UnitGen 是我们从 UnitEval 拆分出来的代码数据集生成项目,旨在为基于开源模型供的私有化部署提供更好的编码数据集。
在结合开源模型 + AutoDev 插件之后,你可以使用 UnitGen 结合企业内部现有的代码生成微调数据集,以让模型生成的代码更适合组织内部的需要,提升开发人员效率。
GitHub:https://github.com/unit-mesh/unit-gen
使用文档:https://gen.unitmesh.cc
UnitGen 数据集生成框架
如在先前的文章所介绍,为了保持 UnitMesh 开源 AI 辅助编码方案的完整性,即 UnitGen + AutoDev + UnitEval 工具的一体化,我们所秉持的设计原则是:
统一提示词(Prompt)。统一工具-微调-评估底层的提示词。
代码质量管道(Pipeline)。诸如于代码复杂性、代码坏味道、测试坏味道、API 设计味道等。
可扩展的质量阈。自定义规则、自定义阈值、自定义质量类型等。
基于上述的思想,我们所实现的 UnitGen 架构所如所示:
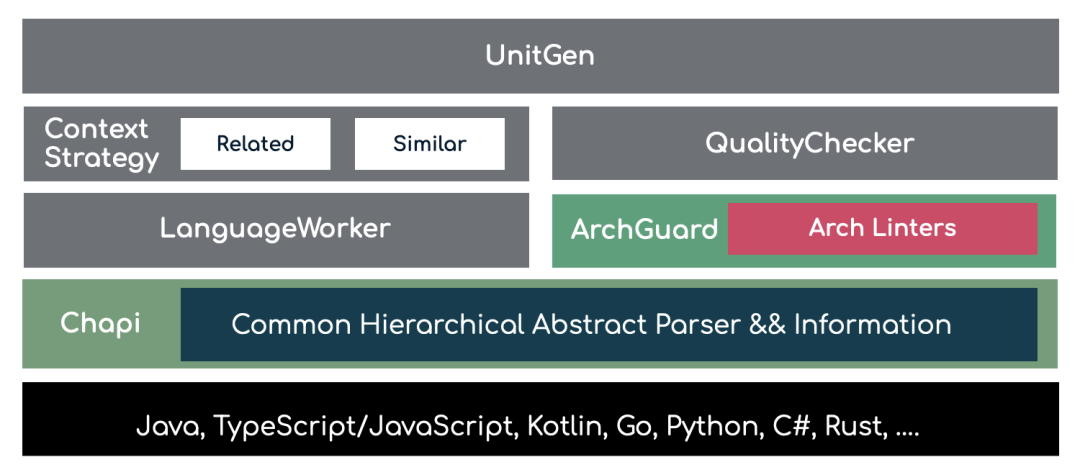
在实现上主要分为两部分:
基于 LanguageWorker 的上下文策略实现。即由于不同语言的语法差异,如文档位置、数据 + 行为实现方式,我们需要根据需要做一些差异化的实现。
基于 ArchGuard 的质量检查。我们会先进行一些基本的长度、是否minifid 检查(JavaScript)等。ArchGuard 只是作为阈值的一部分,以支持:代码、测试代码、MVC 代码的质量检查。
在底层,我们使用了自己开源的 Chapi 来实现对于语言的 AST(抽象语法树) 转换和处理分析,以更好处理语言与数据结构的问题。Chapi 是一个开源的通用层次抽象解析器与信息转换器,它可以将不同编程语言的源代码转换为统一的层次抽象模型。
与此同时,由于架构治理平台 ArchGuard 本身也是基于 Chapi 作为其分析引擎的核心语法处理,所以两者可以实现很好的兼容 + 互补。诸如于在完善 UnitGen 功能的同时,ArchGuard 的质量功能也在持续完善。
UnitGen 文档数据集生成
在文档数据生成上,与先前的补全数据集生成,文档的生成逻辑非常简单 —— 找到对应的注释块(类和方法级),然后生成即可。甚至于,我们可以直接使用代码来解释:
container.DataStructures.forEach { dataStruct ->
// build class comment
val methodCommentIns =
dataStruct.Functions
.filter { it.Name != "PrimaryConstructor" }
.map { function ->
// build method comment
}
// return comments
}在 Chapi 里代码文件是一个 Container,Container 内包含一系列的 DataStructures,每个 DataStructure 则包含了一系列的 Functions。因此,在实现上只需要先构建出所有的注释块,做一些基本的质量检查,再与对应的代码块结合。
UnitGen 测试数据集生成
由于 AutoDev 支持的是整个测试文件的生成,因此在生成测试时要考虑到测试框架和技术框对于项目的影响,所以还需要读取项目的依赖信息。
