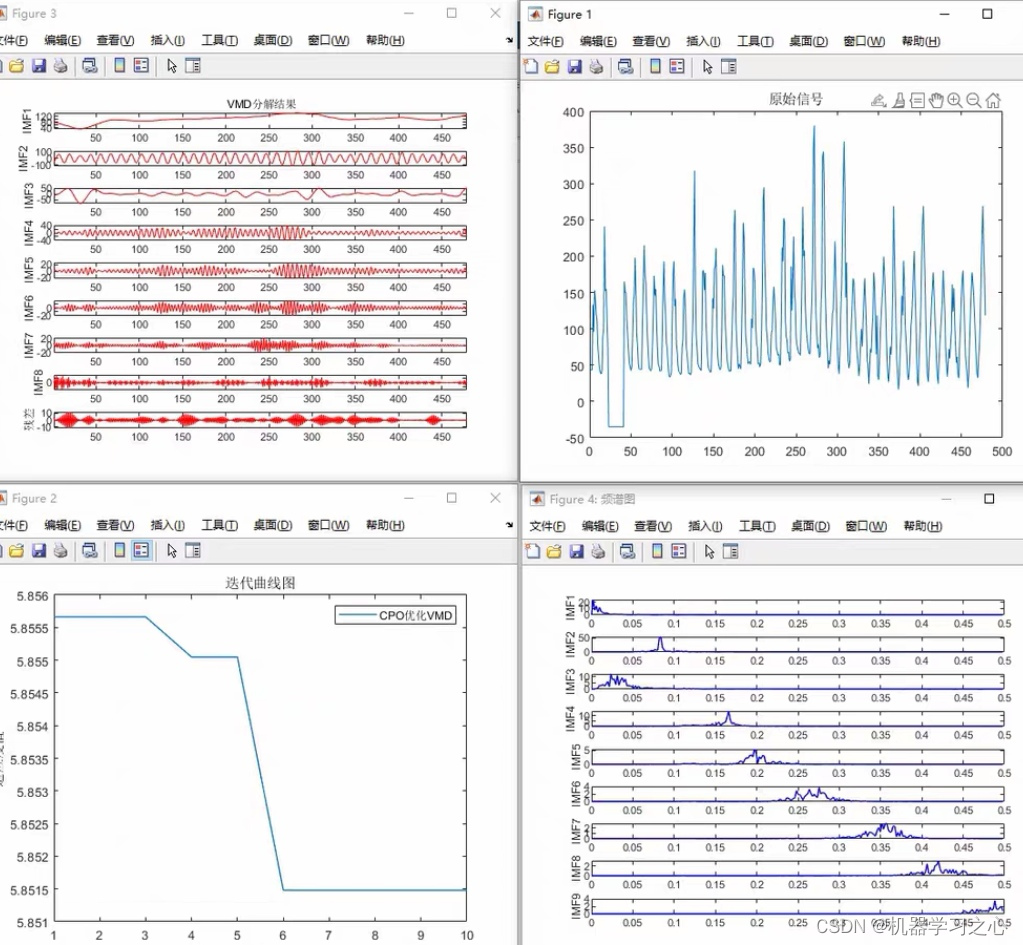
C++中神奇的tuple:详解使用技巧和实例解析
- 一、tuple的基本概念
- 二、tuple基础知识
- 2.1、tuple的创建和初始化
- 2.2、tuple的成员访问
- 2.3、效果展示
- 2.4、tupe的成员函数、非成员函数 及 辅助类
- 三、tuple高级应用技巧
- 3.1、tuple的结构化绑定
- 3.2、tuple的运算符重载
- 3.3、tuple的嵌套和组合
- 四、tuple实例解析
- 五、tuple的性能和适用场景分析
- 总结
一、tuple的基本概念
在C++中,tuple是一种数据结构,用于将多个值组合在一起,形成一个有序的元组。每个值在tuple中都有一个对应的索引,可以通过索引来访问和操作其中的值。
作用:
-
tuple将多个值组合在一起,形成一个整体。这些值可以是不同的数据类型,例如整数、浮点数、字符串等。
-
tuple中的值是有序排列的,每个值都有一个对应的位置索引,可以通过索引来访问和操作其中的值。
-
可以将tuple中的值解构出来,分别赋值给不同的变量,方便对其中的值进行单独处理。
-
在函数中可以使用tuple作为返回类型,从而方便返回多个值,而不需要使用指针或引用参数。
-
C++17引入了结构化绑定的特性,可以方便的从tuple中提取出其中的值并进行使用,在代码书写上更加简洁和可读。

二、tuple基础知识
C++中的tuple是一个标准库类模板,用于存储固定数量的异类对象。允许将多个对象捆绑成一个单一的对象,并且可以轻松地从中提取值或者通过结构化绑定将其解构到不同的变量中。tuple提供了一个通用的数据结构,可以保存不同类型的元素,并通过下标或者std::get函数来访问其中的值。
C++11引入了最初的tuple实现, C++17进一步扩展了其功能,增加了结构化绑定的支持,大大提高了tuple在实际应用中的便利性。
2.1、tuple的创建和初始化
(1)直接初始化:
#include <tuple>
#include <string>
int main() {
// 直接初始化一个tuple
std::tuple<int, double, std::string> myTuple(10, 3.14, "Hello");
return 0;
}
(2)使用std::make_tuple函数进行初始化:
#include <tuple>
#include <string>
int main() {
// 使用make_tuple函数创建一个tuple
auto myTuple = std::make_tuple(10, 3.14, "Hello");
return 0;
}
(3)使用std::tie进行结构化绑定的初始化:
#include <tuple>
#include <string>
int main() {
int a;
double b;
std::string c;
std::tie(a, b, c) = std::make_tuple(10, 3.14, "Hello");
return 0;
}
(4)使用std::forward_as_tuple进行创建和初始化:
#include <tuple>
#include <string>
int main() {
auto myTuple = std::forward_as_tuple(10, 3.14, "Hello");
return 0;
}
2.2、tuple的成员访问
(1)使用 std::get 函数按索引访问元素:
#include <iostream>
#include <tuple>
int main() {
std::tuple<int, double, std::string> myTuple(10, 3.14, "Hello");
int intValue = std::get<0>(myTuple);
double doubleValue = std::get<1>(myTuple);
std::string stringValue = std::get<2>(myTuple);
std::cout << "Int value: " << intValue << std::endl;
std::cout << "Double value: " << doubleValue << std::endl;
std::cout << "String value: " << stringValue << std::endl;
return 0;
}
(2)使用 std::tie 进行结构化绑定,将 tuple 成员绑定到指定的变量:
#include <iostream>
#include <tuple>
int main() {
int a;
double b;
