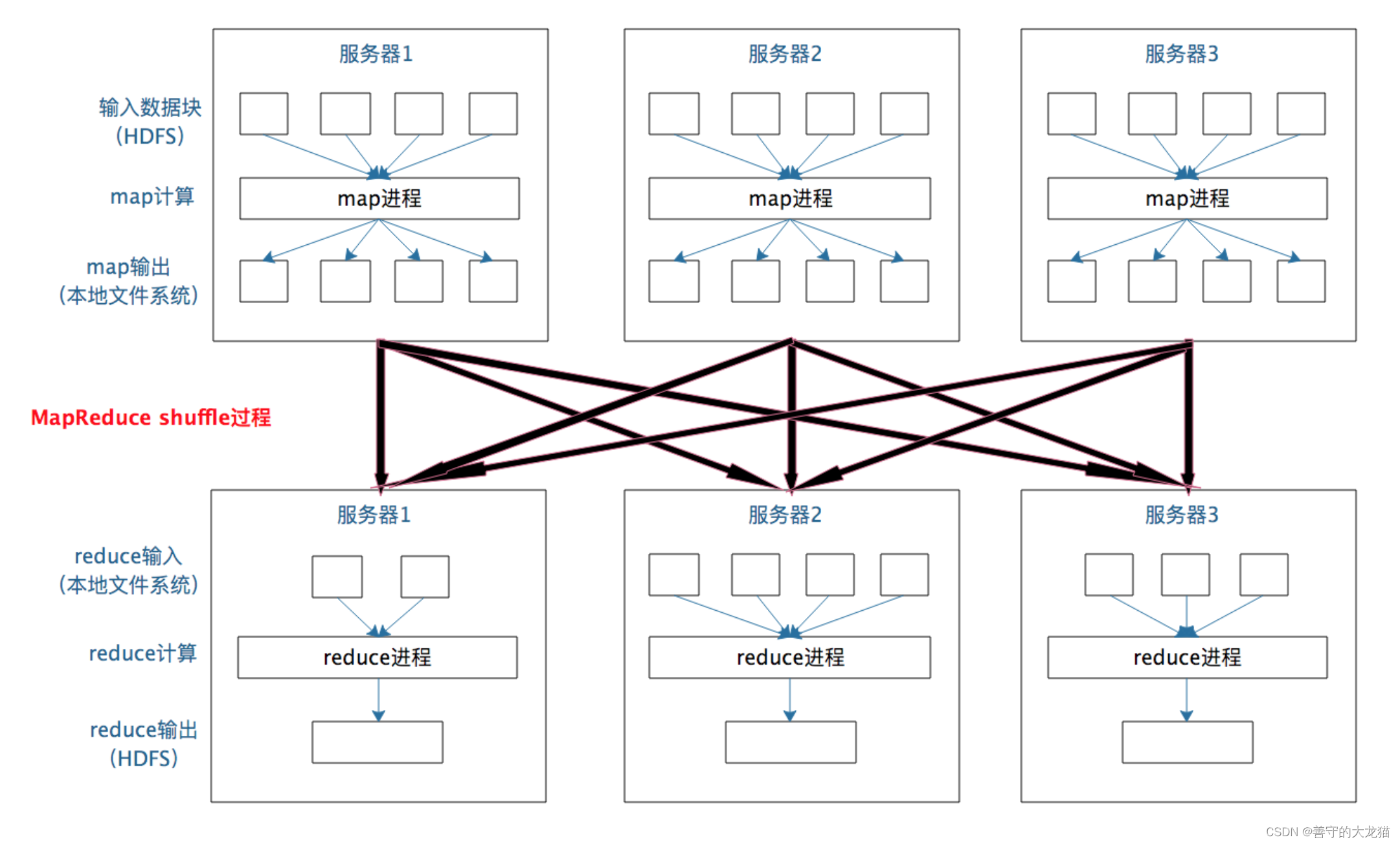
In the previous post, Running GPT4All On a Mac Using Python langchain in a Jupyter Notebook, 我发布了一个简单的演练,让GPT4All使用langchain在2015年年中的16GB Macbook Pro上本地运行。在这篇文章中,我将提供一个简单的食谱,展示我们如何运行一个查询,该查询通过从单个基于文档的已知源检索的上下文进行扩展。
I’ve updated the previously shared notebook here to include the following…
基于文档的知识源支持的示例查询
使用langchain文档中的示例进行示例文档查询。
其想法是对文档源运行查询,以检索一些相关的上下文,并将其用作提示上下文的一部分。
#https://python.langchain.com/en/latest/use_cases/question_answering.html
template = """
Question: {question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["question"]) llm_chain = LLMChain(prompt=prompt, llm=llm)
天真的提示给出了一个无关紧要的答案:
%%time query = "What did the president say about Ketanji Brown Jackson" llm_chain.run(question)
CPU times: user 58.3 s, sys: 3.59 s, total: 1min 1s Wall time: 9.75 s
'\nAnswer: The Pittsburgh Steelers'
Now let’s try with a source document.
