:
[ 0 3 0 1 1 0 2 0 0 1 0 0 1 0 0 0 ] \begin{bmatrix} 0 & 3 & 0 & 1 \\\\ 1 & 0 & 2 & 0 \\\\ 0 & 1 & 0 & 0 \\\\ 1 & 0 & 0 & 0 \end{bmatrix} 0101301002001000
可以用coo format表示为:
row = [ 0 , 0 , 1 , 1 , 2 , 3 ] col = [ 1 , 3 , 0 , 2 , 1 , 0 ] data = [ 3 , 1 , 1 , 2 , 1 , 1 ] \begin{aligned} &\text{row} = [0, 0, 1, 1, 2, 3] \\\\ &\text{col} = [1, 3, 0, 2, 1, 0] \\\\ &\text{data} = [3, 1, 1, 2, 1, 1] \end{aligned} row=[0,0,1,1,2,3]col=[1,3,0,2,1,0]data=[3,1,1,2,1,1]
其中,row和col是两个长度为非零元素个数的数组,分别存储每个非零元素的行和列索引。data是一个同样长度的数组,存储每个非零元素的值。这样,就可以用三个数组来代替一个完整的矩阵,节省了空间和计算资源。
在图神经网络领域,coo format可以用来表示图的邻接矩阵,即图中每两个节点之间是否有边相连的矩阵。由于图的邻接矩阵通常是稀疏的,即大部分节点之间没有边相连,所以用coo format可以有效地压缩和处理图的结构信息。一些图神经网络的库,如PyTorch Geometric,就支持用coo format来输入图的邻接矩阵。
可视化一下图
接下来我们可视化一下这个图,看看和我们上面展示真实的图是不是一样的。
可视化,我们使用的networkx这个包,首先我们需要把Data转换成networkx支持的图结构。这里是使用的to_networkx函数。
# Helper function for visualization.
%matplotlib inline
import torch
import networkx as nx
import matplotlib.pyplot as plt
# Visualization function for NX graph or PyTorch tensor
def visualize(h, color, epoch=None, loss=None, accuracy=None):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
if torch.is_tensor(h):
h = h.detach().cpu().numpy()
plt.scatter(h[:, 0], h[:, 1], s=140, c=color, cmap="Set2")
if epoch is not None and loss is not None and accuracy['train'] is not None and accuracy['val'] is not None:
plt.xlabel((f'Epoch: {epoch}, Loss: {loss.item():.4f} \n'