std::string c;
std::tuple<int, double, std::string> myTuple(10, 3.14, "Hello");
std::tie(a, b, c) = myTuple;
std::cout << "Int value: " << a << std::endl;
std::cout << "Double value: " << b << std::endl;
std::cout << "String value: " << c << std::endl;
return 0;
}
(3)使用结构化绑定(C++17):
#include <iostream>
#include <tuple>
int main() {
std::tuple<int, double, std::string> myTuple(10, 3.14, "Hello");
auto [intValue, doubleValue, stringValue] = myTuple;
std::cout << "Int value: " << intValue << std::endl;
std::cout << "Double value: " << doubleValue << std::endl;
std::cout << "String value: " << stringValue << std::endl;
return 0;
}
注意,std::forward_as_tuple的初始化方式是无法使用结构化绑定访问元素的。
2.3、效果展示
示例:
#include <tuple>
#include <iostream>
# include <string>
int main(int n,char ** args)
{
// 直接初始化:
std::tuple<int, double, std::string> mtuple(1,2.0,"3a");
// 使用`std::make_tuple`函数进行初始化:
auto mtuple2 = std::make_tuple(11,22.0,"3aa");
// 使用`std::tie`进行结构化绑定的初始化:
int a;
double b;
std::string s;
std::tie(a,b,s)=std::make_tuple(111,222.0,"3aaa");
// 使用`std::forward_as_tuple`进行创建和初始化:
auto mtuple3=std::forward_as_tuple(1111,2222.0,"3aaaa");
// 使用 `std::get` 函数按索引访问元素:
std::cout<<"使用 `std::get` 函数按索引访问元素:"<<std::endl;
int oa=std::get<0>(mtuple);
double ob=std::get<1>(mtuple);
std::string os=std::get<2>(mtuple);
std::cout<<"oa="<<oa<<",ob="<<ob<<",os="<<os<<std::endl;
std::cout<<"使用 std::tie 进行结构化绑定,将 tuple 成员绑定到指定的变量:"<<std::endl;
std::cout<<"a="<<a<<",b="<<b<<",s="<<s<<std::endl;
std::cout<<"使用结构化绑定(C++17):"<<std::endl;
// 注意,std::forward_as_tuple的初始化方式是无法使用结构化绑定访问元素的。
auto [intVal,doubleVal,strVal] = mtuple2;
std::cout<<"intVal="<<intVal<<",doubleVal="<<doubleVal<<",strVal="<<strVal<<std::endl;
return 0;
}
输出:
使用 `std::get` 函数按索引访问元素:
oa=1,ob=2,os=3a
使用 std::tie 进行结构化绑定,将 tuple 成员绑定到指定的变量:
a=111,b=222,s=3aaa
使用结构化绑定(C++17):
intVal=11,doubleVal=22,strVal=3aa
2.4、tupe的成员函数、非成员函数 及 辅助类
| 成员函数 | 描述 |
|---|---|
| constructor(C++11) | 构造一个新的“元组”(公共成员函数) |
| operator=(C++11) | 将一个“元组”的内容分配给另一个(公共成员函数) |
| swap (C++11) | 交换两个元组的内容(公共成员函数) |
| 非成员函数 | 描述 |
|---|---|
| std::tuple_size | 返回 tuple 中元素的数量 |
