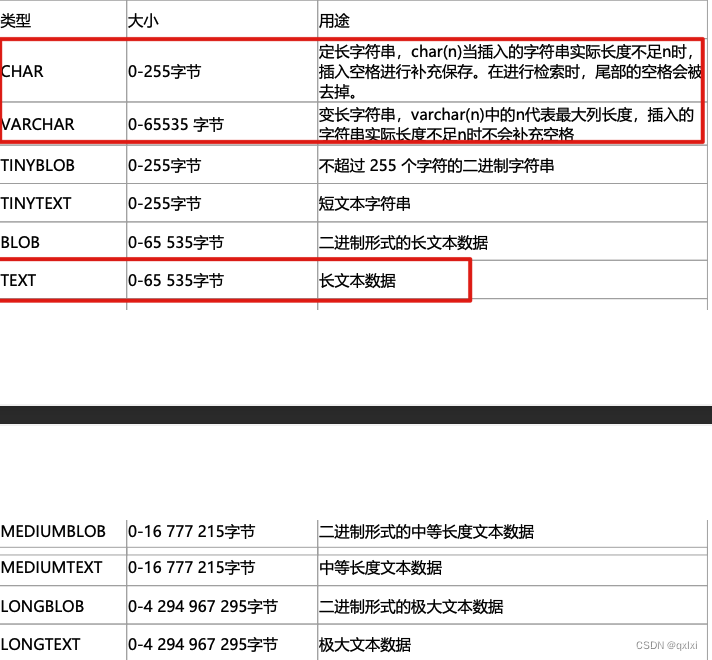
训练好一个模型之后,我们往往要对其进行保存,除非下次用时想再次训练一遍。
下面以一个简单的回归任务来详细讲解模型的保存和加载。
来看这样一组数据:
x=torch.linspace(-1,1,50)x=x.view(50,1)y=x.pow(2)+0.3*torch.rand(50).view(50,1)
画图:
plt.scatter(x.numpy(),y.numpy())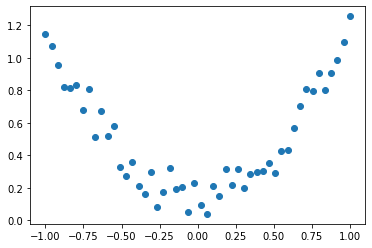
很显然,x与y基本呈二次函数关系,那么接下来我们就来拟合整个函数。
import torchimport matplotlib.pyplot as pltimport torch.nn as nnimport torch.optim as optimx=torch.linspace(-1,1,50)x=x.view(50,1)y=x.pow(2)+0.3*torch.rand(50).view(50,1)net1=nn.Sequential(nn.Linear(1,10),nn.ReLU(),nn.Linear(10,1))criterion=nn.MSELoss()optimizer=optim.SGD(net1.parameters(),lr=0.2)#训练模型for i in range(1000):pred=net1(x)loss=criterion(pred,y)optimizer.zero_grad()loss.backward()optimizer.step()#测试模型net1.eval()with torch.no_grad():y1=net1(x)plt.plot(x.numpy(),y1.numpy(),'r-')plt.scatter(x.numpy(),y.numpy())

结果似乎不错!
这里我们得到了一个网络net1,它可以被当作一个二次函数,用于描述之前的x,y数据的关系。
得到这个网络后,我们想保存它,主要有两种方式:
1,保存整个网络,包括训练后的各个层的参数
#保存整个网络,包括训练后的各个层的参数torch.save(net1,'net1weight.pkl')
2,只保存训练好的网络的参数,速度更快
#只保存训练好的网络的参数,速度更快torch.save(net1.state_dict(),'net1_params.pkl')
假设我们按第一种方式保存,那么下次想要使用次网络时需要这样做:
network=torch.load('net1weight.pkl')#测试模型network.eval()with torch.no_grad():y1=network(x)plt.plot(x.numpy(),y1.numpy(),'b-')plt.scatter(x.numpy(),y.numpy())

假设我们按第二种方式保存,那么下次想要使用次网络时需要这样做:
network=nn.Sequential(nn.Linear(1,10),nn.ReLU(),nn.Linear(10,1))network.load_state_dict(torch.load('net1_params.pkl'))
#测试模型network.eval()with torch.no_grad():y1=network(x)plt.plot(x.numpy(),y1.numpy(),'g-')plt.scatter(x.numpy(),y.numpy())
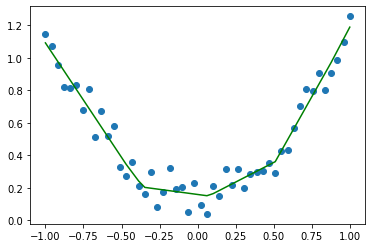
可以看出,第二次首先需要构造出一个一模一样的模型,接着再导入参数即可。当然,这只是个简单的回归模型,其它模型保存与加载同样如此。
总结一下:
模型保存与导入有两种方式:
方式一:
#模型保存torch.save(net1,'net1weight.pkl')#模型导入network=torch.load('net1weight.pkl')
方式二:
#模型保存torch.save(net1.state_dict(),'net1_params.pkl')#模型导入network.load_state_dict(torch.load('net1_params.pkl'))