f'Training Accuracy: {accuracy["train"]*100:.2f}% \n'
f' Validation Accuracy: {accuracy["val"]*100:.2f}%'),
fontsize=16)
else:
nx.draw_networkx(h, pos=nx.spring_layout(h, seed=42), with_labels=False,
node_color=color, cmap="Set2")
plt.show()
from torch_geometric.utils import to_networkx
G = to_networkx(data, to_undirected=True)
visualize(G, color=data.y)

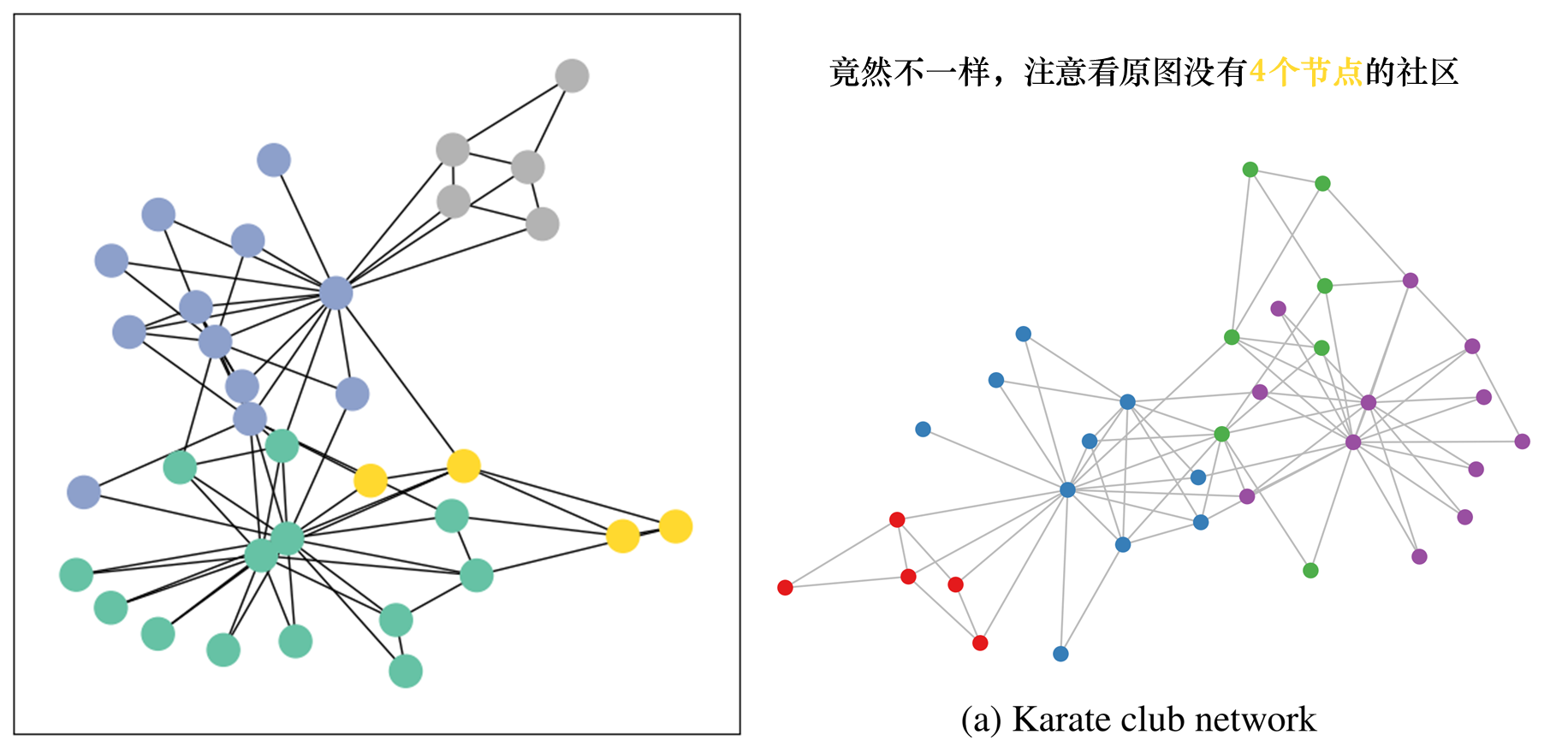
虽然不一样,不过问题不大,和后续的分析没有关系。
用图卷积神经网络(GCN)对节点进行低维嵌入
接下来我们看看如何使用PyG(PyTorch Geometric)库来实现图神经网络(GNNs)。我们用最简单的GNN结构——GCN layer,它可以通过节点特征表示x和COO格式的edge_index来执行图卷积操作,从而更新节点的特征。
输入输出与模型本质
输入是什么?
节点特征表示x和COO格式的edge_index,也就是节点特征和节点间的连接关系的信息。
输出是什么?
GNN的输出目标是学习一个函数f,它可以将图中的每个节点及其特征向量映射到一个低维的嵌入向量,这个嵌入向量可以反映节点在图中的结构和语义信息,从而用于后续的任务,如节点分类、边预测或图回归等。
通俗理解:用一个向量来表示这个节点,这个由GCN layer组成的GNN就是为了学习到一个从节点特征和节点间的连接关系到节点的向量表示的一个方法。
下面我们来看看如何实现吧!注释非常详细!
模型的定义与训练,训练前后的比较
__init__和forward是两个特殊的方法,用于定义一个PyTorch的神经网络模型,__init__是初始化方法,用于创建模型中需要用到的各种层和参数,forward是前向传播方法,用于定义模型的计算流程,即如何用层和参数来计算模型的输出。
三个图卷积层是GCN模型的核心部分,图卷积层是一种能够有效地处理图数据的神经网络层,它可以实现图数据的信息传递和聚合。每个图卷积层都可以收集每个节点的一跳(one hop)邻居(直接相连的节点)的信息,但是当我们把三个图卷积层叠加在一起时,我们就可以收集每个节点的三跳邻居(最多相隔三条边的节点)的信息,这样可以使得模型能够捕捉到更广泛的图结构信息。
GCNConv层还可以降低节点特征的维度,从34维降到2维(
34
→
4
→
4
→
2
34 \rightarrow 4 \rightarrow 4 \rightarrow 2
34→4→4→2),也就是说,经过三个GCNConv层后,每个节点的特征会变成2维的向量,这个向量可以看作是节点在图卷积神经网络的嵌入空间中的表示,可以用于可视化或其他任务。每个GCNConv层后面还加了一个tanh函数,这是一种非线性激活函数,可以增加模型的表达能力,也可以避免梯度消失或爆炸的问题。
在三个图卷积层之后,我们还应用了一个线性变换层(torch.nn.Linear),这个层的作用是对每个节点的嵌入向量进行线性变换,得到每个类别的得分,然后可以用softmax函数计算每个类别的概率,这个层相当于一个分类器,可以将我们的节点映射到四个类别/社区之一。起到监督学习的作用。