| std::tuple_element | 返回 tuple 中指定索引的元素类型 |
| std::get | 通过索引访问 tuple 的元素 |
| std::tie | 将 tuple 的元素绑定到指定的变量 |
| std::make_tuple | 创建 tuple |
| std::forward_as_tuple | 创建 tuple,保留变量的类型(包括引用) |
| std::tuple_cat | 连接两个或多个 tuple |
| std::swap | 交换两个 tuple 的内容 |
| 辅助类 | 描述 |
|---|---|
| std::pair | 包含两个值的不同类型的固定大小集合 |
| std::tuple_size | tuple 类型的长度 |
| std::tuple_element | tuple 类型的元素类型 |
这些成员函数、非成员函数和辅助类提供了丰富的功能,可以用于创建、访问和操作 tuple,使得 tuple 在 C++ 中成为一个强大且灵活的数据结构。
三、tuple高级应用技巧
3.1、tuple的结构化绑定
因为tuple的结构化绑定是一种非常方便的技巧,所以这里再次强调一下。在 C++17 中引入了结构化绑定(structured bindings),可以用来将 tuple 或其他数据结构中的元素绑定到多个变量中,而无需显式地通过索引进行访问。这个技巧可以让代码更加清晰和易读,特别是在处理多个返回值或者复杂的数据结构时非常有用。
(1)对于 tuple 结构化绑定的使用(再次强调):
std::tuple<int, double, std::string> myTuple(10, 3.14, "Hello");
auto [intValue, doubleValue, stringValue] = myTuple;
std::cout << "Int value: " << intValue << std::endl;
std::cout << "Double value: " << doubleValue << std::endl;
std::cout << "String value: " << stringValue << std::endl;
(2)结构化绑定也可以用于返回多个值的函数:
std::tuple<int, double> getData() {
return std::make_tuple(10, 3.14);
}
auto [value1, value2] = getData();
std::cout << "Value 1: " << value1 << std::endl;
std::cout << "Value 2: " << value2 << std::endl;
(3)结构化绑定还可以用于 STL 容器中的元素访问:
std::map<int, std::string> myMap = {{1, "One"}, {2, "Two"}, {3, "Three"}};
for (const auto& [key, value] : myMap) {
std::cout << "Key: " << key << ", Value: " << value << std::endl;
}
(4)使用结构化绑定处理复杂的数据结构:
std::unordered_map<std::string, std::pair<int, double>> data = {{"item1", {10, 3.14}}, {"item2", {20, 6.28}}};
for (const auto& [key, value] : data) {
int intValue = value.first;
double doubleValue = value.second;
std::cout << "Key: " << key << ", Int value: " << intValue << ", Double value: " << doubleValue << std::endl;
}
结构化绑定的引入让 tuple对其他数据结构的处理变得更加简洁、清晰和灵活。
3.2、tuple的运算符重载
(1)比较运算符重载(如==、!=、<、>等),实现自定义的比较行为。例如对 tuple 元素的比较:
bool operator==(const std::tuple<int, double>& t1, const std::tuple<int, double>& t2) {
return std::get<0>(t1) == std::get<0>(t2) && std::get<1>(t1) == std::get<1>(t2);
}
(2)算术运算符重载如+、-、*、/等),实现对 tuple 的算术操作。例如对两个 tuple 进行加法运算:
std::tuple<int, double> operator+(const std::tuple<int, double>& t1, const std::tuple<int, double>& t2) {
return std::make_tuple(std::get<0>(t1) + std::get<0>(t2), std::get<1>(t1) + std::get<1>(t2));
}
(3)流操作符重载(<<和>>)。实现对 tuple 的输入输出操作,使得可以直接使用流操作符对 tuple 进行输入输出:
template <typename... Args>
std::ostream& operator<<(std::ostream& os, const std::tuple<Args...>& t) {
os << "(";
std::apply([&os](const auto&... args) {
((os << args << ", "), ...);
}, t);
os << ")";
return os;
}
3.3、tuple的嵌套和组合
在 C++ tuple 嵌套和组合是为处理复杂的数据结构提供了灵活性和便利性。
(1)嵌套 tuple:将多个 tuple 组合成一个更大的 tuple,以便对多个数据结构进行整体操作,主要使用tuple_cat函数。
例如,将两个 tuple 进行组合:
std::tuple<int, double> tuple1 = std::make_tuple(10, 3.14);
std::tuple<std::string, char> tuple2 = std::make_tuple("hello", 'A');
auto combinedTuple = std::tuple_cat(tuple1, tuple2);
// combinedTuple 的类型为 std::tuple<int, double, std::string, char>
(2)元组中嵌套元组:在 tuple 中嵌套另一个 tuple,以实现更复杂的数据结构。例如,创建一个包含两个 tuple 的元组:
std::tuple<int, std::tuple<double, std::string>> nestedTuple = std::make_tuple(10, std::make_tuple(3.14, "hello"));
(3)使用结构化绑定处理嵌套 tuple可以方便地处理嵌套的 tuple,通过一次性的声明对嵌套 tuple 进行解构和赋值:
auto [intValue, nestedTupleValue] = nestedTuple;
auto [doubleValue, stringValue] = nestedTupleValue;
(4)嵌套 tuple 的更复杂组合:多次的 tuple_cat 操作将多个 tuple 进行更复杂的组合,实现更为复杂的数据结构:
auto tuple1 = std::make_tuple(1, 2, 3);
auto tuple2 = std::make_tuple(4, 5, 6);
auto tuple3 = std::make_tuple(7, 8, 9);
auto combinedTuple = std::tuple_cat(tuple1, tuple2, tuple3);
// combinedTuple 的类型为 std::tuple<int, int, int, int, int, int, int, int, int>
特别是结合结构化绑定的使用,可以简化对嵌套和组合 tuple 的操作,提高代码的可读性和可维护性。
四、tuple实例解析
(1)实例一:使用tuple进行函数返回多个值。
#include <iostream>
#include <tuple>
// 使用 std::make_tuple 返回多个值
std::tuple<int, double, float> calculateValues(int a, int b) {
int sum = a + b;
double difference = a - b;
float product = a * b;
float quotient = static_cast<float>(a) / b;
return std::make_tuple(sum, difference, product * quotient);
}
int main() {
int x = 10, y = 5;
// 使用 std::make_tuple 方式创建 tuple
auto result1 = calculateValues(x, y);
// 使用结构化绑定和 std::tie 方式解构 tuple 结果
