整体架构
日志采集端
Flume
Flume的设计宗旨是向Hadoop集群批量导入基于事件的海量数据。系统中最核心的角色是agent,Flume采集系统就是由一个个agent所连接起来形成。每一个agent相当于一个数据传递员,内部有三个组件:
- source: 采集源,用于跟数据源对接,以获取数据
- sink:传送数据的目的地,用于往下一级agent或者最终存储系统传递数据
- channel:agent内部的数据传输通道,用于从source传输数据到sink
Logstash
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到存储库中。数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash是基于pipeline方式进行数据处理的,pipeline可以理解为数据处理流程的抽象。在一条pipeline数据经过上游数据源汇总到消息队列中,然后由多个工作线程进行数据的转换处理,最后输出到下游组件。一个logstash中可以包含多个pipeline。
- Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器:
- Input:数据输入组件,用于对接各种数据源,接入数据,支持解码器,允许对数据进行编码解码操作;必选组件;
- output:数据输出组件,用于对接下游组件,发送处理后的数据,支持解码器,允许对数据进行编码解码操作;必选组件;
- filter:数据过滤组件,负责对输入数据进行加工处理;可选组件;Logstash安装部署
- pipeline:一条数据处理流程的逻辑抽象,类似于一条管道,数据从一端流入,经过处理后,从另一端流出;一个pipeline包括输入、过滤、输出3个部分,其中输入和输出部分是必选组件,过滤是可选组件;instance:一个Logstash实例,可以包含多条数据处理流程,即多个pipeline;
- event:pipeline中的数据都是基于事件的,一个event可以看作是数据流中的一条数据或者一条消息;
Filebeat
Filebeat是一个日志文件托运工具,在服务器上安装客户端后,Filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到ElasticSearch或者Logstarsh中存放。
当你开启Filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
Filebeat由两个主要组成部分组成:prospector和 harvesters。这些组件一起工作来读取文件并将事件数据发送到指定的output。
- Harvesters:负责读取单个文件的内容。harvesters逐行读取每个文件,并将内容发送到output中。每个文件都将启动一个harvesters。harvesters负责文件的打开和关闭,这意味着harvesters运行时,文件会保持打开状态。如果在收集过程中,即使删除了这个文件或者是对文件进行重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。默认情况下,Filebeat会一直保持文件的开启状态,直到超过配置的close_inactive参数,Filebeat才会把Harvester关闭。