#!wget https://raw.githubusercontent.com/hwchase17/langchainjs/main/examples/state_of_the_union.txt
from langchain.document_loaders import TextLoader
# Ideally....
loader = TextLoader('./state_of_the_union.txt')
然而,创建嵌入非常慢,所以我将使用文本片段:
#ish via chatgpt...
def search_context(src, phrase, buffer=100):
with open(src, 'r') as f:
txt=f.read()
words = txt.split()
index = words.index(phrase)
start_index = max(0, index - buffer)
end_index = min(len(words), index + buffer+1)
return ' '.join(words[start_index:end_index])
fragment = './fragment.txt'
with open(fragment, 'w') as fo:
_txt = search_context('./state_of_the_union.txt', "Ketanji")
fo.write(_txt)
!cat $fragment Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence. A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. We can do both. At our border, we’ve installed new technology like cutting-edge
loader = TextLoader('./fragment.txt')
从知识源文本生成索引:
#%pip install chromadb from langchain.indexes import VectorstoreIndexCreator
%time
# Time: ~0.5s per token
# NOTE: "You must specify a persist_directory oncreation to persist the collection."
# TO DO: How do we load in an already generated and persisted index?
index = VectorstoreIndexCreator(embedding=llama_embeddings,
vectorstore_kwargs={"persist_directory": "db"}
).from_loaders([loader])
Using embedded DuckDB with persistence: data will be stored in: db CPU times: user 2 µs, sys: 2 µs, total: 4 µs Wall time: 7.87 µs
%time pass # The following errors... #index.query(query, llm=llm)
# With the full SOTU text, I got:
# Error: llama_tokenize: too many tokens;
# Also occasionally getting:
# ValueError: Requested tokens exceed context window of 512
# If we do get passed that,
# NotEnoughElementsException
# For the latter, somehow need to set something like search_kwargs={"k": 1}
在默认情况下,检索器似乎期望4个结果文档。我看不出如何通过下限(在这种情况下,可以接受单个响应文档),所以我们必须滚动自己的链…
%%time # Roll our own.... #https://github.com/hwchase17/langchain/issues/2255 from langchain.vectorstores import Chroma from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.chains import RetrievalQA documents = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0) texts = text_splitter.split_documents(documents) # Again, we should persist the db and figure out how to reuse it docsearch = Chroma.from_documents(texts, llama_embeddings)
在没有持久性的情况下使用嵌入式DuckDB:数据将是瞬态的 CPU times: user 5min 59s, sys: 1.62 s, total: 6min 1s Wall time: 49.2 s
%%time
# Just getting a single result document from the knowledge lookup is fine...
MIN_DOCS = 1
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff",
retriever=docsearch.as_retriever(search_kwargs={"k": MIN_DOCS}))
CPU times: user 861 µs, sys: 2.97 ms, total: 3.83 ms Wall time: 7.09 ms
现在在知识源的上下文中运行我们的查询怎么样?
%%time print(query) qa.run(query)
What did the president say about Ketanji Brown Jackson CPU times: user 7min 39s, sys: 2.59 s, total: 7min 42s Wall time: 1min 6s ' The president honored Justice Stephen Breyer and acknowledged his service to this country before introducing Justice Ketanji Brown Jackson, who will be serving as the newest judge on the United States Court of Appeals for the District of Columbia Circuit.'
更精确的查询如何?
%%time query = "Identify three things the president said about Ketanji Brown Jackson" qa.run(query)
CPU times: user 10min 20s, sys: 4.2 s, total: 10min 24s Wall time: 1min 35s ' The president said that she was nominated by Barack Obama to become the first African American woman to sit on the United States Court of Appeals for the District of Columbia Circuit. He also mentioned that she was an Army veteran, a Constitutional scholar, and is retiring Justice of the United States Supreme Court.'
嗯……我们是否正在进行对话,并了解以前的输出?在之前的尝试中,我似乎确实得到了非常相关的答案……我们是否可能得到了几个以上的结果文档,并选择了不太好的结果文档?或者,模型在检索内容上是否有遗漏?我们是否可以查看knowledge查找中的示例结果文档,以帮助了解发生了什么?
让我们看看是否可以格式化响应
…
%%time query = """ Identify three things the president said about Ketanji Brown Jackson. Provide the answer in the form: - ITEM 1 - ITEM 2 - ITEM 3 """ qa.run(query)
CPU times: user 12min 31s, sys: 4.24 s, total: 12min 35s Wall time: 1min 45s "\n\nITEM 1: President Trump honored Justice Breyer for his service to this country, but did not specifically mention Ketanji Brown Jackson.\n\nITEM 2: The president did not identify any specific characteristics about Justice Breyer that would be useful in identifying her.\n\nITEM 3: The president did not make any reference to Justice Breyer's current or past judicial rulings or cases during his speech."
本文:【langchain】在单个文档知识源的上下文中使用langchain对GPT4All运行查询 | 开发者开聊
自我介绍
- 做一个简单介绍,酒研年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师研究会】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。全网同号【架构师研究会】

欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.