我们的模型的输出有两部分,一部分是最后的分类器的输出,也就是每个节点的类别得分或概率,另一部分是最后的节点嵌入矩阵,也就是每个节点在图卷积神经网络的嵌入空间中的表示,这两部分都可以用于不同的目的。
import torch
from torch.nn import Linear
from torch_geometric.nn import GCNConv
# 从PyTorch Geometric库中导入GCNConv类,这是一个图卷积层,可以实现图数据的信息传递和聚合
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
torch.manual_seed(1234)
# 创建一个GCNConv层,命名为conv1,这个层的输入特征维度是dataset.num_features,
# 也就是数据集中每个节点的特征数,输出特征维度是4,也就是经过这个层后,每个节点的特征会变成4维的向量。
self.conv1 = GCNConv(dataset.num_features, 4)
# 创建一个GCNConv层,命名为conv2,这个层的输入特征维度是4,
# 也就是上一个层的输出特征维度,输出特征维度也是4,也就是经过这个层后,每个节点的特征仍然是4维的向量。
self.conv2 = GCNConv(4, 4)
# 创建一个GCNConv层,命名为conv3,这个层的输入特征维度是4,
# 也就是上一个层的输出特征维度,输出特征维度是2,也就是经过这个层后,每个节点的特征会变成2维的向量,
# 这个向量可以看作是节点在图卷积神经网络的嵌入空间中的表示。
self.conv3 = GCNConv(4, 2)
# 创建一个Linear层,命名为classifier,这个层的输入特征维度是2,
# 也就是上一个层的输出特征维度,输出特征维度是dataset.num_classes,
# 也就是数据集中的类别数,这个层的作用是对每个节点的嵌入向量进行线性变换,
# 得到每个类别的得分,然后可以用softmax函数计算每个类别的概率。
self.classifier = Linear(2, dataset.num_classes)
def forward(self, x, edge_index):
'''
定义模型的前向传播方法,这里需要接收两个参数,
x是节点特征矩阵,每一行是一个节点的特征向量,
edge_index是边索引矩阵,每一列是一条边的两个端点的索引,
这两个参数可以描述一个图的结构和属性。
'''
h = self.conv1(x, edge_index)
# 调用conv1层,传入节点特征矩阵和边索引矩阵,得到经过第一次图卷积后的节点特征矩阵,命名为h。
h = h.tanh()
# 对h矩阵中的每个元素应用双曲正切函数,这是一种非线性激活函数,
# 可以增加模型的表达能力,也可以避免梯度消失或爆炸的问题。
h = self.conv2(h, edge_index)
# 调用conv2层,传入经过第一次激活后的节点特征矩阵和边索引矩阵,
# 得到经过第二次图卷积后的节点特征矩阵,仍然命名为h,覆盖原来的值。
h = h.tanh()