- Prospector:负责管理Harvsters,并且找到所有需要进行读取的数据源。如果input type配置的是log类型,Prospector将会去配置路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。每个Prospector都运行在自己的Go routine里。
- Filebeat目前支持两种Prospector类型:log和stdin。每个Prospector类型可以在配置文件定义多个。log Prospector将会检查每一个文件是否需要启动Harvster,启动的Harvster是否还在运行,或者是该文件是否被忽略(可以通过配置 ignore_order,进行文件忽略)。如果是在Filebeat运行过程中新创建的文件,只要在Harvster关闭后,文件大小发生了变化,新文件才会被Prospector选择到。
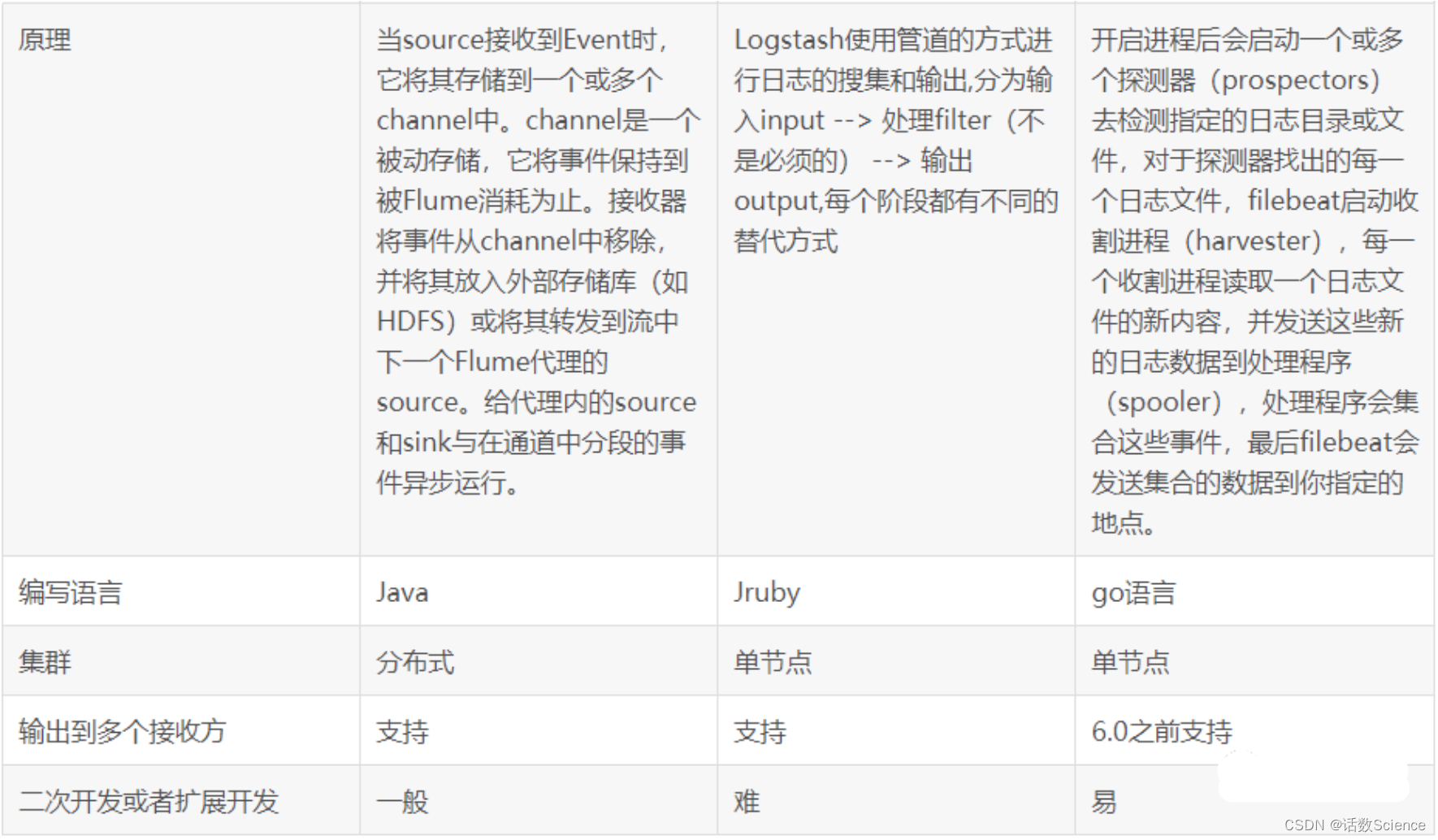
Flume、Logstash、Filebeat对比
Flume和Logstash都是基于JVM,比较吃资源,跟LogServer部署在一起的话会有风险。
而Filebeat是基于Go语言开发,吃资源较少,非常稳定。
Flume更注重于数据的传输,对于数据的预处理不如Logstash。在传输上Flume比Logstash更可靠一些,因为数据会持久化在channel中。数据只有存储在sink端中,才会从channel中删除,这个过程是通过事物来控制的,保证了数据的可靠性。Logstash是ELK组件中的一个,一般都是同ELK其它组件一起使用,更注重于数据的预处理,Logstash有比Flume丰富的插件可选,所以在扩展功能上比Flume全面。但Logstash内部没有persist queue,所以在异常情况下会出现数据丢失的问题。Filebeat是一个轻量型日志采集工具,因为Filebeat是Elastic Stack的一部分,因此能够与ELK组件无缝协作。Filebeat占用的内存要比Logstash小很多。性能比较稳健,很少出现宕机。


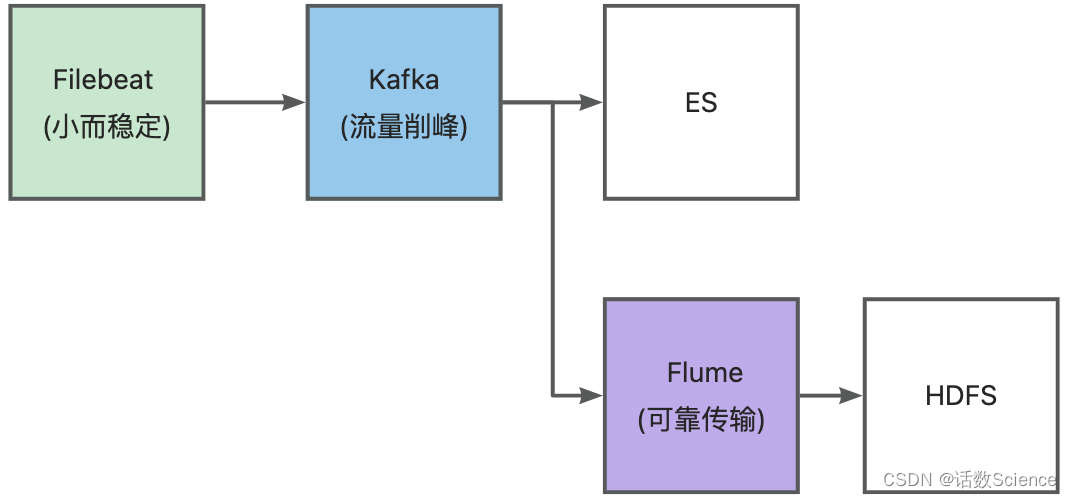
流量削峰Kafka
为什么要使用 kafka?
- 缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
- 解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
- 冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
- 健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
- 异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
下图是理想情况下的系统配置:

实际部署时需要通过ZooKeeper做高可用的保障,kafka到es中间可以通过logstash进行数据的清洗。

日志采集场景问题汇总
怎么确保日志文件不会重复采集?
Filebeat至少一次保证
Filebeat如何保证at least once
filebeat维护了一个registry文件在本地的磁盘,该registry文件维护了所有已经采集的日志文件的状态。 实际上,每当日志数据发送至后端成功后,会返回ack事件。filebeat启动了一个独立的registry协程负责监听该事件,接收到ack事件后会将日志文件的State状态更新至registry文件中,State中的Offset表示读取到的文件偏移量,所以filebeat会保证Offset记录之前的日志数据肯定被后端的日志存储接收到。