int s1, d1;
float pq1;
std::tie(s1, d1, pq1) = result1;
std::cout << "Sum: " << s1 << ", Difference: " << d1 << ", Product*Quotient: " << pq1 << std::endl;
// 使用直接通过 std::tuple 的构造函数方式创建 tuple
std::tuple<int, double, float> result2(x + y, x - y, x * y / static_cast<float>(x));
int s2, d2;
float pq2;
std::tie(s2, d2, pq2) = result2;
std::cout << "Sum: " << s2 << ", Difference: " << d2 << ", Product*Quotient: " << pq2 << std::endl;
return 0;
}
函数接受两个整数参数,并返回了一个包含三个值的 tuple。在 main 函数中通过不同方式创建了 tuple 并使用结构化绑定解构 tuple 中的值。
(2)实例二:使用tuple进行数据结构的扩展。
#include <iostream>
#include <tuple>
int main() {
// 创建一个包含不同类型的元素的 tuple
std::tuple<int, double> data1 = std::make_tuple(10, 3.14);
// 定义结构体
struct Person {
std::string name;
int age;
};
// 创建一个包含结构体和其他类型的元素的 tuple
std::tuple<Person, std::string, int> data2 = std::make_tuple(Person{"Alice", 30}, "Hello", 99);
// 创建一个包含 tuple 的 tuple
std::tuple<int, std::tuple<double, std::string>> data3 = std::make_tuple(5, std::make_tuple(3.14, "pi"));
// 创建一个更复杂的嵌套结构
std::tuple<std::string, std::tuple<int, double>, std::tuple<float, char>> data4 = std::make_tuple("Nested", std::make_tuple(10, 3.14), std::make_tuple(4.5f, 'A'));
// 访问和打印 tuple 中的元素
std::cout << "Data 1: " << std::get<0>(data1) << ", " << std::get<1>(data1) << std::endl;
std::cout << "Data 2: " << std::get<0>(std::get<0>(data2)).name << ", " << std::get<0>(std::get<0>(data2)).age << ", " << std::get<1>(data2) << ", " << std::get<2>(data2) << std::endl;
std::cout << "Data 3: " << std::get<0>(data3) << ", " << std::get<0>(std::get<1>(data3)) << ", " << std::get<1>(std::get<1>(data3)) << std::endl;
std::cout << "Data 4: " << std::get<0>(data4) << ", " << std::get<0>(std::get<1>(data4)) << ", " << std::get<1>(std::get<1>(data4)) << ", " << std::get<0>(std::get<2>(data4)) << ", " << std::get<1>(std::get<2>(data4)) << std::endl;
return 0;
}
示例中创建了多个不同的 tuple 数据结构,每个都展示了一种常见的嵌套和组合方式。
(3)实例三:作为STL容器类的元素类型。例如 vector 和 map,使用 tuple 来存储不同类型的元素:
#include <iostream>
#include <vector>
#include <map>
#include <tuple>
int main() {
// 使用 tuple 作为 vector 的元素类型