# 对h矩阵中的每个元素应用双曲正切函数,这是第二次激活。
h = self.conv3(h, edge_index)
h = h.tanh() # Final GNN embedding space.
# Apply a final (linear) classifier.
# 调用classifier层,传入节点嵌入矩阵,得到每个节点的类别得分矩阵,
# 命名为out,这个矩阵可以用于计算交叉熵损失或预测节点的类别。
out = self.classifier(h)
# 返回类别得分矩阵和节点嵌入矩阵
return out, h
# 创建一个GCN类的实例,命名为model,这是一个图卷积神经网络的模型对象,可以用于训练或测试
model = GCN()
print(model)
GCN(
(conv1): GCNConv(34, 4)
(conv2): GCNConv(4, 4)
(conv3): GCNConv(4, 2)
(classifier): Linear(in_features=2, out_features=4, bias=True)
)
前面说了,我们的模型分为两部分,一部分是用图卷积进行图嵌入,得到节点的低维向量表示,另一部分则是一个分类器,起到监督学习的作用,根据标签来调整前面图卷积的效果。
我们为了能够看到GNN的训练的效果,我们可以比较这两个节点的嵌入向量:①不经过训练,只有图卷积嵌入得到的低维向量;②经过训练。
我们可以通过两种方法来评估,第一种是直接看四类样本的分布情况,由于我们最终是用2维向量进行表示的,所以很直观地可以用二维平面可视化;第二种是用嵌入向量构建分类器,如果用同样的分类器训练前和训练后的效果一样,那就说明图卷积没啥用,反之则可以说明还是有用的。
model = GCN()
_, h_no_train = model(data.x, data.edge_index)
print(f'Embedding shape: {list(h_no_train.shape)}')
visualize(h_no_train, color=data.y)
Embedding shape: [34, 2]

# 导入sklearn的模块
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from sklearn.model_selection import train_test_split # 数据切分
from sklearn.metrics import accuracy_score # 准确率评估
from sklearn.tree import plot_tree # 决策树绘图
import matplotlib.pyplot as plt # 画图工具
# 划分训练集和测试集,随机种子设为0,测试集比例设为0.2
X_train, X_test, y_train, y_test = train_test_split(h_no_train.detach().numpy(), data.y.detach().numpy(), random_state=10, test_size=0.2)
# 创建一个决策树分类器,使用默认参数,随机种子设为0
clf = DecisionTreeClassifier(random_state=0)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