由于文件可能会被改名或移动,filebeat会根据inode和设备号来标志每个日志文件。
如果filebeat异常重启,每次采集harvester启动的时候都会读取registry文件,从上次记录的状态继续采集,确保不会从头开始重复发送所有的日志文件。
当然,如果日志发送过程中,还没来得及返回ack,filebeat就挂掉,registry文件肯定不会更新至最新的状态,那么下次采集的时候,这部分的日志就会重复发送,所以这意味着filebeat只能保证at least once,无法保证不重复发送。
还有一个比较异常的情况是,linux下如果老文件被移除,新文件马上创建,很有可能它们有相同的inode,而由于filebeat根据inode来标志文件记录采集的偏移,会导致registry里记录的其实是被移除的文件State状态,这样新的文件采集却从老的文件Offset开始,从而会遗漏日志数据。
为了尽量避免inode被复用的情况,同时防止registry文件随着时间增长越来越大,建议使用clean_inactive和clean_remove配置将长时间未更新或者被删除的文件State从registry中移除。
Filebeat处理文件重命名,删除,截断
- 获取文件信息时会获取文件的device id + indoe作为文件的唯一标识;
- 前面我们提过文件收集进度会被持久化,这样当创建Harvester时,首先会对文件作openFile, 以 device id + inode为key在持久化文件中查看当前文件是否被收集过,收集到了什么位置,然后断点续传;
- 在读取过程中,如果文件被截断,认为文件已经被同名覆盖,将从头开始读取文件;
- 如果文件被删除,因为原文件已被打开,不影响继续收集,但如果设置了CloseRemoved, 则不会再继续收集;
- 如果文件被重命名,因为原文件已被打开,不影响继续收集,但如果设置了CloseRenamed , 则不会再继续收集;
inode号码回收和再分配对filebeat日志采集的影响
inode不是单调递增分配的。
我有几个明确知道创建时间先后顺序的文件,他们的inode号码不是按照创建时间有序递增,后创建的文件可能比先创建的文件inode号码更小,比如下图中的 filebeat.2 比 filebeat.3 更晚创建,但inode号码却更小。
应该是分配出去的inode对应的文件被删除后,inode就可以被回收然后分配出去。
这就引出了filebeat日志采集的一个问题:filebeat是按文件的inode来作为标识符保存文件信息的,如果一个日志文件被采集到了偏移为1KB的位置,然后被删除,接着系统可能将旧文件的inode号码分配给新的日志文件,那么新日志文件的前1KB内容将被filebeat误以为已经采集过了而漏采。该问题的官方描述:https://www.elastic.co/guide/en/beats/filebeat/current/inode-reuse-issue.html
因此filebeat推荐使用 clean_inactive 选项来移除一段时间未活跃过的文件的状态,当然即使这样也需要好运气,期待linux系统不会恰好在这段时间内就分配这个inode给新的日志文件。
文件系统一般由 superblock,inode,block 三部分组成。
1)superblock存储磁盘的文件系统中有多少inode、block