std::vector<std::tuple<int, double, std::string>> vec;
// 添加元素到 vector
vec.push_back(std::make_tuple(10, 3.14, "Hello"));
vec.push_back(std::make_tuple(20, 6.28, "World"));
// 遍历 vector 中的元组
for (const auto& item : vec) {
std::cout << "Int value: " << std::get<0>(item) << std::endl;
std::cout << "Double value: " << std::get<1>(item) << std::endl;
std::cout << "String value: " << std::get<2>(item) << std::endl;
}
// 使用 tuple 作为 map 的 value 类型
std::map<int, std::tuple<std::string, double>> myMap;
// 添加元素到 map
myMap[1] = std::make_tuple("John", 175.5);
myMap[2] = std::make_tuple("Alice", 160.3);
// 遍历 map 中的元组
for (const auto& pair : myMap) {
std::cout << "Key: " << pair.first << std::endl;
std::cout << "Name: " << std::get<0>(pair.second) << std::endl;
std::cout << "Height: " << std::get<1>(pair.second) << std::endl;
}
return 0;
}
五、tuple的性能和适用场景分析
tuple的性能:
(1)与自定义结构体的性能比较:tuple不一定总是比自定义结构体优秀,tuple 也可能比使用自定义结构体更加低效,因为 tuple 通常需要进行运行时的动态内存分配。而使用自定义结构体会更加高效,因为它的内存布局更为紧凑,没有额外的开销。
(2)当tuple中包含的元素数量较少时,tuple 的性能通常是可以接受的,并且不会造成太大的性能损耗。
(3)当tuple中包含大量的元素时,tuple 的性能可能会受到影响,特别是在元组的创建、销毁和访问操作方面。
建议:如果对性能有较高要求,使用结构体或类来代替 tuple,因为结构体或类通常会在编译时进行优化,并且在内存布局方面更加紧凑。
tuple的适用场景:
(1)返回多个值:当需要从函数中返回多个值时,使用 tuple 是一种方便的方式。
(2)想将多个数据项打包在一起,并且数据项的类型各不相同 时使用 tuple 可以很好地解决这个问题,避免创建新的自定义结构体。
(3)函数参数传递:函数需要接受多个不同类型的参数时,使用 tuple 可以很方便地将这些参数打包在一起,并传递给函数。
(4)中间结果存储:在一些算法或计算过程中会产生中间结果,使用 tuple 可以方便地将这些中间结果存储起来,以便之后使用。
(5)与算法库结合:在使用标准库中的算法时,tuple 也有其用武之地,比如可以方便地将多个数据项打包在一起,用作算法的输入或输出;或者遍历容器时使用tuple结构化绑定。
tuple与其他数据结构的对比:
(1)Array(数组):数组是一种包含相同类型元素的数据结构,而 tuple 允许存储不同类型的元素。因此,如果要存储相同类型的元素,选择使用数组;而如果要存储不同类型的元素,使用 tuple。
(2)Pair(对):pair 是一种特殊的 tuple,它只能存储两个元素。因此,如果只需要存储两个元素,使用 pair;要存储三个及以上的元素,使用 tuple。
(3)Struct(结构体):结构体是一种自定义的数据结构,可以包含不同类型的数据成员,并且可以定义自己的成员函数。相比之下,tuple 是一个泛化的数据结构,通常用于临时存储一些松散相关的数据,而不需要为每个元素定义一个具体的名称。
(4)Vector(向量):vector 是一种动态数组,用于存储相同类型的元素。提供了动态扩展和访问元素的能力。tuple 则更适合用于存储固定数量的松散相关的数据,不要求动态操作。
总结
tuple 具有多种强大功能和灵活应用:
- 存储多个不同类型的值,便于打包和传递多元数据。
- 在函数中方便地返回多个值,简化了函数返回值的处理。
- 可以作为函数的参数类型,简化了参数列表的处理。
- 可以用于元编程和函数式编程范式,用于表示元组、模式匹配等。
- 与标准库中的算法结合使用,方便地作为算法的输入或输出。
- 可以用于解耦数据,不需要创建新的自定义数据结构。
- 使代码更简洁、更易读、更灵活。