acc = accuracy_score(y_test, y_pred)
print("The accuracy score is:", acc)
# 可视化决策树
plt.figure(figsize=(10, 10)) # 设置画布大小
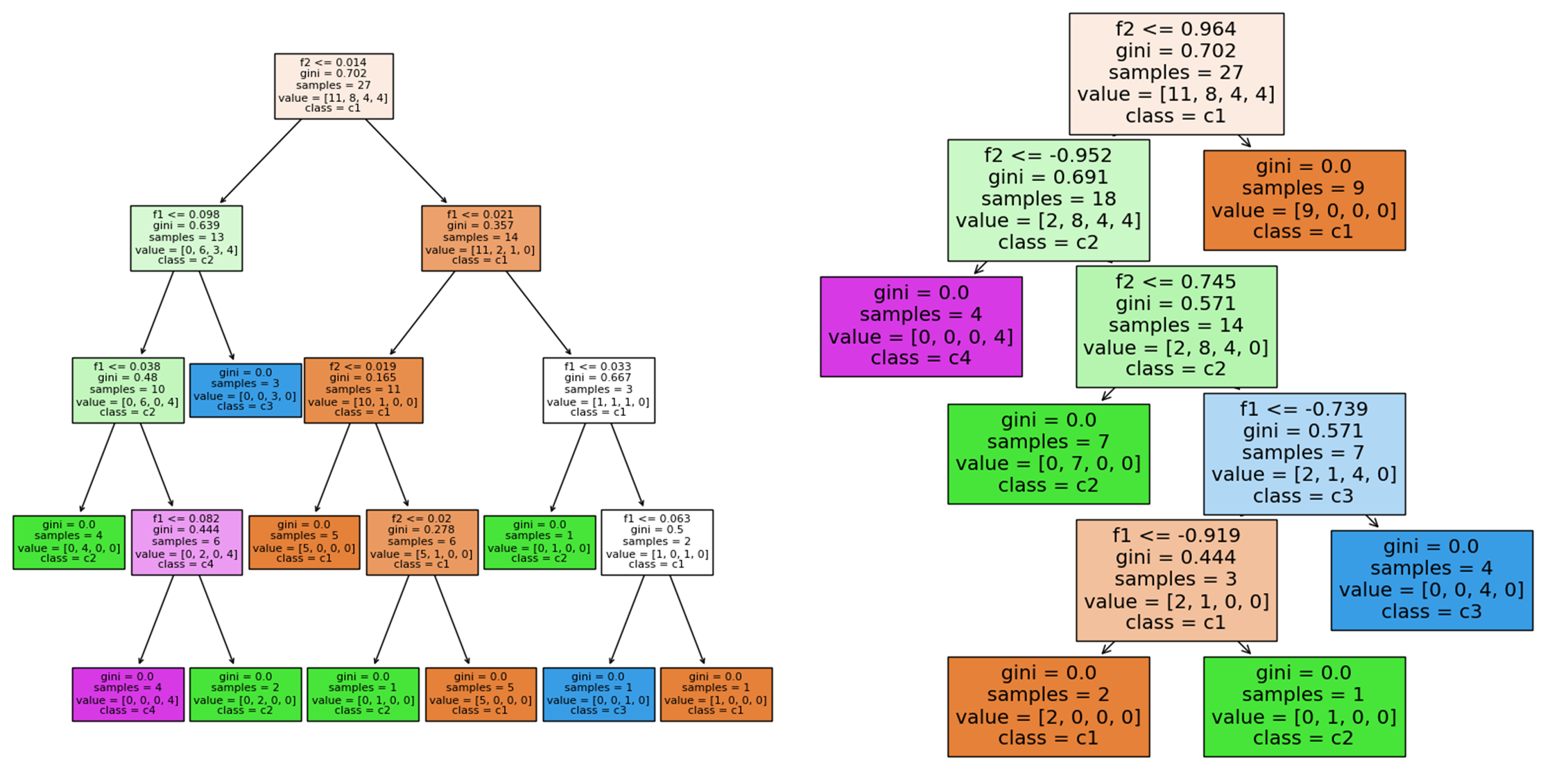
plot_tree(clf, feature_names=["f1", "f2", "f3", "f4"], class_names=["c1", "c2", "c3", "c4"], filled=True) # 绘制决策树,填充颜色,设置特征名和类别名
plt.show() # 显示图像
The accuracy score is: 0.7142857142857143

# 导入sklearn的模块
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.metrics import precision_recall_curve, roc_curve, auc
from sklearn.model_selection import KFold
X = h_no_train.detach().numpy()
y = data.y.detach().numpy()
# 创建一个逻辑回归模型,使用默认参数,随机种子设为0
clf = LogisticRegression(random_state=0)
# 使用5折交叉验证,得到每折的准确率
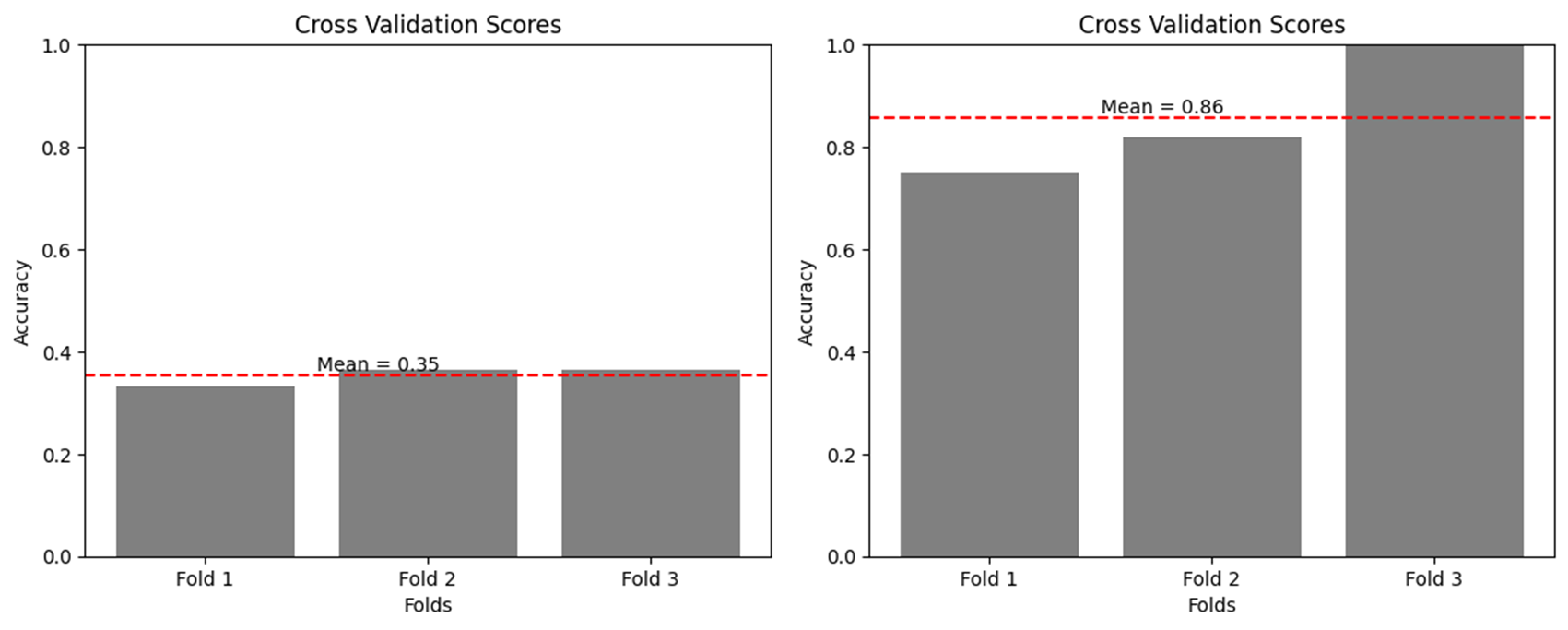
acc_scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
# 计算平均的准确率
acc_mean = acc_scores.mean()
# 打印平均的准确率
print("The average accuracy score is:", acc_mean)
# 导入matplotlib.pyplot模块
import matplotlib.pyplot as plt
# 设置柱状图的x轴坐标和高度
x = ["Fold 1", "Fold 2", "Fold 3"]
height = acc_scores
# 绘制柱状图
plt.bar(x, height, color="grey")
# 添加标题和坐标轴标签
plt.title("Cross Validation Scores")
plt.xlabel("Folds")
plt.ylabel("Accuracy")
plt.ylim(0, 1) # 设置y轴的范围为0~1
# 计算平均值
mean = sum(acc_scores) / len(acc_scores)
# 在图上显示平均值
plt.axhline(y=mean, color="red", linestyle="--")
plt.text(0.5, mean + 0.01, f"Mean = {mean:.2f}")
# 显示图形
plt.show()
The average accuracy score is: 0.35353535353535354

模型如何训练?
