1 Title
Deep Learning for 3D Point Clouds: A Survey(Yulan Guo; Hanyun Wang; Qingyong Hu; Hao Liu; Li Liu; Mohammed Bennamoun)【IEEE Transactions on Pattern Analysis and Machine Intelligence 2020】
2 Conclusion
Deep learning on point clouds is still in its infancy due to the unique challenges faced by the processing of point clouds with deep neural networks. To stimulate future research, this paper presents a comprehensive review of recent progress in deep learning methods for point clouds. It covers three major tasks, including 3D shape classification, 3D object detection and tracking, and 3D point cloud segmentation.It also presents comparative results on several publicly available datasets, together with insightful observations and inspiring future research directions.
3 Good Sentences
1、As a commonly used format, point cloud representation preserves the original geometric information in 3D space without any discretization. Therefore, it is the preferred representation for many scene understanding related applications such as autonomous driving and robotics.(why 3D point cloud is so important)
2、deep learning on 3D point clouds still face several significant challenges, such as the small scale of datasets, the high dimensionality and the unstructured nature of 3D point clouds.(The challenge of 3D point cloud meet)
3、These methods first project a 3D shape into multiple views and extract view-wise features, and then fuse these features for accurate shape classification. How to aggregate multiple view-wise features into a discriminative global representation is a key challenge for these methods.(The principal of Multi-View Based Methods)
介绍:
3D 数据通常可以用不同的格式表示,包括深度图像、点云、网格和体积网格。作为一种常用的格式,点云表示保留了 3D 空间中的原始几何信息,没有任何离散化。因此,它是许多场景理解相关应用(例如自动驾驶和机器人技术)的首选表示。近年来,深度学习技术主导了许多研究领域,例如计算机视觉、语音识别和自然语言处理。然而,3D点云深度学习仍然面临一些重大挑战,例如数据集规模小、3D点云的高维性和非结构化性质。在此基础上,本文重点分析了已用于处理3D点云的深度学习方法。
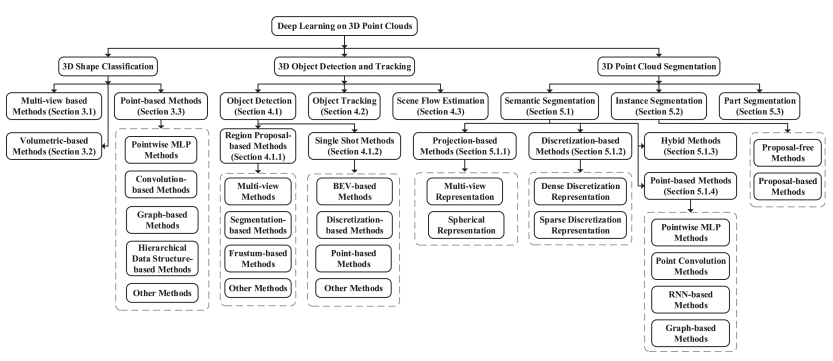
如图为3D 点云深度学习方法的分类。常用3D点云数据集包括ModelNet、ScanObjectNN、ShapeNet 、 PartNet、 S3DIS 、ScanNet、Semantic3D、ApolloCar3D和KITTI 视觉基准套件。
数据集