除此,UnitGen 在测试数据生成上,同样分为类级和方法级,但是方法级的生成比类级稍微复杂一些 —— 需要分析出被测函数。
获取框架与测试框架信息
框架等信息的分析,其实就是 SCA(Software Composition Analysis)软件成分分析。在实现上,我们需要分析出项目的依赖文件、依赖信息,并尝试给出主要的框架。诸如于:
从 package.json 知道项目使用的是 React 框架,并使用了 Jest 作为测试框架
从 build.gradle 中获取项目使用是 Spring Boot 框架,并使用了
spring-boot-starter-test作为测试框架。
所以,我们在 UnitGen 中创建了 ProjectContext 和 TestStack 来管理它们。而在实现上,由于我们在开源的架构治理平台 ArchGuard 中编写了依赖分析模块 analyser_sca ,随后根据不同的语言编写主流的框架和映射。
函数级测试数据集生成
对于文件级的测试生成来说,实现起来非常简单 —— 通过包名和类名来映射,就能通过测试文件找到被测试文件。但是,对于微调来说,会导致样本过少。与此同时,由于我们通常更想要的实现某个方法的测试,所以需要构建和分析 CG(Call graph,函数调用图),以正确匹配测试方法和被测试方法 —— 当时这并非 100% 正确的,需要测试方法在被测试方法最后调用。
而正好我们在 Chapi 中实现了对应的 CG 静态分析,所以可以直接遍历 Function 的 FunctionCalls 就能实现上述的功能。
dataStruct.Functions.mapIndexed { _, function ->
function. c.map {
val canonicalName = it.Package + "." + it.NodeName + ":" + it.FunctionName
if (it.NodeName != underTestFile.NodeName) return@map
val originalContent = underTestFunctionMap[canonicalName] ?: return@map
if (originalContent.isBlank() || function.Content.isBlank()) return@map
// 生成测试指令
}
}而考虑到不同的开发人员编写测试的习惯不一样,所以还需要检查一下测试代码的命名规则:
val namingStyle = dataStruct.checkNamingStyle()人生苦短,我有:https://github.com/phodal/chapi 。
Chapi 支持主流语言(我喜欢使用的)的 FunctionCall,所以在这些语言的 FunctionCall 功能相对比较完整:
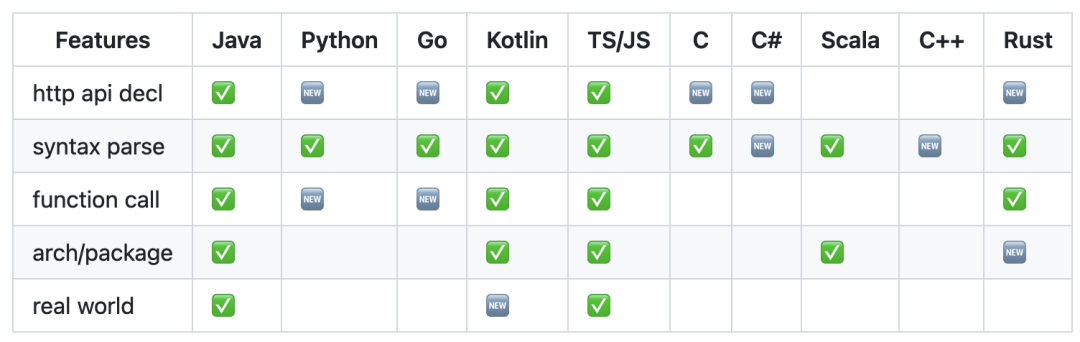
关于 Chapi 的更多介绍见:https://chapi.phodal.com/ 。
其它
在外部测试时,我们使用了 ThoughtWorks 开源项目作为核心,并结合一些框架的官方 examples,诸如 Spring Data Examples, ArchUnit Examples,以更好地辅助开发人员编写对应的测试。
同时,在生成第二个版本的 AutoDev Coder 数据集时,我们人工 review 了一部分代码,结合 OpenAI 重构了注释和一些测试的实现,以提升数据级的质量 —— 以实现真正的人工-智能。