上面是训练前的,下面我们来看看训练后的。
要看训练后的,当然得知道怎么训练。
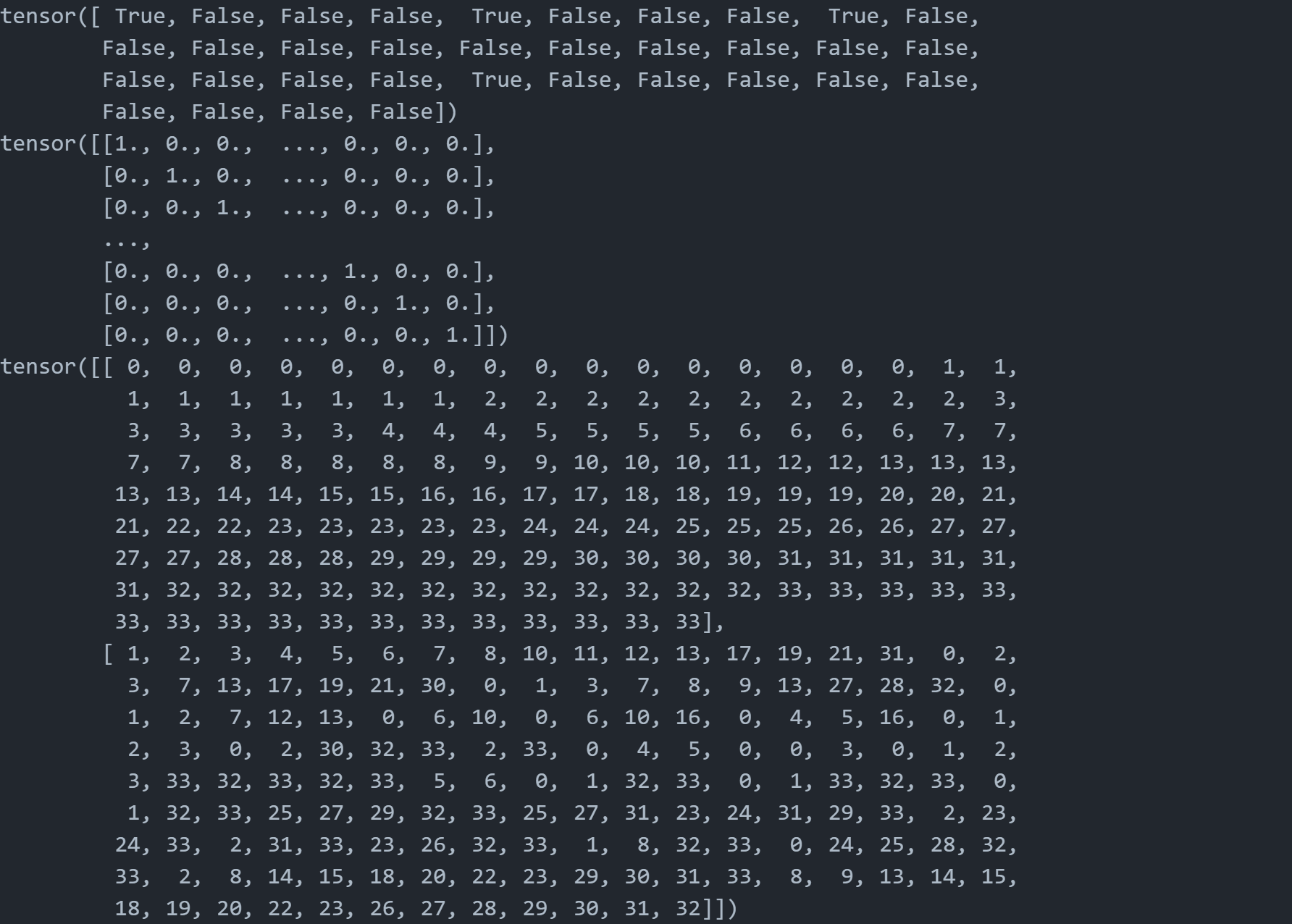
先看看这些关键的数据长什么样。
print(data.train_mask)
# print(data.train_mask.shape())
print(data.x)
# print(data.x.shape())
print(data.edge_index)
# print(data.edge_index.shape())
下面谈谈模型训练几个关键的地方,注释也非常详细。
这里的data.train_mask,其实就是一个[ True, False, False,…]的一个用来索引的向量,里面有4个是True,所以out[data.train_mask]就是选了4个出来。
train_mask虽然叫train_mask,但我觉得是起到一个测试的作用:一是用来在训练过程中计算这四个节点(也是样本)的loss,并更新参数使得loss减少;二是在一次训练结束后用这四个样本来计算一下准确率,作为training accuracy。
再说一下validation accuracy,前面说了,更新参数是根据train_mask的,计算准确率也是train_mask,那么在全图上的表现如何呢?也就是在所有样本的表现如何呢?于是就把上面的out[data.train_mask]直接换成out了。
import time
from IPython.display import Javascript # Restrict height of output cell.