3D形状分类,有两种类型的数据集:合成数据集和真实数据集。合成数据集中的对象是完整的,没有任何遮挡和背景。相比之下,现实世界数据集中的对象在不同级别上被遮挡,并且某些对象受到背景噪声的污染。
3D对象检测和跟踪,有两种类型的数据集:室内场景和室外城市场景。室内数据集中的点云要么从密集深度图转换而来,要么从 3D 网格中采样。室外城市数据集是为自动驾驶而设计的,其中物体在空间上分离良好,并且这些点云稀疏。
对于 3D 点云分割,这些数据集由不同类型的传感器获取,包括移动激光扫描仪 (MLS) 、航空激光扫描仪(ALS)静态地面激光扫描仪 (TLS) 、RGB-D 相机和其他 3D 扫描仪。这些数据集可用于开发应对各种挑战的算法,包括类似的干扰因素、形状不完整性和类别不平衡。
评估指标
对于 3D 形状分类,总体精度 (OA) 和平均类别精度 (mAcc) 是最常用的性能标准。 “OA”代表所有测试实例的平均准确度,“mAcc”代表所有形状类别的平均准确度。对于 3D 对象检测,平均精度 (AP) 是最常用的标准。它的计算方式是精确率-召回率曲线下的面积。精度和成功度通常用于评估 3D 单目标跟踪器的整体性能。平均多目标跟踪精度 (AMOTA) 和平均多目标跟踪精度 (AMOTP) 是评估 3D 多目标跟踪最常用的标准。对于 3D 点云分割、OA、平均交并集 (mIoU) 和平均类精度是最常用的绩效评估标准。
3D形状分类
用于此任务的方法通常首先学习每个点的嵌入,然后使用聚合方法从整个点云中提取全局形状嵌入。最终通过将全局嵌入输入到几个全连接层中来实现分类。根据神经网络输入的数据类型,现有的3D形状分类方法可以分为基于多视图的方法、基于体积的方法和基于点的方法。基于多视图的方法将非结构化点云投影为 2D 图像,而基于体积的方法将点云转换为 3D 体积表示。然后,利用完善的 2D 或 3D 卷积网络来实现形状分类。相比之下,基于点的方法直接作用于原始点云,无需任何体素化或投影。基于点的方法不会引入显式信息丢失,并且变得越来越流行。

同样,我看这篇文章只是为了3D点云对比循环网络,只关注有关的部分,前两个方法略过了
基于多视图的方法:
这些方法首先将 3D 形状投影到多个视图中并提取视图特征,然后融合这些特征以进行准确的形状分类。如何将多个视图特征聚合成有区别的全局表示是这些方法的关键挑战。
基于体积的方法:
这些方法通常将点云体素化为 3D 网格,然后在体积表示上应用 3D 卷积神经网络 (CNN) 以进行形状分类。
基于点的方法:
根据用于每个点的特征学习的网络架构,此类方法可以分为逐点MLP、基于卷积、基于图、基于分层数据结构的方法和其他典型方法。
逐点 MLP 方法:使用多个共享的多层感知器 (MLP) 独立地对每个点进行建模,然后使用对称聚合函数聚合全局特征
基于卷积的方法:
与在 2D 网格结构(例如图像)上定义的内核相比,由于点云的不规则性,3D 点云的卷积内核很难设计。根据卷积核的类型,当前的3D卷积方法可以分为连续卷积方法和离散卷积方法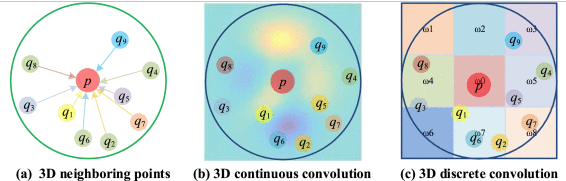
(a) 表示以点 p 为中心的局部邻域 qi ; (b) 和 (c) 分别表示 3D 连续卷积和离散卷积。
3D 连续卷积方法。这些方法在连续空间上定义卷积核,其中相邻点的权重与相对于中心点的空间分布相关。3D 卷积可以解释为给定子集的加权和,MLP,以某一点周围的局部点子集为输入 ,通过学习从低级关系(如欧几里得距离和相对位置)到局部子集与中心点之间高级关系的映射,实现卷积。
3D 离散卷积方法。这些方法在规则网格上定义卷积核,其中相邻点的权重与相对于中心点的偏移量相关。
基于图的方法:

空间域中基于图的方法。这些方法定义了空间域中的操作(例如,卷积和池化)。具体来说,卷积通常通过空间邻居上的 MLP 来实现,并采用池化来通过聚合来自每个点的邻居的信息来生成新的粗化图。每个顶点通常被赋予坐标、激光强度或颜色等特征,而每个边上的特征通常与两个相连点之间的几何属性相关联。
![[C#]使用sdcb.paddleocr部署v4版本ocr识别模型](https://img-blog.csdnimg.cn/direct/230006d3b85b442b87ee1e5a10dbb750.jpeg)