2)inode存储一个文件的元信息,比如文件拥有者和群组、访问时间、修改时间、文件大小等,以及最重要的,文件内容所在的block号。如果一个文件的内容大小超过了一个block,那么inode里面会有多个block的号码;如果一个inode的大小不够存储该文件所有block的号码,那么inode本身其实还有一种多级block索引,确保一定能通过文件inode找到这个文件的所有block。(详情看 参考1)
每个文件有且仅有一个inode。目录也是文件的一种,也有inode。一个inode一般是128byte,但较新文件系统ext4也可设置为256byte。
3)block存储文件内容,一个文件至少占用一个block。每个block的大小固定,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种,在文件系统格式化磁盘时确定。文件系统格式化磁盘时,一般按照固定配比来为inode和block分配空间,这个配比似乎典型值是1:8(参考2,“每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。”)。所以一块磁盘的inode数量是有上限的,所能保存的文件数量不能超过inode数量,所以会出现磁盘还有剩余空间但无法创建新文件的现象。
这种数据存取的方法我们称为索引式文件系统(indexed allocation)。
但FAT文件系统(常见于U盘)不属于这一类,并没有 inode 存在,所以 FAT 没有办法将这个文件的所有 block 在一开始就读取出来。每个 block 号码都记录在前一个 block 当中。
Flume至少一次保证
Flume的At-least-once提交方式
Flume的事务机制,总的来说,保证了source产生的每个事件都会传送到sink中。但是值得一说的是,实际上Flume作为高容量并行采集系统采用的是At-least-once(传统的企业系统采用的是exactly-once机制)提交方式,这样就造成每个source产生的事件至少到达sink一次,换句话说就是同一事件有可能重复到达。这样虽然看上去是一个缺陷,但是相比为了保证Flume能够可靠地将事件从source,channel传递到sink,这也是一个可以接受的权衡。如spooldir的使用,Flume会对已经处理完的数据进行标记。
flume之taildirSource重复获取数据和不释放资源解决办法
- log4j的日志文件肯定是会根据规则进行滚动的:当*.log满了就会滚动把前文件更名为*.log.1,然后重新进行*.log文件打印。这样flume就会把*.log.1文件当作新文件,又重新读取一遍,导致重复。
- 当flume监控的日志文件被移走或删除,flume仍然在监控中,并没有释放资源,当然,在一定时间后会自动释放,这个时间根据官方文档设置默认值是120000ms。
flume会把重命名的文件重新当作新文件读取是因为正则表达式的原因,因为重命名后的文件名仍然符合正则表达式。所以第一,重命名后的文件仍然会被flume监控;第二,flume是根据文件inode&&文件绝对路径 、文件是否为null&&文件绝对路径。
处理参考:flume之taildirSource重复获取数据和不释放资源解决办法_文件中已经有多行数据,flume为什么一直读取一条-CSDN博客



![[java]JAVA中文版API手册 -jdk_api_1.8](https://img-blog.csdnimg.cn/direct/417a1b806bcf4a249d7376038814b3be.png)