display(Javascript('''google.colab.output.setIframeHeight(0, true, {maxHeight: 430})'''))
model = GCN()
# 定义交叉熵损失函数,用于计算模型的预测值和真实值之间的差异
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
# 定义 Adam 优化器,用于根据损失函数的梯度更新模型的参数,学习率为 0.01
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Define optimizer.
def train(data):
'''
这里的data.train_mask,其实就是一个[ True, False, False,......]的一个用来索引的向量
里面有4个是True,所以out[data.train_mask]就是选了4个出来,虽然叫train_mask,但我觉得是起到一个测试的作用
一是用来在训练过程中计算这四个节点(也是样本)的loss,并更新参数使得loss减少
二是在一次训练结束后用这四个样本来计算一下准确率,作为training accuracy
再说一下validation accuracy,前面说了,更新参数是根据train_mask的,
计算准确率也是train_mask,那么在全图上的表现如何呢?也就是在所有样本的表现如何呢?
于是就把上面的out[data.train_mask]直接换成out了。
'''
# 调用优化器的 zero_grad 方法,清除之前的梯度
optimizer.zero_grad() # Clear gradients.
# 调用模型的 forward 方法,传入节点特征 data.x 和边索引 data.edge_index,得到模型的输出 out 和节点嵌入 h
out, h = model(data.x, data.edge_index) # Perform a single forward pass.
# 调用损失函数,传入模型输出的训练节点部分 out[data.train_mask] 和真实标签的训练节点部分 data.y[data.train_mask],计算训练损失
loss = criterion(out[data.train_mask], data.y[data.train_mask]) # Compute the loss solely based on the training nodes.
# 调用损失的 backward 方法,求出损失函数对模型参数的梯度
loss.backward() # Derive gradients.
# 调用优化器的 step 方法,根据梯度更新模型参数
optimizer.step() # Update parameters based on gradients.
# 上面是训练部分,下面就是看训练的怎么样了
# 定义一个字典,用于存储训练准确率和验证准确率
accuracy = {}
# Calculate training accuracy on our four examples
predicted_classes = torch.argmax(out[data.train_mask], axis=1) # [0.6, 0.2, 0.7, 0.1] -> 2
target_classes = data.y[data.train_mask]
accuracy['train'] = torch.mean(
torch.where(predicted_classes == target_classes, 1, 0).float())
# Calculate validation accuracy on the whole graph
predicted_classes = torch.argmax(out, axis=1)
target_classes = data.y
accuracy['val'] = torch.mean(
torch.where(predicted_classes == target_classes, 1, 0).float())
return loss, h, accuracy
# 定义一个循环,迭代 100 次
for epoch in range(100):
loss, h, accuracy = train(data)
# Visualize the node embeddings every 10 epochs
if epoch % 10 == 0:
visualize(h, color=data.y, epoch=epoch, loss=loss, accuracy=accuracy)
time.sleep(0.3)
可以看到随着训练次数的增加四类点的分布也呈现了区域化的特征,说明训练是有用的。

# 导入sklearn的模块
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from sklearn.model_selection import train_test_split # 数据切分
from sklearn.metrics import accuracy_score # 准确率评估
from sklearn.tree import plot_tree # 决策树绘图
import matplotlib.pyplot as plt # 画图工具
# 划分训练集和测试集,随机种子设为0,测试集比例设为0.2
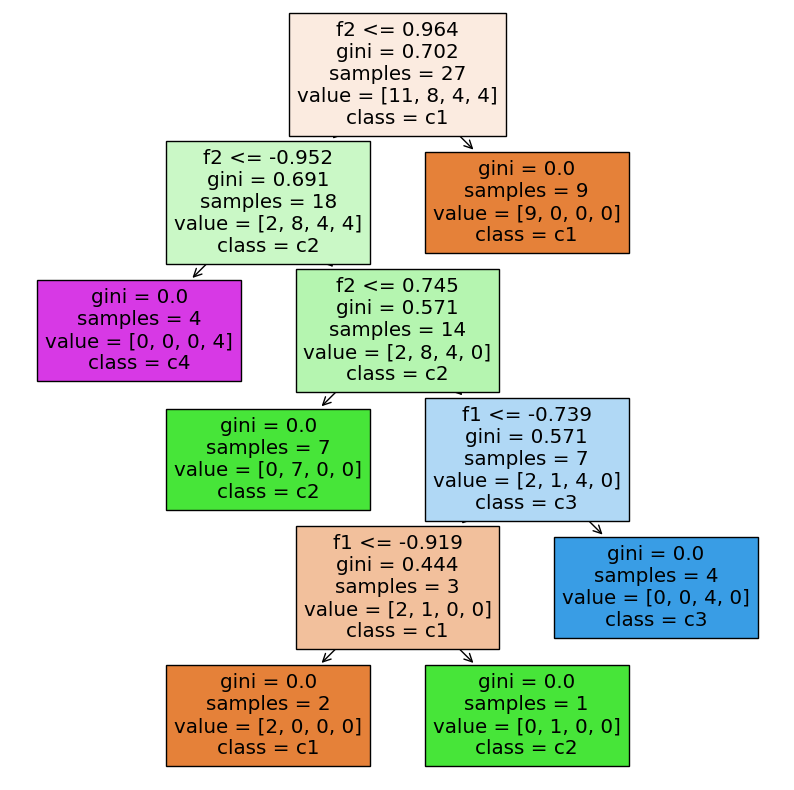
X_train, X_test, y_train, y_test = train_test_split(h.detach().numpy(), data.y.detach().numpy(), random_state=10, test_size=0.2)
# 创建一个决策树分类器,使用默认参数,随机种子设为0
clf = DecisionTreeClassifier(random_state=0)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
acc = accuracy_score(y_test, y_pred)
print("The accuracy score is:", acc)
# 可视化决策树
plt.figure(figsize=(10, 10)) # 设置画布大小
plot_tree(clf, feature_names=["f1", "f2", "f3", "f4"], class_names=["c1", "c2", "c3", "c4"], filled=True) # 绘制决策树,填充颜色,设置特征名和类别名
plt.show() # 显示图像
The accuracy score is: 0.8571428571428571
# 导入sklearn的模块
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.metrics import precision_recall_curve, roc_curve, auc
from sklearn.model_selection import KFold
X = h.detach().numpy()
y = data.y.detach().numpy()
# 创建一个逻辑回归模型,使用默认参数,随机种子设为0
clf = LogisticRegression(random_state=0)
# 使用5折交叉验证,得到每折的准确率
acc_scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
# 计算平均的准确率
acc_mean = acc_scores.mean()
# 打印平均的准确率
print("The average accuracy score is:", acc_mean)
# 导入matplotlib.pyplot模块
import matplotlib.pyplot as plt
# 设置柱状图的x轴坐标和高度
x = ["Fold 1", "Fold 2", "Fold 3"]
height = acc_scores
# 绘制柱状图
plt.bar(x, height, color="grey")
# 添加标题和坐标轴标签
plt.title("Cross Validation Scores")
plt.xlabel("Folds")
plt.ylabel("Accuracy")
plt.ylim(0, 1) # 设置y轴的范围为0~1
# 计算平均值
mean = sum(acc_scores) / len(acc_scores)
# 在图上显示平均值
plt.axhline(y=mean, color="red", linestyle="--")
plt.text(0.5, mean + 0.01, f"Mean = {mean:.2f}")
# 显示图形
plt.show()
The average accuracy score is: 0.8560606060606061
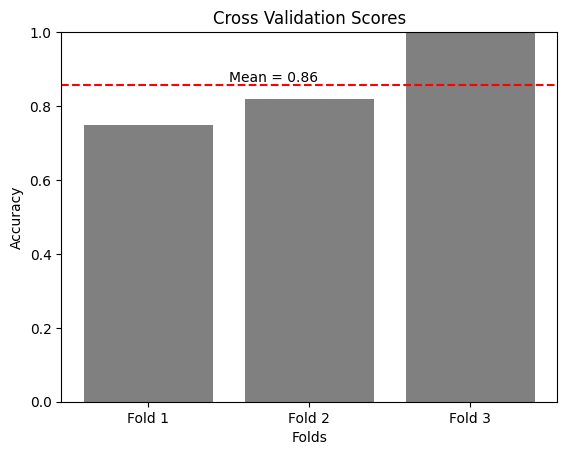
可以看到,经过训练后,这些点的二维分布(嵌入向量)比之前更加离散,也就是更容易将其分开,换句话说就是分类器可以更好地进行分类,这也就导致了分类器在训练后数据通常会比在训练前数据上表现得更好。
结语
图神经网络的学习道阻且长,但行则将至,动手写起代码来吧,我们一起努力!如果觉得还不错,可以点赞收藏哟!
欣赏一下苏轼的寒食帖!